Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Расшифруйте понятия “протокол”, “интерфейс”. В чем разница между ними. Какие основные виды интерфейсов существуют у компьютерных программ согласно стандарта posix.Содержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте
Расшифруйте понятия “протокол”, “интерфейс”. В чем разница между ними? Какие основные виды интерфейсов существуют у компьютерных программ согласно стандарта POSIX? Интерфейс – это внешнее представление, абстракция какого-то информационного объекта. Протокол – это набор правил взаимодействия между объектами.
1. Базовые Стандарты. В них определяются системные интерфейсы, связанные с различными сторонами операционной системы. Базовый стандарт специфицирует синтаксис и семантику системного интерфейса таким образом, что прикладные программы могут непосредственно обращаться к системным службам. Способ реализации этих служб в базовом стандарте не определяется (определяется только их семантика); системные разработчики свободны в выборе способа реализации, находясь, однако, в рамках спецификации интерфейса. Первоначально базовые стандарты были разработаны для языка СИ, но сейчас они специфицируются как независимые от языка интерфейсы. Находящиеся в настоящий момент в стадии принятия базовые стандарты POSIX приводятся в табл. 1 и в табл. 2.
Стандарт состоит из четырёх основных разделов: § Основные определения (Base definitions) — список основных определений и соглашений, используемых в спецификациях, и список заголовочных файлов языка Си, которые должны быть предоставлены соответствующей стандарту системой. § Оболочка и утилиты (Shell and utilities) — описание утилит и командной оболочки sh, стандарты регулярных выражений. § Системные интерфейсы (System interfaces) — список системных вызовов языка Си. § Обоснование (Rationale) — объяснение принципов, используемых в стандарте. 3.
Перечислите этапы загрузки компьютера от включения питания до активизации GUI или CLI ОС. Охарактеризуйте роль каждого из них. Перечислите разные способы синхронизации работы многопоточных программ. Перечислите и охарактеризуйте проблемные ситуации, которые могут возникать в случае конкуренции за ресурсы между нитями. Какие существуют подходы, для того чтобы избежать их? Синхронизация (от др.-греч. σύγχρονος — одновременный) в информатике обозначает одно из двух: синхронизацию процессов, либо синхронизацию данных. Синхронизация процессов — приведение двух или нескольких процессов к такому их протеканию, когда определённые стадии разных процессов совершаются в определённом порядке, либо одновременно. Синхронизация необходима в любых случаях, когда параллельно протекающим процессам необходимо взаимодействовать. Для её организации используются средства межпроцессного взаимодействия. Среди наиболее часто используемых средств — сигналы и сообщения, семафоры и мьютексы, каналы (англ. pipe), совместно используемая память. Сигнал (в теории информации и связи) — материальный носитель информации, используемый для передачи сообщений в системе связи. Сигнал может генерироваться, но его приём не обязателен, в отличие от сообщения, которое должно быть принято принимающей стороной, иначе оно не является сообщением. Сигналом может быть любой физический процесс, параметры которого изменяются в соответствии с передаваемым сообщением. Семафо́р — объект, позволяющий войти в заданный участок кода не более чем n потокам. Определение введено Эдсгером Дейкстрой. Мью́текс (англ. mutex, от mutual exclusion — «взаимное исключение») — одноместный семафор, служащий в программировании для синхронизации одновременно выполняющихся потоков. Мьютексы — это один из вариантов семафорных механизмов для организации взаимного исключения. Они реализованы во многих ОС, их основное назначение — организация взаимного исключения для потоков из одного и того же или из разных процессов. Синхронизация данных — ликвидация различий между двумя копиями данных. Предполагается, что ранее эти копии были одинаковы, а затем одна из них, либо обе были независимо изменены. Способ синхронизации данных зависит от делаемых дополнительных предположений. Главной проблемой тут является то, что независимо сделанные изменения могут быть несовместимы друг с другом (так называемый «конфликт правок»), и даже теоретически не существует общего способа разрешения подобных ситуаций. Тем не менее, есть ряд частных способов, применимых в тех или иных случаях: § Наиболее простой способ: предполагают, что изменения вносились лишь в одну из копий — «рабочую» — и другая копия просто перезаписывается её содержимым. Этот способ реализуют большинство приложений синхронизации; в силу необратимости делаемых изменений пользователю даётся выбор, какую копию считать «главной». § Если данные представляют собой набор независимых записей (то есть любое сочетание записей является корректным — это, напр., телефонная книга), то можно просто объединить множества записей. Это ликвидирует риск потери информации, но чтобы удалить запись из набора, этот способ приходится сочетать с первым. § Если наборы синхронизируются неоднократно, можно автоматически вводить в них дополнительную служебную информацию: дата и время последнего изменения записи, пометки об удалённых записях (стираются после следующей синхронизации или через достаточно большое время) и пр.. Этот подход используется, например, в Outlook. § Обрабатывать конфликты правок: автоматически (если возможно), иначе — вручную. Этот, наиболее общий способ применяется только если указанные выше упрощённые недопустимы — например, в системах контроля версий. Так, CVS при обнаружении двух независимых изменений объявляет о «конфликте» и либо (в простых случаях) разрешает его автоматически, либо предоставляет пользователю разрешить его вручную. В этих случаях конфликтов стараются просто избегать — например, распределением областей компетенции.
16. Что представляет из себя примитив синхронизации “Семафор”? Опишите его интерфейс (набор операций) и приведите простой пример использования.
Семафор -это примитив синхронизации потоков, который позволяет войти в заданный участок кода не более чем n потокам (это определение дал выдающийся ученый Эдсгер Дейкстра). Обычно семафор нужен для того, чтобы ограничить доступ к некоторому ресурсу, заданным количеством потоков приложения (ресурсом может быть например внешнее устройство, или некий сетевой ресурс). При входе в критический участок (КУ) процесса функция P(s) проверяет значение семафора, и если оно равно 0 – блокирует процесс, если не равно 0 – отнимает от значения семафора 1 и пропускает процесс в КУ. По завершении работы с общим ресурсом ф-я V(s) прибавляет к значению семафора 1, что позволяет другим процессам обращаться к общему ресурсу. Одним из первых механизмов, предложенных для синхронизации поведения процессов, стали семафоры, концепцию которых описал Дейкстра (Dijkstra) в 1965 году. Семафор представляет собой целую переменную, принимающую неотрицательные значения, доступ любого процесса к которой, за исключением момента ее инициализации, может осуществляться только через две атомарные операции: P (от датского слова proberen — проверять) и V (от verhogen — увеличивать). Классическое определение этих операций выглядит следующим образом: P(S): пока S == 0 процесс блокируется; S = S – 1; V(S): S = S + 1; Эта запись означает следующее: при выполнении операции P над семафором S сначала проверяется его значение. Если оно больше 0, то из S вычитается 1. Если оно меньше или равно 0, то процесс блокируется до тех пор, пока S не станет больше 0, после чего из S вычитается 1. При выполнении операции V над семафором S к его значению просто прибавляется 1. Подобные переменные-семафоры могут быть с успехом применены для решения различных задач организации взаимодействия процессов. В ряде языков программирования они были непосредственно введены в синтаксис языка (например, в ALGOL-68), в других случаях применяются через использование системных вызовов. Соответствующая целая переменная располагается внутри адресного пространства ядра операционной системы. Операционная система обеспечивает атомарность операций P и V, используя, например, метод запрета прерываний на время выполнения соответствующих системных вызовов. Если при выполнении операции P заблокированными оказались несколько процессов, то порядок их разблокирования может быть произвольным, например, FIFO. Одной из типовых задач, требующих организации взаимодействия процессов, является задача producer-consumer (производитель-потребитель). Пусть два процесса обмениваются информацией через буфер ограниченного размера. Производитель закладывает информацию в буфер, а потребитель извлекает ее оттуда. Грубо говоря, на этом уровне деятельность потребителя и производителя можно описать следующим образом. Producer: while(1) { produce_item; put_item; } Consumer: while(1) { get_item; consume_item; } Если буфер забит, то производитель должен ждать, пока в нем появится место, чтобы положить туда новую порцию информации. Если буфер пуст, то потребитель должен дожидаться нового сообщения. Как можно реализовать эти условия с помощью семафоров? Возьмем три семафора empty, full и mutex. Семафор full будем использовать для гарантии того, что потребитель будет ждать, пока в буфере появится информация. Семафор empty будем использовать для организации ожидания производителя при заполненном буфере, а семафор mutex - для организации взаимоисключения на критических участках, которыми являются действия put_item и get_item (операции положить информацию и взять информацию не могут пересекаться, так как тогда возникнет опасность искажения информации). Тогда решение задачи выглядит так: Semaphore mutex = 1; Semaphore empty = N, где N – емкость буфера; Semaphore full = 0; Producer: while(1) { produce_item; P(empty); P(mutex); put_item; V(mutex); V(full); } Consumer: while(1) { P(full); P(mutex); put_item; V(mutex); V(empty); consume_item; }
Легко убедиться, что это действительно корректное решение поставленной задачи. Попутно заметим, что семафоры использовались здесь для достижения двух целей: организации взаимоисключения на критическом участке и синхронизации скорости работы процессов. 17. Что представляет из себя примитив синхронизации “Монитор”? Опишите его интерфейс (набор операций) и приведите простой пример использования. Мониторы представляют собой тип данных, который может быть с успехом внедрен в объектно-ориентированные языки программирования. Монитор обладает собственными переменными, определяющими его состояние. Значения этих переменных извне могут быть изменены только с помощью вызова функций-методов, принадлежащих монитору. В свою очередь, эти функции-методы могут использовать в работе только данные, находящиеся внутри монитора, и свои параметры. На абстрактном уровне можно описать структуру монитора следующим образом:
monitor monitor_name { описание переменных; void m1(...){... } void m2(...){... } ... void mn(...){... } { блок инициализации внутрениих переменных; } }
Здесь функции m1,..., mn представляют собой функции-методы монитора, а блок инициализации внутренних переменных содержит операции, которые выполняются только один раз: при создании монитора или при самом первом вызове какой-либо функции-метода до ее исполнения. Важной особенностью мониторов является то, что в любой момент времени только один процесс может быть активен, т. е. находиться в состоянии готовность или исполнение, внутри данного монитора. Поскольку мониторы представляют собой особые конструкции языка программирования, то компилятор может отличить вызов функции, принадлежащей монитору, от вызовов других функций и обработать его специальным образом, добавив к нему пролог и эпилог, реализующий взаимоисключение. Так как обязанность конструирования механизма взаимоисключений возложена на компилятор, а не на программиста, работа программиста при использовании мониторов существенно упрощается, а вероятность появления ошибок становится меньше. Однако одних только взаимоисключений не достаточно для того, чтобы в полном объеме реализовать решение задач, возникающих при взаимодействии процессов. Нам нужны еще и средства организации очередности процессов, подобно семафорам full и empty в предыдущем примере. Для этого в мониторах было введено понятие условных переменных (condition variables), над которыми можно совершать две операции wait и signal, до некоторой степени похожие на операции P и V над семафорами. Если функция монитора не может выполняться дальше, пока не наступит некоторое событие, она выполняет операцию wait над какой-либо условной переменной. При этом процесс, выполнивший операцию wait, блокируется, становится неактивным, и другой процесс получает возможность войти в монитор. Когда ожидаемое событие происходит, другой процесс внутри функции-метода совершает операцию signal над той же самой условной переменной. Это приводит к пробуждению ранее заблокированного процесса, и он становится активным. Если несколько процессов дожидались операции signal для этой переменной, то активным становится только один из них. Что нам нужно предпринять для того, чтобы у нас не оказалось двух процессов, разбудившего и пробужденного, одновременно активных внутри монитора? Хор предложил, чтобы пробужденный процесс подавлял исполнение разбудившего процесса, пока он сам не покинет монитор. Несколько позже Хансен (Hansen) предложил другой механизм: разбудивший процесс покидает монитор немедленно после исполнения операции signal. Мы будем придерживаться подхода Хансена. Давайте применим концепцию мониторов к решению задачи производитель-потребитель.
monitor ProducerConsumer { condition full, empty; int count; void put() { if(count == N) full.wait; put_item; count += 1; if(count == 1) empty.signal; } void get() { if (count == 0) empty.wait; get_item(); count -= 1; if(count == N-1) full.signal; } { count = 0; } } Producer: while(1) { produce_item; ProducerConsumer.put(); } Consumer: while(1) { ProducerConsumer.get(); consume_item; }
Легко убедиться, что приведенный пример действительно решает поставленную задачу.
Реализация мониторов требует разработки специальных языков программирования и компиляторов для них. Мониторы встречаются в таких языках как параллельный Евклид, параллельный Паскаль, Java и т.д. Эмуляция мониторов с помощью системных вызовов для обычных широко используемых языков программирования не так проста, как эмуляция семафоров. Поэтому можно пользоваться еще одним механизмом со скрытыми взаимоисключеньями, механизмом, о котором мы уже упоминали, — передачей сообщений.
18. Какие инструкции аппаратной синхронизации вы знаете? Сравните их. Приведите 2 примера, как на их основе можно построить различные примитивы синхронизации (условные переменные, семафоры, …). Переменная-замок Одним из возможных не вполне корректных решений проблемы синхронизации является использование переменной-замка. Например, можно сделать условием вхождения в критическую секцию значение 0 некоторой разделяемой переменной lock. Сразу же после проверки это значение меняется на 1 (закрытие замка). При выходе из критической секции замок открывается (значение переменной lock сбрасывается в 0). TSL команды Многие вычислительные архитектуры имеют инструкции, которые могут обеспечить атомарность последовательности операций при входе в критическую секцию. Такие команды называются Test and_Set Lock или TSL командами. Спин-блокировка Рассмотренные решения проблемы синхронизации, безусловно, являются корректными. Они реализуют следующий алгоритм: перед входом в критическую секцию поток проверяет возможность входа и, если такой возможности нет, продолжает опрос значения переменной-замка. Такое поведение потока, связанное с его вращением в пустом цикле, называется активным ожиданием или спин-блокировкой (spin lock). Очевидно, что на однопроцессорной машине это пустая трата машинного времени, поскольку значение опрашиваемой переменной в течение этого цикла не может быть волшебным образом изменено. Спин-блокировка, хотя бы временная, может быть полезна на многопроцессорных машинах, где один из потоков крутится в цикле, а второй - работает на другом процессоре и может изменить значение переменной-замка. В этом случае у активно ожидающего потока есть шанс быстро войти в критическую секцию, не будучи блокированным. Блокировка потока связана с переходом в режим ядра (примерно 1000 тактов работы процессора).Однако более разумным решением, особенно на однопроцессорных машинах, представляется перевод потока в состояние ожидания, если вход в критическую секцию запрещен. После снятия запрета на вход в критическую секцию этот поток переводится в состояние готовности. Функции EnterCriticalSection и LeaveCriticalSection реализованы на основе Interlocked-функций, выполняются атомарным образом и работают очень быстро. Существенным является то, что в случае невозможности входа в критический участок поток переходит в состояние ожидания. Впоследствии, когда такая возможность появится, поток будет "разбужен" и сможет сделать попытку входа в критическую секцию. Механизм пробуждения потока реализован с помощью объекта ядра "событие" (event), которое создается только в случае возникновения конфликтной ситуации.Уже говорилось, что иногда, перед блокированием потока, имеет смысл некоторое время удерживать его в состоянии активного ожидания. Чтобы функция EnterCriticalSection выполняла заданное число циклов спин-блокировки, критическую секцию целесообразно проинициализировать с помощью функции InitalizeCriticalSectionAndSpinCount. Мьютексы также представляют собой объекты ядра, используемые для синхронизации, но они проще семафоров, так как регулируют доступ к единственному ресурсу и, следовательно, не содержат счетчиков. По существу они ведут себя как критические секции, но могут синхронизировать доступ потоков разных процессов. Инициализация мьютекса осуществляется функцией CreateMutex, для входа в критическую секцию используется функция WaitForSingleObject, а для выхода - ReleaseMutex. Если поток завершается, не освободив мьютекс, последний переходит в свободное состояние. Отличие от семафоров в том, что поток, занявший мьютекс, получает права на владение им. Только этот поток может освободить мьютекс. Поэтому мнение о мьютексе как о семафоре с максимальным значением 1 не вполне соответствует действительности. Известно, что семафоры, предложенные Дейкстрой в 1965 г., представляет собой целую переменную в пространстве ядра, доступ к которой, после ее инициализации, может осуществляться через две атомарные операции: wait и signal (в ОС Windows это функции WaitForSingleObject и ReleaseSemaphore соответственно). wait(S): если S <= 0 процесс блокируется (переводится в состояние ожидания); в противном случае S = S - 1; signal(S): S = S + 1 Семафоры обычно используются для учета ресурсов (текущее число ресурсов задается переменной S) и создаются при помощи функции CreateSemaphore, в число параметров которой входят начальное и максимальное значение переменной. Текущее значение не может быть больше максимального и отрицательным. Значение S, равное нулю, означает, что семафор занят.
Расшифруйте аббревиатуру ACID в применении к системному программированию и кратко охарактеризуйте значение каждого из слов. Какая из букв аббревиатуры не применима, когда речь идет о программной транзакционной памяти (STM)? Вступление. Транзакция – это некоторая форма выполнения программ, перенятая от сообщества баз данных [8]. Параллельно исполняемые запросы конфликтуют, когда они читают и изменяют некоторый элемент базы данных, и возникающий конфликт может привести к ошибочному результату, который не мог бы получиться при последовательном выполнении этих запросов. Транзакции гарантируют, что все запросы произведут тот же самый результат, как если бы они выполнялись последовательно в некотором порядке (serially, «сериально»; это свойство называют «сериализуемостью» (serializability)). Декомпозиция семантики транзакции приводит к четырем требованиям, обычно называемым свойствами ACID: атомарность (atomicity), согласованность (consistency), изоляция (isolation) и долговечность (durability) ACID (atomicity, consistency, isolation, durability).
В информатике, акроним ACID описывает требования к транзакционной системе (например, к СУБД), обеспечивающие наиболее надёжную и предсказуемую её работу. Требования ACID были в основном сформулированы в конце 70-х годов Джимом Греем Лингвистические корни STM.NET берут свое начало из самых разных областей, но концептуальная идея STM гениально проста и знакома: вместо того чтобы заставлять разработчиков придумывать средства распараллеливания (блокировки и все такое), дать им возможность помечать, какие части кода должны выполняться с теми или иными характеристиками дружественности к параллельной обработке, и разрешить инструментальным средствам языка (компилятору или интерпретатору) при необходимости самостоятельно управлять блокировками. Другими словами, разработчики подобно администраторам и пользователям баз данных помечают код атрибутами транзакционной семантики в стиле ACID и оставляют все черную работу по управлению блокировками нижележащей среде. Хотя STM.NET может показаться всего лишь еще одной попыткой управления параллельной обработкой, она отражает нечто более глубокое — поиск путей переноса всех четырех характеристик ACID -транзакций баз данных в модель программирования, размещенную в памяти. Помимо управления блокировками в интересах программиста, модель STM также обеспечивает атомарность (atomicity), согласованность (consistency), изоляцию (isolation) и надежность (durability), которые сами по себе могут значительно упростить программирование независимо от наличия нескольких потоков выполнения.
Атомарность заявляет, что база данных изменений должны следовать принципу "все или ничего". Каждая операция называется "атомной". Если одна часть сделки не удается, вся сделка не удается. Очень важно, что система управления базами данных сохраняет атомный характер операций, несмотря на любую операционную систему или аппаратный сбой. Последовательность заявляет, что только достоверные данные будут записаны в базу данных. Если по каким-то причинам совершается сделка, которая нарушает согласованность правил базы данных, вся сделка будет отменена, и база данных будет восстановлена в состоянии, в соответствии с этими правилами. С другой стороны, если операция успешно выполняется, это переведет базу данных из данного состояния, которое соответствует другому состоянию, которое также находится в соответствии с правилами. Изоляция требует, чтобы несколько изменений, совершенных в то же время, не влияли на исполнение друг друга. Например, если Джо запросил транзакции с базой данных в то же время, что Мария запросила различные сделки, и операции должны функционировать на базе данных, независимо. База данных должна либо выполнять весь запрос Джо перед выполнением запроса Марии или наоборот. Это предохраняет запрос Джо от чтения промежуточных данных, полученных в качестве побочного эффекта части запроса Марии, которая в конечном итоге не будет фиксироваться в базе данных. Обратите внимание, что изоляция собственности не обеспечивает исполнения, только того, что не конфликтует друг с другом. Долговечность гарантирует, что любое изменение, внесенное в базу данных, не будет потеряно. Долговечность обеспечивается за счет использования резервных копий баз данных и журналов транзакций, которые способствуют восстановлению совершенных изменений, несмотря на любые последующие программные или аппаратные сбои.
Не применима буква “I”(изоляция), т.к. при STM - транзакции выполняются таким образом, как будто текущая транзакция это единственная операция над текущими данными, а при ACID - несколько изменений, совершенных в то же время, не влияют на исполнение друг друга. 22. Что такое конвейер (PIPE)? Что такое именованный конвейер? Охарактеризуйте их. Как эти объекты можно использовать для взаимодействия программ (приведите несколько примеров)? Конвейеры (PIPE) — это возможность нескольких программ работать совместно, когда выход одной программы непосредственно идет на вход другой без использования промежуточных временных файлов. В программировании именованный канал или именованный конвейер (англ. named pipe) — расширение понятия конвейера в Unix и подобных ОС, один из методов межпроцессного взаимодействия. Это понятие также существует и в Microsoft Windows, хотя там его семантика существенно отличается. Традиционный канал — «безымянен», потому что существует анонимно и только во время выполнения процесса. Именованный канал — существует в системе и после завершения процесса. Он должен быть «отсоединён» или удалён когда уже не используется. Процессы обычно подсоединяются к каналу для осуществления взаимодействия между процессами. Именованные каналы в Unix Вместо традиционного, безымянного конвейера оболочки (англ. shell pipeline), именованный канал создаётся явно с помощью mknod или mkfifo, и два различных процесса могут обратиться к нему по имени. Например, можно создать канал и настроить gzip на сжатие того, что туда попадает: mkfifo pipe gzip -9 -c < pipe > out Параллельно, в другом процессе можно выполнить: cat file > pipe что приведёт к сжатию передаваемых данных gzip-ом.
Конвейер (pipe) - перенаправление ввода-вывода в Linux В UNIX-подобных операционных системах пользователю открывается огромный простор для перенаправления ввода-вывода команд.
23. Объясните разницу между взаимодействием программ с помощью разделяемой памяти и обмена сообщениями. Опишите преимущества и недостатки обоих вариантов. В каких случаях предпочтительно использование каждого из них? (приведите несколько примеров) Memory fragmentation Basic principle " Fragmented memory " denotes all of the system's unusable free memory. Memory fragmentation usually occurs when memory is allocated dynamically (using calls like malloc). Generally, memory allocation performed during runtime is not in the form of stacks. The memory allocator wastes memory in the following ways: 1. Overhead 2. Internal Fragmentation 3. External Fragmentation. Overhead The memory allocator needs to store all the information related to all memory allocations. This information includes the location, size and ownership of any free blocks, as well as other internal status details. Overhead comprises of all the additional system resources that the programming algorithm requires. A dynamic memory allocator typically stores this overhead information in the memory it manages. This leads to wastage of memory. Hence, it is considered as a part of memory fragmentation.
Internal fragmentation When the memory allocated is larger than required, the rest is wasted. Some reasons for excess allocation are: 1. Allocator policy - involves architectural constraints, 2. A client asks for more memory than is required. The term "internal" refers to the fact that the unusable storage is inside the allocated region. While this may seem foolish, it is often accepted in return for increased efficiency or simplicity.
External fragmentation
External fragmentation is the inability to use free memory as the free memory is divided into small blocks of memory and these blocks are interspersed with the allocated memory. It is a weakness of certain storage allocation algorithms, occurring when an application allocates and deallocates ("frees") regions of storage of varying sizes, and the allocation algorithm responds by leaving the allocated and deallocated regions interspersed. The result is that although free storage is available, it is effectively unusable because it is divided into pieces that are too small to satisfy the demands of the application. The term "external" refers to the fact that the unusable storage is outside the allocated regions.
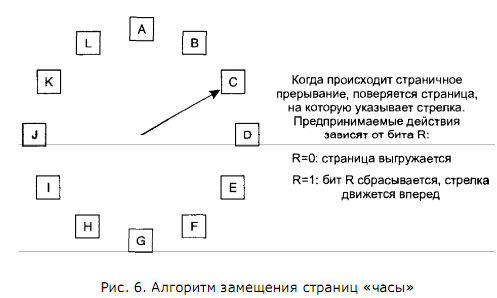
25. Какой максимальный адресуемый объем памяти для программы на 32-разрядной архитектуре? Почему объем доступной виртуальной памяти меньше максимального (куда девается разница)? На какие основные части делится виртуальная память работающей программы? Как это соотносится с форматами исполняемых файлов? Максимум 2^32 байт. Реально доступно меньше Например, при наличии видеоадаптера с 256 МБ собственной памяти эта память должна отображаться в первые 4 ГБ адресного пространства. Если на компьютере уже установлено 4 ГБ системной памяти, часть адресного пространства должна быть зарезервирована для отображения памяти видеоадаптера. Для отображения памяти видеоадаптера используется часть системной памяти. В результате общий объем системной памяти, доступной операционной системе, сокращается. То, насколько сократится объем доступной системной памяти, зависит от установленных на компьютере устройств. Memory-mapped I/O (MMIO) and port I/O (also called port-mapped I/O (PMIO) or isolated I/O) are two complementary methods of performing input/output between the CPU and peripheral devices in a computer. Another method, not discussed in this article, is using dedicated I/O processors — commonly known as channels on mainframe computers — that execute their own instructions. Memory-mapped I/O (not to be confused with memory-mapped file I/O) uses the same address bus to address both memory and I/O devices, and the CPU instructions used to access the memory are also used for accessing devices. In order to accommodate the I/O devices, areas of the CPU's addressable space must be reserved for I/O. The reservation might be temporary — the Commodore 64 could bank switch between its I/O devices and regular memory — or permanent. Each I/O device monitors the CPU's address bus and responds to any of the CPU's access of address space assigned to that device, connecting the data bus to a desirable device's hardware register. Алгоритм «часы» Хотя алгоритм «вторая попытка» является корректным, он слишком неэффективен, потому что постоянно передвигает страницы по списку. Поэтому лучше хранить все страничные блоки в кольцевом списке в форме часов, как показано на рис. 6. Стрелка указывает на старейшую страницу.
Когда происходит страничное прерывание, проверяется та страница, на которую направлена стрелка. Если ее бит R равен 0, страница выгружается, на ее место в часовой круг встает новая страница, а стрелка сдвигается вперед на одну позицию. Если бит R равен 1, то он сбрасывается, стрелка перемещается к следующей странице. Этот процесс повторяется до тех пор, пока не находится та страница, у которой бит R = 0. Неудивительно, что этот алгоритм называется «часы». Он отличается от алгоритма «вторая попытка» только своей реализацией. "Часы" реализуются так: элементы кэша хранятся в виде списка, по которому указатель перемещается каждый раз, когда нужно найти свободный участок. Записи помечаются флагом "используется", который определяет, что указатель должен освобождать эту запись для последующего использования. Каждый раз, когда указатель находит запись с флагом, он сбрасывает флаг, чтобы при следующем проходе запись могла быть освобождена. Освобождение записи кэша возможно только при не установленном для неё флаге "используется", поэтому, указатель проходит по списку записей, пока не обнаружит запись без флага, после полного прохода по списку - начиная с его начала, по кругу, вследствие чего алгоритм и получил свое название. Недостатки: строгая цикличность замедляет работу. Преимущества: простота и надежность.
30. Сформулируйте алгоритм выбора кандидата на удаление из кэша “Наименее недавно использовавшийся” (LRU). Опишите его работу на простом примере. В чем его преимущества и недостатки? Кэш или кеш (англ. cache, от фр. cacher — прятать; произносится [kæʃ] — кэш) — промежуточный буфер с быстрым доступом, содержащий информацию, которая может быть запрошена с наибольшей вероятностью. Доступ к данным в кэше идёт быст
|
||||
|
|
Последнее изменение этой страницы: 2016-08-16; просмотров: 544; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.223.172.180 (0.02 с.) |

 POSIX - это развивающийся набор стандартов, каждый их которых охватывает различные аспекты операционных систем. Некоторые из них уже одобрены, в то время как другие все еще находятся на стадии разработки. Их можно разбить на три группы:
POSIX - это развивающийся набор стандартов, каждый их которых охватывает различные аспекты операционных систем. Некоторые из них уже одобрены, в то время как другие все еще находятся на стадии разработки. Их можно разбить на три группы:
 2. Языковые интерфейсы. Эти стандарты обеспечивают действующие интерфейсы к различным языкам программирования. В настоящее время это языки СИ, АДА, ФОРТРАН 77 и ФОРТРАН 90. В табл. 3 приводятся разрабатываемые в настоящее время стандарты POSIX на интерфейсы языков программирования.
2. Языковые интерфейсы. Эти стандарты обеспечивают действующие интерфейсы к различным языкам программирования. В настоящее время это языки СИ, АДА, ФОРТРАН 77 и ФОРТРАН 90. В табл. 3 приводятся разрабатываемые в настоящее время стандарты POSIX на интерфейсы языков программирования. Операционная среда Открытых Систем. Эти стандарты включают руководство по операционной среде POSIX и прикладные профили. Прикладной профиль - это стандарты POSIX вместе с их опциями и параметрами, которые необходимы для конкретной прикладной среды. Прикладные профили - это весьма важное средство, позволяющее получить небольшое количество хорошо определенных типов реализации операционных систем для конкретных прикладных контекстов. В табл. 4 приводятся разрабатываемые в настоящее время стандарты этой группы.
Операционная среда Открытых Систем. Эти стандарты включают руководство по операционной среде POSIX и прикладные профили. Прикладной профиль - это стандарты POSIX вместе с их опциями и параметрами, которые необходимы для конкретной прикладной среды. Прикладные профили - это весьма важное средство, позволяющее получить небольшое количество хорошо определенных типов реализации операционных систем для конкретных прикладных контекстов. В табл. 4 приводятся разрабатываемые в настоящее время стандарты этой группы.