
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Аксиомы, связывающие функциональные зависимости и многозначные зависимости.Содержание книги
Поиск на нашем сайте
А4. (копирования) Если А5. (объединения) Если Пример:?
t1t4 + t1t3 – Утверждение1: Если отношение Утверждение 2: Пусть
Правила вывода: 1) (объединения) Если 2) (псевдотранзитивность) Если 3) (декомпозиции)
Существует обобщение формы Бойса-Кодда для многозначных зависимостей, которая называется 4НФ: Пусть Теорема: Если отношение Из 2) и 3) следует: Утверждение: Пусть Множества Алгоритм вычисления базиса: Входные данные: множество многозначных зависимостей Выходные данные: базис зависимостей 1) Пусть 2) До тех пор, пока Пусть в результате получаем совокупность 3) До тех пор, пока возможны изменения в 4) Полученная совокупность Метод построения декомпозиции обладает свойством соединения без потерь. Теорема: Пусть Алгоритм построения декомпозиции отношения R, обладающего свойством соединения без потерь, может быть обобщен и на случай многозначной зависимости. Приведение отношений к нормальной форме обеспечивает целостность данных. Если отношение находится в 3НФ, то несколько несложных правил помогают сохранить семантическую целостность при операциях проектирования и соединения: 1. Проектирование корректно, если получающееся в результате отношение содержит тот же самый ключ, что и исходное отношение, или эквивалентный возможный ключ. 2. Отношение а) ключ отношения б) ключ отношения В общем случае секретность может быть нарушена при: сбое оборудования, ошибке оператора, программной ошибке в СУБД или операционной системе, или в прикладной программе. Основная идея обеспечения ограничений целостности данных заключается в том, чтобы использовать ЯМД как средство выражения этих ограничений. Декларация ограничений целостности содержит 2 части. В первой из них должно быть выражено само ограничение, а во второй – описывается когда, при каких условиях должна выполняться сама проверка. ЯМД реальных систем позволяет в той или иной мере поддерживать, если не все, то многие из рассмотренных ограничений целостности.
СЕКРЕТНОСТЬ ДАННЫХ. Под секретностью данных понимается защита от несанкционированного доступа к данным, и, как следствие, защита от разрушения данных. Средства защиты имеют особое значение при функционировании БД в сети. Заключается в: 1. идентификации пользователя. Различным пользователям предоставляются различные права по отношению к различным БД или частям БД, т.е. к их отношениям или атрибутам. Это могут быть права только чтения данных, или работа с частью БД и т.д. Наиболее часто для идентификации пользователя используется пароль; 2. поддержка и передача прав. Система должна поддерживать перечень прав предоставленных любому пользователю для каждой защищенной части БД; 3. физическая защита. Можно защищать с помощью кодирования данных. Обеспечение секретности требует разделения всей хранимой в БД информации на общедоступные данные и конфиденциальные данные. Это функция администратора БД. Кроме этого администратор БД: - определяет права доступа отдельных пользователей к данным; - организовывает систему контроля за данными. Access 7.0 для Windows 95 предусматривает различные средства защиты данных. С помощью средств защиты можно задать действия, которые разрешается выполнять пользователю или группе пользователей над объектами БД – таблицами, отчетами, формами, запросами, макросами и модулями. Для каждого пользователя или группы пользователей создаются регистрационные записи с указанием прав доступа к тем или иным объектам БД. Средства защиты состоят из нескольких составных частей, обеспечивающих полную или частичную защиту приложения. Полная защита устанавливается настройкой всех составных частей – рабочих групп, регистрационных записей, прав владения и прав доступа. Рабочая группа – файл с информацией о группе пользователей, работающих в многопользовательской среде. В рабочей группе хранятся регистрационные записи, содержащие данные о правах доступа к объектам. При инсталляции рабочая группа создается по умолчанию; ее можно изменить (рабочая группа содержит имя, код, организацию). Регистрационные записи включаются в рабочую группу. Admins (администратор), Users (пользователь). Изменение прав владельца. По умолчанию администратор является владельцем любой БД и всех ее объектов после инсталляции MАccess. Поэтому для защиты необходимо изменить права владения БД и всеми ее объектами, присвоив эти права созданной регистрационной записи владельца, т.е. пользователя, которому будут присвоены права владельца. Присвоение и удаление прав доступа для пользователей и групп. Определить права доступа к некоторому обекту может пользователь, который является владельцем этого объекта или администратором, включенным в текущую рабочую группу администраторов. Могут быть следующие права доступа: чтение данных, изменение, вставка, исключение. Одни права следуют из других (чтение из изменения). Шифрование БД.
ФИЗИЧЕСКАЯ ОРГАНИЗАЦИЯ БД. Физическое проектирование заключается в отображении МД в среду хранения. Задачей физического проектирования является выбор рациональной структуры хранения данных и методов доступа к ним, исходя из того арсенала методов и средств, которые предоставляются разработчику системой управления БД. Т.к. СУБД функционирует в среде развитых ЭВМ с мощными ОС, при проектировании БД не разрабатываются программы манипулирования данными на физическом уровне, а используются программы методов доступа ОС. Такой подход обеспечивает возможность относительной независимости операций хранения данных от используемых технических средств. Во внутренней модели БД может быть представлена в виде совокупности хранимых файлов, для которых известна структура хранимых записей, определены служебные поля, реализующие необходимые связи между записями, известны методы доступа СУБД к этим записям и т.д. Хранимое поле – это наименьшая именованная единица данных в БД. Хранимая запись – именованная совокупность связанных хранимых полей. Экземпляр хранимой записи состоит из группы соответствующих экземпляров хранимых полей. Хранимый файл – именованная совокупность всех экземпляров хранимых записей одного типа. В большинстве существующих систем логические записи идентичны хранимым записям. Но может быть, что 1) логическая запись состоит из некоторого подмножества хранимых записей (2 типа хранимых записей объединяются в один); 2) логическая запись может содержать поля из нескольких хранимых записей (если один тип хранимой записи расщеплен на два). Любой хранимый файл может физически размещаться в памяти разными способами. Внутренняя модель – это еще один шаг в сторону от физического уровня, т.к. она не строится в терминах физических записей или блоков. Внутренняя модель состоит из внутренних (хранимых) записей. В состав СУБД включаются средства преобразования хранимых записей к виду физического представления на машинном носителе и обратно.
интерфейс логических
интерфейс хранимых
интерфейс экземпляры физических физических
Пользователи составляют свой запрос в ПП, используя термины МД. СУБД, получив запрос из ПП (например, на чтение данных из базы), организует запрос к ОС на считывание из физической БД необходимой порции данных с машинного носителя в свою буферную область памяти. Таким образом, в буферной памяти СУБД окажутся хранимые записи, имеющие структуру в соответствии со схемой внутренней МД. Затем выполняется требуемое отображение хранимых записей в записи МД и уже затем затребованные записи модели передаются в рабочую область ввода-вывода прикладной программы, затребовавшей эти данные. Интерфейс хранимых записей позволяет СУБД представить структуры хранения в виде совокупности хранимых файлов, каждый из которых состоит из экземпляров одного типа хранимых записей. Точнее, СУБД известно, какие существуют хранимые файлы и для каждого из них: - структура соответствующих хранимых записей; - хранимые поля упорядочения (если таковые есть); - хранимые поля, которые могут использоваться как аргументы выборки при прямом доступе (если таковые есть). Объектом, передаваемым через интерфейс хранимых записей, является один экземпляр хранимой записи. СУБД неизвестно ничего о: - физических записях (блоках); - как хранимые поля связаны в хранимые записи; - как осуществляется упорядочение (физическое следование, по индексу, по указателю); - как выполняется доступ (посредством индекса; последовательным просмотром; хэш-адресация). Эта информация есть часть описания структуры хранения, но она используется методами доступа, а не СУБД. Рассмотрим возможные структуры хранения на примере РМД (поставщик)
1 вариант: (простейший) предполагает единственный хранимый файл, содержащий 5 экземпляров хранимых записей, по одному экземпляру для каждого поставщика. Преимуществом данного варианта является его простота. Недостатком является избыточность информации. Например, 10000 поставщиков из 10 городов (информация о городах избыточна). Метод доступа – последовательный. Если предположить, что указатель занимает меньше памяти, чем название города, то вариант 2 позволяет сэкономить некоторый объем памяти (это единственное преимущество).
+ файл Город:
Об указателях заботится заботится СУБД, а не метод доступа; методу доступа связь между двумя файлами неизвестна. Метод доступа – последовательный. 3 вариант: Если наиболее частым является запрос: «Перечислить всех поставщиков из данного города», то может быть выбран следующий способ хранения: файл Город: файл Поставщик:
Метод доступа – индексно-последовательный. Этот вариант лучше предыдущего для запросов о всех поставщиках, расположенных в данном городе, но обеспечивает худшие характеристики для запросов о всех характеристиках данного поставщика. Требование к объему памяти то же, что в варианте 2. Интересное свойство: файл «Город» служит индексом для файла «Поставщик» (индекс, управляемый СУБД, но не методом доступа). Фактически это плотный, вторичный индекс. Термин плотный индекс означает, что индекс содержит отдельную запись для каждого экземпляра хранимой записи индексируемого файла. В этом случае индексируемый файл не содержит индексированное поле (файл «Поставщик» не содержит поле «Город»). Неплотный индекс: индекс не содержит элементы для каждого экземпляра хранимой записи в индексируемом файле. В этом случае каждый экземпляр хранимой записи должен содержать индексируемое поле. Термин «вторичный» означает, что индексируемое поле не является первичным ключом. 4 вариант: объединение 2 и 3 вариантов. Чтобы получить преимущество каждого за счет потери большего пространства памяти и за счет необходимости прилагать больше усилий для поддержания указателей при изменениях.
Недостатком вариантов 3,4 (там, где используются вторичные индексы) является непредсказуемое число указателей в каждом элементе индекса, т.е. в каждом экземпляре хранимой записи в индексе. Это усложняет работу СУБД при изменениях в БД. 5 вариант. Каждый экземпляр хранимой записи файла «Поставщик» или файла «Город» содержит только один указатель. Каждая запись файла городов указывает на запись первого поставщика в этом городе. Эта запись поставщика указывает на запись второго поставщика того же города и т.д.; последняя запись содержит указатель на город. Таким образом, для каждой записи города мы имеем цепочку записей всех поставщиков в этом городе. Преимущество этого варианта состоит в простоте изменений. Недостатком является то, что для города единственным способом доступа к n-му поставщику является последовательное прохождение по цепочке от 1-го ко 2-му и т.д. до (n-1) поставщика. Если каждая операция доступа включает операцию поиска, то время доступа к n-му поставщику может стать достаточно большим. Этот способ называется многосписочной организацией.
Развитие этого варианта: двунаправленные цепочки; включение в запись поставщика указателя на соответствующую запись города, для того, чтобы сократить объем просматриваемых ссылок при выполнении некоторых типов запросов. 6 вариант: Можно сделать произвольное число вторичных индексов. В предельном случае предусмотрен индекс по каждому вторичному полю. Это инвертированная организация структуры хранения. Она обеспечивает хорошую производительность для запросов о всех поставщиках, обладающих определенным значением атрибута, но ответ на запрос о всех атрибутах конкретного поставщика потребует продолжительного времени. Поставщик:Код:
5 30 На практике часто используют компромиссный вариант, предусматривающий обычную организацию (вариант 1) совместно со вторичными индексами по тем полям, которые являются важными с точки зрения АБД. Это требует дополнительной памяти для хранения значений индексируемых полей. Такой вариант является одной из наиболее общих структур хранения. Другой вариант – иерархическая организация (разновидность индексированной).Вид хранимой записи зависит от запроса.
С У М
1 2 3 4 5 Один хранимый файл, содержащий три экземпляра хранимой записи, по одному экземпляру на город. Каждый экземпляр хранимой записи содержит список произвольной длины, каждый экземпляр которого содержит номер поставщика, его имя и код товара. В этой же записи есть данные о городе (аналогично варианту 3, где используются указатели. Вариант 3 является фактически иерархическим файлом). Последний вариант – хэш-адресация. Основная идея: каждый экземпляр хранимой записи размещается в БД по адресу хранимой записи, который может быть вычислен как некоторая функция Алгоритм преобразования ключа в адрес называется подпрограммой рандомизации или хэширования.
Чтобы заполнить экземпляр, СУБД вычисляет адрес хранимой записи и заставляет метод доступа разместить этот экземпляр в соответствующей позиции; при поиске экземпляра СУБД выполняет те же самые вычисления и запрашивает метод доступа для вызова экземпляра из вычисленной позиции. Преимущество: быстрый прямой доступ на основе значений хэшируемого поля. Недостатки: 1) теоретически возможно использовать (числовое) значение первичного ключа в качестве адреса хранимой записи. Практически это неприемлимо, т.к. диапазон значений первичного ключа обычно много шире диапазона доступных адресов хранимых записей. Например, пусть номера поставщиков трехзначные. Теоретически их 999, а на практике максимально 10. Это увеличивает объем памяти. 2) последовательность экземпляров хранимых записей в пределах хранимого файла не совпадает с последовательностью, определяемой первичным ключом. 3) возможность коллизий – двум различным экземплярам хранимых записей назначен один и тот же адрес.
Таким образом, структур хранения достаточно много, но «наилучшей» не существует. В обязанности АБД входит согласование большого числа противоречивых требований при выборе структуры хранения, учитывая при этом следующие факторы: - эффективность выборки; - затраты на осуществление изменений; - объем доступного пространства памяти; - реорганизация БД; - проблема восстановления. Интерфейс физических записей – это интерфейс между методом доступа и физической БД. Единицей передачи через этот интерфейс является экземпляр физической записи (один блок). В этом интерфейсе в отличии от интерфейса хранимых записей существенно физическое следование, которое является важным средством установления порядка экземпляров хранимых записей в хранимом файле за счет: - физического порядка экземпляров хранимых записей в пределах одного блока; - физического порядка блоков на носителе. Говоря о физической БД обычно имеют в виду дисковую память. Файловые системы, использующие дисковую память разделяют диск на физические блоки равного размера. Типичный размер физического блока от 29 до 212 байт. Каждый физический блок (или просто блок) имеет адрес, который является абсолютным адресом на диске. Файл хранится в одном или более блоках, причем в каждом блоке хранится несколько записей. Внутри блока могут быть пустые байты. Запись имеет адрес, который может рассматриваться либо как абсолютный адрес ее первого байта, либо как адрес блока, в котором она содержится, вместе со смещением – числом байтов в блоке, предшествующих началу записи. Методы доступа к данным. Метод доступа – это средство, которое использует СУБД для детального управления физическим доступом к БД. Метод доступа реализуется набором подпрограмм, назначение которых состоит в том, чтобы скрыть все детали управления устройствами от СУБД и обеспечить СУБД интерфейсом хранимых записей. Допущение: когда экземпляр новой хранимой записи впервые создается и вводится в СУБД, методы доступа должны присвоить ему уникальный адрес хранимой записи. Эта величина позволяет различать экземпляры хранимых записей в БД. Она, например, может быть физическим адресом экземпляра в пределах дисковой памяти. Адрес хранимой записи в последующем может использоваться СУБД для прямой выборки этого экземпляра записи. Адрес хранимой записи является статическим, т.е. его значение не изменяется до тех пор, пока экземпляр записи физически не будет помещен в результате реорганизации БД. Концепция адреса хранимой записи позволяет СУБД строить собственные механизмы доступа (индексы, цепочки указателей и т.п.) на основе тех, которые обеспечиваются методом доступа. 1. Хэширование – алгоритмическое определение адреса физической записи по значению ее ключа. 2. Физический последовательный метод доступа предполагает хранение физических записей в логической последовательности. Эффективность метода доступа физической последовательности крайне низка. Для выборки нужной записи нужно просмотреть все предшествующие ей записи БД. 3. Индексно-последовательный – индексный файл упорядочивается по первичному ключу. По значению первичного ключа идентифицируется физическая запись. Индекс содержит ссылку не на каждую запись БД, а на группу записей, хранимых в физическом блоке. В физическом блоке записи хранятся в той же логической последовательности, что и индекс: (v,b) – первая запись в блоке с адресом b имеет ключ v. 4. Индексно-произвольный. При таком методе записи хранятся в произвольном порядке, и создается отдельный файл, записи которого включают значения действующего ключа и физические адреса хранимых записей: (v,a) – а – адрес записи. 5. Инвертированный используется для поиска. Хранение (обновление) с помощью других методов доступа. 6. Прямой устанавливает взаимно-однозначное соответствие между ключом записи и ее адресом.
Файлы сортируются по значению ключа. Для целых и действительных полей – это числовой порядок. Для текстовых – это лексикографический порядок. Если значение ключа состоит из нескольких полей, то сортируются в произвольном порядке. Сортированный файл называется главным, другой файл состоит из пар (v,b) – файлом индексов. Кроме выполнения операций включения, удаления, модификации с файлами индексов, нужно получать ответы на запросы следующего вида: при заданном значении ключа v1 для индексного файла найти в индексе такую запись (v2,b), что v2<v1 и либо (v2,b) является последней записью в индексе, либо следующая запись (v3,b) удовлетворяет условию v1<v3 (говорят, что v2 покрывает v1). Поиск. Пусть необходимо найти запись (v2,b) такую, что v2 покрывает заданное значение ключа v1. Используется двоичный поиск. Если задано значение ключа v1 и индекс над блоками В1, В2,…, Вn, то рассматривается средний блок Вn/2 и сравнивается v1 со значением ключа v2 в первой записи этого блока. Если v1<v2, то рассматривается В1,…, Вn/2. Если v1³v2, то процесс повторяется над блоками Вn/2,…, Вn. В конце концов для рассмотрения останется один блок. Т.к. на каждом этапе число блоков уменьшается вдвое, то не более чем за log2(n+1) шагов поиск локализуется до одного блока. Внутри блока нужная запись ищется линейным поиском. Модификация. Используется сначала поиск. Если модификация изменяет ключ, будем интерпретировать ее как удаление с последующим включением. В противном случае это перезапись данной записи. Включение записи со значением ключа v1: 1) применяется процедура поиска, чтобы найти блок Вi, в котором должна находиться эта запись; 2) если в блоке Вi есть свободное место, то все записи сдвигаются. Если места нет, то ищется свободный блок и в нем сдвигаются записи; а блок Вi смещается на блок Вi+1. Если Вi последний блок, то создается новый блок. Удаление аналогично включению. Адрес – идентификация месторасположения хранящихся данных. В реляционных СУБД обычно используются два основных метода доступа к данным: последовательный и поиск по индексу. При последовательном поиске данных осуществляется перебор всех записей файла БД. Для поиска по индексу предварительно необходимо создать вспомогательный индексный файл. Индексный файл содержит номера записей файла БД или комбинацию нескольких полей. В случае использования индексного файла поиск заданного значения поля (или комбинации полей) выполняется с помощью номеров записей индексного файла с использованием метода деления отрезка пополам, что значительно ускоряет этот процесс. С одним файлом БД может быть связано несколько индексных файлов, что позволяет осуществлять поиска по различным полям (или их комбинациям).
Структуру файлов рассмотрим на примере dbf (FoxPro, Clipper, dBase). Большинство СУБД и интегрированных пакетов имеют средства экспорта и импорта этих файлов.
32 0÷255 записи, байта терм. символ имеют fix длину Дескриптор содержит: а) имя поля; б) тип (используются коды ASCII символов C, N, F, D (дата), L, M); в) длина поля. Список записей. Каждая запись начинается с односимвольного флага удаления записи (‘ ‘ – не удалена, ‘*’ – удалена). За флагом удаления идут значения полей записи БД в том порядке, как они следуют в списке дескрипторов. Специальных символов разграничения полей нет.
ОПТИМИЗАЦИЯ ЗАПРОСОВ. Ответ на запрос, написанный на языке МД (SQL, QBR и т.д.), иногда требует достаточно много времени. Время исполнения запросов может быть в достаточной степени сокращено, если процессор ЯЗ перефразирует запрос перед его исполнением. Такой процесс называется оптимизацией, этот перефразированный запрос не обязательно является оптимальным из всех возможных способов его реализации. Оптимизация запросов равносильна оптимизации выражений РА и РИ. Особенно важное значение имеет исследование выражений, которое включает соединение или декартово произведение с последующими операциями селекции и проекции. Непосредственное выполнение операций требует достаточно много времени. Пример: R( A B ), S( C D ). Выполнить (n) (m)
В: С:
Декартово произведение R´S R(AB) S(CD) Надо организовать просмотр файла ФR, реализовать отношение R, и для каждой записи ZR, соответствующей кортежу t, надо просматривать весь файл ФS. При этом строится конкатенация записи ZR с каждой записью ZS. Соединение Общие стратегии оптимизации: 1) Выполнить операции селекции по возможности раньше. 2) Целесообразно предварительно, перед выполнением операции соединения (или декартова произведения с последующей селекцией), сделать сортировку или индексирование файла. Если сделать индексы по В и С, то время вычисления R´S будет линейно зависимо от обоих отношений. При сортировке R по В и S по С, надо просматривать каждый файл один раз для поиска записей, удовлетворяющих условию B<C. В: 5, 10, 15 fix B и С: 1, 3, 4, 15, 20 двигаться по С 3) Искать общие подвыражения в выражении. Если результат общего подвыражения представляет собой не
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2017-01-25; просмотров: 251; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.12.34.96 (0.014 с.) |

 , то
, то 
 , и для некоторого
, и для некоторого 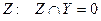 , то имеем
, то имеем 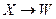
 со схемой
со схемой  удовлетворяет многозначной зависимости
удовлетворяет многозначной зависимости 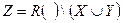 , то
, то  .
. подмножества
подмножества  .
.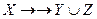
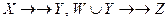 , то
, то 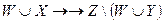

 множество зависимостей.
множество зависимостей.  .
.  содержит ключ отношения
содержит ключ отношения  , то оно находится и в НФБК относительно множества функциональных зависимостей
, то оно находится и в НФБК относительно множества функциональных зависимостей  ,
,  .
.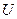 – множество всех атрибутов. Тогда можно построить разбиение
– множество всех атрибутов. Тогда можно построить разбиение  на множествах
на множествах  такое, что при
такое, что при  имеем
имеем 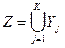
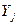 называются базисом зависимостей для
называются базисом зависимостей для  объединением базисов)
объединением базисов) , заданное на множестве атрибутов
, заданное на множестве атрибутов  .
. множество всех подмножеств множества
множество всех подмножеств множества  такого, что
такого, что  имеем
имеем  и
и  есть либо
есть либо  .
. не превратится в совокупность не пересекающихся множеств, будем находить в нем очередную пару не пересекающихся множеств
не превратится в совокупность не пересекающихся множеств, будем находить в нем очередную пару не пересекающихся множеств 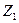 и
и  , и заменять ее множествами
, и заменять ее множествами  ,
,  ,
,  , отбрасывая пустое множество в том случае, если одно из
, отбрасывая пустое множество в том случае, если одно из  .
.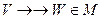 , и некоторое множество
, и некоторое множество 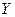 в
в 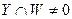 ;
;  . Заменяем
. Заменяем  и
и  .
. – декомпозиция
– декомпозиция  Тогда
Тогда  обладает свойством соединения без потерь т. и т.т., когда имеет место многозначная зависимость
обладает свойством соединения без потерь т. и т.т., когда имеет место многозначная зависимость  (или по пр. дополнения
(или по пр. дополнения  ).
). экземпляры
экземпляры экземпляры
экземпляры


 Самара
Самара
 Ульяновск
Ульяновск
 Москва
Москва



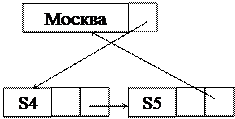





 Самара 1 10
Самара 1 10


 Москва 2
Москва 2
 Ульяновск 3 20
Ульяновск 3 20 4
4





 (хэш-функция) от значения некоторого ключа в этом экземпляре записи – обычно значения первичного ключа:
(хэш-функция) от значения некоторого ключа в этом экземпляре записи – обычно значения первичного ключа:  ,
,  значение ключа.
значение ключа.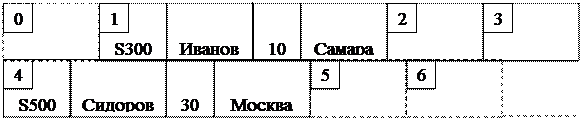



 операций.
операций. – количество операций уменьшается сортировкой.
– количество операций уменьшается сортировкой.




