Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Выделенные и мультиплексируемые линииСодержание книги
Поиск на нашем сайте
В некоторых ВМ линии адреса и данных объединены в единую мультиплексируемую шину адреса/данных. Такая шина функционирует в режиме разделения времени, поскольку цикл шины разбит на временной интервал для передачи адреса и временной интервал для передачи данных. Мультиплексирование адресов и данных предполагает наличие мультиплексора на одном конце тракта пересылки информации и демультиплексора на его другом конце. Мультиплексоры и демультиплексоры играют роль коммутирующих устройств. Мультиплексирование позволяет сократить общее число линий, но требует усложнения логики связи с шиной. Кроме того, оно ведет к потенциальному снижению производительности, поскольку исключает возможность параллельной передачи адресов и данных, что можно было бы использовать в транзакциях записи, одновременно выставляя на ША адрес, а на ШД — записываемое слово. Арбитраж шин
В реальных системах на роль ведущего вправе одновременно претендовать сразу несколько из подключенных к шине устройств, однако управлять шиной в каждый момент времени может только одно из них. Чтобы исключить конфликты, шина должна предусматривать определенные механизмы арбитража запросов и правила предоставления шины одному из запросивших устройств. Решение обычно принимается на основе приоритетов претендентов. Схемы приоритетов
Каждому потенциальному ведущему присваивается определенный уровень приоритета, который может оставаться неизменным (статический или фиксированный приоритет) либо изменяться по какому-либо алгоритму (динамический приоритет). Основной недостаток статических приоритетов в том, что устройства, имеющие высокий приоритет, в состоянии полностью блокировать доступ к шине устройств с низким уровнем приоритета. Системы с динамическими приоритетами дают шанс каждому из запросивших устройств рано или поздно получить право на управление шиной, то есть в таких системах реализуется принцип равнодоступности. Наибольшее распространение получили следующие алгоритмы динамического изменения приоритетов: · простая циклическая смена приоритетов; · циклическая смена приоритетов с учетом последнего запроса; · смена приоритетов по случайному закону; · схема равных приоритетов; · алгоритм наиболее давнего использования. В алгоритме простой циклической смены приоритетов после каждого цикла арбитража все приоритеты понижаются на один уровень, при этом устройство, имевшее ранее низший уровень приоритета, получает наивысший приоритет. В схеме циклической смены приоритетов с учетом последнего запроса все возможные запросы упорядочиваются в виде циклического списка. После обработки очередного запроса обслуженному ведущему назначается низший уровень приоритета. Следующее в списке устройство получает наивысший приоритет, а остальным устройствам приоритеты назначаются в убывающем порядке, согласно их следованию в циклическом списке. В обеих схемах циклической смены приоритетов каждому ведущему обеспечивается шанс получить шину в свое распоряжение, однако большее распространение получил второй алгоритм. При смене приоритетов по случайному закону после очередного цикла арбитража с помощью генератора псевдослучайных чисел каждому ведущему присваивается случайное значение уровня приоритета. В схеме равных приоритетов при поступлении к арбитру нескольких запросов каждый из них имеет равные шансы на обслуживание. Возможный конфликт разрешается арбитром. Такая схема принята в асинхронных системах. В алгоритме наиболее давнего использования (LRU, Least Recently Used) после каждого цикла арбитража наивысший приоритет присваивается ведущему, который дольше чем другие не использовал шину. Помимо рассмотренных существует несколько алгоритмов смены приоритетов, которые не являются чисто динамическими, поскольку смена приоритетов происходит не после каждого цикла арбитража. К таким алгоритмам относятся: · алгоритм очереди (первым пришел — первым обслужен); · алгоритм фиксированного кванта времени. В алгоритме очереди запросы обслуживаются в порядке очереди, образовавшейся к моменту начала цикла арбитража. Сначала обслуживается первый запрос в очереди, то есть запрос, поступивший раньше остальных. Аппаратурная реализация алгоритма связана с определенными сложностями, поэтому используется он редко. В алгоритме фиксированного кванта времени каждому ведущему для захвата шины в течение цикла арбитража выделяется определенный квант времени. Если ведущий в этот момент не нуждается в шине, выделенный ему квант остается не использованным. Такой метод наиболее подходит для шин с синхронным протоколом. Схемы арбитража
Арбитраж запросов на управление шиной может быть организован по централизованной или децентрализованной схеме. Выбор конкретной схемы зависит от требований к производительности и стоимостных ограничений. При централизованном арбитраже в системе имеется специальное устройство – центральный арбитр, – ответственное за предоставление доступа к шине только одному из запросивших ведущих. Это устройство, называемое иногда центральным контроллером шины, может быть самостоятельным модулем или частью ЦП. Наличие на шине только одного арбитра означает, что в централизованной схеме имеется единственная точка отказа. В зависимости от того, каким образом ведущие устройства подключены к центральному арбитру, возможные схемы централизованного арбитража можно подразделить на параллельные и последовательные. В параллельном варианте центральный арбитр связан с каждым потенциальным ведущим индивидуальными двухпроводными трактами. Поскольку запросы к центральному арбитру могут поступать независимо и параллельно, данный вид арбитража называют централизованным параллельным арбитражем или централизованным арбитражем независимых запросов. Второй вид централизованного арбитража известен как централизованный последовательный арбитраж. В последовательных схемах для выделения запроса с наивысшим приоритетом используется один из сигналов, поочередно проходящий через цепочку ведущих, чем и объясняется другое название — цепочечный или гирляндный арбитраж. В дальнейшем будем полагать, что уровни приоритета ведущих устройств в цепочке понижаются слева направо. В зависимости от того, какой из сигналов используется для целей арбитража, различают три основных типа схем цепочечного арбитража: с цепочкой для сигнала предоставления шины (ПШ), с цепочкой для сигнала запроса шины (ЗШ) и с цепочкой для дополнительного сигнала разрешения (РШ). Наиболее распространена схема цепочки для сигнала ПШ. При децентрализованном или распределенном арбитраже единый арбитр отсутствует. Вместо этого каждый ведущий содержит блок управления доступом к шине, и при совместном использовании шины такие блоки взаимодействуют друг с другом, разделяя между собой ответственность за доступ к шине. По сравнению с централизованной схемой децентрализованный арбитраж менее чувствителен к отказам претендующих на шину устройств. Вне зависимости от принятой модели арбитража должна быть также продумана стратегия ограничения времени контроля над шиной. Одним из вариантов может быть разрешение ведущему занимать шину в течение одного цикла шины, с предоставлением ему возможности конкуренции за шину в последующих циклах. Другим вариантом является принудительный захват контроля над шиной устройством с более высоким уровнем приоритета, при сохранении восприимчивости текущего ведущего к запросам на освобождение шины от устройств с меньшим уровнем приоритета.
Основные интерфейсы современных ВМ на базе архитектуры IA-32 Интерфейс PCI
Доминирующее положение на рынке ПК достаточное длительное время занимали системы на основе шины PCI (Peripheral Component Interconnect – Взаимодействие периферийных компонентов). Этот интерфейс был предложен фирмой Intel в 1992 году (стандарт PCI 2.0 – в 1993) в качестве альтернативы локальной шине VLB/VLB2. Следует отметить, что разработчики этого интерфейса позиционируют PCI не как локальную, а как промежуточную шину (mezzanine bus), т.к. она не является шиной процессора. Поскольку шина PCI не ориентирована на определенный процессор, ее можно использовать для других процессоров. Шина PCI была адаптирована к таким процессорам, как Alpha, MIPS, PowerPC и SPARC. Именно PCI сменила NuBus на платформе Apple Macintosh. Шины ISA, EISA или MCA могут управляться шиной PCI с помощью моста сопряжения (рис. 41), что позволяет устанавливать в ПК платы устройств ввода-вывода с различными системными интерфейсами. Например, в чипсете Intel Triton использовалась микросхема PIIX, помимо контроллера IDE предоставляющая мост для шины ISA.
Существуют три варианта плат PCI: с уровнями сигналов 3,3 В, с уровнями сигналов 5 В и универсальные. Ключ в разъеме гарантирует, что платы с одним уровнем сигнала и невзаимозаменяемые не будут по ошибке вставлены в разъем с другим уровнем сигнала. Платы с пониженным напряжением питания в основном используются в мобильных компьютерах. Существует 32-разрядная и 64-разрядная реализация шины PCI. В 64-разрядной реализации используется разъем с дополнительной секцией. 32-разрядные и 64-разрядные платы можно устанавливать в 64-разрядные и 32-разрядные разъемы и наоборот. Платы и шина определяют тип разъема и работают должным образом. При установке 64-разрядной платы в 32-разрядный разъем остальные выводы не задействуются и просто выступают за пределы разъема. На шине PCI сигналы адреса и данных мультиплексированы, поэтому для передачи каждых 32 или 64 разрядов требуется два шинных цикла: один - для пересылки адреса, а второй - для пересылки данных. Однако возможен также пакетный режим, при котором вслед за одним циклом передачи адреса разрешается осуществить до четырех циклов передачи данных (до 16 байт в PCI-32). После этого устройство должно подать новый запрос на обслуживание и снова получить управление над шиной (и выполнить адресный цикл). Поэтому шина PCI-32 с тактовой частотой 33 МГц имеет пиковую скорость обычной передачи около 66 Мбайт/с (два шинных цикла для передачи 4 байт) и пиковую скорость пакетной передачи около 105 Мбайт/с. PCI поддерживает процедуру прямого доступа к памяти ведущего устройства на шине (bus mastering DMA), хотя некоторые реализации PCI могут и не предоставлять такую возможность для всех разъемов PCI. Процессор может функционировать параллельно с периферийными устройствами, являющимися ведущими на шине. Кроме того, платы PCI поддерживают: · автоматическую конфигурацию Plug&Play (не требуют назначения адресов расширений BIOS вручную); · совместное использование прерываний (когда один и тот же номер прерывания может использоваться разными устройствами); · контроль четности сигналов шины данных и адресной шины; · конфигурационную память от 64 до 256 байт (код производителя, код устройства, код класса (функции) устройства и др.). Персональные компьютеры могут иметь две или больше шин PCI. Каждой шиной управляет свой мост PCI, что позволяет устанавливать в компьютер больше плат PCI (вплоть до 16 – ограничение адресации). Если управление второй шиной PCI осуществляется с первой шины, то это называется каскадной или иерархической схемой. В этом случае первая шина будет также нести нагрузку второй шины. Если управление каждой шиной PCI осуществляется непосредственно с шины процессора, это называется равноправной схемой. Обычно мост PCI выполняет также функции контроллера внешней кэш-памяти, контроллера основной памяти и обеспечивает сопряжение с процессором. В системах на основе Pentium II/III эти функции распределены между двумя мостами: "северным" (North Bridge) и "южным" (South Bridge), что связано с наличием дополнительного высокоскоростного системного интерфейса для подключения видеокарты (AGP). В 1995 году был выпущена улучшенная версия интерфейса – PCI 2.1, которая предоставила следующие возможности: · поддержка тактовой частоты шины 66 МГц; · таймер обработки множественных запросов MTT (Multi-Transaction Timer) позволяет устройствам, осуществляющим прямой доступ к памяти, удерживать шину для "прерывистой" передачи пакетов, при этом не требуется повторно добиваться права управления шиной, что особенно полезно при передаче видеоданных; · пассивное разъединение (Passive Release) позволяет устройствам, осуществляющим прямой доступ к памяти по шине PCI, передавать данные в то время, когда ведется передача данных по шине ISA (обычно это приводило к блокированию передачи по шине PCI, поскольку она использовалась для подключения центрального процессора к шине ISA); · задержанные транзакции PCI позволяют передаваемым данным ведущего устройства на шине PCI получать приоритет над ожидающими в очереди данными для передачи с PCI на ISA (которые будут переданы позже); · повышение производительности записи благодаря оснащению PCI-чипсета буферами большего объема, поэтому транзакции могут выстраиваться в очередь, когда шина PCI занята, и происходит сбор байтов, слов и двойных слов, которые могут объединяться в единую 8-байтную операцию записи. C 2005 года в ПК на основе Pentium 4 вместо PCI используют новый системный интерфейс – PCI Express. Порт AGP
С повсеместным внедрением технологий мультимедиа пропускной способности шины PCI стало не хватать для производительной работы видеокарты. Чтобы не менять сложившийся стандарт на шину PCI, но, в то же время, ускорить ввод-вывод данных в видеокарту и увеличить производительность обработки трехмерных изображений, в 1996 году фирмой Intel был предложен выделенный интерфейс для подключения видеокарты - AGP (Accelerated Graphics Port - высокоскоростной графический порт). Впервые порт AGP был представлен в системах на основе Pentium II. В таких системах чипсет был разделен на два моста: "северный" (North Bridge) и "южный" (South Bridge). Северный мост связывал ЦП, память и видеокарту - три устройства в системе, между которыми курсируют наибольшие потоки данных. Таким образом, на северный мост возлагаются функции контроллера основной памяти, моста AGP и устройства сопряжения с фасадной шиной процессора FSB (Front-Side Bus). Собственно мост PCI, обслуживающий остальные устройства ввода-вывода в системе, в том числе контроллер IDE (PIIX), реализован на основе южного моста. Одной из целей разработчиков AGP было уменьшение стоимости видеокарты, за счет уменьшения количества встроенной видеопамяти. По замыслу Intel, большие объемы видеопамяти для AGP-карт были бы не нужны, поскольку технология предусматривала высокоскоростной доступ к общей памяти. Интерфейс AGP по топологии не является шиной, т.к. обеспечивает только двухточечное соединение, т.е. один порт AGP поддерживает только одну видеокарту. В то же время, порт AGP построен на основе PCI 2.1 с тактовой частотой 66 МГц, 32-разрядной шиной данных и питанием 3,3 В. Поскольку порт AGP и основная шина PCI независимы и обслуживаются разными мостами, это позволяет существенно разгрузить последнюю, освобождая пропускную способность, например, для потоков данных с каналов IDE. В то же время, поскольку AGP-порт всегда один, в интерфейсе нет возможностей арбитража, что существенно упрощает его и положительно сказывается на быстродействии. Для повышения пропускной способности AGP предусмотрена возможность передавать данные с помощью специальных сигналов, используемых как стробы, вместо сигнала тактовой частоты 66 МГц (табл. 4). Например, в режиме AGP 2x данные передаются как по переднему, так и по заднему фронту тактового сигнала, что позволяет достичь пропускной способности 533 Мбайт/с.
В AGP существует возможность отмены механизма мультиплексирования шины адреса и данных - режим адресации по боковой полосе SBA (Side-Band Addressing). При использовании SBA задействуются 8 дополнительных линий, по которым передается новый адрес, в то время как по 32-битной шине данных передается пакет от предыдущего запроса. Альтернативный способ повышения эффективности использования пропускной способности AGP - с помощью конвейеризации. На PCI по выставленному адресу после задержки появляются данные. На AGP сначала выставляется пакет адресов, на которые следует ответ пакетом данных (рис. 42).
Рис. 42. Конвейеризация AGP
Главная обработка трехмерных изображений выполняется в основной памяти компьютера как центральным процессором, так и процессором видеокарты. AGP обеспечивает два механизма доступа процессора видеокарты к памяти: · DMA (Direct Memory Access) – обычный прямой доступ к памяти. В этом режиме основной памятью считается встроенная видеопамять на карте, текстуры копируются туда из системной памяти компьютера перед использованием их процессором видеокарты; · DIME (Direct In Memory Execute) – непосредственное выполнение в памяти. В этом режиме основная и видеопамять находятся как бы в общем адресном пространстве. Общее пространство эмулируется с помощью таблицы отображения адресов GART (Graphic Address Remapping Table) блоками по 4 Кбайт. Таким образом, процессор видеокарты способен непосредственно работать с текстурами в основной памяти без необходимости их копирования в видеопамять. Этот процесс называется AGP-текстурированием. Чтобы извлечь выгоду из применения порта AGP, помимо требуемой аппаратной поддержки (т.е. графического адаптера AGP и системной платы), необходимую поддержку должны обеспечивать операционная система и драйвер видеоадаптера, а в прикладной программе должны быть использованы новые возможности порта AGP (например, трехмерное проецирование текстур). Существуют модификации порта AGP: · спецификация AGP Pro для видеокарт с большой потребляемой мощностью (до 110 Вт), включающая дополнительные разъемы питания; · 64-битный порт AGP, используемый для профессиональных графических адаптеров; · интерфейс AGP Express, представляющий собой эмуляцию порта AGP при помощи сдвоенного слота PCI в форм-факторе AGP. Применяется на некоторых материнских платах на основе PCI Express для поддержки AGP-видеокарт. В настоящее время порт AGP практически исчерпал свои возможности и активно вытесняется системным интерфейсом PCI Express. PCI Express
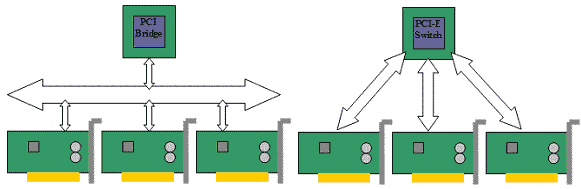
Интерфейс PCI Express (первоначальное название - 3GIO) использует концепцию PCI, однако физическая их реализация кардинально отличается. На физическом уровне PCI Express представляет собой не шину, а некое подобие сетевого взаимодействия на основе последовательного протокола. Высокое быстродействие PCI Express позволяет отказаться от других системных интерфейсов (AGP, PCI), что дает возможность также отказаться от деления системного чипсета на северный и южный мосты в пользу единого контроллера PCI Express. Одна из концептуальных особенностей интерфейса PCI Express, позволяющая существенно повысить производительность системы – использование топологии «звезда». В топологии "шина" (рис. 43, левая схема) устройствам приходится разделять пропускную способность PCI между собой. При топологии «звезда» (рис. 43, правая схема) каждое устройство монопольно использует канал, связывающий его с концентратором (switch) PCI Express, не деля ни с кем пропускную способность этого канала.
Канал (link), связывающий устройство с концентратором PCI Express, представляет собой совокупность дуплексных последовательных (однобитных) линий связи, называемых полосами (lane). Дуплексный характер полос также контрастирует с архитектурой PCI, в которой шина данных - полудуплексная (в один момент времени передача выполняется только в определенном направлении). На электрическом уровне каждая полоса соответствует двум парам проводников с дифференциальным кодированием сигналов. Одна пара используется для приема, другая - для передачи. PCI Express первого поколения декларирует скорость передачи одной полосы 2,5 Гбит/с в каждом направлении. В будущем планируется увеличить скорость до 5 и 10 Гбит/с. Канал может состоять из нескольких полос: одной (x1 link), двух (x2 link), четырех (x4 link), восьми (x8 link), шестнадцати (x16 link) или тридцати двух (x32 link). Все устройства должны поддерживать работу с однополосным каналом. Аналогично, различают слоты: x1, x2, x4, x8, x16, x32. Однако слот может быть "шире", чем подведенный к нему канал, т.е. на слот x16 фактически может быть выведен канал x8 link и т.п. Карта PCI Express должна физически подходить и корректно работать в слоте, который по размерам не меньше разъема на карте, т.е. карта x4 будет работать в слотах x4, x8, x16, даже если реально к ним подведен однополосный канал. Процедура согласования канала PCI Express обеспечивает выбор максимального количества полос, поддерживаемого обеими сторонами. При передаче данных по многополосным каналам используется принцип чередования или "разборки данных" (data stripping): каждый последующий байт передается по другой полосе. В случае канала x2 это означает, что все четные байты передаются по одной полосе, а нечетные - по другой. Как и большинство других высокоскоростных последовательных протоколов, PCI Express использует схему кодирования данных, встраивающую тактирующий сигнал в закодированные данные, т.е. обеспечивающую самосинхронизацию. Применяемый в PCI Express алгоритм 8B / 10B (8 бит в 10 бит) обеспечивает разбиение длинных последовательностей нулей или единиц так, чтобы приемная сторона не потеряла границы битов. С учетом кодирования 8B/10B пропускную способность однополосного канала PCI Express можно оценить, как 2500 Мбит/с / 10 бит/байт = 250 мегабайт/с (238 Мбайт/с). PCI Express обеспечивает передачу управляющих сообщений, в том числе прерываний, по тем же линиям данных. Последовательный протокол не предусматривает блокирование, поэтому легко обеспечивается латентность, сопоставимая с PCI, где имеются выделенные линии для прерываний.
Лабораторная работа №2. Мультиплексоры и демультиплексоры
Назначение мультиплексоров (от английского multiplex — многократный) – коммутировать в заданном порядке сигналы, поступающие с нескольких входных шин на одну выходную. У мультиплексора может быть, например, 16 входов и 1 выход. Это означает, что если к этим входам присоединены 16 источников цифровых сигналов - генераторов последовательных цифровых слов, то байты от любого из них можно передавать на единственный выход. Для выбора любого из 16 каналов обходимо иметь 4 входа селекции, на которые подается двоичный адрес канала. Так, для передачи данных от канала номер 9 на входах селекции необходимо установить код 1001.
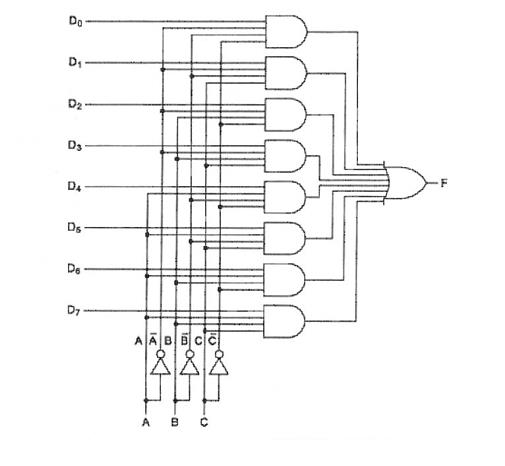
Рис. 44. Схема восьмивходового мультиплексора.
Например, подав на входы A B C мультиплексора на рис. 44 двоичное число 011, мы обеспечим появление на выходе F сигнала со входа D3. В силу этого мультиплексоры часто называют селекторами или селекторами-мультиплексорами. Мультиплексоры применяются, например, в МП i8088 для выдачи на одни и те же выводы МП адреса и данных, что позволяет существенно сократить общее количество выводов микросхемы; в микропроцессорных системах управления мультиплексоры устанавливают на удаленных объектах для возможности передачи информации по одной линии от нескольких установленных на них датчиков. Демультиплексоры в функциональном отношении противоположны мультиплексорам. С их помощью сигналы с одного информационного входа распределяются в требуемой последовательности по нескольким выходам. Выбор нужной выходной шины, как и в мультиплексоре, обеспечивается установкой соответствующего кода на адресных входах. При m адресных входах демультиплексор может иметь до 2m выходов. Мультиплексоры и демультиплексоры присутствуют в составе микросхем 74 серии в библиотеке цифровых элементов EWB (Electronics Worbench). Примером может служить микросхема 74153. это сдвоенный четырёхканальный мультиплексор, имеющий 2 адресных входа, входы разрешения первого и второго мультиплексоров и их непосредственные выходы и входы. Шифраторы (кодеры) используются чаще всего для преобразования десятичных чисел в двоичный или двоично-десятичный код, например, в микрокалькуляторах, в которых нажатие десятичной клавиши соответствует генерации соответствующего двоичного кода. Поскольку возможно нажатие сразу нескольких клавиш, в шифраторах используется принцип приоритета старшего разряда, т.е. при нажатии клавиш 9, 5 и 2 на выходе шифратора будет генерироваться код 1001, соответствующий цифре 9. Следует отметить, что шифраторы как отдельный класс функциональных устройств представлены в наиболее богатой ТТЛ-серии всего двумя ИМС — 74147 и 74148, причем последняя ИМС имеется и в библиотеке программы EWB. Дешифратор (декодер) — устройство с несколькими входами и выходами, у которого определенным комбинациям входных сигналов соответствует активное состояние одного из выходов, т.е. дешифратор является обращенным по входам де-мультиплексором, у которого адресные входы стали информационными, а бывший информационный вход стал входом разрешения. Поэтому часто дешифраторы называют дешифраторами-демультиплексорами и наоборот. Дешифраторы и демультиплексоры в виде серийных ИМС средней степени интеграции широко используются в информационно-измерительной технике и микропроцессорных системах управления, в частности, в качестве коммутаторов-распределителей информационных сигналов и синхроимпульсов, для демультиплексирования данных и адресной логики в запоминающих устройствах, а также для преобразования двоично-десятичного кода в десятичный с целью управления индикаторными и печатающими устройствами.
Рис. 45. Схема дешифратора-демультиплексора с тремя входами и восемью выходами.
Дешифраторы как самостоятельные изделия электронной техники имеют 4, 8 или 16 выходов. Если требуется большее число выходов, дешифраторы наращиваются в систему. Имеющийся в библиотеке EWB дешифратор ИМС 74154 имеет четыре адресных входа А, В, С, D, два входа разрешения G1, G2 и шестнадцать выходов 0...15 (выходы не прямые, как ошибочно обозначено в EWB, а инверсные, т.е. в исходном состоянии на выходах сигнал логической единицы). В режиме дешифратора с генератора слова на входы G1, G2 подается 0, а на адресные входы — код в диапазоне 0000...1111. В режиме демультиплексора один из разрешающих входов, например G1, используется в качестве информационного. Информационный сигнал в виде логического 0 с этого выхода распределяется по выходам 0...15 в соответствии с состоянием адресных входов, т.е. режимы дешифратора и демультиплексора практически неразличимы. Используя программу Electronics workbench (или любой другой пакет схемотехнического моделирования), выполните следующие задания: 1–5: Используется микросхема 74148 (шифратор), три светодиода (подключены к выходам A0-A2, нумерация соответственная) и генератор слова; собрать схему осуществляющую: 1. Включение светодиодов в последовательности «0; 1; 2». 2. Включение светодиодов в последовательности «0; 0+1; 0+1+2» 3. Включение светодиодов в последовательности «0; 0+1; 1+2; 2» 4. Включение светодиодов в последовательности «2; 0; 1; 1+2+3» 5. Включение светодиодов в последовательности «0; 0+1; 1+2; 2»
5–15: Используется микросхема 74154 (дешифратор-демультиплексор), генератор слова и светодиоды. Исследовать микросхему и определить уровень сигнала на выходах микросхемы в исходном состоянии. Собрать схему, осуществляющую: 6. Последовательное гашение светодиодов по возрастанию номеров. (эффект бегущего огня) 7. Последовательное гашение светодиодов по убыванию номеров. 8. Последовательное гашение сначала чётных, а затем нечётных светодиодов по убыванию номеров. 9. Последовательное гашение сначала чётных, а затем нечётных светодиодов по возрастанию номеров. 10. Последовательное гашение светодиодов от краёв диапазона к центру. 11. Последовательное зажигание светодиодов по возрастанию номеров. (использовать инвертер) 12. Последовательное зажигание светодиодов по убыванию номеров. 13. Последовательное зажигание сначала чётных, а затем нечётных светодиодов по убыванию номеров. 14. Последовательное зажигание сначала нечётных, а затем чётных светодиодов по возрастанию номеров. 15. Последовательное зажигание светодиодов от краёв диапазона к центру.
|
|||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-09-18; просмотров: 1193; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.170 (0.013 с.) |