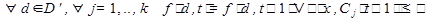Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Подходы к кластеризации текстов ⇐ ПредыдущаяСтр 7 из 7
Кластерный анализ занимает одно из центральных мест среди методов анализа данных и представляет собой совокупность методов, подходов и процедур, разработанных для решения проблемы формирования однородных классов (кластеров) в произвольной проблемной области. Задача кластеризации заключается в следующем. Заданы: коллекция тестов D, подлежащих кластеризации; множество описаний F документов этой коллекции в признаковом пространстве; обучающая выборка документов коллекции функция расстояния между объектами ρ(x,x′); множество номеров кластеров Y. процедура кластеризации (алгоритм кластеризации) f:D→Y, которая заключается в разбиении обучающей выборки на подмножества, называемые кластерами, так, чтобы каждый кластер состоял из объектов, близких по метрике ρ, а объекты разных кластеров существенно отличались. При этом каждому документу dϵD приписывается метка (номер) кластера yi. Общая модель классификатора текстов может быть представлена алгебраической системой следующего вида
C=<D, D', Y, F, ρ, f>
При кластеризации документов возникают некоторые сложности, связанные с множественностью выбора алгоритмов этого процесса. Разные методологии используют разные алгоритмы подобия документов при наличии большого количества признаков. Механизм классификации обычно обучается на отобранных документах только после того, как заканчивается стадия обучения путем автоматической кластеризации - разбиения множества документов на классы (кластеры), смысловые параметры которых заранее неизвестны. При этом для каждого кластера находится центроид - документ, чей образ расположен наиболее близко к геометрическому центру кластера. Количество кластеров может быть произвольным или фиксированным. Если классификация допускает приписывание документам определенных, известных заранее признаков, то кластеризация более сложный процесс, который допускает не только приписывание документам некоторых признаков, но и выявление самых этих признаков как основ формирования классов. Цель методов кластеризации массивов документов состоит в том, чтобы подобие документов, которые попадают в кластер, было максимальным. Поэтому методы кластерного анализа базируются на таких определениях кластера, как множества документов, значение семантической близости, т.е. функции, обратной функции расстояния ρ(x,x′), для любых двух элементов этого множества (или значение близости между любым документом этого множества и центром кластера) не меньше определенного порога.
В начале текущего обзора упоминалось о метриках, которые используются в задачах классификации (раздел 2). В кластерном анализе для численного определения значения близости между документами используются такие основные правила определения расстояния (метрики), как метрика Минковского:
где x и y — образы документов в признаковом пространстве, представляющие собой векторы, элементами которых являются весовые значения термов, которые, как правило, определяются в результате анализа большого массива документов. Частным случаем при р=2 метрики Минковского является Евклидова метрика. Для группирования документов, представленных в виде векторов весовых значений входящих в них термов, часто используется скалярное произведение весовых векторов. Решение задачи кластеризации текстов выдвигает ряд требований к алгоритму кластеризации: · применимость сильно сгруппированных данных; · автоматическое определение оптимального числа кластеров; · не более чем логлинейный рост времени работы кластеризатора с увеличением количества текстов; · минимальная (в лучшем случае отсутствующая) настройка со стороны пользователя.
Задача кластеризации текстов с трудом поддается формализации. Оценка адекватности разбиения множества D, как правило, основывается на кластеры основывается на мнении эксперта и трудновыразима в виде одной численной характеристики. Возникает требование интерпретируемости результата: кластерам должны быть присвоены некоторые метки, отражающие их семантику. Следовательно, процедура кластеризации должна еще обладать свойством интерпретируемости найденных кластеров в терминах смысла содержания относящихся к ним документов. Рассмотрим наиболее распространенные алгоритмы кластеризации. В общем виде методы кластеризации могут быть разбиты на две группы: представляющие тексты в виде векторов в многомерном пространстве признаков (и использующие метрику близости между векторами) и применяющие другие представления анализируемых текстов. Первая группа использует неиерархические алгоритмы: метод k-средних — модификация метода k ближайших соседей, рассмотренных в данном обзоре в пункте 3.1, а также, нейронные сети SOM, ART, топология которых была описана в пункте 3.2.3, латентно-семантического анализа - модели LSA и PLSA, описание которых было приведено в пункте 3.2.2.1 и которые позволяют выявить достаточно чётко выделяемые кластеры), а также большое число других базирующихся на них методов. Примером алгоритмов второй группы является алгоритм Suffix Trie Clustering (STC – древовидные структуры).
Неиерархические методы выявляют более высокую устойчивость по отношению к шумам и выбросам, некорректному выбору метрики, включению незначимых переменных в набор, участвующий в кластеризации. Но при этом в большинстве алгоритмов необходимо заранее определить количество кластеров, итераций или правило остановки, а также некоторые другие параметры кластеризации. Иерархические методы строят полное дерево вложенных кластеров. Сложности данных методов кластеризации – ограничение объема набора данных, выбор меры близости, негибкость полученных классификаций. В частности, недостатками метода STC являются обязательное наличие первоначального дерева, значительное время работы при больших размерах первоначального дерева. В связи с перечисленными выше трудностями эти методы в рамках данной работы рассматриваться не будут. При анализе рассмотренных методов кластеризации выявлено, что максимально соответствует перечисленным требованиям к алгоритму кластеризации метод нейронных сетей SOM, использующей метод обучения без учителя (unsupervised learning). SOM не требует наличия обучающей выборки, применима к сильно сгруппированным данным; сама определяет количество получаемых кластеров, дает возможность настроить параметры сети по умолчанию. При этом увеличение количества текстов не влечет за собой экспоненциальный рост времени обработки, и интерпретация найденных кластеров осуществляется осмысленно в ключевых словах. Если входным вектором X при кластеризации текстов является частотный портрет или, например, TF*IDF модель представления данных, то автоматически извлекается индекс в виде вектора основных понятий и их связи с весовыми характеристиками. В качестве смыслового портрета текста рассматривается сеть понятий – множество ключевых слов или словосочетаний. Каждое понятие имеет некоторый вес, отражающий значимость этого понятия в тексте. Как было подробно описано ранее в пункте 3.2.3, механизм работы сети использует две основные процедуры настройки нейронной сети – инициализация весов нейронов случайным образом и непосредственно алгоритм SOM: · определение расстояний между входным вектором X и вектором весов W каждого нейрона по формуле: · определение нейрона-победителя с минимальным расстоянием; · определение области активации нейрона-победителя; · коррекция весов нейронов внутри области влияния по формуле
wij(t + 1) = wij(t) + λ (xi(t) − wij(t))
Далее следует запись обработанной обучающей выборки в получаемый динамический массив кластеров. Таким образом, сеть SOM имеет набор входных элементов (частотные портреты документов) и набор выходных элементов (множество кластеров). Обучение нейронной сети происходит на каждом документе из обучающей выборки Данная нейронная сеть имеет несколько настраиваемых числовых параметров: · число нейронов; · норма обучения; · множитель для нормы обучения; · радиус активности области нейрона-победителя; · число производимых итераций, шаг модификации. Время обработки резко возрастает при увеличении числа нейронов, радиуса активации и при уменьшении нормы обучения. В ходе исследований были выявлены тенденции влияния на получаемое множество классов при изменении перечисленных выше параметров нейронной сети. Наборы комбинаций числовых параметров нейронной сети для кластеризации могут быть получены в результате численных исследований в зависимости от желаемой точности/полноты классов. При оценке адекватности разбиения документов на кластеры выявлено, что кластеры в большинстве своем разбивают по типам документов, при этом выносят в отдельные кластеры документы с резко отличающейся лексикой. Полученный результат кластеризации адекватен экспертной разбивке проблемной области. Нейросетевой кластеризатор на основе SOM прост в реализации, удобен в обучении, требует минимального участия эксперта, а также позволяет выбирать оптимальное соотношение точность/полнота за счет настройки числовых параметров в алгоритме обучения. При заданном количестве кластеров наиболее эффективным является итеративный алгоритм кластерного анализа k-means (k-средних). Группировка документов по фиксированному количеству кластеров с помощью этого метода заключается в следующем: 0. Инициализация. Случайным образом выбирается k документов, которые определяются как центроиды (наиболее типичные представители) кластеров, т.е. каждый кластер cjпредставляется вектором 1. Кластеризация. k кластеров наполняются: для каждого из документов обучающей выборки, определяется близость к центроиду соответствующего кластера с помощью метрики ρ(x,x′). Текущий документ d, образ которого — вектор x, приписывается к ближайшему кластеру с помощью процедуры кластеризации
:
2. Уточнение положения центроида. После того, как все документы обучающей выборки распределены по кластерам, проводится перерасчет координат векторов центроидов. В качестве центроида используется вектор, координаты которого определяются, как среднее арифметическое соответствующих весовых документов, входящих в данный кластер:
3. Проверка условия останова. Процесс считается стабильным, если результаты кластеризации не изменились. Возможен другой вариант - уменьшение суммы расстояния от каждого элемента до центра его кластера не станет меньше некоторого заданного порогового значения).
В отличие от метода LSA, k-means может использоваться для группирования динамических информационных потоков благодаря своей вычислительной простоте. Недостатком метода является то, что каждый документ может попасть всего лишь в один кластер.
Выводы
Обобщая вышесказннное, можно сделать следующие выводы. 1. Несмотря на многообразие с уществующих методов автоматической классификации текста, с практической точки зрения их все можно разбить на два класса. Методы первого класса — методы парадигматического подхода, формируют достаточно изощренные, дающие хороший результат, но сравнительно медленно работающие, основанные на лингвистических методах, ко второму классу относятся простые, быстрые, но грубые механизмы анализа; чаще всего это подходы, использующие формальные статистические методы, основанные на частоте появления в тексте слов различных тематик. Эффективным же можно считать такой метод, который сочетал бы в себе «простоту» статистических алгоритмов с достаточно высоким качеством обработки лингвистических методов. В тоже время, как показала практика, для классификации текстов не требуется полный грамматический анализ предложений, в него входящих. Достаточно выделить наиболее информативные единицы текста - ключевые слова, словосочетания, предложения и фрагменты, причем в качестве характеристики информативности хорошо работает частота повторения слов в тексте. 2. Поэтому представляется перспективным представление смысла текста в форме сети, узлы которой представлены множеством часто встречавшихся понятий текста - слов и устойчивых словосочетаний, из числа которых исключены общеупотребимые слова. Узлы сети связаны между собой с различной силой связи, причем сила связи коррелированна с частотой совместной встречаемости понятий в предложениях текста. Сеть может быть автоматически построена на базе множества текстов. Ее можно рассматривать как модель предметной области или как модель некоторой тематики. автоматически построенные модели заданных тематик могут быть использованы для анализа неизвестных документов. Таким образом, задачу тематической классификации текстов можно сформулировать так: построение моделей тематик, построение описания (модели) рассматриваемого документа и оценка близости между описаниями тематик и описанием документа.
3.Во всех созданных человеком текстах можно выделить статистические закономерности. Никому не удается обойти их. Кто бы их ни писал, какой бы язык он при этом ни использовал, внутренняя структура текста останется неизменной. Поэтому для выделения понятий сети, представляющих слова и связные словосочетания, целесообразно использовать статистический алгоритм, основанный на анализе частоты встречаемости цепочек слов различной длины и их вхождения друг в друга. При этом необходимо учитывать следующее: слова, которые попадаются слишком часто, в основном оказываются предлогами, местоимениями, т.е. стоп-словами. Редко встречающиеся слова тоже, в большинстве случаев, не имеют решающего смыслового значения. От того, как будет выставлен диапазон значимых слов, зависит многое. Если поставить широко – то в ключевые слова будут попадать вспомогательные слова; если установить узкий диапазон – то можно потерять смысловые термины. Сделать выделение наиболее значимых слов качественнее помогает препоцессинг, т.н. предварительное исключение исследуемого текста некоторых слов, которые априори не могут являться значимыми и, поэтому являются «шумом». 3. Для вычисления веса терма нужнопредставить всю базу данных как единый документ, к ней можно будет применить те же законы, что и к единичному документу. Обычно, чтобы избавиться от лишних слов и в тоже время поднять рейтинг значимых слов, вводят инверсную частоту термина - IDF. Значение этого параметра тем меньше, чем чаще слово встречается в документах базы данных. Если использовать модель представления TF*IDF, то термин, получивший нулевой или близкий к нулю вес, можно исключить из модели семантической сети. 4. Для понижения размерности признакового пространства целесообразно в качестве терминов использовать не только отдельные слова, но и словосочетания. Тогда необходимо модель сети определить следующим образом: Пусть N – количество элементов сети, W = [wij] — матрица весов. Тогда wij ~ p(j|i), где p(j|i) – условная вероятность появления j- го понятия в связи с i-м Оценка параметров сети требует определения понятий, а также условных вероятностей p(j|i) появления пары понятий в связи. Провести такую оценку возможно на основе анализа множества текстов, порожденных моделью - эталонных текстов из одного класса в задаче классификации, используя определение условной вероятности и Байесовский вывод. 5. Обоснованными можно считать предположения, что: · предложение представимо как набор входящих в него понятий; · каждое предложение имеет одно порождающее понятие – тему, которое обуславливает появление всех остальных понятий, связанных с ним, но попарно независимых. В качестве критерия возможной связности понятий используем факт их появления в одном предложении текста. Отсутствие априорной информации на этапе построения модели не позволяет учесть сверхфразовые связи, вследствие чего разумно предположить все понятий равновероятными в качестве тем. · порождающее понятие-тема — скрытый параметр, его появление обусловленно понятием предшествующего предложения. 6. В свете сделанных предположений можно сказать, что полная вероятность порождения наблюдаемого текста моделью есть вероятность соответствующей реализации марковского процесса. 7. После получения семантической сети текста и рубрик сравнение семантической сети входного текста с семантическими сетями рубрик (классификация) позволяет сделать вывод о принадлежности текста к тематике одной или нескольких рубрик.
|
|||||||||
|
|
Последнее изменение этой страницы: 2017-02-07; просмотров: 146; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 52.14.221.113 (0.038 с.) |
 , вектора признаков которой принадлежат множеству
, вектора признаков которой принадлежат множеству  ,
,  ;
;
 ;
; , соответствующим центроиду. Затем на каждой итерации t выполняется:
, соответствующим центроиду. Затем на каждой итерации t выполняется: