
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Методы математической статистики в психолого-пелагогическом исследованииСодержание книги
Поиск на нашем сайте
Применение математики к другим наукам имеет смысл только в единении с глубокой теорией конкретного явления. Об этом важно помнить, чтобы не сбиваться на простую игру в формулы, за которой не стоит никакого реального содержания. Академик Ю. А. Митропольский Теоретические методы исследования в психологии и педагогике дают возможность раскрыть качественные характеристики изучаемых явлений. Эти характеристики будут полнее и глубже, если накопленный эмпирический материал подвергнуть количественной обработке. Однако проблема количественных измерений в рамках психолого-педагогических исследований очень сложна. Эта сложность заключается прежде всего в субъективно-причинном многообразии педагогической деятельности и ее результатов, в самом объекте измерения, находящемся в состоянии непрерывного движения и изменения. Вместе с тем введение в исследование количественных показателей стало сегодня необходимым и обязательным компонентом получения объективных данных о результатах педагогического труда. Как правило, эти данные могут быть получены путем прямого или опосредованного измерения различных составляющих педагогического процесса либо посредством количественной оценки соответствующих параметров адекватно построенной математической модели педагогического процесса. С этой целью при исследовании проблем психологии и педагогики применяются методы математической статистики. С их помощью решаются различные задачи: обработка фактического материала, получение новых, дополнительных данных, обоснование научной организации исследования и др. ОСНОВНЫЕ ПОНЯТИЯ МАТЕМАТИЧЕСКОЙ СТАТИСТИКИ Исключительно важную роль в анализе многих психолого-педагогических явлений играют средние величины, представляющие собой обобщенную характеристику качественно однородной совокупности по определенному количественному признаку. Нельзя, например, вычислить среднюю специальность или среднюю национальность студентов вуза, так как специальность и национальность — качественно разнородные явления. Зато можно и нужно определить среднюю количественную характеристику их успеваемости (средний балл), эффективности методических систем и приемов и т. д. В психолого-педагогических исследованиях обычно применяются различные виды средних величин: средняя арифметическая, средняя геометрическая, медиана, мода и др. Наиболее распространены средняя арифметическая, Медиана и мода. Средняя арифметич еская применяется в тех случаях, когда между определяющим свойством и данным признаком имеется прямо пропорциональная зависимость (например, при улучшении показателей работы учебной группы улучшаются показатели работы каждого ее члена). Средняя арифметическая представляет собой частное от деления суммы величин на их число и вычисляется по формуле:
где X— средняя арифметическая; Х1, Х2, Х3... ХN — результаты отдельных наблюдений (приемов, действий), N — количество наблюдений (приемов, действий), ∑ — сумма результатов всех наблюдений (приемов, действий). Медианой (Ме) называется мера среднего положения, характеризующая значение признака на упорядоченной (построенной по признаку возрастания или убывания) шкале, которое соответствует середине исследуемой совокупности. Медиана может быть определена для порядковых и количественных признаков. Место расположения этого значения определяется по формуле Место медианы =
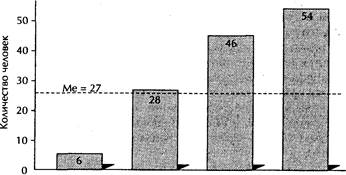
Например, по результатам исследования установлено, что: · на «отлично» учатся 5 человек из участвующих в эксперименте; · на «хорошо» — 18 человек; · на «удовлетворительно» — 22 человека; · на «неудовлетворительно» — 6 человек. Так как всего в эксперименте принимало участие N = 54 человека, то середина выборки равна 0,5 х N = 27 человек. Отсюда делается вывод, что больше половины обучающихся учатся ниже оценки «хорошо», т. е. медиана больше «удовлетворительно», но меньше «хорошо» (рис. 6.1).
неуд. неуд. + удовл. удовл. + хор. хор. + отл. Успеваемость Рис. 6.1. Пример определения медианы Мода (Мо) — наиболее часто встречающееся типичное значение признака среди других значений. Она соответствует классу с максимальной частотой. Этот класс называется модальным значением. Например, если ответы на вопрос анкеты «Укажите степень владения иностранным языком» распределились таким образом: 1 — владею свободно — 25; 2 — владею в степени, достаточной для общения — 54; 3 — владею, но испытываю трудности при общении — 253; 4 — понимаю с трудом — 173; 5 — не владею — 28, то очевидно, что наиболее типичным значением здесь является «Владею, но испытываю трудности при общении», которое и будет модальным. Таким образом, мода равна 253. Важное значение при использовании в психолого-педагогическом исследовании математических методов уделяется расчету дисперсии и среднеквадратических (стандартных) отклонений. Дисперсия равна среднему квадрату отклонений значения исследуемой переменной от среднего значения. Она выступает как одна из характеристик индивидуальных результатов разброса значений исследуемой переменной (например, оценок учащихся) вокруг среднего значения. Вычисление дисперсии осуществляется путем определения: • отклонения от среднего значения; • квадрата указанного отклонения; • суммы квадратов отклонения и среднего значения квадрата отклонения (табл. 6.1)1. Значение дисперсии используется в различных статистических расчетах, но не имеет непосредственного наблюдаемого характера. Величиной, непосредственно связанной с содержанием наблюдаемой переменной, является среднее квадратическое отклонение.
Таблица 6.1 Пример вычисления дисперсии
Среднее квадратическое отклонение подтверждает типичность и показательность средней арифметической, отражает меру колебания численных значений признаков, из которых выводится средняя величина. Оно равно корню квадратному из дисперсии и определяется по формуле
(6.1) где s — средняя квадратическая. При малом числе наблюдения (действий) — менее 100 — в значении формулы следует ставить не N, a N-1. Средняя арифметическая и средняя квадратическая являются основными характеристиками полученных результатов в ходе исследования. Они позволяют обобщить данные, сравнить их, установить преимущества одной психолого-педагогической системы (программы) над другой. Среднее квадратическое (стандартное) отклонение широко применяется как мера разброса для различных характеристик. На рис. 6.2 приведен пример распределения частот значений двух переменных с одинаковыми средними, но различным разбросом.
Значение переменной Рис. 6.2. Кривая нормального распределения вероятности случайной величины (закон Гаусса) Оценивая результаты исследования, важно определить рассеивание случайной величины около среднего значения. Это рассеивание описывается с помощью закона Гауса (закона нормального распределения вероятности случайной величины). Суть закона заключается в том, что при измерении некоторого признака в данной совокупности элементов всегда имеют место отклонения в обе стороны от нормы вследствие множества неконтролируемых причин, при этом чем больше отклонения, тем реже они встречаются. При дальнейшей обработке данных могут быть выявлены: коэффициент вариации (устойчивости) исследуемого явления, представляющий собой процентное отношение среднеквадратического отклонения к средней арифметической; мера косости, показывающая, в какую сторону направлено преимущественное число отклонений; мера крутости, которая показывает степень скопления значений случайной величины около среднего и др. Все эти статистические данные помогают более полно выявить признаки изучаемых явлений. Меры связи между переменными. Связи (зависимости) между двумя и более переменными в статистике называют корреляцией. Она оценивается с помощью значения коэффициента корреляции, который является мерой степени и величины этой связи. Коэффициентов корреляции много. Рассмотрим лишь часть из них, которые учитывают наличие линейной связи между переменными. Их выбор зависит от шкал измерения переменных, зависимость между которыми необходимо оценить. Наиболее часто в психологии и педагогике применяются коэффициенты Пирсона и Спирмена. Рассмотрим вычисление значений коэффициентов корреляции на конкретных примерах. Пример 1. Пусть две сравниваемые переменные Х (семейное положение) и Y (исключение из университета) измеряются в дихотомической шкале (частный случай шкалы наименований). Для определения связи используем коэффициент Пирсона. В тех случаях, когда нет необходимости подсчитывать частоту появления различных значений переменных Х и Y, удобно проводить вычисления коэффициента корреляции с помощью таблицы сопряженности (табл. 6.2-6.4), показывающей количество совместных появлений пар значений по двум переменным (признакам). А — количество случаев, когда переменная Х имеет значение, равное нулю, и одновременно переменная Y имеет значение, равное единице; В — количество случаев, когда переменные Х и Y имеют одновременно значения, равные единице; С — количество случаев, когда переменные X и Y имеют одновременно значения, равные нулю; D — количество случаев, когда переменная Х имеет значение, равное единице, и одновременно переменная Y имеет значение, равное нулю.
Таблица 6.2 Общая таблица сопряженности
В общем виде формула коэффициента корреляции Пирсона для дихотомических данных имеет вид:
Таблица 6.3 Пример данных в дихотомической шкале
Таблица 6.4 Таблица сопряженности для данных из табл. 6.3
Подставим в формулу данные из таблицы сопряженности (табл. 6.4), соответствующей рассматриваемому примеру:
Таким образом, коэффициент корреляции Пирсона для выбранного примера равен 0,32, т. е. зависимость между семейным положением студентов и фактами исключения из университета незначительная. Пример 2. Если обе переменные измеряются в шкалах порядка, то в качестве меры связи используется коэффициент ранговой корреляции Спирмена (Rs). Он вычисляется по формуле
где Rs, — коэффициент ранговой корреляции Спирмена; Di, — разность рангов сравниваемых объектов; N— количество сравниваемых объектов. Значение коэффициента Спирмена изменяется в пределах от -1 до +1. В первом случае между анализируемыми переменными существует однозначная, но противоположено направленная связь (с увеличением значений одной уменьшается значения другой). Во втором с ростом значений одной переменной пропорционально возрастает значение второй переменной. Если величина К^ равна нулю или имеет значение, близкое к нему, то значимая связь между переменными отсутствует.
В качестве примера вычисления коэффициента Спирмена используем данные из табл. 6.5. Таблица 6.5 Данные и промежуточные результаты вычисления значения коэффициента ранговой корреляции Rs
Подставим данные примера в формулу для коэффициента Спирмена:
Результаты вычисления позволяют говорить о наличии достаточно выраженной связи между рассматриваемыми переменными. Статистическая проверка научной гипотезы. Доказательство статистической достоверности экспериментального влияния существенно отличается от доказательства в математике и формальной логике, где выводы носят более универсальный характер: статистические доказательства не являются столь строгими и окончательными—в них всегда допускается риск ошибиться в выводах, и потому статистическими методами не доказывается окончательно правомерность того или иного вывода, а показывается мера правдоподобности принятия той или иной гипотезы. Педагогическая гипотеза, (научное предположение о преимуществе того или иного метода и т. п.) в процессе статистического анализа переводится на язык статистической науки и заново формулируется, по меньшей мере, в виде двух статистических гипотез. Первая (основная) называется нулевой гипотезой (H0), в которой исследователь говорите своей исходной позиции. Он априори как бы декларирует, что новый метод (предполагаемый им, его коллегами или оппонентами) не обладает какими-либо преимуществами, и потому с самого начала исследователь психологически готов занять честную научную позицию: различия между новым и старым методами объявляются равными нулю. В другой, альтернативной гипотезе (H1) делается предположение о преимуществе нового метода. Иногда выдвигается несколько альтернативных гипотез с соответствующими обозначениями. Например, гипотеза о преимуществе старого метода обозначается как (H2). Альтернативные гипотезы принимаются тогда и только тогда, когда опровергается нулевая гипотеза. Это бывает в случаях, когда различия, скажем, в средних арифметических экспериментальной и контрольной групп настолько значимы (статистически достоверны), что риск ошибки отвергнуть нулевую гипотезу и принять альтернативную не превышает одного из трех принятых уровней значимости статистического вывода: • первый уровень — 5 % (в научных текстах пишут иногда p = 5 % или а ≤ 0,05, если представлено в долях), где допускается риск ошибки в выводе в пяти случаях из ста теоретически возможных таких же экспериментов при строго случайном отборе испытуемых для каждого эксперимента; • второй уровень - 1 %, т. е. соответственно допускается риск ошибиться только в одном случае из ста (а ≤ 0,01, при тех же требованиях); • третий уровень — 0,1 %, т. е. допускается риск ошибиться только в одном случае из тысячи (а ≤ 0,001). Последний уровень значимости предъявляет очень высокие требования к обоснованию достоверности результатов эксперимента и потому редко используется. При сравнении средних арифметических экспериментальной и контрольной групп важно определить, какая средняя не только больше, но и насколько больше. Чем меньше разница между ними, тем более приемлемой окажется нулевая гипотеза об отсутствии статистически значимых (достоверных) различий. В отличие от мышления на уровне обыденного сознания, склонного воспринимать полученную в результате опыта разность средних как факт и основание для вывода, педагог-исследователь, знакомый с логикой статистического вывода, не будет торопиться в таких случаях. Он, скорее всего, сделает предположение о случайности различий, выдвинет нулевую гипотезу об отсутствии достоверных различий в результатах экспериментальной и контрольной групп и лишь после опровержения нулевой гипотезы примет альтернативную. Таким образом, вопрос о различиях в рамках научного мышления переводится в другую плоскость. Дело не только в различиях (они почти всегда есть), а в величине этих различий и отсюда — в определении разницы и границы, после которого можно сказать: да, различия неслучайны, они статистически достоверны, а значит, испытуемые этих двух групп принадлежат после эксперимента уже не к одной (как раньше), а к двум различным генеральным совокупностям, и уровень подготовленности учащихся, потенциально принадлежащих этим совокупностям, будет существенно отличаться. Для того чтобы показать границы этих различий, используются так называемые оценки генеральных параметров. Рассмотрим на конкретном примере (табл. 6.6), как с помощью математической статистики можно опровергнуть или подтвердить нулевую гипотезу. Допустим, необходимо определить, зависит ли эффективность групповой деятельности студентов от уровня развития межличностных отношений в их учебной группе. В качестве нулевой гипотезы выдвигается предположение, что такой зависимости не существует, а в качестве альтернативной — зависимость существует. Для этих целей сравниваются результаты эффективности деятельности в двух группах, одна из которых в этом случае выступает в качестве экспериментальной, а вторая — контрольной. Чтобы определить, является ли разность между средними значениями показателей эффективности в первой и во второй группах существенной (значимой), необходимо вычислить статистическую достоверность этой разницы. Для этого можно использовать t-критерий Стъюдента. Он вычисляется по формуле
где X1 и X2 — средние арифметические значения переменных в группах 1 и 2; М1 и М2 — величины средних ошибок, которые вычисляются по формуле
где s — средняя квадратическая, вычисляемая по формуле (6.1). Определим ошибки для первого ряда (экспериментальная группа) и второго ряда (контрольная группа):
Находим значение t-критерия по формуле
Вычислив величину t-критерия, по специальной таблице определяют уровень статистической значимости различий между средними показателями эффективности деятельности в экспериментальной и контрольной группах. Чем выше значение (-критерия, тем выше значимость различий. Для этого t расчетное сравниваем с t табличным. Табличное значение выбирается с. учетом выбранного уровня достоверности (р = 0,05 или р = 0,01), а также в зависимости от числа степеней свободы, которое находится по формуле
где U — число степеней свободы; N1 и N2— число замеров в первом и во втором рядах. В нашем примере U =7+7-2= 12.
Таблица 6.6 Данные и промежуточные результаты вычисления значимости статистических различий средних значений
Для таблицы t-критерия находим, что значение tтабл = 3,055 для однопроцентного уровня (р < 0,01) при 12 степенях свободы. Таким образом, величина tтабл.< tрасч. Следовательно, можно сделать статистически обоснованный вывод о том, что эффективность деятельности в экспериментальной группе выше, чем в контрольной, при уровне значимости 0,01 (риск ошибки составляет одна из ста теоретически возможных). Однако педагогу-исследователю следует помнить, что существование статистической значимости разности средних значений может быть важным, но не единственным аргументом в пользу наличия или отсутствия связи (зависимости) между явлениями или переменными. Поэтому необходимо привлекать и другие аргументы количественного или содержательного обоснования возможной связи. Многомерные методы анализа данных. Анализ взаимосвязи между большим количеством переменных осуществляется путем использования многомерных методов статистической обработки. Цель применения подобных методов — обнаружить скрытые закономерности, выделить наиболее существенные взаимосвязи между переменными. Примерами таких многомерных статистических методов являются: · факторный анализ; · кластерный анализ; · дисперсионный анализ; · регрессионный анализ; · латентно-структурный анализ; · многомерное шкалирование и др. Факторный анализ заключается в выявлении и интерпретации факторов. Фактор—обобщенная переменная, которая позволяет свернуть часть информации, т. е. представить ее в удобообозримом виде. Например, факторная теория личности выделяет ряд обобщенных характеристик поведения, которые в данном случае называются чертами личности. Кластерный анал из позволяет выделить ведущий признак и иерархию взаимосвязей признаков. Дисперсионный анализ —статистический метод, используемый для изучения одной или нескольких одновременно действующих и независимых переменных на изменчивость наблюдаемого признака. Его особенность состоит в том, что наблюдаемый признак может быть только количественным, в то же время объясняющие признаки могут быть как количественными, так и качественными. Регрессионный анализ позволяет выявить количественную (численную) зависимость среднего значения изменений результативного признака (объясняемой) от изменений одного или нескольких признаков (объясняющих переменных). Как правило, данный вид анализа применяется в том случае, когда требуется выяснить, на-сколько изменяется средняя величина одного признака при изменении на единицу другого признака. Латентно-структурный анализ представляет собой совокупность аналитико-статистических процедур выявления скрытых переменных (признаков), а также внутренней структуры связей между ними. Он дает возможность исследовать проявления сложных взаимосвязей непосредственно ненаблюдаемых характеристик социально-психологических и педагогических феноменов. Латентный анализ может стать основой для моделирования указанных взаимосвязей. Многомерное шкалирование обеспечивает наглядную оценку сходства или различия между некоторыми объектами, описываемыми большим количеством разнообразных переменных. Эти различия представляются в виде расстояния между оцениваемыми объектами в многомерном пространстве.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-12-16; просмотров: 391; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.145.81.47 (0.013 с.) |

 .
.



















 = 7
= 7

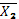 = 4
= 4






