
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Восстановление символической записи команды по ее машинному представлениюСодержание книги
Поиск на нашем сайте
Для специалиста, работающего с компьютером как на программном, так и на аппаратном уровне, иногда возникает необходимость идентифицировать командную информацию, хранящуюся в оперативной памяти. Это может потребоваться, например, в случае программно-аппаратного сбоя, причину и место которого трудно определить традиционными методами и средствами тестирования и отладки программ. Так как исполняемый модуль программы хранится в памяти в машинном представлении, то для лучшего понимания действий, выполняемых компьютером в определенный момент, целесообразно преобразовать команду к символическому виду. Программы, выполняющие такое преобразование, называются дизассемблерами. Рассмотрим несколько примеров подобных преобразований. Для правильной интерпретации команды необходимо знать положение ее первого байта. В рассматриваемых примерах будем полагать, что оно известно. Пример 9. Представить символическую запись команды, имеющей следующую машинную форму: 0000h. Так как поля команды определяются с точностью до бита, то необходимо сначала перейти от шестнадцатеричного к двоичному представлению команды и, исходя из общих принципов кодирования команд, определить назначение всех ее разрядов:
По таблице машинного представления команд (см. табл. 6.4) определим, что КОП=000000 b соответствует общему формату операции сложения ADD. Тогда два младших бита первого байта кодируют признаки d и w, а второй байт является постбайтом, определяющим режимы адресации операндов, участвующих в операции. Значение полей в постбайте позволяет определить, что операндами будут регистр AL (reg=000, w=0) (см. табл. 6.1) и байт памяти, адресуемый с помощью базово-индексной адресации через регистры BX и SI (md=00, r/m=000) (см. табл. 6.2). Значение d=0 указывает, что регистр AL является операндом-источником. Следовательно, символическая запись команды имеет вид: ADD [BX+SI],ALПример 10. Представить символическую запись команды, имеющей следующую машинную форму: 81475D398B h. Переходим к двоичному представлению команды:
Первый байт, согласно таблице машинного представления команд, соответствует команде сложения с непосредственным операндом. Постбайт в этом случае кодирует местоположение лишь одного операнда, которое определяется полями md и r/m: (BX)+disp8 (см. табл. 6.2), а среднее поле постбайта является расширением кода операции. Адресация операнда требует указания в команде 8-разрядного смещения. Оно помещается сразу же за постбайтом. Последние байты команды кодируют непосредственный операнд. Значение sw=01 в первом байте команды указывает на то, что непосредственный операнд - 16-разрядный. Учитывая, что при кодировании в команде двухбайтовых величин сначала записывается их младший байт, получим следующую символическую запись команды: ADD [BX+5D],8B39hПример 11. Пусть машинная форма представления команды следующая: 0445h. Тогда ее двоичный вид:
По таблице машинного представления команд определяем, что это команда специального формата, обеспечивающая суммирование аккумулятора с непосредственным операндом. Так как w=0, то непосредственный операнд имеет длину 1 байт, а в качестве аккумулятора используется регистр AL. При этом команда имеет следующий вид: ADD AL,45h
Пример 1. ADD ES:[BX],DX Команда формата "память-регистр". Базовое время: 16+EA. Время вычисления EA (регистровая косвенная адресация): 5 тактов. Обозначение "ES:" в символической записи команды показывает, что в процессе формирования физического адреса операнда происходит замена сегментного регистра. Вместо используемого по умолчанию при данном режиме адресации сегментного регистра DS используется регистр ES. Эта операция требует 2 тактов синхронизации. Команда обрабатывает слово. Если слово имеет нечетный адрес, то Т=16+5+2+2*4=31 (такт)=310 (нс) Если слово имеет четный адрес, то Т=16+5+2=23 (такта)=230 (нс) |




Пример 2.
MUL [BX]
Умножение без знака содержимого AL на операнд, адрес которого задан в команде. Операнд находится в памяти.
Базовое время: (76...83)+EA.
Время вычисления EA (регистровая косвенная адресация): 5 тактов.
Т=(76...83)+5 = (81...88) тактов = (810...880) нс
Пример 3.
JZ MET; перейти на MET, если "ноль"
Базовое время: 4 такта, если нет перехода, и 16 тактов, если переход выполняется.
Других затрат времени нет.
Т=4 такта=40 нс перехода нет.
Т=16 тактов=160 нс переход выполняется.
Пример 4.
JMP dword ptr [SI+15]; межсегментный косвенный переход.
Базовое время: 24+EA.
Время вычисления EA (регистровая относительная адресация): 9 тактов.
Имеются 2 обращения к памяти за новыми значениями IP и CS.
Если адрес слова четный, то
Т=24+9=33 (такта)=330 (нс).
Если адрес слова нечетный, то
Т=24+9+2*4=41 (такт)=410 (нс).
Время выполнения линейного участка программы равно сумме времен выполнения всех команд этого участка.
Оценим время выполнения ветвящейся программы на примере следующей задачи:

Ниже представлен текст соответствующей программы в предположении, что A, B и y - переменные длиной 1 байт, имеющие идентификаторы MA, MB и MY соответственно. Здесь и далее полагаем, что используемые адреса в сегменте данных - четные. Рядом с каждой командой указано количество тактов синхронизации, необходимое для ее выполнения (идентификаторы соответствуют прямому режиму адресации):
MOV BL,5; 4
MOV AL,MA; 10
CMP AL,MB; 15
JG OUT; 4/16
INC BL; 3
OUT: MOV MY,BL; 15
Таким образом, если A>B, то программа выполняется за 60 тактов, в противном случае - за 51 такт.
Если оба случая равновероятны, то
Тср = (Т1+Т2)/2 = 55.5 (такта).
В общем случае для данной программы
Тср = 4+10+15+16*p1+(4+3)*p2+15=44+16*p1+7*p2.
где p1 и p2 - вероятности перехода в команде JG в случае выполнения и невыполнения условия соответственно (p1+p2=1).
Если известна количественная или хотя бы качественная оценка соотношения p1 и p2, то можно минимизировать среднее время выполнения данного фрагмента программы.
Пусть известно, что A>B при 90% различных исходных данных. Тогда для рассмотренной программы:
Тср = 44+0.9*16+0.1*7=59.1 (такта).
При обратном соотношении, то есть при p1=0.1:
Тср = 44+0.1*16+0.9*7=51.9 (такта).
Следовательно, при p1=0.1 быстрее будет выполняться программа, меняющая условие перехода:
MOV BL,6; 4
MOV AL,MA; 10
CMP AL,MB; 15
JNG OUT; 4/16
DEC BL; 3
OUT: MOV MY,BL; 15
Она дает то же самое среднее время выполнения программы при p1=p2, но выигрыш при p1>p2 и проигрыш при p1<p2.
В циклических программах тело цикла выполняется многократно. В силу этого целесообразно, по возможности, минимизировать этот участок программы даже за счет увеличения времени выполнения подготовительных операций и операций обработки результатов циклического участка.
Рассмотрим это положение на следующем примере. Пусть необходимо вычислить произведение двух целых положительных чисел длиной в слово (S=M*N), не используя команду умножения. Предполагаем, что операнды располагаются в памяти по эффективным адресам, вычисляемым как [SI+2A] и [1148h], а результат также не превышает одного слова и должен быть записан в память по адресу [BX+SI]. Предполагаем также, что все адреса в сегменте данных четные.
Решать задачу будем по следующей схеме:

Рассмотрим несколько возможных вариантов решения.
Вариант 1.
MOV [BX+SI],0; 17
MOV AX,[1148h]; 10
CYCLE: ADD [BX+SI],AX; 23
DEC [SI+2A]; 24
JNZ CYCLE; 4/16
Вариант 2.
MOV AX,[1148h]; 10
MOV CX,[SI+2A]; 17
SUB DX,DX; 3
CYCLE: ADD DX,AX; 3
DEC CX; 2
JNZ CYCLE; 4/16
MOV [BX+SI],DX; 16
Вариант 3.
MOV AX,[1148h]; 10
MOV CX,[SI+2A]; 17
SUB DX,DX; 3
CYCLE: ADD DX,AX; 3
LOOP CYCLE; 15/17
MOV [BX+SI],DX; 16
Вариант 1 использует минимальное общее количество команд. В варианте 2 обработка идет в регистрах общего назначения, но не используется специальная команда цикла, которая использована в варианте 3.
Сравнительные характеристики этих вариантов представлены в табл. 9.3
| Таблица 9.3. | |||
| Вариант | Количество команд | Длина программы, (байт) | Время выполнения, (такт) |
| 63N+15 | |||
| 21N+34 | |||
| 20N+34 |
Таким образом, даже несмотря на некоторое увеличение длины, программа, реализованная в вариантах 2 и 3, при достаточно больших N выполняется почти втрое быстрее, чем реализованная в варианте 1.
Так как время выполнения этих программ зависит от величины лишь одного сомножителя, то в том случае, когда известны относительные величины сомножителей, это время можно минимизировать, используя в качестве счетчика наименьший из сомножителей.
| 10. Лекция: Взаимодействие основных узлов и устройств персонального компьютера при автоматическом выполнении команды. Архитектура 32-разрядного микропроцессора | |

| |

| |

| |
| Страницы: 1 | 2 | вопросы |» | | учебники | для печати и PDA | ZIP |
|
| |
| Если Вы заметили ошибку - сообщите нам, или выделите ее и нажмите Ctrl+Enter | |
|
| |
| Рассматриваются особенности функционирования персонального компьютера при автоматическом выполнении команды. Рассматриваются особенности 32-разрядного микропроцессора с архитектурой IA-32. | |
|
| |
|
| |
|
| |
Взаимодействие основных узлов и устройств персонального компьютера при автоматическом выполнении команды
Основные этапы автоматического выполнения программы в компьютере с классической трехадресной архитектурой были рассмотрены в лекции 3. В этой лекции рассмотрим особенности этого процесса на примере функционирования персонального компьютера, использующего 16 разрядный микропроцессор типа I8086.
Структура такого компьютера приведена на рис. 10.1. В составе ЭВМ кроме традиционных устройств компьютера с классической архитектурой (оперативное запоминающее устройство, арифметико-логическое устройство и основные схемы устройства управления) выделим следующие блоки:
 Рис. 10.1. Структурная схема базовой модели персональной ЭВМ
На входы регистровой памяти из БФАО поступают номера регистров, к которым проводится обращение. На входы выбираемых регистров поступают из АЛУ результаты выполнения операции и значения сегментных регистров, устанавливаемых операционной системой ЭВМ. В регистрах хранятся составляющие эффективных адресов данных, исходные и промежуточные данные, участвующие в выполнении операции, старшие 16 разрядов базовых адресов сегментов.
На блок формирования адреса операнда поступают: Рис. 10.1. Структурная схема базовой модели персональной ЭВМ
На входы регистровой памяти из БФАО поступают номера регистров, к которым проводится обращение. На входы выбираемых регистров поступают из АЛУ результаты выполнения операции и значения сегментных регистров, устанавливаемых операционной системой ЭВМ. В регистрах хранятся составляющие эффективных адресов данных, исходные и промежуточные данные, участвующие в выполнении операции, старшие 16 разрядов базовых адресов сегментов.
На блок формирования адреса операнда поступают:
|
Архитектура 32-разрядного микропроцессора
В 1985 году фирма Intel выпустила 32-разрядный микропроцессор, ставший родоначальником семейства IA-32. Развитие этого семейства прошло ряд этапов, среди которых можно выделить следующие: реализация блока обработки чисел с плавающей запятой непосредственно на кристалле МП (микропроцессор I486), введение MMX-технологии обработки данных с фиксированной точкой по принципу SIMD - singl instruction multi data (один поток команд - множество потоков данных) в микропроцессоре Pentium MMX и развитие этой технологии на числа с плавающей запятой (SSE - streaming SIMD Extention), появившееся впервые в МП Pentium III [[4], [9]]. Однако основные черты этой архитектуры вплоть до настоящего времени остаются неизменными.
Архитектура 32-разрядного микропроцессора (рис. 10.2) существенно отличается от архитектуры 16-разрядного. Некоторые из этих отличий чисто количественные, другие носят принципиальный характер.
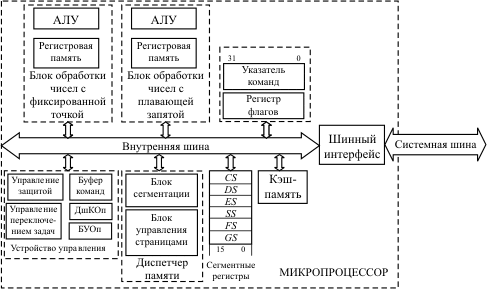 Рис. 10.2. Структура 32-разрядного микропроцессора
Главное внешнее отличие - увеличение разрядности шины данных и шины адреса до 32 бит. Это, в свою очередь, связано с изменениями в разрядности внутренних элементов микропроцессора и в механизме выполнения некоторых процессов, например, формирования физического адреса.
Регистры блока обработки чисел с фиксированной точкой стали 32-разрядными. К каждому из них можно обращаться как к одному двойному слову (32 разряда). К младшим 16 разрядам этих регистров можно обращаться так же, как и в 16-разрядном микропроцессоре.
В блоке сегментных регистров произошли как количественные, так и качественные изменения. К используемым в реальном режиме четырем регистрам CS, DS, SS и ES добавлены еще два: FS и GS. Хотя разрядность регистров этого блока осталась прежней (каждый по 16 бит), в формировании физического адреса оперативной памяти они используются по-другому. При работе микропроцессора в так называемом защищенном режиме они предназначаются для поиска дескриптора (описателя) сегмента в соответствующих системных таблицах, а уже в дескрипторе хранится базовый адрес и атрибуты сегмента. Формирование адреса в этом случае выполняет блок сегментации диспетчера памяти.
Если помимо сегментов память разбита еще и на страницы, то окончательное вычисление физических адресов выполняет блок управления страницами.
Начиная с микропроцессора I486, в состав кристалла микропроцессора входит блок обработки чисел с плавающей запятой, включающий в себя восемь 80-разрядных регистров для представления знаков, мантисс и порядков таких чисел.
На кристалле микропроцессора располагается также внутренняя кэш-память, которая представляет собой особым образом организованную быстродействующую буферную память, предназначенную для хранения наиболее часто используемой информации (команд и данных). В различных моделях микропроцессоров объем кэш-памяти составляет от 8 Кбайт до 512 Кбайт.
Микропроцессор на аппаратном уровне поддерживает мультипрограммный режим работы ЭВМ, то есть возможность иметь в памяти одновременно несколько готовых к выполнению программ, запуск которых осуществляется операционной системой в соответствии с алгоритмами ее функционирования либо в зависимости от особых ситуаций, складывающихся в работе внешних устройств.
С этой возможностью неразрывно связаны средства защиты памяти, которые обеспечивают контроль над неразрешенными взаимодействиями между отдельными программами. Они включают в себя защиту при управлении памятью и защиту по привилегиям.
Главные особенности расширенного формата команды - возможность использовать любой из регистров общего назначения в любом из режимов адресации, а также добавление еще одного режима адресации - относительного базового индексного с масштабированием. При этом эффективный адрес формируется следующим образом:
ЭА = (base) + (index) · scale + disp,
где (base) - значение базового регистра; (index) - значение индексного регистра; scale - величина масштабного множителя (scale = 1,2,3,4); disp - значение смещения, закодированного в самой команде.
Отметим, что в 32-разрядной архитектуре эффективный адрес обычно называют смещением (offset), в то же время отличая его от смещения, кодируемого в самой команде (displacement). Рис. 10.2. Структура 32-разрядного микропроцессора
Главное внешнее отличие - увеличение разрядности шины данных и шины адреса до 32 бит. Это, в свою очередь, связано с изменениями в разрядности внутренних элементов микропроцессора и в механизме выполнения некоторых процессов, например, формирования физического адреса.
Регистры блока обработки чисел с фиксированной точкой стали 32-разрядными. К каждому из них можно обращаться как к одному двойному слову (32 разряда). К младшим 16 разрядам этих регистров можно обращаться так же, как и в 16-разрядном микропроцессоре.
В блоке сегментных регистров произошли как количественные, так и качественные изменения. К используемым в реальном режиме четырем регистрам CS, DS, SS и ES добавлены еще два: FS и GS. Хотя разрядность регистров этого блока осталась прежней (каждый по 16 бит), в формировании физического адреса оперативной памяти они используются по-другому. При работе микропроцессора в так называемом защищенном режиме они предназначаются для поиска дескриптора (описателя) сегмента в соответствующих системных таблицах, а уже в дескрипторе хранится базовый адрес и атрибуты сегмента. Формирование адреса в этом случае выполняет блок сегментации диспетчера памяти.
Если помимо сегментов память разбита еще и на страницы, то окончательное вычисление физических адресов выполняет блок управления страницами.
Начиная с микропроцессора I486, в состав кристалла микропроцессора входит блок обработки чисел с плавающей запятой, включающий в себя восемь 80-разрядных регистров для представления знаков, мантисс и порядков таких чисел.
На кристалле микропроцессора располагается также внутренняя кэш-память, которая представляет собой особым образом организованную быстродействующую буферную память, предназначенную для хранения наиболее часто используемой информации (команд и данных). В различных моделях микропроцессоров объем кэш-памяти составляет от 8 Кбайт до 512 Кбайт.
Микропроцессор на аппаратном уровне поддерживает мультипрограммный режим работы ЭВМ, то есть возможность иметь в памяти одновременно несколько готовых к выполнению программ, запуск которых осуществляется операционной системой в соответствии с алгоритмами ее функционирования либо в зависимости от особых ситуаций, складывающихся в работе внешних устройств.
С этой возможностью неразрывно связаны средства защиты памяти, которые обеспечивают контроль над неразрешенными взаимодействиями между отдельными программами. Они включают в себя защиту при управлении памятью и защиту по привилегиям.
Главные особенности расширенного формата команды - возможность использовать любой из регистров общего назначения в любом из режимов адресации, а также добавление еще одного режима адресации - относительного базового индексного с масштабированием. При этом эффективный адрес формируется следующим образом:
ЭА = (base) + (index) · scale + disp,
где (base) - значение базового регистра; (index) - значение индексного регистра; scale - величина масштабного множителя (scale = 1,2,3,4); disp - значение смещения, закодированного в самой команде.
Отметим, что в 32-разрядной архитектуре эффективный адрес обычно называют смещением (offset), в то же время отличая его от смещения, кодируемого в самой команде (displacement).
|
|
|
| 11. Лекция: Конвейерная организация работы процессора | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Страницы: 1 | 2 | 3 | вопросы |» | | учебники | для печати и PDA | ZIP | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Если Вы заметили ошибку - сообщите нам, или выделите ее и нажмите Ctrl+Enter | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Рассматривается конвейерная организация работы идеального микропроцессора, сравнение производительности его работы с последовательной обработкой команд, типы и причины конфликтов в конвейере и пути уменьшения их влияния на работу микропроцессора. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Оценка производительности идеального конвейера
Выполнение каждой команды складывается из ряда последовательных этапов (шагов, стадий), суть которых не меняется от команды к команде. С целью увеличения быстродействия процессора и максимального использования всех его возможностей в современных микропроцессорах используется конвейерный принцип обработки информации. Этот принцип подразумевает, что в каждый момент времени процессор работает над различными стадиями выполнения нескольких команд, причем на выполнение каждой стадии выделяются отдельные аппаратные ресурсы. По очередному тактовому импульсу каждая команда в конвейере продвигается на следующую стадию обработки, выполненная команда покидает конвейер, а новая поступает в него.
В различных процессорах количество и суть этапов различаются. Рассмотрим принципы конвейерной обработки информации на примере пятиступенчатого конвейера, в котором выполнение команды складывается из следующих этапов:
Пусть для выполнения отдельных стадий обработки требуются следующие затраты времени (в некоторых условных единицах): TIF = 20, TID = 15, TOR = 20, TEX = 25, TWB = 20. Тогда, предполагая, что дополнительные расходы времени составляют dt = 5 единиц, получим время такта: T = max {TIF, TID, TOR, TEX, TWB} + Δt = 30. Оценим время выполнения одной команды и некоторой группы команд при последовательной и конвейерной обработке. При последовательной обработке время выполнения N команд составит: Tпосл = N*(TIF + TID + TOR + TEX + TWB) = 100N. Анализ таблица 11.1 показывает, что при конвейерной обработке после того, как получен результат выполнения первой команды, результат очередной команды появляется в следующем такте работы процессора. Следовательно, Tконв = 5T + (N-1) * T. Примеры длительности выполнения некоторого количества команд при последовательной и конвейерной обработке приведены в таблица 11.2.
Очевидно, что при достаточно длительной работе конвейера его быстродействие будет существенно превышать быстродействие, достигаемое при последовательной обработке команд. Это увеличение будет тем больше, чем меньше длительность такта конвейера и чем больше количество выполненных команд. Сокращение длительности такта достигается, в частности, разбиением выполнения команды на большое число этапов, каждый из которых включает в себя относительно простые операции и поэтому может выполняться за короткий промежуток времени. Так, если в микропроцессоре Pentium длина конвейера составляла 5 ступеней (при максимальной тактовой частоте 200 МГц), то в Pentium-4 - уже 20 ступеней (при максимальной тактовой частоте на сегодняшний день 3,4 ГГц). |
|
| Поделиться: |



