Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Формальные грамматики и языки.Содержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте
Формальные грамматики и языки. Элементы теории трансляции.
(издание второе, переработанное и дополненное)
1999 УДК 519.682.1+681.142.2
Приводятся основные определения, понятия и алгоритмы теории формальных грамматик и языков, некоторые методы трансляции, а также наборы задач по каждой из рассматриваемых тем. Излагаемые методы трансляции проиллюстрированы на примере модельного языка.
Во втором издании исправлены неточности и ошибки первого издания, расширен набор задач: номера первого издания сохранены, но появились дополнительные пункты, отмеченные малыми латинскими буквами. Все новые или измененные задачи отмечены звездочкой.
Для студентов факультета ВМК в поддержку основного лекционного курса “Системное программное обеспечение” и для преподавателей, ведущих практические занятия по этому курсу.
Авторы выражают благодарность Пильщикову В.Н. за предоставленные материалы по курсу “Системное программное обеспечение”, ценные советы и замечания при подготовке пособия, а также благодарят Баландина К.А. за большую помощь в оформлении работы.
Рецензенты: проф. Жоголев Е.А. доц. Корухова Л.С.
Волкова И.А., Руденко Т.В. “Формальные грамматики и языки. Элементы теории трансляции. (учебное пособие для студентов II курса)” - издание второе
Издательский отдел факультета ВМиК МГУ (лицензия ЛР №040777 от 23.07.96), 1998.-62 с.
Печатается по решению Редакционно-издательского Совета факультета вычислительной математики и кибернетики МГУ им. М.В.Ломоносова
ISBN 5-89407-032-5
Ó Издательский отдел факультета вычислительной математики и кибернетики МГУ им. М.В.Ломоносова, 1999 ЭЛЕМЕНТЫ ТЕОРИИ Введение. В этом разделе изложены некоторые аспекты теории формальных языков, существенные с точки зрения трансляции. Здесь введены базовые понятия и даны определения, связанные с одним из основных механизмов определения языков - грамматиками, приведена наиболее распространенная классификация грамматик (по Хомскому). Особое внимание уделяется контекстно-свободным грамматикам и, в частности, их важному подклассу - регулярным грамматикам. Грамматики этих классов широко используются при трансляции языков программирования. Здесь не приводятся доказательства сформулированных фактов, свойств, теорем, доказательства правильности алгоритмов; их можно найти в книгах, указанных в списке литературы.
Основные понятия и определения Определение: алфавит - это конечное множество символов. Предполагается, что термин "символ" имеет достаточно ясный интуитивный смысл и не нуждается в дальнейшем уточнении.
Определение: цепочкой символов в алфавите V называется любая конечная последовательность символов этого алфавита.
Определение: цепочка, которая не содержит ни одного символа, называется пустой цепочкой. Для ее обозначения будем использовать символ e.
Более формально цепочка символов в алфавите V определяется следующим образом: (1) e - цепочка в алфавите V; (2) если a - цепочка в алфавите V и a - символ этого алфавита, то aa - цепочка в алфавите V; (3) b - цепочка в алфавите V тогда и только тогда, когда она является таковой в силу (1) и (2).
Определение: если a и b - цепочки, то цепочка ab называется конкатенацией ( или сцеплением) цепочек a и b. Например, если a = ab и b = cd, то ab = abcd. Для любой цепочки a всегда ae = ea = a.
Определение: обращением ( или реверсом) цепочки a называется цепочка, символы которой записаны в обратном порядке. Обращение цепочки a будем обозначать aR. Например, если a = abcdef, то aR = fedcba. Для пустой цепочки: e = eR.
Определение: n-ой степенью цепочки a (будем обозначать an) называется конкатенация n цепочек a. a0 = e; an = aan-1 = an-1a.
Определение: длина цепочки - это число составляющих ее символов. Например, если a = abcdefg, то длина a равна 7. Длину цепочки a будем обозначать | a |. Длина e равна 0.
Определение: язык в алфавите V - это подмножество цепочек конечной длины в этом алфавите.
Определение: обозначим через V* множество, содержащее все цепочки в алфавите V, включая пустую цепочку e. Например, если V={0,1}, то V* = {e, 0, 1, 00, 11, 01, 10, 000, 001, 011,...}.
Определение: обозначим через V+ множество, содержащее все цепочки в алфавите V, исключая пустую цепочку e. Следовательно, V* = V+ È {e}.
Ясно, что каждый язык в алфавите V является подмножеством множества V*.
Известно несколько различных способов описания языков [3]. Один из них использует порождающие грамматики. Именно этот способ описания языков чаще всего будет использоваться нами в дальнейшем.
Определение: декартовым произведением A ´ B множеств A и B называется множество { (a,b) | a Î A, b Î B}.
Определение: порождающая грамматика G - это четверка (VT, VN, P, S), где VT - алфавит терминальных символов (терминалов), VN - алфавит нетерминальных символов (нетерминалов), не пересекаю- P - конечное подмножество множества (VT È VN)+ ´ (VT È VN)*; элемент (a, b) множества P называется правилом вывода и записывается в виде a ® b, S - начальный символ (цель) грамматики, S Î VN.
Для записи правил вывода с одинаковыми левыми частями a ® b1 a ® b2... a ® bn будем пользоваться сокращенной записью a ® b1 | b2 |...| bn. Каждое bi , i = 1, 2,...,n, будем называть альтернативой правила вывода из цепочки a.
Пример грамматики: G1 = ({0,1}, {A,S}, P, S), где P состоит из правил S ® 0A1 0A ® 00A1 A ® e
Определение: цепочка b Î (VT È VN)* непосредственно выводима из цепочки a Î (VT È VN)+ в грамматике G = (VT, VN, P, S) (обозначим a ® b), если a = x1gx2, b = x1dx2, где x1, x2, d Î (VT È VN)*, g Î (VT È VN)+ и правило вывода Например, цепочка 00A11 непосредственно выводима из 0A1 в грамматике G1.
Определение: цепочка b Î (VT È VN)* выводима из цепочки
Определение: последовательность g0, g1,..., gn называется выводом длины n.
Например, S Þ 000A111 в грамматике G1 (см. пример выше), т.к. существует вывод S ® 0A1 ® 00A11 ® 000A111. Длина вывода равна 3.
Определение: языком, порождаемым грамматикой G = (VT, VN, P, S), называется множество L(G) = {a Î VT* | S Þ a}. Другими словами, L(G) - это все цепочки в алфавите VT, которые выводимы из S с помощью P. Например, L(G1) = {0n1n | n>0}.
Определение: цепочка a Î (VT È VN)*, для которой S Þ a, называется сентенциальной формой в грамматике G = (VT, VN, P, S).
Таким образом, язык, порождаемый грамматикой, можно определить как множество терминальных сентенциальных форм.
Определение: грамматики G1 и G2 называются эквивалентными, если Например, G1 = ({0,1}, {A,S}, P1, S) и G2 = ({0,1}, {S}, P2, S) P1: S ® 0A1 P2: S ® 0S1 | 01 0A ® 00A1 A ® e эквивалентны, т.к. обе порождают язык L(G1) = L(G2) = {0n1n | n>0}.
Определение: грамматики G1 и G2 почти эквивалентны, если Другими словами, грамматики почти эквивалентны, если языки, ими порождаемые, отличаются не более, чем на e.
Например, G1 = ({0,1}, {A,S}, P1, S) и G2 = ({0,1}, {S}, P2, S) P1: S ® 0A1 P2: S ® 0S1 | e 0A ® 00A1 A ® e почти эквивалентны, т.к. L(G1)={0n1n | n>0}, а L(G2)={0n1n | n>=0}, т.е. L(G2) состоит из всех цепочек языка L(G1) и пустой цепочки, которая в L(G1) не входит. Примеры грамматик и языков. Замечание: если при описании грамматики указаны только правила вывода Р, то будем считать, что большие латинские буквы обозначают нетерминальные символы, S - цель грамматики, все остальные символы - терминальные.
1) Язык типа 0: L(G) = {a2 G: S ® aaCFD F ® AFB | AB AB ® bBA Ab ® bA AD ® D Cb ® bC CB ® C bCD ® e
2) Язык типа 1: L(G) = { an bn cn, n >= 1} G: S ® aSBC | abC CB ® BC bB ® bb bC ® bc cC ® cc
3) Язык типа 2: L(G) = {(ac)n (cb)n | n > 0} G: S ® aQb | accb Q ® cSc
4) Язык типа 3: L(G) = {w ^ | w Î {a,b}+, где нет двух рядом стоящих а} G: S ® A^ | B^ A ® a | Ba B ® b | Bb | Ab
Разбор цепочек
Цепочка принадлежит языку, порождаемому грамматикой, только в том случае, если существует ее вывод из цели этой грамматики. Процесс построения такого вывода (а, следовательно, и определения принадлежности цепочки языку) называется разбором. С практической точки зрения наибольший интерес представляет разбор по контекстно-свободным (КС и УКС) грамматикам. Их порождающей мощности достаточно для описания большей части синтаксической структуры языков программирования, для различных подклассов КС-грамматик имеются хорошо разработанные практически приемлемые способы решения задачи разбора.
Рассмотрим основные понятия и определения, связанные с разбором по КС-грамматике.
Определение: вывод цепочки b Î (VT)* из S Î VN в КС-грамматике
Определение: вывод цепочки b Î (VT)* из S Î VN в КС-грамматике
В грамматике для одной и той же цепочки может быть несколько выводов, эквивалентных в том смысле, что в них в одних и тех же местах применяются одни и те же правила вывода, но в различном порядке.
Например, для цепочки a+b+a в грамматике G = ({a,b,+}, {S,T}, {S ® T | T+S; T ® a | b}, S) можно построить выводы: (1) S®T+S®T+T+S®T+T+T®a+T+T®a+b+T®a+b+a (2) S®T+S®a+S®a+T+S®a+b+S®a+b+T®a+b+a (3) S®T+S®T+T+S®T+T+T®T+T+a®T+b+a®a+b+a
Здесь (2) - левосторонний вывод, (3) - правосторонний, а (1) не является ни левосторонним, ни правосторонним, но все эти выводы являются эквивалентными в указанном выше смысле.
Для КС-грамматик можно ввести удобное графическое представление вывода, называемое деревом вывода, причем для всех эквивалентных выводов деревья вывода совпадают.
Определение: дерево называется деревом вывода ( или деревом разбора) в КС-грамматике G = {VT, VN, P, S), если выполнены следующие условия: (1) каждая вершина дерева помечена символом из множества (VN È VT È e), при этом корень дерева помечен символом S; листья - символами из (VT È e); (2) если вершина дерева помечена символом A Î VN, а ее непосредственные потомки - символами a1, a2,..., an, где каждое ai Î (VT È VN), то A ® a1a2...an - правило вывода в этой грамматике; (3) если вершина дерева помечена символом A Î VN, а ее единственный непосредственный потомок помечен символом e, то A ® e - правило вывода в этой грамматике.
Пример дерева вывода для цепочки a+b+a в грамматике G:
Определение: КС-грамматика G называется неоднозначной, если существует хотя бы одна цепочка a Î L(G), для которой может быть построено два или более различных деревьев вывода. Это утверждение эквивалентно тому, что цепочка a имеет два или более разных левосторонних (или правосторонних) выводов.
Определение: в противном случае грамматика называется однозначной.
Определение: язык, порождаемый грамматикой, называется неоднозначным, если он не может быть порожден никакой однозначной грамматикой.
Пример неоднозначной грамматики: G = ({if, then, else, a, b}, {S}, P, S), где P = {S ® if b then S else S | if b then S | a}.
В этой грамматике для цепочки if b then if b then a else a можно построить два различных дерева вывода.
Однако это не означает, что язык L(G) обязательно неоднозначный. Определенная нами неоднозначность - это свойство грамматики, а не языка, т.е. для некоторых неоднозначных грамматик существуют эквивалентные им однозначные грамматики. Если грамматика используется для определения языка программирования, то она должна быть однозначной. В приведенном выше примере разные деревья вывода предполагают соответствие else разным then. Если договориться, что else должно соответствовать ближайшему к нему then, и подправить грамматику G, то неоднозначность будет устранена: S ® if b then S | if b then S’ else S | a S’ ® if b then S’ else S’ | a
Проблема, порождает ли данная КС-грамматика однозначный язык (т.е. существует ли эквивалентная ей однозначная грамматика), является алгоритмически неразрешимой.
Однако можно указать некоторые виды правил вывода, которые приводят к неоднозначности: (1) A ® AA | a (2) A ® AaA | b (3) A ® aA | Ab | g (4) A ® aA | aAbA | g
Пример неоднозначного КС-языка: L = {ai bj ck | i = j или j = k}.
Интуитивно это объясняется тем, что цепочки с i = j должны порождаться группой правил вывода, отличных от правил, порождающих цепочки с j = k. Но тогда, по крайней мере, некоторые из цепочек с i = j = k будут порождаться обеими группами правил и, следовательно, будут иметь по два разных дерева вывода. Доказательство того, что КС-язык L неоднозначный, приведен в [3, стр. 235-236].
Одна из грамматик, порождающих L, такова: S ® AB | DC A ® aA | e B ® bBc | e C ® cC | e D ® aDb | e Очевидно, что она неоднозначна.
Дерево вывода можно строить нисходящим либо восходящим способом.
При нисходящем разборе дерево вывода формируется от корня к листьям; на каждом шаге для вершины, помеченной нетерминальным символом, пытаются найти такое правило вывода, чтобы имеющиеся в нем терминальные символы “проектировались” на символы исходной цепочки. Метод восходящего разбора заключается в том, что исходную цепочку пытаются “свернуть” к начальному символу S; на каждом шаге ищут подцепочку, которая совпадает с правой частью какого-либо правила вывода; если такая подцепочка находится, то она заменяется нетерминалом из левой части этого правила. Если грамматика однозначная, то при любом способе построения будет получено одно и то же дерево разбора.
Преобразования грамматик
В некоторых случаях КС-грамматика может содержать недостижимые и бесплодные символы, которые не участвуют в порождении цепочек языка и поэтому могут быть удалены из грамматики.
Определение: символ x Î (VT È VN) называется недостижимым в грамматике G = (VT, VN, P, S), если он не появляется ни в одной сентенциальной форме этой грамматики.
Алгоритм удаления недостижимых символов: Вход: КС-грамматика G = (VT, VN, P, S) Выход: КС-грамматика G’ = (VT’, VN’, P’, S), не содержащая недостижимых символов, для которой L(G) = L(G’). Метод: 1. V0 = {S}; i = 1. 2. Vi = {x | x Î (VT È VN), в P есть A®axb и AÎVi-1, a,bÎ(VTÈVN)*} È Vi-1. 3. Если Vi ¹ Vi-1, то i = i + 1 и переходим к шагу 2, иначе VN’ = Vi Ç VN;
Определение: символ A Î VN называется бесплодным в грамматике
Алгоритм удаления бесплодных символов: Вход: КС-грамматика G = (VT, VN, P, S). Выход: КС-грамматика G’ = (VT, VN’, P’, S), не содержащая бесплодных символов, для которой L(G) = L(G’). Метод: Рекурсивно строим множества N0, N1,... 1. N0 = Æ, i = 1. 2. Ni = {A | (A ® a) Î P и a Î (Ni-1 È VT)*} È Ni-1. 3. Если Ni ¹ Ni-1, то i = i + 1 и переходим к шагу 2, иначе VN’ = Ni; P’ состоит из правил множества P, содержащих только символы из VN’ È VT; G’ = (VT, VN’, P’, S). Определение: КС-грамматика G называется приведенной, если в ней нет недостижимых и бесплодных символов.
Алгоритм приведения грамматики:
(1) обнаруживаются и удаляются все бесплодные нетерминалы. (2) обнаруживаются и удаляются все недостижимые символы. Удаление символов сопровождается удалением правил вывода, содержащих эти символы.
Замечание: е сли в этом алгоритме переставить шаги (1) и (2), то не всегда результатом будет приведенная грамматика.
Для описания синтаксиса языков программирования стараются использовать однозначные приведенные КС-грамматики.
Задачи. 1. Дана грамматика. Построить вывод заданной цепочки.
a) S ® T | T+S | T-S b) S ® aSBC | abC T ® F | F*T CB ® BC F ® a | b bB ® bb Цепочка a-b*a+b bC ® bc cC ® cc Цепочка aaabbbccc
2. Построить все сентенциальные формы для грамматики с правилами:
S ® A+B | B+A A ® a B ® b
3. К какому типу по Хомскому относится данная грамматика? Какой язык она порождает? Каков тип языка?
a) S ® APA b) S ® aQb | e P ® + | - Q ® cSc A ® a | b
c) S ® 1B d) S ® A | SA | SB B ® B0 | 1 A ® a B ® b
4. Построить грамматику, порождающую язык:
a) L = { an bm | n, m >= 1} b) L = { acbcgc | a, b, g - любые цепочки из a и b} c) L = { a1 a2... an an... a2 a1 | ai = 0 или 1, n >= 1} d) L = { an bm | n ¹ m; n, m >= 0} e) L = { цепочки из 0 и 1 с неравным числом 0 и 1} f) L = { aa | a Î {a,b}+} g) L = { w | w Î {0,1}+ и содержит равное количество 0 и 1, причем любая подцепочка, взятая с левого конца, содержит единиц не меньше, чем нулей}. h) L = { (a2m bm)n | m >= 1, n >= 0} i) L = { j) L = { k) L = {
5. К какому типу по Хомскому относится данная грамматика? Какой язык она порождает? Каков тип языка?
a) S ® a | Ba b) S ® Ab B ® Bb | b A ® Aa | ba
c) S ® 0A1 | 01 d) S ® AB 0A ® 00A1 AB ® BA A ® 01 A ® a B ® b
*e) S ® A | B *f) S ® 0A | 1S A ® aAb | 0 A ® 0A | 1B B ® aBbb | 1 B ® 0B | 1B | ^
*g) S ® 0S | S0 | D *h) S ® 0A | 1S | e D ® DD | 1A | e A ® 1A | 0B A ® 0B | e B ® 0S | 1B B ® 0A | 0
*i) S ® SS | A *j) S ® AB^ A ® a | bb A ® a | cA B ® bA
*k) S ® aBA | e *l) S ® Ab | c B ® bSA A ® Ba AA ® c B ® cS
6. Эквивалентны ли грамматики с правилами:
а) S ® AB и S ® AS | SB | AB A ® a | Aa A ® a B ® b | Bb B ® b
b) S ® aSL | aL и S ® aSBc | abc L ® Kc cB ® Bc cK ® Kc bB ® bb K ® b
7. Построить КС-грамматику, эквивалентную грамматике с правилами:
а) S ® aAb b) S ® AB | ABS aA ® aaAb AB ® BA A ® e BA ® AB A ® a B ® b
8. Построить регулярную грамматику, эквивалентную грамматике с правилами:
а) S ® A | AS b) S ® A. A A ® a | bb A ® B | BA B ® 0 | 1
9. Доказать, что грамматика с правилами:
S ® aSBC | abC CB ® BC bB ® bb bC ® bc cC ® cc порождает язык L = {an bn cn | n >= 1}. Для этого показать, что в данной грамматике 1) выводится любая цепочка вида an bn cn (n >= 1) и 2) не выводятся никакие другие цепочки.
10. Дана грамматика с правилами:
a) S ® S0 | S1 | D0 | D1 b) S ® if B then S | B = E D ® H. E ® B | B + E H ® 0 | 1 | H0 | H1 B ® a | b
Построить восходящим и нисходящим методами дерево вывода для цепочки: a) 10.1001 b) if a then b = a+b+b
11. Определить тип грамматики. Описать язык, порождаемый этой грамматикой. Написать для этого языка КС-грамматику.
S ® P^ P ® 1P1 | 0P0 | T T ® 021 | 120R R1 ® 0R R0 ® 1 R^® 1^
12. Построить регулярную грамматику, порождающую цепочки в алфавите
13. Написать КС-грамматику для языка L, построить дерево вывода и левосторонний вывод для цепочки aabbbcccc.
L = {a2n bm c2k | m=n+k, m>1}.
14. Построить грамматику, порождающую сбалансированные относительно круглых скобок цепочки в алфавите { a, (,), ^ }. Сбалансированную цепочку a определим рекуррентно: цепочка a сбалансирована, если a) a не содержит скобок, b) a = (a1) или a= a1 a2, где a1 и a2 сбалансированы.
15. Написать КС-грамматику, порождающую язык L, и вывод для цепочки aacbbbcaa в этой грамматике.
L = {an cbm can | n, m>0}.
16. Написать КС-грамматику, порождающую язык L, и вывод для цепочки 110000111 в этой грамматике.
L = {1n 0m 1p | n+p>m; n, p, m>0}.
17. Дана грамматика G. Определить ее тип; язык, порождаемый этой грамматикой; тип языка.
G: S ® 0A1 0A ® 00A1 A ® e
18. Дан язык L = {13n+2 0n | n>=0}. Определить его тип, написать грамматику, порождающую L. Построить левосторонний и правосторонний выводы, дерево разбора для цепочки 1111111100.
19. Привести пример грамматики, все правила которой имеют вид
20. Написать общие алгоритмы построения по данным КС-грамматикам G1 и G2, порождающим языки L1 и L2, КС-грамматики для a) L1ÈL2 b) L1 * L2 c) L1*
Замечание: L =L1 * L2 - это конкатенация языков L1 и L2, т.е.L = { ab | a Î L1, b Î L2}; L = L1* - это итерация языка L1, т.е. объединение {e} È L1 È L1*L1 È L1*L1*L1 È...
21. Написать КС-грамматику для L={wi 2 wi+1R | i Î N, wi=(i)2 - двоичное представление числа i, wR - обращение цепочки w}. Написать КС-грамматику для языка L* (см. задачу 20).
22. Показать, что грамматика E ® E+E | E*E | (E) | i неоднозначна. Как описать этот же язык с помощью однозначной грамматики?
23. Показать, что наличие в КС-грамматике правил вида a) A ® AA | a b) A ® AaA | b c) A ® aA | Ab | g где a, b, g Î (VTÈVN)*, A Î VN, делает ее неоднозначной. Можно ли преобразовать эти правила таким образом, чтобы полученная эквивалентная грамматика была однозначной?
*24. Показать, что грамматика G неоднозначна. Какой язык она порождает? Является ли этот язык однозначным? G: S ® aAc | aB B ® bc A ® b
25. Дана КС-грамматика G={VT, VN, P, S}. Предложить алгоритм построения множества X={A Î VN | A Þ e}.
26. Для произвольной КС-грамматики G предложить алгоритм, определяющий, пуст ли язык L(G).
27. Написать приведенную грамматику, эквивалентную данной.
a) S ® aABS | bCACd b) S ® aAB | E A ® bAB | cSA | cCC A ® dDA | e B ® bAB | cSB B ® bE | f C ® cS | c C ® cAB | dSD | a D ® eA E ® fA | g
28. Язык называется распознаваемым, если существует алгоритм, который за конечное число шагов позволяет получить ответ о принадлежности любой цепочки языку. Если число шагов зависит от длины цепочки и может быть оценено до выполнения алгоритма, язык называется легко распознаваемым. Доказать, что язык, порождаемый неукорачивающей грамматикой, легко распознаваем.
29. Доказать, что любой конечный язык, в который не входит пустая цепочка, является регулярным языком.
30. Доказать, что нециклическая КС-грамматика порождает конечный язык. Замечание: Нетерминальный символ A Î VN - циклический, если в грамматике существует вывод A Þ x1Ax2. КС-грамматика называется циклической, если в ней имеется хотя бы один циклический символ.
31. Показать, что условие цикличности грамматики (см. задачу 30) не является достаточным условием бесконечности порождаемого ею языка.
32. Доказать, что язык, порождаемый циклической приведенной КС-грамматикой, содержащей хотя бы один эффективный циклический символ, бесконечен. Замечание: Циклический символ называется эффективным, если A Þ aAb, где |aAb| > 1; иначе циклический символ называется фиктивным.
ЭЛЕМЕНТЫ ТЕОРИИ ТРАНСЛЯЦИИ Введение. В этом разделе будут рассмотрены некоторые алгоритмы и технические приемы, применяемые при построении трансляторов. Практически во всех трансляторах (и в компиляторах, и в интерпретаторах) в том или ином виде присутствует большая часть перечисленных ниже процессов: à лексический анализ à синтаксический анализ à семантический анализ à генерация внутреннего представления программы à оптимизация à генерация объектной программы. В конкретных компиляторах порядок этих процессов может быть несколько иным, некоторые из них могут объединяться в одну фазу, другие могут выполнятся в течение всего процесса компиляции. В интерпретаторах и при смешанной стратегии трансляции некоторые этапы могут вообще отсутствовать. В этом разделе мы рассмотрим некоторые методы, используемые для построения анализаторов (лексического, синтаксического и семантического), язык промежуточного представления программы, способ генерации промежуточной программы, ее интерпретации. Излагаемые алгоритмы и методы иллюстрируются на примере модельного паскалеподобного языка (М-языка). Все алгоритмы записаны на Си. Информацию о других методах, алгоритмах и приемах, используемых при создании трансляторов, можно найти в [1, 2, 3, 4, 5, 8].
Описание модельного языка
P ® program D1; B^ D1 ® var D {,D} D ® I {,I}: [ int | bool ] B ® begin S {;S} end S ® I:= E | if E then S else S | while E do S | B | read (I) | write (E) E ® E1 [ = | < | > |!= ] E1 | E1 E1 ® T {[ + | - | or ] T} T ® F {[ * | / | and ] F} F ® I | N | L | not F | (E) L ® true | false I ® C | IC | IR N ® R | NR C ® a | b |... | z | A | B |... | Z R ® 0 | 1 | 2 |... | 9 Замечание: a) запись вида {a} означает итерацию цепочки a, т.е. в порождаемой цепочке в этом месте может находиться либо e, либо a, либо aa, либо aaa и т.д. b) запись вида [ a | b ] означает, что в порождаемой цепочке в этом месте может находиться либо a, либо b. c) P - цель грамматики; символ ^ - маркер конца текста программы.
Контекстные условия:
1. Любое имя, используемое в программе, должно быть описано и только один раз. 2. В операторе присваивания типы переменной и выражения должны совпадать. 3. В условном операторе и в операторе цикла в качестве условия возможно только логическое выражение. 4. Операнды операции отношения должны быть целочисленными. 5. Тип выражения и совместимость типов операндов в выражении определяются по обычным правилам; старшинство операций задано синтаксисом.
В любом месте программы, кроме идентификаторов, служебных слов и чисел, может находиться произвольное число пробелов и комментариев вида {< любые символы, кроме } и ^ >}. True, false, read и write - служебные слова (их нельзя переопределять, как стандартные идентификаторы Паскаля). Сохраняется паскалевское правило о разделителях между идентификаторами, числами и служебными словами. Лексический анализ Рассмотрим методы и средства, которые обычно используются при построении лексических анализаторов. В основе таких анализаторов лежат регулярные грамматики, поэтому рассмотрим грамматики этого класса более подробно.
Соглашение: в дальнейшем, если особо не оговорено, под регулярной грамматикой будем понимать леволинейную грамматику. Напомним, что грамматика G = (VT, VN, P, S) называется леволинейной, если каждое правило из Р имеет вид A ® Bt либо A ® t, где A Î VN, B Î VN, t Î VT.
Соглашение: предположим, что анализируемая цепочка заканчивается специальным символом ^ - признаком конца цепочки.
Для грамматик этого типа существует алгоритм определения того, принадлежит ли анализируемая цепочка языку, порождаемому этой грамматикой (алгоритм разбора): (1) первый символ исходной цепочки a1a2...an^ заменяем нетерминалом A, для которого в грамматике есть правило вывода A ® a1 (другими словами, производим "свертку" терминала a1 к нетерминалу A) (2) затем многократно (до тех пор, пока не считаем признак конца цепочки) выполняем следующие шаги: полученный на предыдущем шаге нетерминал A и расположенный непосредственно справа от него очередной терминал ai исходной цепочки заменяем нетерминалом B, для которого в грамматике есть правило вывода B ® Aai (i = 2, 3,.., n);
Это эквивалентно построению дерева разбора методом "снизу-вверх": на каждом шаге алгоритма строим один из уровней в дереве разбора, "поднимаясь" от листьев к корню.
При работе этого алгоритма возможны следующие ситуации:
(1) прочитана вся цепочка; на каждом шаге находилась единственная нужная "свертка"; на последнем шаге свертка произошла к символу S. Это означает, что исходная цепочка a1a2...an^ Î L(G). (2) прочитана вся цепочка; на каждом шаге находилась единственная нужная "свертка"; на последнем шаге свертка произошла к символу, отличному от S. Это означает, что исходная цепочка a1a2...an^ Ï L(G). (3) на некотором шаге не нашлось нужной свертки, т.е. для полученного на предыдущем шаге нетерминала A и расположенного непосредственно справа от него очередного терминала ai исходной цепочки не нашлось нетерминала B, для которого в грамматике было бы правило вывода B ® Aai. Это означает, что исходная цепочка a1a2...an^ Ï L(G). (4) на некотором шаге работы алгоритма оказалось, что есть более одной подходящей свертки, т.е. в грамматике разные нетерминалы имеют правила вывода с одинаковыми правыми частями, и поэтому непонятно, к какому из них производить свертку. Это говорит о недетерминированности разбора. Анализ этой ситуации будет дан ниже.
Допустим, что разбор на каждом шаге детерминированный.
Для того, чтобы быстрее находить правило с подходящей правой частью, зафиксируем все возможные свертки (это определяется только грамматикой и не зависит от вида анализируемой цепочки).
Это можно сделать в виде таблицы, строки которой помечены нетерминальными символами грамматики, столбцы - терминальными. Значение каждого элемента таблицы - это нетерминальный символ, к которому можно свернуть пару "нетерминал-терминал", которыми помечены соответствующие строка и столбец.
Например, для грамматики G = ({a, b, ^}, {S, A, B, C}, P, S), такая таблица будет выглядеть следующим образом:
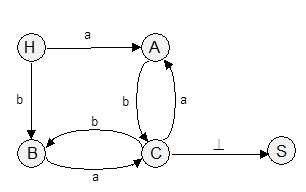
Знак "-" ставится в том случае, если для пары "терминал-нетерминал" свертки нет. Но чаще информацию о возможных свертках представляют в виде диаграммы состояний (ДС) - неупорядоченного ориентированного помеченного графа, который строится следующим образом: (1) строят вершины графа, помеченные нетерминалами грамматики (для каждого нетерминала - одну вершину), и еще одну вершину, помеченную символом, отличным от нетерминальных (например, H). Эти вершины будем называть состояниями. H - начальное состояние. (2) соединяем эти состояния дугами по следующим правилам: a) для каждого правила грамматики вида W ® t соединяем дугой состояния H и W (от H к W) и помечаем дугу символом t; б) для каждого правила W ® Vt соединяем дугой состояния V и W (от V к W) и помечаем дугу символом t;
Диаграмма состояний для грамматики G (см. пример выше):
Алгоритм разбора по диаграмме состояний: (1) объявляем текущим состояние H; (2) затем многократно (до тех пор, пока не считаем признак конца цепочки) выполняем следующие шаги: считываем очередной символ исходной цепочки и переходим из текущего состояния в другое состояние по дуге, помеченной этим символом. Состояние, в которое мы при этом попадаем, становится текущим.
При работе этого алгоритма возможны следующие ситуации (аналогичные ситуациям, которые возникают при разборе непосредственно по регулярной грамматике): (1) прочитана вся цепочка; на каждом шаге находилась единственная дуга, помеченная очередным символом анализируемой цепочки; в результате последнего перехода оказались в состоянии S. Это означает, что исходная цепочка принадлежит L(G). (2) прочитана вся цепочка; на каждом шаге находилась единственная "нужная" дуга; в результате последнего шага оказались в состоянии, отличном от S. Это означает, что исходная цепочка не принадлежит L(G). (3) на некотором шаге не нашлось дуги, выходящей из текущего состояния и помеченной очередным анализируемым символом. Это означает, что исходная цепочка не принадлежит L(G). (4) на некотором шаге работы алгоритма оказалось, что есть несколько дуг, выходящих из текущего состояния, помеченных очередным анализируемым символом, но ведущих в разные состояния. Это говорит о недетерминированности разбора. Анализ этой ситуации будет приведен ниже.
Диаграмма состояний определяет конечный автомат, построенный по регулярной грамматике, который допускает множество цепочек, составляющих язык, определяемый этой грамматикой. Состояния и дуги ДС - это графическое изображение функции переходов конечного автомата из состояния в состояние при условии, что очередной анализируемый символ совпадает с символом-меткой дуги. Среди всех состояний выделяется начальное (считается, что в начальный момент своей работы автомат находится в этом состоянии) и конечное (если автомат завершает работу переходом в это состояние, то анализируемая цепочка им допускается).
Определение: конечный автомат (КА) - это пятерка (K, VT, F, H, S), где K - конечное множество состояний; VT - конечное множество допустимых входных символов; F - отображение множества K ´ VT ® K, определяющее поведение автомата; отображение F часто называют функцией переходов; H Î K - начальное состояние; S Î K - заключительное состояние (либо конечное множество заключительных состояний).
F(A, t) = B означает, что из состояния A по входному символу t происходит переход в состояние B.
Определение: конечный автомат допускает цепочку a1a2...an, если F(H,a1) = A1; F(A1,a2) = A2;...; F(An-2,an-1) = An-1; F(An-1,an) = S, где ai Î VT, Aj Î K,
Определение: множество цепочек, допускаемых конечным автоматом, составляет определяемый им язык.
Для более удобной работы с диаграммами состояний введем несколько соглашений: a) есл
|
|||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-12-30; просмотров: 443; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.147.103.33 (0.012 с.) |

 | n >= 1}
| n >= 1}
 ^ | n >= 1}
^ | n >= 1} | n >= 1}
| n >= 1} | n >= 1}
| n >= 1}