
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Реализации множества на базе деревьевСодержание книги
Поиск на нашем сайте
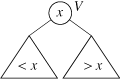
Реализация множества с помощью бинарного поиска во всех отношениях лучше нативной реализации. Вместе с тем, она все же имеет недостатки: 1) при добавлении и удалении элементов в середине массива приходится переписывать элементы в конце массива на новое место, чтобы освободить место для добавляемого элемента либо закрыть образовавшуюся лакуну при удалении элемента; 2) поиск выполняется гарантированно быстро, но все-таки не мгновенно. От первого из этих недостатков можно избавиться, применяя вместо непрерывной реализации на базе массива ссылочную реализацию, при которой элементы множества содержатся в вершинах бинарного дерева. Элементы в вершинах упорядочены таким образом, что, если зафиксировать некоторую вершину V и рассмотреть два поддерева, соответствующих левому и правому сыновьям вершины, то все элементы в вершинах левого поддерева должны быть меньше, чем элемент в вершине V, а все элементы в вершинах правого поддерева должны быть больше него.
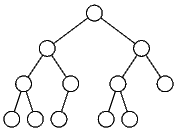
Для такого дерева можно также применять алгоритм бинарного поиска. Максимальное число сравнений при поиске в таком дереве равняется его высоте (т.е. максимальной длине пути от корня к терминальной вершине). Чтобы поиск выполнялся быстро, дерево должно быть сбалансированным, т.е. все его ветви должны иметь почти одинаковую длину. Точное определение сбалансированности следующее: будем считать, что у каждой вершины, включая терминальные, ровно два сына, при необходимости добавляя внешние, или нулевые, вершины. Например, у терминальной вершины оба сына нулевые. (Это в точности соответствует представлению дерева в языке Си, где каждая вершина хранит два указателя на сыновей; если сына нет, то соответствующий указатель нулевой.) Обычные вершины дерева будем называть собственными. Рассмотрим путь от корня дерева к внешней (нулевой) вершине. Длиной пути считается количество собственных вершин в нем. Дерево называется сбалансированным, если длины всех возможных путей от корня дерева к внешним вершинам различаются не более чем на единицу. Иногда в литературе такие деревья называют почти сбалансированными, понимая под сбалансированностью строгое равенство длин всех путей от корня к внешним узлам; мы, однако, будем придерживаться нестрогого определения. Пример сбалансированного дерева представлен на рисунке.
h <= log2n + 1 Поскольку максимальное число сравнений при поиске элемента в упорядоченном бинарном дереве равняется высоте дерева, поиск в сбалансированном дереве осуществляется исключительно быстро, за время, логарифмически зависящее от числа элементов множества. (это является теоретической оценкой снизу: никакой алгоритм не может в общем случае находить элемент быстрее, чем за log2n операций.) Для эффективной реализации множества на базе дерева процедуры добавления и удаления элементов должны сохранять свойство сбалансированности (или почти сбалансированности). Рассмотрим коротко две наиболее популярные схемы реализации. Красно-черные деревья, AVG-деревья.
AVL-деревья Так называемые AVL-деревья (названные в честь их двух изобретателей Г.М. Адельсона-Вельского и Е.М. Ландиса) хранят дополнительно в каждой вершине разность между высотами левого и правого поддеревьев, которая в сбалансированном дереве может принимать только три значения: -1, 0, 1. Строго говоря, AVL-деревья не являются сбалансированными в смысле приведенного выше определения. Требуется только, чтобы для любой вершины AVL-дерева разность высот ее левого и правого поддеревьев была по абсолютной величине не больше единицы. При этом длины путей от корня к внешним вершинам могут различаться больше, чем на единицу. Можно, тем не менее, доказать, что и в случае AVL-деревьев их высота оценивается сверху логарифмически в зависимости от числа вершин: h <= C log2 n где константа C = 1.5. Обычно константы не очень важны в практическом программировании — принципиально лишь, по какому закону увеличивается время работы алгоритма при увеличении n. В данном случае зависимость логарифмическая, т.е. наилучшая из всех возможных (поскольку поиск невозможен быстрее чем за log2 n операций). Новый элемент всегда добавляется в дерево в соответствии с упорядоченностью как левый или правый сын некоторой вершины, у которой данного сына до этого не было (или, как мы считаем, сын являлся внешним). Новая вершина добавляется как терминальная. После этого выполняется процедура восстановления балансировки. В ней используются следующие элементарные преобразования дерева, сохраняющие упорядоченность вершин: 1. вращение вершины x поддерева влево:
2. вращение вершины x поддерева вправо:
Операции вращения носят локальный характер и позволяют при необходимости исправить баланс поддерева с корнем x. Например, для восстановления баланса дерева, показанного на следующем рисунке, достаточно выполнить одно вращение вершины b влево:
Красно-черные деревья Исторически AVL-деревья, изобретенные в 1962 г., были одной из первых схем реализации почти сбалансированных деревьев. В настоящее время, однако, более популярна другая схема: красно-черные деревья, или RB-деревья, от англ. Red-Black Trees. Красно-черные деревья были введены Р. Байером в 1972 г. В стандартной библиотеке классов языка C++ исполнители множество и нагруженное множество — классы set и map — реализованы именно как красно-черные деревья. Вместо баланс-фактора, применяемого в AVL-деревьях, RB-деревья используют цвета вершин. Каждая вершина окрашена либо в красный, либо в черный цвет. (В реализации за цвет отвечает логическая переменная.) При этом выполняется несколько дополнительных условий: 1. каждая внешняя (или нулевая) вершина считается черной; 2. корневая вершина дерева черная; 3. у красной вершины дети черные; 4. всякий путь от корня дерева к произвольной внешней вершине имеет одно и то же количество черных вершин.
Пример красно-черного дерева. Из пункта 3) определения следует, что в произвольном пути от корня к терминальной вершине не может быть двух красных вершин подряд. Это означает, что, поскольку число черных вершин в любом пути одинаково, длины разных путей к терминальным вершинам отличаются не более чем вдвое. Это свойство близко по своей сути к сбалансированности. Несложно показать, что для красно-черного дерева справедлива следующая оценка сверху на высоту дерева в зависимости от числа вершин: h <= 2 log2 (n+1) Из этого следует, что поиск в красно-черном дереве также выполняется за логарифмическое время. Новая вершина добавляется в красно-черное дерево как терминальная после процедуры поиска (этим RB-дерево ничем не отличается от других упорядоченных деревьев). Новая вершина окрашивается в красный цвет. При этом пункт 3) в определении красно-черного дерева может нарушиться. Поэтому после добавления, а также удаления вершины выполняется процедура восстановления структуры красно-черного дерева, играющая ту же роль, что и восстановление балансировки AVL-дерева. Преимущество красно-черных деревьев состоит в том, что процедура восстановления более простая. Во многих случаях она ограничивается перекрашиванием вершин. В ней также могут выполняться операции вращения вершины влево и вправо, но число вращений может быть не больше двух при добавлении элемента и не больше четырех при удалении. Всего число операций при восстановлении структуры RB-дерева оценивается сверху через высоту дерева: число операций <= K x h где h — высота дерева, K — константа. Поскольку для высоты RB-дерева справедлива приведенная выше логарифмическая оценка от числа вершин n, получаем оценку число операций <= C log2 n где C - константа. Таким образом, добавление и удаление элементов выполняется в случае красно-черных деревьев за логарифмическое время в зависимости от числа вершин дерева.
Хеширование Рассмотрим другую реализацию множества, в которой поиск элемента чаще всего происходит почти мгновенно. Правда, в исключительных случаях поиск может быть долгим, и поэтому такая реализация не подходит для программ, в которых требуется повышенная надежность, например, при управлении реальными процессами. Идея хеш-реализации состоит в том, что мы сводим работу с одним большим множеством к работе с массивом небольших множеств. Рассмотрим, к примеру, записную книжку. Она содержит список фамилий людей с их телефонами (телефоны — это нагрузка элементов множества). Страницы записной книжки помечены буквами алфавита; страница, помеченная некоторой буквой, содержит только фамилии, начинающиеся с этой буквы. Таким образом, все множество фамилий разбито на 26 подмножеств, соответствующих буквам латинского алфавита. При поиске фамилии мы сразу открываем записную книжку на странице, помеченной первой буквой фамилии, и в результате поиск значительно убыстряется. Разбиение множества на подмножества осуществляется с помощью так называемой хеш-функции. Хеш-функция определена на элементах множества и принимает целые неотрицательные значения. Она должна быть подобрана таким образом, чтобы 1) ее можно было легко вычислять; 2) она должна принимать всевозможные различные значения приблизительно с равной вероятностью; 3) желательно, чтобы на близких значениях аргумента она принимала далекие друг от друга значения (свойство, противоположное математическому понятию непрерывности). В приведенном примере значение хеш-функции для данной фамилии равно номеру первой буквы фамилии в русском (английском) алфавите. Параметром реализации является число подмножеств, которое также называют размером хеш-таблицы. Пусть он равен N. Тогда хеш-функция должна принимать значения 0, 1, 2,..., N - 1. Если изначально у нас есть некоторая функция H(x), принимающая произвольные целые неотрицательные значения, то в качестве хеш-функции можно использовать функцию h(x), равную остатку от деления H(x) на N. Множество M разбивается на N непересекающихся подмножеств, занумерованных индексами от 0 до N - 1. Подмножество Mi с индексом i содержит все элементы x из M, значения хеш-функции для которых равняются i:
При поиске элемента x сначала вычисляется значение его хеш-функции: t = h(x). Затем мы ищем x в подмножестве Mt. Поскольку это подмножество небольшое, то поиск осуществляется быстро. Для эффективной реализации каждое подмножество должно в большинстве случаев содержать не больше одного элемента. Следовательно, размер хеш-таблицы N должен быть больше, чем среднее число элементов множества. Обычно N выбирают превышающим число элементов множества примерно в три раза. В примере с записной книжкой это означает, что в ней должно быть записано около 10 фамилий. В таком случае большинство страниц либо пустые, либо содержат одну фамилию, хотя не исключены и коллизии, когда на одной странице записаны несколько фамилий. Различные конкретные схемы по-разному реализуют массив подмножеств и борются с коллизиями. В основном механизм решения коллизий строится на: открытом хешировании (с раздельными цепочками) и закрытом хешировании (с открытой адресацией) Открытое хеширование Приоткрытом хешировании ключи хранятся в связанных списках, присоединенных к ячейкам хеш-таблицы. Каждый список содержит все ключи, хешированные в данную ячейку.
Это наиболее универсальная схема, использующая ссылочную реализацию. Каждое подмножество представляется в виде линейного однонаправленного списка, содержащего элементы подмножества. Таким образом, имеем N списков. Головы всех списков хранятся в одном массиве размера N, который называется хеш-таблицей. Элемент хеш-таблицы с индексом i представляет собой голову i -го Закрытое хеширование В случае закрытого хеширования все ключи хранятся в хеш-таблице без использования связанных списков. Простейшая стратегия реализации - линейное исследование, когда в случае коллизии ячейки проверяются одна за другой. Если ячейка пуста, то новый ключ вносится в нее, если заполнена- проверяется ячейка следующая за ней. На рисунке показано, как выглядит хеш-таблица при закрытом хешировании с линейным исследованием в случае вставки ключей с коллизиями.
|
||||
|
|
Последнее изменение этой страницы: 2016-08-06; просмотров: 449; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.15.145.50 (0.008 с.) |

 Высота сбалансированного дерева h оценивается логарифмически в зависимости от числа вершин n:
Высота сбалансированного дерева h оценивается логарифмически в зависимости от числа вершин n: Здесь вершина x поддерева, которая является его корнем, опускается вниз и влево. Бывший правый сын d вершины x становится новым корнем поддерева, а x становится левым сыном d. (Вершиныx и d, начальник и подчиненный, как бы меняются ролями: бывший начальник становится подчиненным.) Поддерево c, которое было левым сыном вершины d, переходит в подчинение от вершины dк вершине x и становится ее правым сыном. Отметим, что упорядоченность вершин сохраняется: a < b < c< d < e. Таким образом, для выполнения преобразования надо лишь заменить фиксированное количество указателей в вершинах x, d, c и, возможно, в родительской для x вершине;
Здесь вершина x поддерева, которая является его корнем, опускается вниз и влево. Бывший правый сын d вершины x становится новым корнем поддерева, а x становится левым сыном d. (Вершиныx и d, начальник и подчиненный, как бы меняются ролями: бывший начальник становится подчиненным.) Поддерево c, которое было левым сыном вершины d, переходит в подчинение от вершины dк вершине x и становится ее правым сыном. Отметим, что упорядоченность вершин сохраняется: a < b < c< d < e. Таким образом, для выполнения преобразования надо лишь заменить фиксированное количество указателей в вершинах x, d, c и, возможно, в родительской для x вершине; Здесь вершина x опускается вниз и вправо, ее бывший левый сын b становится новым корнем поддерева, а x — его правым сыном. Поддерево c переходит в подчинение от b к x.
Здесь вершина x опускается вниз и вправо, ее бывший левый сын b становится новым корнем поддерева, а x — его правым сыном. Поддерево c переходит в подчинение от b к x. В случае AVL-деревьев операции вращения повторяются в цикле при восстановлении баланса после добавления или удаления элемента, число вращений не превышает С x h, где h — высота дерева, C — константа. Таким образом, как поиск элемента, так и его добавление или удаление выполняется за логарифмическое время: t <= C x log2n.
В случае AVL-деревьев операции вращения повторяются в цикле при восстановлении баланса после добавления или удаления элемента, число вращений не превышает С x h, где h — высота дерева, C — константа. Таким образом, как поиск элемента, так и его добавление или удаление выполняется за логарифмическое время: t <= C x log2n. -Последний пункт определения означает сбалансированность дерева по черным вершинам.
-Последний пункт определения означает сбалансированность дерева по черным вершинам.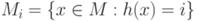

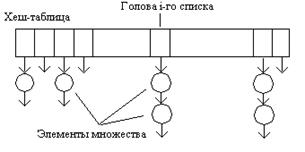 списка. Голова содержит ссылку на первый элемент списка, первый элемент — на второй и так далее. Последний элемент в цепочке содержит нулевую ссылку, т.е. ссылку в никуда. Если список пустой, то элемент хеш-таблицы с индексом i содержит нулевую ссылку.
списка. Голова содержит ссылку на первый элемент списка, первый элемент — на второй и так далее. Последний элемент в цепочке содержит нулевую ссылку, т.е. ссылку в никуда. Если список пустой, то элемент хеш-таблицы с индексом i содержит нулевую ссылку.



