Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Етапи аналізу даних. Класифікація типів змінних. Кількісні, ординальні та номінальні дані та робота з ними.Содержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте
Методи візуалізації даних. Графічні методи експрес-аналізу даних. Якісна візуалізація даних є важливою частиною будь-якої аналітичної системи. У багатьох випадках експерту досить просто поглянути на дані, щоб зробити необхідні висновки. Але одні й ті ж дані можна відображати безліччю способів, і який з них буде найбільш прийнятний, залежить від розв'язуваної задачі. Тому користувачеві Deductor Studio пропонується багато механізмів візуалізації, з яких він може вибрати найбільш оптимальні. Візуалізувати дані в Deductor Studio можна на будь-якому етапі обробки. Система самостійно визначає, яким способом вона може це зробити, наприклад, якщо буде навчена нейронна мережа, то крім таблиць і діаграм можна переглянути граф нейромережі. Користувачеві необхідно вибрати потрібний варіант зі списку і налаштувати декілька параметрів. Можливі способи візуалізації даних:
Експрес-аналіз - це швидка, оперативна перевірка, швидке надання послуг та інформації. Терміни проведення експрес-аналізу від 1 до 3 робочих днів (залежно від обсягу інформації). Головна мета експрес-аналізу - швидка діагностика стану справ на підприємстві з наданням детального звіту. У процесі перевірки аудиторами проводиться оцінка стану податкового та фінансового обліку як в цілому так і по окремих ділянках.
Правило розбиття Для побудови дерева на кожному внутрішньому вузлі необхідно знайти таку умову (перевірку), яка б розбивала множину, асоційовану з цим вузлом на підмножини. В якості такої перевірки повинен бути вибраний один з атрибутів. Загальне правило для вибору атрибута: обраний атрибут повинен розбити множину так, щоб одержані в результаті підмножини складалися з об'єктів, які належать до одного класу, або були максимально наближені до цього, тобто кількість об'єктів з інших класів ("домішків") в кожній з цих множин було якомога менше. Зупинка навчання
Подальша побудова дерева зупиняється, якщо глибина дерева перевищує задане значення. Для оцінки доцільності подальшого розбиття можна використати "ранню зупинку". Вона приваблива в плані економії часу навчання, але цей підхід надає менш точні класифікаційні моделі і тому є небажаним. Правило відсікання Під точністю (розпізнавання) дерева рішень розуміють відношення правильно класифікованих об'єктів при навчанні до загальної кількості об'єктів з навчальної множини, а під похибкою - кількість неправильно класифікованих. Припустимо, що нам відомо спосіб оцінки похибки дерева, гілок і листя. Тоді, можна використати просте правило: · Побудувати дерево. · Відсікти або замінити піддеревом ті гілки, які призводять до зростання помилки. На відміну від процесу побудови, відсікання гілок відбувається знизу вгору, рухаючись з листя дерева, відзначаючи вузли як листя, або замінюючи їх на піддерева. В більшості практичних завдань відсікання надає добрі результати. Метод опорних векторів - це набір схожих алгоритмів виду «навчання із вчителем». Ці алгоритми зазвичай використовуються для задач класифікації та регресійного аналізу. Метод належить до розряду лінійних класифікаторів. Також може розглядатись як особливий випадок регуляризації за А. Н. Тихоновим. Особливою властивістю методу опорних векторів є безперервне зменшення емпіричної помилки класифікації та збільшення проміжку. Тому цей метод також відомий як метод класифікатора з максимальним проміжком. Основна ідея методу опорних векторів – перевід вихідних векторів у простір більш високої розмірності та пошук роздільної гіперплощини з максимальним проміжком у цьому просторі. Дві паралельні гіперплощини будуються по обидва боки гіперплощини, що розділяє наші класи. Роздільною гіперплощиною буде та, що максимізує відстань до двох паралельних гіперплощин. Алгоритм працює у припущенні, що чим більша різниця або відстань між цими паралельними гіперплощинами, тим меншою буде середня помилка класифікатора. Часто в алгоритмах машинного навчання виникає необхідність класифікувати дані. Кожен об'єкт даних представлений як вектор (точка) у р -вимірному просторі (послідовність р чисел) Кожна з цих точок належить тільки одному з двох класів. Нас цікавить, чи можемо ми розділити точки гіперплощиною розмірністю (р -1). Це типовий випадок лінійної роздільності. Таких гіперплощин може бути багато. Тому цілком природно вважати, що максимізація зазору між класами сприяє більш впевненій класифікації. Тобто чи можемо ми знайти таку гіперплощину, щоб відстань від неї до найближчої точки було максимальною. Це б означало, що відстань між двома найближчими точками, що лежать по різні сторони гіперплощини, максимальна. Якщо така гіперплощина існує, то вона нас буде цікавити найбільше; вона називається оптимальною розділяючою гіперплощиною, а відповідний їй лінійний класифікатор називається оптимально поділяючим класифікатором. Алгоритм найближчого сусіда — один з перших і найбільш простих евристичних методів розв'язування задачі комівояжера. Відноситься до категорії жадібних алгоритмів. За кожен крок його виконання до знайденої частини маршруту додається нове ребро. Алгоритм припиняє роботу, коли розв’язок знайдено і не намагається його покращити. Формулюється таким чином:
Алгоритм найближчого сусіда починається в довільній точці та поступово відвідує кожну найближчу точку, яка ще не була відвідана. Пункти обходу плану послідовно включаються до маршруту, причому, кожен черговий пункт, що включається до маршруту, повинен бути найближчим до останнього вибраного пункту серед усіх інших, ще не включених до складу маршруту. Алгоритм завершується, коли відвідано всі точки. Остання точка з’єднується з першою. Вхідні дані: множина точок V розмірністю N Вихідні дані: маршрут Т, що складається з послідовності відвідування точок множини V. Кроки алгоритму (варіант 1): 1. Вибрати довільну точку V1 2. Т1 = V1 3. Для і=2 до і=N виконати: 4. Вибрати точку Vi, найближчу до точки Ті-1 5. Ti = Vi 6. Т N +1 = V1 7. Кінець алгоритму Кроки алгоритму (варіант 2): 1. Довільно обрати поточну точку 2. Знайти найкоротше ребро, що сполучає поточну точку з досі ще не відвіданою точкою V 3. Зробити точку V поточною 4. Позначити точку V, як відвідану 5. Коли всі точки розмірності N відвідані, припинити пошук маршруту 6. Перейти до другого кроку Алгоритм простий у реалізації, швидко виконується, але, як і інші «жадібні» алгоритми, може видавати неоптимальні рішення. Обчислювальна складність алгоритму – O(n2). Результатом виконання алгоритму найближчого сусіда є маршрут, приблизно на 25% довший від оптимального. Одним з евристичних критеріїв оцінки рішення є правило: якщо шлях, пройдений на останніх кроках алгоритму, зіставний зі шляхом, пройденим на початкових кроках, то можна умовно вважати знайдений маршрут прийнятним, інакше, імовірно, існують кращі рішення. Інший варіант оцінки рішення полягає у використанні алгоритму нижньої граничної оцінки. Другий критерій оцінки рішення полягає в застосуванні алгоритму нижньої граничної оцінки. Для будь-якої кількості міст більшій за три в задачі комівояжера можна підібрати таке розташування міст (значення відстаней між вершинами графа і вказівка початкової вершини), що алгоритм найближчого сусіда буде видавати найгірше рішення. Метод Байєса - це простий класифікатор, заснований на імовірнісній моделі, що має сильне припущення незалежності компонент вектора ознак. Метод Байєса - це простий класифікатор, заснований на імовірнісній моделі, що має сильне припущення незалежності компонент вектора ознак. Розуміється, метод Байєса має недоліки: великий обсяг попередньою інформацією, «пригнічення» рідко зустрічаються діагнозів та ін. Однак у випадках, коли обсяг статистичних даних дозволяє застосувати метод Байєса, його доцільно використовувати як один з найбільш надійних і ефективних методів. Метод заснований на простій формулі Байєса. Якщо є стан (діагноз) Di і проста ознака kj, що зустрічається при цьому діагнозі, то ймовірність спільного появи подій (наявність у об'єкта стану Di і ознаки kj) P(Dikj) = P(Di)P(kj/Di) = P(kj)P(Di/kj). З цієї рівності випливає формула Байєса P(Di/kj) = P(Di)P(ki/Di)/P (kj). Дуже важливо визначити точний зміст всіх вхідних в цю формулу величин. P(Di) - ймовірність діагнозу Di, обумовлена за статистичними даними (апріорна ймовірність діагнозу). Так, якщо попередньо обстежено N об'єктів і у Ni об'єктів малося стан Di, то P(Di) = Ni/N. P(kj/Di) - ймовірність появи ознаки kj у об'єктів зі станом Di. Якщо серед Ni об'єктів, що мають діагноз Di, у Nij проявився ознака kj, то P(kj/Di) = Nij/Ni. P(kj) - ймовірність появи ознаки kj у всіх об'єктах незалежно від стану (діагнозу) об'єкта. Нехай із загального числа N об'єктів ознака kj був виявлений у Nj об'єктів, тоді P(kj) = Nj/N. Для встановлення діагнозу спеціальне обчислення P(kj) не потрібно. Як буде ясно з подальшого, значення P(Di) і P(kj/Di), відомі для всіх можливих станів, визначають величину P(kj).
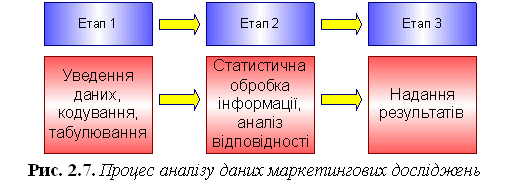
Етапи аналізу даних. Класифікація типів змінних. Кількісні, ординальні та номінальні дані та робота з ними. Аналіз даних — це процес виконання послідовних логічних дій з інтерпретації відповіді респондентів та їх перетворення у статистичні форми, необхідні для ухвалення маркетингових та управлінських рішень. Зазвичай цей процес складається з трьох послідовних етапів
На першому етапі дані, зібрані у процесі опитування, вводять у комп'ютер як матриці (відбувається табуляція даних). Уведення даних і їх табуляція може здійснюватися за допомогою спеціальних комп'ютерних програм, наприклад, Vortex, SPSS, Statistica, або в середовищі MS Excel чи Access. І в першому, і в другому випадку уможливлюється сортування, форматування, відбір та інші операції оброблення даних. На другому етапі проводять статистичний аналіз даних, пошук взаємозв'язків і відмінностей у масивах. Крім того, статистична обробка передбачає розробку висновків та гіпотез (концептуалізацію даних), одночасно проводять перевірку репрезентативності результатів, їх здатності до перенесення на всю генеральну сукупність. Статистичний аналіз може проводитися по-різному. Третій етап передбачає подання викладеного зрозуміло для замовника або керівника заключного звіту, що дасть змогу досягти остаточної мети дослідження — ухвалити стратегічне рішення. Звіт про результати дослідження можна поділити на три частини: вступну, основну та заключну. У вступній частині міститься титульний аркуш, договір на проведення дослідження, меморандум, зміст, перелік ілюстрацій та анотація. Основна мета меморандуму полягає в зорієнтуванні читача на проблему, яку вивчають, та у створенні позитивного іміджу самого звіту. Меморандум має персональний і дещо неформальний стиль. У ньому стисло викладено відомості про характер дослідження та про його виконавців, прокоментовано одержані результати, висунуто пропозиції щодо проведення подальших досліджень. Обсяг меморандуму — один аркуш. Анотація адресована, передусім, керівникам, яких не цікавлять детальні результати проведеного дослідження. Крім того, анотація повинна налаштувати читача на сприйняття основного змісту звіту. В ній повинні бути охарактеризовані: предмет дослідження, коло розглянутих питань, методологія дослідження, основні висновки та рекомендації. Обсяг анотації — не більше одного аркуша. Основна частина звіту складається зі вступу, характеристики методології дослідження, обговорення отриманих результатів, констатації обмежень, а також висновків і рекомендацій. Вступ орієнтує читача на ознайомлення з результатами звіту. Він містить загальну мету звіту та цілі дослідження, актуальність його проведення. У методологічному розділі з належним рівнем деталізації описують: хто або що є об'єктом дослідження та використовувані методи. Додаткову інформацію подають у додатку. Наводяться посилання на авторів і джерела використаних методів. Читач повинен зрозуміти, у який спосіб були зібрані й опрацьовані дані, чому був використаний вибраний метод, а не інші. Головним розділом звіту є розділ, у якому подано отримані результати. Рекомендується формувати його зміст відповідно до мети дослідження. Часто логіка викладу даного розділу визначається структурою анкети, оскільки запитання в ній подано в певній логічній послідовності. Оскільки не слід приховувати проблем, що виникли під час проведення дослідження, то в заключний звіт звичайно вміщують розділ «Обмеження дослідження». У цьому розділі визначають ступінь впливу обмежень (обмеженість часу, грошових і технічних засобів, недостатня кваліфікація персоналу тощо) на отримані результати. Наприклад, ці обмеження могли вплинути на формування вибірки тільки для незначної за розміром кількості регіонів. Отже, переносити отримані результати на всю країну слід обережно або взагалі не робити цього. Висновки та рекомендації можуть бути подані як в одному, так і в окремих розділах. Висновки ґрунтуються на результатах проведеного дослідження. Рекомендації є припущенням щодо того, як потрібно діяти, відповідно до отриманих висновків. Надання рекомендацій може передбачити використання знань, що виходять за рамки отриманих результатів. У заключній частині подають додатки, у яких міститься додаткова інформація, необхідна для більш глибокого осмислення отриманих результатів. Крім написання звіту для клієнтів, дослідники можуть використати усну презентацію методів дослідження та результатів. У цьому разі з'являється можливість відповісти на запитання та обговорити отримані дані. Змінна в імперативному програмуванні - пойменована, або адресована іншим способом область пам'яті, адреса якої можна використовувати для здійснення доступу до даними. Дані, що знаходяться в змінної (тобто за даною адресою пам'яті), називаються значенням цієї змінної. В інших парадигмах програмування, наприклад, в функціональній та логічній, поняття змінної виявляється дещо іншим. У таких мовах змінна визначається як ім'я, з яким може бути пов'язано значення, або навіть як місце (location) для зберігання значення. Область видимості і / або час існування змінної в деяких мовах задається класом пам'яті. Адреса пойменованої комірки пам'яті також може визначатися як на етапі компіляції, так і під час виконання програми. За часом створення змінні бувають статичними і динамічними. Перші створюються в момент запуску програми або підпрограми, а другі створюються в процесі виконання програми. Динамічна адресація потрібна тільки тоді, коли кількість вступників на зберігання даних заздалегідь точно не відомо. Такі дані розміщують у спеціальних динамічних структурах, тип якої вибирається у відповідності зі специфікою задачі і з можливостями обраної системи програмування. Це може бути стек, купа, черга і т. п. Навіть файл, в тому сенсі, який заклав Н.Вірт в Паскаль, є динамічною структурою. За зоною видимості розрізняють локальні та глобальні змінні. Перші доступні тільки конкретної підпрограми, другі - всій програмі. З поширенням модульного та об'єктного програмування, з'явилися ще й загальні змінні (доступні для певних рівнів ієрархії підпрограм). Область видимості іноді задається класом пам'яті. Обмеження видимості може проводитися шляхом введення просторів імен. Обмеження зони видимості придумали як для можливості використовувати однакові імена змінних (що розумно, коли в різних підпрограмах змінні виконують схожу функцію), так і для захисту від помилок, пов'язаних з неправомірним використанням змінних (правда, для цього програміст повинен володіти і користуватися відповідною логікою при структуризації даних). По наявності внутрішньої структури, змінні можуть бути простими або складними (складовими). Прості змінні не мають внутрішньої структури, доступною для адресації. Остання застереження важлива тому, що для компілятора або процесора змінна може бути як завгодно складною, але конкретна система (мова) програмування приховує від програміста її внутрішню структуру, дозволяючи адресуватися тільки "в цілому". Складні змінні програміст створює для зберігання даних, що мають внутрішню структуру. Відповідно, є можливість звернутися безпосередньо до будь-якого елементу. Найхарактернішими прикладами складних типів є масив (всі елементи однотипні) і запис (елементи можуть мати різний тип). Слід підкреслити відносність такого поділу: для різних програм одна і та ж змінна може мати різну структуру. Наприклад, компілятор розрізняє в змінної речовинного типу 4 поля: знаки мантиси і порядку, плюс їх значення, але для програміста, компілюються свою програму, речова змінна - єдина комірка пам'яті, що зберігає дійсне число. Дані – це подання фактів і ідей у формалізованому вигляді, придатному для передачі та обробки в деякому інформаційному процесі. Кількісні дані - це інформація, яка представлена в термінах вимірюваних величин, наприклад у вигляді значень: 100 ° C, 50 ° C, 0 ° С, 1500 ° С, 30 ° С, -273 ° С; 1000 м, 2 мм. Інформація, представлена в кількісній формі, має перевагу в тому, що вона меншою мірою залежить від суб'єктивних схильностей спостерігача. Наприклад, одна людина може сказати, що в кімнаті жарко, в той час як інший скаже, що в ній тепло. Це може призвести до неоднозначності якісної інформації. Показання шкали термометра, що знаходиться в тій же кімнаті, рівне 30 ° С, могло б представляти собою об'єктивно виміряну інформацію. Тим не менш, кількісні дані не завжди можуть містити багато інформації. Що б ви хотіли: щоб вам сказали, що колір має довжину хвилі 5890 ангстрем або ж, що це жовтий колір? Незважаючи на те, що основа кількісних даних - об'єктивні факти, самі числа фактами не є. Фактом в даному випадку може бути число + пояснення. Пояснення повинно містити в собі визначення виміряних або порахованих одиниць і алгоритм маніпуляцій з результатами вимірювань (якщо такі маніпуляції були проведені). Ординальні дані потрібні для вирішення задач прогнозування, коли необхідно визначити, яким чином поведеться той або інший процес в майбутньому, на основі наявних історичних даних. Частіше всього в якості одного з фактів виступає дата або час, хоча це і не обов'язково, може йтися і про деякі відліки, наприклад, дані з певною періодичністю збирані з датчиків. Якщо для процесу характерна сезонність/циклічність, необхідно мати дані хоча б за один повний сезон/цикл з можливістю варіювання інтервалів (потижневе, щомісячне). Так як циклічність може бути складною, наприклад, усередині річного циклу квартальні, а усередині кварталів тижневі, то необхідно мати повні дані як мінімум за один найтриваліший цикл. Максимальний горизонт прогнозування залежить від об'єму даних: - дані на 1,5 роки – прогноз максимум на 1 місяць; - дані за 2-3 роки – прогноз максимум на 2 місяці; Використання дуже великого об'єму даних для аналізу недоцільно, оскільки в цьому випадку модель буде будуватися по старій історії, і, отже, будуть враховуватися чинники, які вже, можливо, втратили свою значність. Номінальні дані (іноді їх також називають номінативними) - вид якісних даних, які відображають умовні коди невимірюваних категорій (наприклад, коди діагнозу).
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-06-29; просмотров: 653; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.137.199.190 (0.017 с.) |