
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Скрытое распределение ДирихлеСкрытое распределение Дирихле (LDA) относительно новый метод, был впервые представлен как метод информационного поиска в 2002 году. LDA – это статистический метод, который, используя баейсовские вероятности, определяет, насколько релевантен данный документ заданной теме. Как и описанные выше методы латентно-семантического анализа, LDA предполагает наличие латентных связей между словами и их контекстом, определяющим релевантность документа, анализируя встречаемость слов и словосочетаний в коллекции документов, метод предполагает, что наблюдаемые слова документа — результат влияния скрытых факторов (тем). В теории вероятностей и математической статистике распределение Дирихле Dir(α) — это семейство непрерывных многомерных вероятностных распределений, параметризованных вектором α неотрицательных вещественных чисел. Его функция плотности вероятности возвращает доверительную вероятность того, что вероятность каждого из K взаимноисключающих событий равна xi при условии, что каждое событие наблюдалось αi − 1 раз: Распределение Дирихле является сопряжённым априорным распределением к мультиномиальному распределению, а именно:
если X=(X1,...,XK) ~ Dir(α) и β|X=(β1,...,βK)|X~Mult(X), то X|β ~ Dir(α+β)
где βi — число вхождений i в выборку из n точек дискретного распределения на {1, …, K} определенного через X. Эта связь используется в Байесовской статистике для того, чтобы оценить скрытые параметры дискретного вероятностного распределения X, имея набор из n выборок. Очевидно, если априорное распределение обозначено как Dir(α), то Dir(α+β) - апостериорное распределение после серии наблюдений с гистограммой β. В модели LDA используются упрощения концепции «Bag of Words» и следующие положения: · документы представляют собой совместное распределение скрытых тем, · каждая тема — результат распределения слов словаря.
Пусть М — количество документов, К — количество тем, V — размер словаря, wn — n -тое слово документа w. Процесс генерации каждого документа w может быть описан следующими шагами: 1. Выбор вектора распределения тем в документе, который описывается многомерной случайной величиной θ, имеющей распределение Дирихле θ ~ Dir (α) 2. Для каждого слова wт 2.1. выбор скрытой темы zn с помощью мультиномиального распределения zn~Mult (θi) 2.2. Выбор слова wn с помощью мультиномиального распределения wn ~Mult (b, zn) Наблюдаемыми переменными при этом являются только wn, остальные — скрытые. На рис. 3.1 модель LDA показана графически.
Рисунок 3.1. Графическое представление LDA-модели, имеющей 3 уровня: корпус текстов~ (α, b), документ ~(θ), слово ~ (z,w)
Вероятность совместного распределения:
Маргинальная вероятность для документа w:
Процедура классификации в LDA-модели традиционна в рамках статистических методов:
Однако ключевым моментом здесь является то, что в качестве оценки вероятности P(w|ci) LDA-метод использует
Модель LDA, как правило, работают лучше на небольших наборах данных, поскольку байесовские методы не могут подстраиваться под изменение данных.
|
||
|
|
Последнее изменение этой страницы: 2017-02-07; просмотров: 259; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.138.69.45 (0.005 с.) |




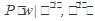 . В этом случае классификатор имеет вид:
. В этом случае классификатор имеет вид:



