Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Системы оперативной обработки информацииСодержание книги Похожие статьи вашей тематики
Поиск на нашем сайте
Хранение информации Хранение информации – важнейшая составляющая ИТ. Информацию необходимо хранить, защищать, оптимизировать, управлять ею. Информационное содержание - информационные объекты, хранящиеся в различных форматах, которые можно извлекать, повторно использовать и публиковать. Содержание характеризуется как "неструктурированная" информация, в том числе текст, изображения, офисная документация, графические данные, чертежи, веб-страницы, сообщения электронной почты, видео- и аудиофайлы и другие мультимедийные активы. Традиционно содержание хранилось в виде бумажных документов, на микропленке и других нецифровых носителях. Сегодня все большие объемы содержания хранятся в цифровом формате, включая динамическое содержание на веб-сайтах (в том числе в корпоративном интранете и экстранете), мобильных телефонах, Интернет-телевидении, КПК и пейджерах. В информационном обществе все больше информации создается частными лицами, а не предприятиями. Эта информация приобретает ценность при обмене с другими людьми (общение в социальных сетях, отправка электронной почты, обмен фото и видео). В момент создания информация обычно размещается в мобильных телефонах, камерах, ноутбуках. Для обмена ее нужно загружать через сеть в центры хранения данных. Хранение и управление этой информацией осуществляет относительно небольшое число организаций. В мире бизнеса значимость, взаимосвязанность и объем информации также стремительно растет. В бизнесе данные используются для извлечения информации, необходимой для деловых операций. Некоторые коммерческие приложения по обработке информации включают системы бронирования билетов, рассылки счетов, электронную коммерцию, использование банкоматов, проектирование изделий, управление снабжением, архивами электронной почты, веб-порталами, базами данных клиентов, пластиковыми картами, рынком ценных бумаг и т.п. Рост значимости информации для бизнеса усилил потребность в защите и управлении данными. Теперь для информационных центров хранение информации становится приоритетной задачей. Хранилище данных представляет собой репозиторий, дающий пользователям возможность хранения и извлечения цифровых данных. Билл Инмон (1989г.): " Хранилище данных (Data Warehouse) - это предметно-ориентированное, привязанное ко времени и неизменяемое собрание данных для поддержки процесса принятия управляющих решений". СИСТЕМЫ ОПЕРАТИВНОЙ ОБРАБОТКИ ИНФОРМАЦИИ OLTP (On-Line Transaction Processing — оперативная, т.е. в режиме реального времени, обработка транзакций). Транзакция — некоторый набор операций над базой данных, который рассматривается как единое завершенное, с точки зрения пользователя, действие над некоторой информацией, обычно связанное с обращением к базе данных.
Хранилища данных Со временем важность и значимость данных меняется. Значимость большей части создаваемых данных носит краткосрочный характер, и со временем такие данные обесцениваются. Частные лица хранят данные на различных устройствах (HDD, CD/DVD, Flash). Предприятиям необходимо заниматься сохранением данных и обеспечивать возможность доступа к ним на протяжении длительного периода. При этом данные могут отличаться по степени важности и требовать особого подхода. Например, банки должны обеспечивать сохранность и точность данных клиентских счетов. Некоторые фирмы хранят данные миллионов клиентов. Для этих данных обеспечивается безопасность и целостность в течение длительного периода. Для этого необходимы специальные устройства хранения данных больших объемов с улучшенными характеристиками безопасности и способные хранить данные в течение долгого времени. Устройства для хранения данных называются хранилищами. Тип используемого хранилища зависит от типа данных и их применения (DVD, HDD, внешние дисковые массивы и ленты, RAID-массивы и т.п.). Классификация данных в зависимости от способа управления и хранения: 1) Структурированные (20%) 2) Неструктурированные (80%). Структурированные данные организуют в ряды и колонки строго определенного формата, чтобы приложения могли извлекать данные и эффективно обрабатывать их. Обычно хранятся с применением СУБД. К неструктурированным данным можно отнести данные клиента (на наклейках, электронных сообщениях, визитках, текстовых файлах). Поскольку данные неструктурированны, то их трудно извлекать посредством приложения, управляющего клиентскими базами. Неструктурированные данные на предприятии: электронная почта, pdf-файлы, мгновенные сообщения в ICQ, документы, веб-страницы, счета, аудио/видео, чеки, руководства, формы, контракты, картинки и т.п. Они занимают много места и требуют больших усилий для управления ими. На основе анализа данных предприятие извлекает информацию. Эффективный анализ данных не только приносит прибыль, но и создает новые возможности. Поэтому существует постоянная необходимость в их доступности и защите. В зависимости от специфики решаемых задач и уровня их сложности архитектура ХД и модели данных, используемых для их построения, могут различаться. Согласно схеме данные извлекаются из различных источников и загружаются в ХД, которое содержит как собственно данные, представленные в соответствии с некоторой моделью, так и метаданные.
МЕТАДАННЫЕ Слово «метаданные» буквально переводится как «данные о данных». Метаданные в широком смысле необходимы для описания значения и свойств информации с целью лучшего ее понимания, использования и управления ею. Пример В любой книге, помимо текста, содержится значительное количество дополнительной информации. Цель ее заключается в том, чтобы, во-первых, помочь читателю быстрее ознакомиться с содержимым книги и осмыслить его, во-вторых, описать структуру книги для более эффективного поиска нужной информации. Для решения первой задачи служат такие элементы, как аннотация, комментарии, глоссарий, примечания и т.д. Для поиска нужной информации используются оглавление, названия глав, параграфов и разделов, номера страниц, колонтитулы, предметный указатель и т.д. Кроме этого, читателю могут понадобиться сведения об авторах или об издательстве. Вся эта информация, которая не является частью книги, а служит для повышения эффективности работы с ней, и представляет собой метаданные. С точки зрения IT-технологий метаданные — любая информация, необходимая для анализа, проектирования, построения, внедрения и применения компьютерной информационной системы. Одно из основных назначений метаданных — повышение эффективности поиска. Поисковые запросы, использующие метаданные, делают возможным выполнение сложных операций по фильтрации и отбору данных. Если рассматривать понятие «метаданные» в контексте технологии ХД, то метаданные должны содержать описание структуры данных хранилища и структуры данных импортируемых источников. Метаданные хранятся отдельно от данных в репозитарии метаданных. Они содержат всю информацию, необходимую для извлечения, преобразования и загрузки данных из различных источников, а также для последующего использования и интерпретации данных, содержащихся в ХД. Можно выделить два уровня метаданных — технический (административный) и бизнес-уровень. Технический уровень содержит метаданные, необходимые для обеспечения функционирования хранилища (статистика загрузки данных и их использования, описание модели данных и т.д.). Бизнес-метаданные описывают объекты предметной области, информация о которых содержится в ХД, — атрибуты объектов и их возможные значения, соответствующие поля в таблицах и т.д. Бизнес-метаданные образуют так называемый семантический слой. Пользователь оперирует близкими ему терминами предметной области: товар, клиент, продажи, покупки и т.д., а семантический слой транслирует бизнес-термины в низкоуровневые запросы к данным в хранилище. Фиксированный контент По мере устаревания информации она все меньше подлежит изменению, становится «фиксированной», но к ней продолжают обращаться пользователи. Такие данные называют фиксированным контентом. Это документы, сообщения электронной почты, web-страницы.Несмотря на то, что традиционные технологии (оптические диски, ленточные носители и магнитные диски) позволяют хранить контент, ни одна из них не отвечает уникальным требованиям по хранению фиксированного контента и доступа к нему. Система хранения с контентной адресацией (CAS) Архитектура предназначена для безопасного онлайнового хранения и извлечения фиксированного контента.В отличие от доступа к данным файлового или блочного уровня, при котором используются имена файлов и физическое размещение хранимых данных, CAS хранит данные пользователя и их атрибуты в виде отдельных объектов. Примеры: · Электронные документы (контракты, претензии, вложения электронных писем, финансовые аналитические таблицы)· Цифровые записи (документы, исторические справки, чеки, фотографии, исследования)· Мультимедийные данные (медицинские рентгенограммы, томограммы; видеофильмы, видеонаблюдение, голосовая почта, радио) Архив представляет собой хранилище, в котором размещен фиксированный контент.Архивы часто хранятся на устройствах однократной записи и многократного считывания (WORM), например CD. Однако традиционный процесс архивирования не оптимизирован для распознавания контента, поэтому один и тот же контент может быть заархивирован несколько раз. Кроме того ленты и оптические носители подвержены износу, что важно для мультимедийной информации. Частые изменения в технологии ведут к дополнительным затратам на преобразование медиафайлов в новые форматы. В банковской деятельности, финансовой сфере, медицине есть специальные стандарты, касающиеся архивных данных (достоверность, целостность, доступность).CAS – альтернатива ленточным и оптическим носителям.· Подлинность контента (достоверность достигается путем создания уникального адреса контента и его автоматической непрерывной проверки)· Целостность контента (неизменность – при изменении контента присваивается новый адрес, а не заменяется контент)· Независимость от местоположения (уникальный идентификатор контента для извлечения данных)· Единичное хранение (уникальная подпись каждого экземпляра объекта) · Контроль за сохранностью данных (объект и метаобъект, хранящий атрибуты объекта и нормативы (сроки хранения))· Защита на уровне записи и утилизации (резервная копия)· Независимость от технологии· Быстрый поиск записанных данных Примеры: Больница: Рентгенограммы (от 15 Мб до 1 Гб). Хранение локально 60-90 дней. Необходимо хранить минимум 7 лет. Банк. Изображения чеков (25 Кб). 50-90 млн. чеков в месяц.В первые 60 дней 250000-45000 запросов для верификации. Далее 1 запрос на 10000 чеков. Размер архива до 100 Тб. Реализация EMC Centera: RAID (redundant array of independent disks — избыточный массив независимых жёстких дисков) — массив из нескольких дисков, управляемых контроллером, взаимосвязанных скоростными каналами и воспринимаемых внешней системой как единое целое. До 32 узлов. 1 узел более 1 Тб. Масштабируется для хранения до петабайт содержанияАрхитектура Centera – избыточный массив независимых узлов (RAIN) Требование – непрерывность бизнеса Причины недоступности информации: запланированные простои (80%), незапланированные (20%), катастрофы (<1%)CBMO - среднее время между отказамиCBB – среднее время восстановленияДИ – время работоспособного состояния - часть периода времени, когда система готова к выполнению требуемых функций.ДИ = CBMO / (CBMO+CBB), %
Извлечение данных (ETL) Извлечение данных из разнотипных источников и перенос их в ХД с целью дальнейшей аналитической обработки связаны с рядом проблем: · Исходные данные расположены в источниках самых разнообразных типов и форматов, созданных в различных приложениях, и, кроме того, могут использовать различную кодировку, в то время как для решения задач анализа данные должны быть преобразованы в единый универсальный формат, который поддерживается ХД и аналитическим приложением. · Данные в источниках обычно излишне детализированы, тогда как для решения задач анализа в большинстве случаев требуются обобщенные данные. · Исходные данные, как правило, являются «грязными» (отсутствующие, неточные или бесполезные данные с точки зрения практического применения), что мешает их корректному анализу. Поэтому для переноса исходных данных из различных источников в ХД следует использовать специальный инструментарий, который должен извлекать данные из источников различного формата, преобразовывать их в единый формат, поддерживаемый ХД, а при необходимости — производить очистку данных от факторов, мешающих корректно выполнять их аналитическую обработку. Такой комплекс программных средств получил обобщенное название ETL (от англ. extraction, transformation, loading — «извлечение», «преобразование», «загрузка»). Сам процесс переноса данных и связанные с ним действия называются ETL-процессом, а соответствующие программные средства — ETL-системами. ETL — комплекс методов, реализующих процесс переноса исходных данных из различных источников в аналитическое приложение или поддерживающее его хранилище данных. Приложения ETL извлекают информацию из одного или нескольких источников, преобразуют ее в формат, поддерживаемый системой хранения и обработки, которая является получателем данных, а затем загружают в нее преобразованную информацию. Извлечение данных. На этом этапе данные извлекаются из одного или нескольких источников и подготавливаются к преобразованию. Для корректного представления данных после их загрузки в ХД из источников должны извлекаться не только сами данные, но и информация, описывающая их структуру, из которой будут сформированы метаданные для хранилища. Процесс извлечения данных из источников данных можно разбить на следующие основные типы: · извлечение данных при помощи приложений, основанных на выполнении SQL-команд. Эти приложения функционируют совместно с другими приложениями систем источников данных; · извлечение данных при помощи встроенных в СУБД механизмов импорта/экспорта данных. Использование таких механизмов, как правило, обеспечивает более быстрое извлечение данных, чем с помощью команд SQL; · извлечение данных с помощью специально разработанных приложений. Процесс извлечения данных может выполняться ежедневно, еженедельно или, в редких случаях, ежемесячно. Существует целый класс систем бизнес-аналитики, которые требуют извлечения данных в режиме реального времени: например, системы, анализирующие биржевые операции (каждую секунду), или системы в области телекоммуникаций. Преобразование данных Процесс преобразования данных источников включает в себя следующие основные действия. · Преобразование типов данных: · Преобразования, связанные с нормализацией или денормализацией схемы данных · Преобразования ключей, связанные с обеспечением соответствия бизнес-ключей суррогатным ключам ХД. · Преобразования, связанные с обеспечением качества данных в ХД. Как правило, данные источников не обладают необходимым уровнем качества данных. Заметим, что данные в ХД должны быть: · точными – данные должны содержать правильные количественные значения метрик или давать объяснения, почему невозможно такие значения иметь; · полными – пользователи ХД должны знать, что имеют доступ ко всем релевантным данным; · согласованными – никакие противоречия в данных не допускаются: агрегаты должны точно соответствовать подробным данным; · уникальными – одни и те же объекты предметной области должны иметь одинаковые наименования и идентифицироваться в ХД одинаковыми ключами; · актуальными – пользователи ХД должны знать, с какой частотой данные обновляются (т.е. на какую дату данные действительны). Очистка Для обеспечения качества данные при преобразовании подвергаются процедуре очистки. Процедура очистки данных необходима, поскольку системы бизнес-аналитики не работают с несогласованными и неточными данными, иначе бизнес-анализ становится бессмысленным. Процедура очистки данных включает в себя согласование форматов данных, кодирование данных, исключение ненужных атрибутов (например, комментариев), замещение кодов значениями (например, почтового индекса наименованием населенного пункта), комбинирование данных из различных источников под общим ключом (например, собрать все данные о покупателях), обнаружение одинаково поименованных атрибутов, которые содержат различные по смыслу значения. Очистку данных можно разделить на следующие типы: · конвертация и нормализация данных (приведение к одинаковому кодированию текста, форматам даты и т. д.); · стандартизация написания имен, представления адресов, устранение дубликатов; · стандартизация наименований таблиц, индексов и т.д.; · очистка, основанная на бизнес-правилах предметной области. Загрузка данных Основная цель процесса загрузки данных состоит в быстрой загрузке данных в ХД. Особенности: 1) Загрузка данных, основанная на использовании команд обновления SQL, является медленной. Поэтому загрузка с помощью встроенных в СУБД средств импорта/экспорта является предпочтительной. 2) Индексы таблиц загружаются медленно. Во многих случаях целесообразно удалить индекс и построить его заново. 3) Следует максимально использовать параллелизм при загрузке данных. Следует заметить, что при загрузке данных должна быть гарантирована ссылочная целостность данных, а агрегаты должны быть построены и загружены одновременно с подробными данными.
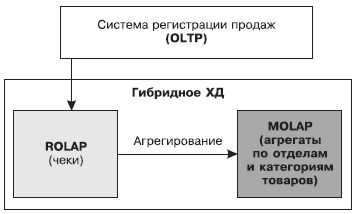
Архитектуры хранилищ данных Реляционные ХД используют классическую реляционную модель, характерную для оперативных регистрирующих OLTP-систем. Данные хранятся в реляционных таблицах, но образуют специальные структуры, эмулирующие многомерное представление данных. Такая технология обозначается аббревиатурой ROLAP — Relational OLAP. Многомерные ХД реализуют многомерное представление данных на физическом уровне в виде многомерных кубов. Данная технология получила название MOLAP — Multidimensional OLAP. Гибридные ХД сочетают в себе свойства как реляционной, так и многомерной модели данных. В гибридных ХД детализированные данные хранятся в реляционных таблицах, а агрегаты — в многомерных кубах. Такая технология построения ХД называется HOLAP — Hybrid OLAP. Виртуальные ХД не являются хранилищами данных в привычном понимании. В таких системах работа ведется с отдельными источниками данных, но при этом эмулируется работа обычного ХД. Иначе говоря, данные не консолидируются физически, а собираются непосредственно в процессе выполнения запроса. В настоящее время не используются. Гибридные хранилища данных Многомерная и реляционная модели ХД имеют свои преимущества и недостатки. Например, многомерная модель позволяет быстрее получить ответ на запрос, но не дает возможности эффективно управлять такими же большими объемами данных, как реляционная модель. Логично было бы использовать такую модель ХД, которая представляла бы собой комбинацию реляционной и многомерной моделей и позволяла бы сочетать высокую производительность, характерную для многомерной модели, и возможность хранить сколь угодно большие массивы данных, присущую реляционной модели. Такая модель, сочетающая в себе принципы реляционной и многомерной моделей, получила название гибридной, или HOLAP (Hybrid OLAP). Хранилища данных, построенные на основе HOLAP, называются гибридными хранилищами данных (ГХД).
Главным принципом построения ГХД является то, что детализированные данные хранятся в реляционной структуре (ROLAP), которая позволяет хранить большие объемы данных, а агрегированные — в многомерной (MOLAP), которая позволяет увеличить скорость выполнения запросов (поскольку при выполнении аналитических запросов уже не требуется вычислять агрегаты). Пример В супермаркете, ежедневно обслуживающем десятки тысяч покупателей, установлена регистрирующая OLTP-система. При этом максимальному уровню детализации регистрируемых данных соответствует покупка по одному чеку, в котором указываются общая сумма покупки, наименования или коды приобретенных товаров и стоимость каждого товара. Оперативная информация, состоящая из детализированных данных, консолидируется в реляционной структуре ХД. С точки зрения анализа представляют интерес обобщенные данные, например, по группам товаров, отделам или некоторым интервалам дат. Поэтому исходные детализированные данные агрегируются, и вычисленные агрегаты сохраняются в многомерной структуре гибридного ХД.
Если данные, поступающие из OLTP-системы, имеют большой объем (несколько десятков тысяч записей в день и более) и высокую степень детализации, а для анализа используются в основном обобщенные данные, гибридная архитектура хранилища оказывается наиболее подходящей. Недостатком гибридной модели является усложнение администрирования ХД из-за более сложного регламента его пополнения, поскольку при этом необходимо согласовывать изменения в реляционной и многомерной структурах. Преимущества: Построение OLAP-куба выполняется по запросу OLAP-средства на основе реляционных и многомерных данных. Такой подход позволяет избежать взрывного роста данных. При этом можно достичь оптимального времени исполнения клиентских запросов. Анализ данных ВВЕДЕНИЕ В OLAP
Любая транзакционная система, как правило, содержит два типа таблиц. Один из них отвечает за быстрые транзакции. Например, при продаже билетов необходимо обеспечить работу большого числа кассиров, которые обмениваются с системой короткими сообщениями. Вводимая и распечатываемая информация, касающаяся фамилии пассажира, даты вылета, рейса, места, пункта назначения, может быть оценена в 1000 байт. Таким образом, для обслуживания пассажиров необходима быстрая обработка коротких записей. Другой тип таблиц содержит итоговые данные о продажах за указанный срок, по направлениям, по категориям пассажиров. Эти таблицы используются аналитиками и финансовыми специалистами раз в месяц, или в конце года, когда необходимо подвести итоги деятельности компании. И если количество аналитиков в десятки раз меньше числа кассиров, то объемы данных, необходимых для анализа, превышают размер средней транзакции на несколько порядков величины. Естественно, что во время выполнения аналитических работ время отклика системы на запрос о наличии билета увеличивается. Вторым фактором, приведшим к разделению аналитических и транзакционных систем, являются разные требования, которые предъявляют аналитические и транзакционные системы к вычислительным комплексам. Технология OLAP (Online Analytical Processing) представляет собой методику оперативного извлечения нужной информации из больших массивов данных и формирования соответствующих отчетов. История OLAP начинается в 1993. Первоначально казалось, что разделения транзакционных и аналитических систем (OLTP – OLAP) вполне достаточно. Однако вскоре выяснилось, что OLAP–системы очень плохо справляются с ролью посредника между различными транзакционными системами - источниками данных и клиентскими приложениями. Стало ясно, что необходима среда хранения аналитических данных. И поначалу на эту роль претендовали единые базы данных, в которые предлагалось копировать исходную информацию из источников данных. Эта идея оказалась не вполне жизнеспособной, поскольку транзакционные системы разрабатывались, как правило, без единого плана, и содержали противоречивую и несогласованную информацию.
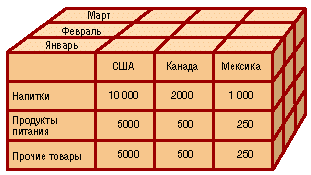
Работа с измерениями В процессе поиска и извлечения из гиперкуба нужной информации над его измерениями производится ряд действий, наиболее типичными из которых являются: · сечение (срез); · транспонирование (вращение); · свертка (консолидация); · детализация. А) Сечение Даже трехмерный куб сложно отобразить на экране компьютера так, чтобы были видны значения интересующих мер. Что уж говорить о кубах с количеством измерений, большим трех? Для визуализации данных, хранящихся в кубе, применяются, как правило, привычные двумерные, т. е. табличные, представления, имеющие сложные иерархические заголовки строк и столбцов. Сечение заключается в выделении подмножества ячеек гиперкуба при фиксировании значения одного или нескольких измерений. В результате сечения получается срез или несколько срезов, каждый из которых содержит информацию, связанную со значением измерения, по которому он был построен.
Двумерное представление куба можно получить, "разрезав" его поперек одной или нескольких осей (измерений): мы фиксируем значения всех измерений, кроме двух, - и получаем обычную двумерную таблицу. В горизонтальной оси таблицы (заголовки столбцов) представлено одно измерение, в вертикальной (заголовки строк) - другое, а в ячейках таблицы - значения фактов. При этом набор фактов фактически рассматривается как одно из измерений - мы либо выбираем для показа один из фактов (и тогда можем разместить в заголовках строк и столбцов два измерения), либо показываем несколько фактов (и тогда одну из осей таблицы займут названия мер, а другую - значения единственного "неразрезанного" измерения). Манипулируя, таким образом, сечениями гиперкуба, пользователь всегда может получить информацию в нужном разрезе. Затем на основе построенных срезов может быть сформирована кросс-таблица и с ее помощью очень быстро получен необходимый отчет. Данная методика лежит в основе технологии OLAP-анализа. На рисунке схематично представлены сечения гиперкуба. Слева сечение выполнено при некотором фиксированном значении измерения Дата. Полученный срез (светло-серая область) содержит информацию обо всех товарах и всех покупателях на определенную дату. На правом фрагменте рисунка получено два среза, пересечение которых будет содержать информацию обо всех покупателях, но на определенный товар и на определенную дату.
Здесь изображен двумерный срез куба для одного факта - Unit Sales (продано штук) и двух "неразрезанных" измерений - Store (Магазин) и Время (Time).
Здесь представлено лишь одно "неразрезанное" измерение - Store, но зато здесь отображаются значения нескольких мер - Unit Sales (продано штук), Store Sales (сумма продажи) и Store Cost (расходы магазина).
Двумерное представление куба возможно и тогда, когда "неразрезанными" остаются и более двух измерений. При этом на осях среза (строках и столбцах) будут размещены два или более измерений "разрезаемого" куба.
Метки Значения, "откладываемые" вдоль измерений, называются членами или метками (members). Метки используются как для "разрезания" куба, так и для ограничения (фильтрации) выбираемых данных - когда в измерении, остающемся "неразрезанным", нас интересуют не все значения, а их подмножество, например три города из нескольких десятков. Значения меток отображаются в двумерном представлении куба как заголовки строк и столбцов. Иерархии и уровни Метки могут объединяться в иерархии, состоящие из одного или нескольких уровней (levels). Например, метки измерения "Магазин" (Store) естественно объединяются в иерархию с уровнями: All (Мир) Country (Страна) State (Штат) City (Город) Store (Магазин). В соответствии с уровнями иерархии вычисляются агрегатные значения, например объем продаж для USA (уровень "Country") или для штата California (уровень "State"). В одном измерении можно реализовать более одной иерархии - скажем, для времени: {Год, Квартал, Месяц, День} и {Год, Неделя, День}.
Б) Транспонирование Транспонирование (вращение) обычно применяется к плоским таблицам, полученным, например, в результате среза, и позволяет изменить порядок представления измерений таким образом, что измерения, отображавшиеся в столбцах, будут отображаться в строках, и наоборот. В ряде случаев транспонирование позволяет сделать таблицу более наглядной.
В) Свертка Операции свертки (группировки) и детализации (декомпозиции) возможны только тогда, когда имеет место иерархическая подчиненность значений измерений. При свертке одно или несколько подчиненных значений измерений заменяются теми значениями, которым они подчинены. При этом уровень обобщения данных уменьшается. Так, если отдельные товары образуют группы, например Стройматериалы, то в результате свертки вместо отдельных наименований товаров будет указано наименование группы, а соответствующие им факты будут агрегированы.
Проиллюстрируем результаты свертки: в табл. 2 представлена исходная таблица, а в табл. 3 — результат ее свертки по измерению Товар. Таблица 2. Исходная таблица
Таблица 3. Результат свертки исходной таблицы по измерению «Товар»
В) Детализация Детализация — это процедура, обратная свертке; уровень обобщения данных уменьшается. При этом значения измерений более высокого иерархического уровня заменяются одним или несколькими значениями более низкого уровня, то есть вместо наименований групп товаров отображаются наименования отдельных товаров.
Например, если при анализе данных о продажах в Северной Америке выполнить операцию детализации для измерения "Регион", то будут отображены такие элементы, как "Канада", "Восточные штаты США" и "Западные штаты США". В результате дальнейшей детализации элемента "Канада" будут отображены элементы "Торонто", "Ванкувер" и т.д.
Хранение информации Хранение информации – важнейшая составляющая ИТ. Информацию необходимо хранить, защищать, оптимизировать, управлять ею. Информационное содержание - информационные объекты, хранящиеся в различных форматах, которые можно извлекать, повторно использовать и публиковать. Содержание характеризуется как "неструктурированная" информация, в том числе текст, изображения, офисная документация, графические данные, чертежи, веб-страницы, сообщения электронной почты, видео- и аудиофайлы и другие мультимедийные активы. Традиционно содержание хранилось в виде бумажных документов, на микропленке и других нецифровых носителях. Сегодня все большие объемы содержания хранятся в цифровом формате, включая динамическое содержание на веб-сайтах (в том числе в корпоративном интранете и экстранете), мобильных телефонах, Интернет-телевидении, КПК и пейджерах. В информационном обществе все больше информации создается частными лицами, а не предприятиями. Эта информация приобретает ценность при обмене с другими людьми (общение в социальных сетях, отправка электронной почты, обмен фото и видео). В момент создания информация обычно размещается в мобильных телефонах, камерах, ноутбуках. Для обмена ее нужно загружать через сеть в центры хранения данных. Хранение и управление этой информацией осуществляет относительно небольшое число организаций. В мире бизнеса значимость, взаимосвязанность и объем информации также стремительно растет. В бизнесе данные используются для извлечения информации, необходимой для деловых операций. Некоторые коммерческие приложения по обработке информации включают системы бронирования билетов, рассылки счетов, электронную коммерцию, использование банкоматов, проектирование изделий, управление снабжением, архивами электронной почты, веб-порталами, базами данных клиентов, пластиковыми картами, рынком ценных бумаг и т.п. Рост значимости информации для бизнеса усилил потребность в защите и управлении данными. Теперь для информационных центров хранение информации становится приоритетной задачей. Хранилище данных представляет собой репозиторий, дающий пользователям возможность хранения и извлечения цифровых данных. Билл Инмон (1989г.): " Хранилище данных (Data Warehouse) - это предметно-ориентированное, привязанное ко времени и неизменяемое собрание данных для поддержки процесса принятия управляющих решений". СИСТЕМЫ ОПЕРАТИВНОЙ ОБРАБОТКИ ИНФОРМАЦИИ OLTP (On-Line Transaction Processing — оперативная, т.е. в режиме реального времени, обработка транзакций). Транзакция — некоторый набор операций над базой данных, который рассматривается как единое завершенное, с точки зрения пользователя, действие над некоторой информацией, обычно связанное с обращением к базе данных.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-12-30; просмотров: 1024; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.129.210.35 (0.016 с.) |