
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Типы классификаторов текстов в рамках синтагматического подхода
В настоящее время практическое применение получили классификаторы следующие типов: 1. Статистические классификаторы, на основе вероятностных методов. Наиболее известным в данной группе является семейство Байесовых. Их общей чертой является процедура классификации, в основе которой лежит формула Байеса для условной вероятности. 2. Классификаторы, основанные на функциях подобия. В терминах введенной модели (1.1) характерной чертой данного метода является универсальность описаний F, которые с одной стороны используются для представления содержания рубрик, а с другой стороны – содержания анализируемых текстов. Процедура классификации f использует меру подобия (семантическое расстояние) вида E: F x F→[0;1], позволяющую количественно оценивать тематическую близость описаний Ft ϵ F и Fi ϵ F, где описание Ft представляет содержание анализируемого текста, а Fi – содержание некоторой рубрики. Действия процедуры классификации f сводятся к преобразованию анализируемого текста t в представление Ft ϵ F, оценке подобия описания Ft с описаниями рубрик Fi, и заключение по результатам сопоставления о принадлежности текста одой или нескольким рубрикам. Последнее заключение выполняется либо на основе сравнения с пороговой величиной Emin, так что текст относится ко всем рубрикам ci, для которых E(Ft,Fi)>Emin, либо из всех E(Ft,Fi) выбирается максимальная величина, которая и указывает на результирующую рубрику. Наиболее характерными для таких классификаторов является использование лексических векторов модели терм-документ в описаниях F, которые так же применяются и в нейронных классификаторах. В качестве меры подобия обычно берется косинус угла между векторами, вычисляемый через скалярное произведение 3. Классификаторы, построенные с использованием методов детерминистского подхода: искусственные нейронные сети, метод опорных векторов и т.п. Нейросети хорошо зарекомендовали себя в задачах распознавания изображений, однако, с большим успехом применяются в обработке ЕЯ-текстов. Описания классов F, как правило, представляют собой многомерные вектора действительных чисел, заложенные в синаптических весах искусственных нейронов, а процедура классификации f характеризуется способом преобразования анализируемого текста t к аналогичному вектору, видом функции активации нейронов, а так же топологией сети. Процесс обучение классификатора в данном случае совпадает с процедурой обучения сети и зависит от выбранной топологии.
Все они дают устойчиво хорошие результаты в различных ситуациях применения. Теперь подробнее о построении каждого типа классификатора. Начнем со статистических моделей. Вероятностные модели на основе наивного байесовского классификатора Классический метод классификации текстов делает очень сильные предположения о независимости участвующих событий (появления слов в документах), но практика показывает, что наивный байесовский классификатор оказывается весьма эффективен. При описании вероятностной модели, как и ранее, используется множество рубрик C, каждая из которых представлена фиксированным набором ключевых слов, множество документов D, по которому составлен словарь коллекции Метод Байеса заключается в вычислении вероятностей сопоставления документа каждой из рубрик и выборе рубрики, вероятность для которой будет максимальной. Каждая рубрика ci характеризуется безусловной вероятностью ее выбора P(ci) в процессе классификации некоторого документа (совокупность таких событий для всех рубрик образуют систему гипотез, так что
Апостериорная вероятность принадлежности документа d рубрике ciпо теореме Байеса вычисляется так:
Делая предположение о независимости термов в документе, получаем:
Далее задача состоит в нахождении оценок априорных вероятностей P(ci) и P(w|ci). Оценить P(ci) можно с помощью отношения количества документов из обучающей выборки, которым приписана рубрика ci, к количеству документов в обучающей выборке
P(w|ci) можно оценить как отношение документов из рубрики ci, содержащих терм w, к общему числу документов в рубрике ci:
В числителе добавлена единица для избегания нулевых вероятностей. Запишем решающее правило для метода Байеса:
На практике существует два подхода к использованию метода Байеса для классификации: 1) для каждой рубрики в отдельности принимать решение относится документ к ней или нет – бинарная классификация. При этом множество рубрик С сокращается до двух – ciи 2) вычислять P(ci|d) для всех рубрик и выбирать те, для которых эта вероятность будет максимальной.
Другой подход у оценке условной вероятности P(ci|d) предложен в методеProbabilistic TF-IDF (PrTFIDF). Терм w встречается в документе d с вероятностью P(w|d). Применяя формулу полной вероятности и затем теорему Байеса, получаем:
Делая предположение о том, что терм w несет исчерпывающую информацию о документе d в целом, так что принадлежность документа к той или иной категории не вносит дополнительной информации о документе в целом, получим P(d|ci,w) ≈ P(d|w). Очевидно, что если в качестве термов выбраны леммы, то данное предположение не всегда верно, в частности, для слов, имеющих несколько смысловых значений. Тем не менее, в целях упрощения можно попробовать использовать это предположение, получаем:
Остается вычислить оценку этих двух вероятностей. P(w|d) вычисляется на основе представления документа d:
где TF(w,d) – частота вхождения слова w в документ d, |d| – общее количество слов в документе.
Применяя теорему Байеса, найдем вероятность того, что документ, в котором есть слово w, принадлежит рубрике ci. По аналогии с моделью наивного байесовского классификатора, логично предположить, что оценки вероятностей P(ci) следует вычислять оценки этих вероятностей на основе априорной информации как отношение количества документов в рубрике к общему числу документов, однако, как показывает практика, классификатор, использующий неравные вероятности для рубрик, давал существенно худшие результаты, поскольку он в основном выбирал рубрики с большим числом документов и игнорировал рубрики с небольшим числом документов. Поэтому следует сделать предположение о том, вероятности P(ci) одинаковы для всех рубрик, следовательно:
Оценка P (w|ci) может быть вычислена на основе обучающего набора данных как
На основе полученных оценок аппроксимируем вероятность P(ci|d):
Запишем решающее правило для алгоритма PrTFIDF. В случае, если значение P(ci|d) не требуется в качестве меры уверенности в выборе рубрики, то знаменатель первой дроби можно не рассчитывать. Тогда классификатор f имеет вид:
Задача обучения классификатора сводится к вычислению всех возможных P (w|ci) на основе обучающей выборки документов. Размерность пространства при построении вектора признаков, равна числу различных термов содержащихся в обучающей выборке текстов. Из-за того, что учитываются все слова, которые когда-либо встретились в текстах, вектора получаются с огромным количеством координат, большинство из которых нули. Многие алгоритмы классификации очень чувствительны к времени вычисления, которое часто является функцией от длины вектора, представляющего документ, поэтому необходимо стараться уменьшить размерность пространства признаков. Существуют различные расширения базового подхода, позволяющие сократить размерность признакового пространства. Например, можно по-другому выбирать термы. Бывает полезным брать в качестве термов не слова, а устойчивые группы слов, вводить дополнительные термы (например, характеризующие длину документа). Для сокращения размерности векторов можно не учитывать редкие слова, которые увеличивают размер правила, но, как правило, не несут полезной для классификатора информации. Для чего вводят коэффициент полезности каждого терма (насколько этот терм полезен для классификации). Эту характеристику можно определить, основываясь на корреляции между встречаемостью слова в документе и принадлежностью этого документа к одной (или нескольким) из категорий. Наиболее простой и популярный подход – удаление из вектора признаков стоп-слов. Кроме удаления лишних термов, можно ещё группировать несколько термов в один. Например, можно группировать вместе синонимы. Ещё один подход — совстречаемость (cooccurrence): объединять слова, часто встречающиеся в одном окружении. Например, в словосочетаниях «руководитель компании», «директор компании» слова «руководитель» и «директор» встречаются перед словом «компания». Поэтому их можно объединить в один искусственный терм. В общем случае для слов определяется некая метрика близости, и группы близких слов склеиваются в один терм. Вес такого терма в каждом конкретном документе рассчитывается из весов представителей группы, которые встречаются в этом документе. Одними из самых распространенных подходов, к уменьшению размерности пространства признаков, являются стемминг (процедура усечения окончаний) [D.A. Hull. Stemming Algorithms – A Case Study for Detailed Evaluation, JASIS, 47(1): 70-84, 1996 ], алгоритмы, основанные на правилах словообразования [M.F.Porter. An algorithm for suffix stripping, Program, 14(3):130-137, 1980 ], а также их комбинации. Они используют предположение, что приведение различных встречающихся форм слова к одному поисковому признаку (к одной форме) значительно уменьшит размерность признакового пространства, что может увеличить скорость и обработки и положительно сказаться на результате классификации.
Эту процедуру выполняет модуль морфологического анализа. В литературе данный модуль также называют нормализатором слов, лемматизатором или стеммером. Операцию, или выполняемую данным модулем можно представить как отображение W→L, где W – множество всех терминов в коллекции документов; L – множество всех соответствующих лемм. При этом количество лемм меньше мощности множества всех терминов |W|>|L|. Реализуя данное преобразование, можно достичь улучшения точности поиска за счет использования вместо частот слов частоты лемм, что позволяет получить больший вес для релевантных документов. Кроме того, так как количество лемм меньше количества слов, то лемматизация приводит к уменьшению размерности пространства признаков и увеличению скорости классификации. Такая предварительная обработка - сокращение текста для более точной классификации, с помощью описанных выше подходов называется препроцессинг. Однако надо сказать, что развитие методов смыслового сжатия текстов [Леонтьева Н. Н. Неполнота и смысловое сжатие в текстовом корпусе // Международная конференция MegaLing'2005 «Прикладная лингвистика в поиске новых путей». Материалы конференции. Меганом, Крым, Украина. Симферополь: Изд-во «Осипов». СПб, 2005. C. 67-73.] и совершенствование алгоритмов классификации приводит к тому, что использование морфологической обработки для уменьшения размера индекса в настоящее время не является критически важным в большинстве случаев. Проблема классификаций произвольной области знаний, к сожалению, не всегда разрешима из-за синонимии и полисемии языка. В первом случае имеется в виду, что одно и то же понятие может быть выражено в документе и в запросе с использованием различных терминов - синонимов. Например, самолет и аэроплан. Во втором случае, один термин может иметь различные значения в различных контекстах. Например, рак - это беспозвоночное, болезнь и созвездие. В приведенных же классических моделях изначально предполагалось рассмотрение документов как множества отдельных слов вне контекста, не зависящих друг от друга, грамматика и порядок следования слов игнорируются. Такая упрощающая концепция имеет название «Bag of Words». Один из подходов к решению проблемы синонимии и полисемии языка, учитывающий контекстную близость и существенно сокращающий размерность вектора признаков, связан с использованием классификаторов, основанных на функциях подобия.
|
|||||||||
|
|
Последнее изменение этой страницы: 2017-02-07; просмотров: 155; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.191.223.123 (0.029 с.) |
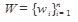 , включающий все термы, встречающиеся хотя бы в одном документе из информационного массива. Образом текста является вектор d=(d1,...,dn), компонента i которого равна 1, если терм w i входит в данный документ, и 0 в противном случае. Здесь, как и ранее, терм задается своим порядковым номером в словаре, а n - общее количество термов в словаре коллекции.
, включающий все термы, встречающиеся хотя бы в одном документе из информационного массива. Образом текста является вектор d=(d1,...,dn), компонента i которого равна 1, если терм w i входит в данный документ, и 0 в противном случае. Здесь, как и ранее, терм задается своим порядковым номером в словаре, а n - общее количество термов в словаре коллекции.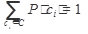 ), а так же условной вероятностью P(w|ci) встретить терм w в документе d при условии выбора рубрики ci. Эти величины используются при расчете вероятностей P(d|ci) того, что текст будет классифицирован при условии выбора рубрики ci. При расчете P(d|ci) учитывается представление d в виде последовательности термов wk. Подстановка этих величин в формулу Байеса дает вероятность того, что будет выбрана рубрика ci, при условии, что документ d пройдет успешную классификацию. Процедура классификации сводится к подсчету P(ci|d) для всех рубрик ci и выбора той, для которой эта величина максимальна. Обучение сводится к составлению словаря W и определению для каждой рубрики величин P(ci) и P(w|ci).
), а так же условной вероятностью P(w|ci) встретить терм w в документе d при условии выбора рубрики ci. Эти величины используются при расчете вероятностей P(d|ci) того, что текст будет классифицирован при условии выбора рубрики ci. При расчете P(d|ci) учитывается представление d в виде последовательности термов wk. Подстановка этих величин в формулу Байеса дает вероятность того, что будет выбрана рубрика ci, при условии, что документ d пройдет успешную классификацию. Процедура классификации сводится к подсчету P(ci|d) для всех рубрик ci и выбора той, для которой эта величина максимальна. Обучение сводится к составлению словаря W и определению для каждой рубрики величин P(ci) и P(w|ci).

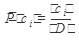

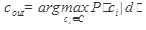
 , в которую входят все документы не вошедшие в ci;
, в которую входят все документы не вошедшие в ci;









