Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Классификация многопроцессорных системСодержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте
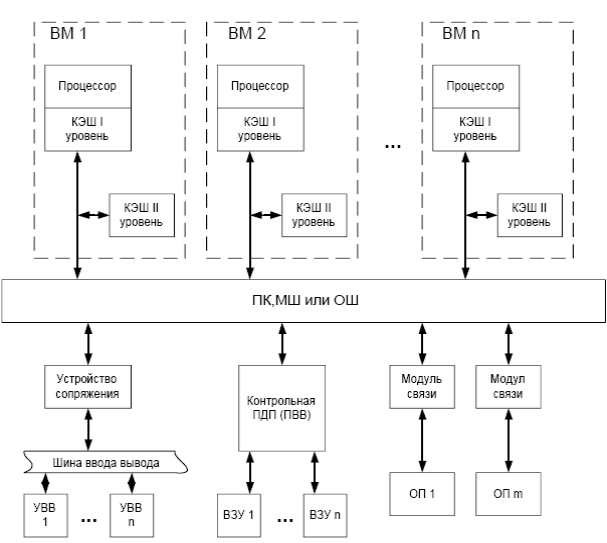
Многопроцессорные системы по классификации Флинна относятся к архитектурам типа MIMD(Multiple Instruction Multipl Data) с множественным потоком команд при множественном потоке данных (МКМД). В многопроцессорной системе каждый процессор выполняет свою программу достаточно независимо от других процессоров. Процессоры в ходе решения общей задачи должны связываться друг с другом в соответствии с графом взаимодействия её параллельных ветвей. Это вызывает необходимость более подробно производить классификацию систем типа MIMD. В многопроцессорных системах с общей памятью (сильносвязанных) имеется память данных и команд, доступная всем процессорам. С общей памятью процессоры связываются с помощью коммуникационной среды, основой которой может быть либо общая шина (ОШ), либо множество шин (МШ), либо перекрёстный коммутатор (ПК). В противоположность этому варианту в слабосвязанных многопроцессорных системах (машинах с распределённой памятью) вся память разделена между процессорами и каждый блок памяти доступен только локальному процессору. Память и процессор образуют фактически независимые вычислительные модули (вычислительные узлы), которые связываются между собой при помощи высокоскоростной сети обмена с коммутацией сообщений. Сообщение – это блок информации, сформированный процессом-отправителем таким образом, чтобы он был понятен процессу-получателю. Сообщение состоит из заголовка фиксированной длины и набора данных определённого типа обычно переменной длины. В заголовок, как правило, включают следующую информацию: • адрес - это поле, предназначенное для идентификации процессоров (вычислительных узлов), участвующих в процедуре обмена. Адрес процессора или вычислительного узла является уникальным и состоит из двух частей - адреса процессора - отправителя и адреса процессора - получателя; • управляющие поля, в которые могут входить символы синхронизации, отмечающие начало и конец передаваемого блока (кадра) данных, символы, обозначающие тип данных, длину передаваемых данных и др. В качестве топологической модели коммуникационной среды применяют линейные или кольцевые моноканалы, звездообразную конфигурацию, плоскую решётку, n- мерный тор, либо n- кубическую (гиперкубическую) сеть. Базовой моделью вычислений на MIMD-системах является совокупность независимых процессов, время от времени обращающихся к разделяемым данным. Основана она на распределенных вычислениях, в которых программа делится на довольно большое число параллельных задач. В настоящее время всё большее внимание разработчики проявляют к архитектурам типа MIMD. Это находит объяснение главным образом существованием двух факторов: 1) в архитектурах MIMD используются высокотехнологичные, дешёвые, выпускаемые массово микропроцессоры, что позволяет оптимизировать соотношение стоимость/производительность; 2) архитектура MIMD дает большую гибкость и при наличии соответствующей поддержки со стороны аппаратных средств и программного обеспечения, поскольку может работать и как однопрограммная система, обеспечивая высокопроизводительную обработку данных для одной прикладной задачи, и как многопрограммная, выполняющая множество задач параллельно, а также как некоторая комбинация этих возможностей. Одной из отличительных особенностей многопроцессорной вычислительной системы является коммуникационная среда, с помощью которой процессоры соединяются друг с другом или с памятью. Топология коммуникационной среды настолько важна для многопроцессорной системы, что многие характеристики производительности и другие оценки выражаются отношением времени обработки к времени обмена, которые в общем случае зависят от алгоритмов решаемых задач и порождаемых ими вычислительных процессов. Существуют две основные модели межпроцессорного обмена: одна основана на передаче сообщений, другая - на использовании общей памяти. В многопроцессорных системах с общей памятью один процессор осуществляет запись в конкретную ячейку, а другой процессор производит считывание из этой ячейки памяти. Чтобы обеспечить согласованность данных и синхронизацию процессов, обмен часто реализуется по принципу взаимно исключающего доступа к общей памяти методом "почтового ящика". В архитектурах с распределённой памятью непосредственное разделение памяти невозможно. Вместо этого процессоры получают доступ к совместно используемым данным посредством передачи сообщений по сети обмена. Эффективность схемы коммуникаций зависит от протоколов обмена, каналов обмена и пропускной способности памяти. Такие системы часто называют системами с передачей сообщений. Каждый из этих механизмов обмена имеет свои преимущества. Для обмена в общей памяти это включает: • совместимость с хорошо понятными и используемыми в однопроцессорных системах механизмами взаимодействия процессора с основной памятью; • простота программирования, особенно это заметно в тех случаях, когда процедуры обмена между процессорами сложные или динамически меняются во время выполнения. Подобные преимущества упрощают конструирование компилятора; • более низкая задержка обмена и лучшее использование полосы пропускания при обмене малыми порциями данных; • возможность использования аппаратно управляемого кэширования для снижения частоты удаленного обмена, допускающая кэширование всех данных как разделяемых, так и неразделяемых. Основные преимущества обмена с помощью передачи сообщений являются: • аппаратура может быть более простой, особенно по сравнению с моделью разделяемой памяти, которая поддерживает масштабируемую когерентность кэш-памяти; • процедуры обмена понятны, принуждают программистов (или компиляторы) уделять внимание обмену, который обычно имеет высокую, связанную с ним, стоимость. Часто, в системах с общей памятью затраты времени на обмен не учитываются, так как проблемы обмена в значительной степени скрыты от программиста. Однако накладные расходы на обмен в этих системах имеются и определяются в основном конфликтами при доступе процессоров и других устройств к общим шинам и блокам основной памяти. Чем больше процессоров добавляется в систему, тем больше процессов соперничают при использовании одних и тех же данных и шины, что может привести к значительным задержкам хода вычислительного процесса и, следовательно, к потерям общей производительности. Причём с увеличением числа процессоров в системе возможно появление эффекта насыщения при котором рост числа процессоров не приведёт к росту производительности, и даже наоборот к её падению. Модель системы с общей памятью очень удобна для прогаммирования, поскольку пользователь практически не задумывается о процедурах распараллеливания (они большей частью ложатся на компилятор) и процедурах взаимодействия параллельных процессов (они производятся аппаратными средствами посредством общей памяти). В сетях с коммутацией сообщений по мере возрастания требований к обмену следует учитывать возможность перегрузки сети. Здесь межпроцессорный обмен связывает сетевые ресурсы: каналы, процессоры, буферы сообщений. Объем передаваемой информации может быть сокращен за счет тщательного разбиения задачи на параллельные ветви и тщательной диспетчеризации процесса их исполнения. Таким образом, существующие MIMD-системы распадаются на два основных класса в зависимости от количества объединяемых процессоров, которое определяет способ организации памяти и методику их межсоединений. К первому классу относятся системы с разделяемой (общей) основной памятью (Shared Memory multiProcessing, SMP), объединяющие до нескольких (2-16) процессоров, число которых зависит от типа применяемой коммуникационной среды. Сравнительно небольшое количество процессоров в таких системах позволяет иметь одну централизованную общую память и зачастую объединить процессоры и память с помощью лишь одной шины. При наличии у процессоров кэш-памяти достаточного объема высокопроизводительная шина и общая память могут удовлетворить обращения к памяти, поступающие от нескольких процессоров. Поскольку имеется единственная память с одним и тем же временем доступа, эти системы называют симметричными, а иногда - UMA (Uniform Memory Access). Симметричная архитектура предполагает однородность процессоров и единообразную схему их включения в многопроцессорную систему. Такой способ организации со сравнительно небольшой разделяемой памятью в настоящее время является наиболее популярным. Структура подобной системы представлена на рис. 90.
Рис. 90. Архитектура многопроцессорной системы с разделяемой (общей) памятью.
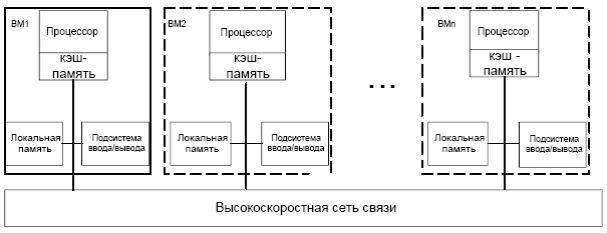
Второй класс составляют крупномасштабные вычислительные системы с распределенной памятью. Подобные ВС получили название систем с массовым параллелизмом (Mass-Parallel Processing, MPP). Для того чтобы подключать в систему большое количество процессоров необходимо физически разделять основную память и распределять её между ними. В противном случае пропускной способности памяти просто может не хватить для удовлетворения запросов, поступающих от очень большого числа процессоров. Естественно при таком подходе также требуется реализовать связь процессоров между собой. На рис. 91 показана структура такой системы.
Рис. 91. Архитектура многопроцессорной системы с распределенной памятью.
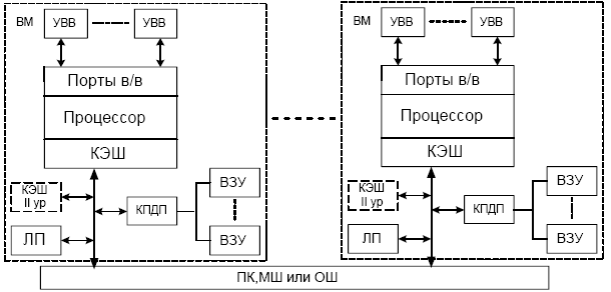
Адресное пространство в таких системах состоит из отдельных адресных пространств, которые логически не связаны, и доступ к которым не может быть осуществлен аппаратно другим процессором. Фактически каждый модуль процессор-память представляет собой отдельный компьютер, поэтому такая структура в какой-то степени приближена к многопроцессорным системам. MPP система менее эффективна с точки зрения пользователя из-за усложнённой процедуры программирования, которая связана с применением специальных коммуникационных библиотек для организации взаимодействия между вычислительными узлами (процессами). Необходимость же реализации модели распределенной памяти объясняется тем, что масштабируемость (способность системы к наращиванию числа процессоров) систем с общей памятью ограничена пропускной способностью памяти и коммуникационной среды. Вообще распределение памяти между отдельными узлами системы имеет два главных преимущества. Во-первых, это эффективный с точки зрения стоимости способ увеличения пропускной способности памяти, поскольку большинство обращений могут выполняться параллельно к локальной памяти в каждом узле. Во- вторых уменьшается задержка обращения к локальной памяти из-за отсутствия конфликтов при доступе к ней. Поэтому совершенно естественно появление промежуточного класса систем, объединяющего достоинства первого и второго классов. Память в таких системах распределена по вычислительным узлам и одновременно является доступной для всех процессоров. Такие ВС называются системами с распределенной разделяемой (общей) памятью (DSM - Distributed Shared Memory), а иногда NUMA (Non-Uniform Memory Access), поскольку время доступа зависит от расположения данных в подсистеме памяти (Рис. 92). Если данные находятся в локальной памяти местного вычислительного узла, то время доступа к ним минимально, если в локальной памяти удалённого вычислительного узла, то время доступа увеличивается в несколько раз.
Рис. 92. Архитектура многопроцессорной системы с распределённой разделяемой памятью.
Хотя структурно DSM и MPP-системы сходны, однако технически они реализуются по-разному. В DSM-системах физически отдельные, распределённые по вычислительным узлам, устройства памяти могут представляться логически как единое адресное пространство, что означает, что любой процессор может выполнять обращения к любым ячейкам памяти, предполагая, что он имеет соответствующие права доступа. Коммуникационная же среда и вовсе другая, так как она полностью соответствует структурам SMP-систем. Поскольку, в связи с принципами локальности, вычислительный процесс в основном развивается внутри вычислительного узла и редко обращается к удалённой памяти, что резко снижает объём передаваемых данных по коммуникационной среде, то масштабируемость таких систем повышается по сравнению с SMP-системами, и число процессоров может достигать 32-х. Что касается устройств ввода/вывода и внешних запоминающих устройств, то они также как и память, либо распределяются по узлам, либо находятся в общем пользовании.
|
||||
|
|
Последнее изменение этой страницы: 2016-09-18; просмотров: 1132; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.137.181.194 (0.008 с.) |