Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Организация внешней памяти в базах данных System RСодержание книги
Поиск на нашем сайте
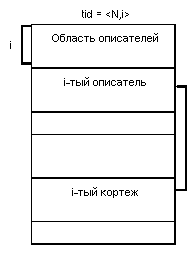
Как мы отмечали, база данных System R располагается в одном или нескольких сегментах внешней памяти. Каждый сегмент состоит из страниц данных и страниц индексной информации. Размер страницы данных в сегменте может быть выбран равным либо 4, либо 32 килобайтам; размер страницы индексной информации равен 512 байтам. Кроме того, при работе RSS поддерживается дополнительный набор данных для ведения журнала. Для повышения надежности журнала (а это наиболее критичная информация; при ее потере восстановление базы данных после сбоев невозможно) этот набор данных дублируется на двух внешних носителях. В каждой странице данных хранятся кортежи одного или нескольких отношений. Фундаментальным понятием RSS является идентификатор кортежа (tuple identifier - tid). Гарантируется неизменяемость tid'а во все время существования кортежа в базе данных независимо от перемещений кортежа внутри страницы и даже при перемещении кортежа в другую страницу. Реально tid представляет собой пару <номер страницы, индекс описателя кортежа в странице>. При этом кортеж может реально располагаться в данной странице:
или в другой странице:
Во втором случае описатель кортежа содержит не координаты кортежа в данной странице, а tid, указывающий на реальное положение кортежа в другой странице. Легко видеть, что применение такого подхода позволяет ограничиться максимум одним уровнем косвенности. Поскольку допускается нахождение в одной странице данных кортежей разных отношений, каждый кортеж должен, кроме содержательной части, включать служебную информацию, идентифицирующую отношение, которому принадлежит данный кортеж. Кроме того, в System R (точнее, в языке SQL) допускается динамическое добавление полей к существующим отношениям. При этом реально происходит лишь модификация описателя отношения в отношении-каталоге отношений. В существующем кортеже отношения новое поле возникает только при модификации этого кортежа, затрагивающей новое поле. Это позволяет избежать массовой перестройки хранимого отношения при добавлении к нему новых полей, но, естественно, требует хранения при кортеже дополнительной служебной информации, определяющей реальное число полей в данном кортеже. (Заметим, что удалять существующие поля существующего отношения в SQL System R не разрешается).
На основе наличия неизменяемых во время существования кортежей tid'ов в System R поддерживаются дополнительные управляющие структуры - индексы. Каждый индекс определен на одном или нескольких полях отношения, значения которых составляют его ключ, и позволяет производить прямой поиск по ключу кортежей (их tid'ов) и последовательное сканирование отношения по индексу, начиная с указанного ключа, в порядке возрастания или убывания значений ключа. Некоторые индексы при их создании могут обладать атрибутом уникальности. В таком индексе не допускаются дубликаты ключа. Это единственное средство SQL указания системе первичного ключа отношения (фактически, набора первичного и всех альтернативных ключей отношения). Для организации индексов в System R применяется техника B-деревьев. Каждый индекс занимает отдельный набор страниц, номер корневой страницы запоминается в описателе индекса. Использование B-деревьев позволяет достичь эффективности при прямом поиске, поскольку они в силу своей сильной ветвистости обладают небольшой глубиной. Кроме того, B-деревья сохраняют порядок ключей в листовых блоках иерархии, что позволяет производить последовательное сканирование отношения в порядке возрастания или убывания значений полей, на которых определен индекс. Фундаментальное свойство B-деревьев - автоматическая балансировка дерева - допускает произведение лишь локальных модификаций индекса при переполнениях и опустошениях страниц индекса. (Мы достаточно вольно используем здесь термин B-дерево. На самом деле в System R используется модифицированный по сравнению с исходным вариант B-деревьев, который называют B*-, а иногда B+-деревьями). В самих B-деревьях System R ничего особенного нет; более подробно мы на этом останавливаться не будем. Отметим только, что System R, насколько нам известно, была первой системой, в которой для организации индексов использовались B-деревья. Эту традицию соблюдает большинство реляционных систем, возникших после System R. Видимо, наиболее важной особенностью физической организации баз данных в System R является возможность обеспечения кластеризации связанных кортежей одного или нескольких отношений. Под кластеризацией кортежей понимается физически близкое расположение (в пределах одной страницы данных) логически связанных кортежей. Обеспечение соответствующей кластеризации позволяет добиться высокой эффективности системы при выполнении выделенного класса запросов. В силу большой важности понятия кластеризации в System R и ее развитиях рассмотрим историю вопроса более подробно.
В окончательном варианте System R существует только одно средство определения условий кластеризации отношения - объявить до заполнения отношения один (и только один) индекс, определенный на полях этого отношения, кластеризованным. Тогда, если заполнение отношения кортежами производится в порядке возрастания или убывания значений полей кластеризации (в зависимости от атрибутики индекса), система физически располагает кортежи в страницах данных в том же порядке. Кроме того, в каждой странице данных кластеризованного отношения оставляется некоторое резервное свободное пространство. При последующих вставках кортежей в такое отношение система стремится поместить каждый кортеж в одну из страниц данных, в которых уже находятся кортежи этого отношения с такими же (или близкими) значениями полей кластеризации. Естественно, что поддерживать идеальную кластеризацию отношения можно только до определенного предела, пока не исчерпается резервная память в страницах. Далее этого предела степень кластеризации отношения начинает уменьшаться, и для восстановления идеальной кластеризации отношения требуется физическая реорганизация отношения (ее можно произвести средствами SQL). Очевидным преимуществом кластеризации отношения является то, что при последовательном сканировании кластеризованного отношения с использованием кластеризованного индекса потребуется ровно столько чтений страниц данных с внешней памяти, сколько страниц занимают кортежи этого отношения. Следовательно, при правильно выбранных критериях кластеризации запросы, связанные с заданием условий на полях кластеризации можно выполнить почти оптимально. В ранних версиях System R существовал еще один способ физического доступа к кортежам отношения и, соответственно, еще один способ указания условия кластеризации с использованием так называемых связей (links). На уровне физического представления связь - это физическая ссылка (tid) из одного кортежа на другой (не обязательно одного отношения). В языке SEQUEL (до того момента, когда его стали называть SQL) существовали средства определения связей в иерархической манере: можно было объявить некоторое отношение родительским по отношению к тому же или другому отношению-потомку. При этом указывались поля родительского отношения и отношения-потомка, в соответствии со значениями которых образовывалась иерархия. Правила построения были очень простыми - проводились связи между кортежем родительского отношения ко всем кортежам отношения-потомка с теми же значениями полей связывания. На самом деле, все кортежи отношения-потомка с общим значением полей связывания образовывали кольцевой список, на который проводилась одна связь из соответствующего кортежа родительского отношения. Естественно, от отношения-родителя требовалась уникальность по отношению к значениям полей связывания. Следует заметить, что мы описали способ использования механизма связей, который поддерживался в ранних версиях SEQUEL. В интерфейсе RSS System R этого периода допускалась возможность произвольного проведения связей без учета совпадения значений полей связывания. Тем самым, в системе в целом не использовались все возможности RSS, которые с избытком превосходили потребности организации иерархических бинарных связей по совпадению полей связывания.
Для одного отношения допускалось создание многих связей: кортеж отношения мог быть родителем нескольких иерархий и входить в несколько других иерархий в качестве потомка. При этом одна связь могла быть объявлена кластеризованной. Тогда система стремилась поместить в одну страницу данных все кортежи одной иерархии. При этом, естественно, использовалась возможность размещения в одной странице данных кортежей нескольких отношений. Основной смысл такой кластеризации заключался в возможности оптимизации выполнения некоторых запросов, включающих (экви)соединение двух связанных отношений в соответствии со значениями полей связывания. В более поздних публикациях по System R упоминания о механизме связей исчезли, из чего можно заключить, что разработчики отказались от его использования. Думается, что основными причинами отказа от использования связей были следующие. Во-первых, средства построения связей, обеспечиваемые RSS, были очень низкого уровня, гораздо более низкого, чем средства поддержания индексов. Если при занесении кортежа RSS обеспечивала автоматическую коррекцию всех индексов, то для коррекции связей требовалось выполнить ряд дополнительных обращений к RSS, из-за чего время выполнения операции занесения кортежа, конечно, увеличивалось (то же касается операций удаления и модификации кортежа). Во-вторых, при реализации этого механизма, возникают дополнительные синхронизационные проблемы нижнего уровня (уровня совместного доступа к страницам данных). В частности, наличие прямых ссылок между страницами данных увеличивает вероятность возникновения синхронизационных тупиков. Наконец, в-третьих, все эти дополнительные накладные расходы не окупались предоставляемыми механизмом связей преимуществами. Действительно, максимального эффекта от использования связей можно достичь только при выполнении операции соединения двух кластеризованных по этой связи отношений, если поле соединения совпадает с полем связывания, и условия, накладываемые на родительское отношение, выделяют в нем ровно один кортеж. Очевидно, что такие запросы на практике редки. (Отметим, что приведенные соображения принадлежат автору и не излагались в публикациях по System R, так что на самом деле причины могли быть и другими.)
Кроме отношений и индексов при работе System R на внешней памяти могут располагаться еще и временные объекты - списки (lists). Список - это мгновенный снимок некоторой выборки с проекцией кортежей одного отношения, возможно, упорядоченный в соответствии со значениями некоторых полей. Средства работы со списками имеются в интерфейсе RSS, но их, естественно, нет в SQL. Соответственно, эти средства используются только внутри системы при выполнении запросов (в частности, один из наиболее эффективных алгоритмов выполнения соединений основан на использовании отсортированных списков кортежей). Публикации по System R не дают точного представления о структурах данных, используемых при организации списков, но исходя из здравого смысла можно предположить, что они устроены не так, как отношения (например, для кортежа, входящего в список, не требуется адресация через tid), и что располагаются они во временных файлах (в случае сбоя системы все временные объекты пропадают). Интерфейс RSS Мы опишем свое представление об интерфейсе RSS, которое не соответствует в точности ни одной из публикаций из приведенного списка литературы, а является скорее некоторой компиляцией, согласующейся с завершающими публикациями. Как мы уже отмечали, на уровне RSS отсутствует именование объектов базы данных, употребляемое на уровне SQL. Вместо имен объектов используются их уникальные идентификаторы, являющиеся прямыми или косвенными адресами внутренних описателей объектов на внешней памяти для постоянных объектов или в оперативной памяти для временных объектов. Можно выделить следующие группы операций:
Операции группы сканирования позволяют последовательно в порядке, определяемом типом сканирования, прочитать кортежи отношения или списка, удовлетворяющие требуемым условиям. Группа включает операции OPEN, NEXT и CLOSE, означающие, соответственно, начало сканирования, требование следующего кортежа, удовлетворяющего условиям, и конец сканирования. Для отношений возможны два режима сканирования: по отношению и по индексу. При сканировании по отношению единственным параметром операции OPEN является идентификатор отношения (включающий, кстати, и идентификатор сегмента, в котором это отношение хранится). По причине того, что в System R допускается размещение в одной странице данных кортежей нескольких отношений, сканирование по отношению предполагает последовательный просмотр всех страниц сегмента с выделением в них кортежей, входящих в данное отношение; это очень дорогой способ сканирования отношения. При этом порядок выборки кортежей определяется их физическим размещением в страницах сегмента, т.е. предопределен системой.
При открытии сканирования отношения по одному из его индексов в число параметров операции OPEN входит идентификатор индекса, определенного ранее на полях этого отношения. Кроме того, можно указать диапазон сканирования в терминах значений полей, составляющих ключ индекса. При открытии сканирования по индексу производится начальная установка указателя сканирования в позицию листа B-дерева индекса, соответствующую левой границе заданного диапазона. Процесс сканирования состоит в последовательном продвижении по листовым вершинам индекса до достижения правой границы диапазона сканирования с выборкой tid'ов и чтением соответствующих кортежей. Легко видеть, что если сканирование производится не по кластеризованному индексу, то в худшем случае может потребоваться столько чтений страниц данных из внешней памяти, сколько tid'ов было встречено, т.е. эффективность сканирования по индексу определяется "широтой" заданного диапазона сканирования. При этом, конечно, имеется то преимущество, что порядок сканирования соответствует порядку возрастания или убывания значений ключа индекса. Наконец, при сканировании списка, как и при сканировании по отношению, единственным параметром операции OPEN является идентификатор списка, но, в отличии от сканирования по отношению это сканирование максимально эффективно: читаются только страницы, содержащие кортежи из данного списка, и порядок сканирования совпадает с порядком занесения кортежей в список или порядком списка, если он упорядочен. В результате успешного выполнения операции открытия сканирования (если нет ошибок в параметрах) вырабатывается и возвращается идентификатор сканирования, который используется в качестве входного параметра других операций этой группы. Операция NEXT выполняет чтение следующего кортежа указанного сканирования, удовлетворяющего условиям данной операции. Условие представляет собой дизъюнктивную нормальную форму простых условий, относящихся к значениям указанных полей отношения. Простое условие - это условие вида <идентификатор-поля op константа>, где op - операция сравнения <, <=, >, >=, = или!=. Общее условие является параметром операции NEXT. Семантика операции NEXT следующая: начиная с текущей позиции сканирования выбираются кортежи отношения в порядке, определяемом типом сканирования, до тех пор, пока не встретится кортеж, значения полей которого удовлетворяют указанному условию; этот кортеж и является результатом операции; если при выборке следующего кортежа достигается правая граница диапазона сканирования (правая граница значения ключа при сканировании по индексу или последний кортеж отношения или списка при сканировании без индекса), вырабатывается особый признак результата. После этого единственным разумным действием является закрытие сканирования - операция CLOSE. Операция CLOSE может быть выполнена в данной транзакции по отношению к любому ранее открытому сканированию независимо от его состояния (т.е. независимо от того, достигнута ли при сканировании правая граница диапазона сканирования). Параметром операции является идентификатор сканирования, и ее выполнение приводит к тому, что этот идентификатор становится недействительным (и, соответственно, уничтожаются служебные структуры памяти RSS, относящиеся к данному сканированию). Группа операций создания и уничтожения постоянных и временных объектов базы данных включает операции создания таблиц (CREATE TABLE), списков (CREATE LIST), индексов (CREATE IMAGE) и уничтожения любого из подобных объектов (DROP TABLE, DROP LIST и DROP IMAGE). Входным параметром операций создания таблиц и списков является спецификатор структуры объекта, т.е. число полей объекта и спецификаторы их типов. Кроме того, при спецификации полей отношения указывается допущение или недопущение неопределенных значений полей в кортежах этого отношения или списка (неопределенные значения кодируются специальным образом; любая операция сравнения константы данного типа с неопределенным значением по определению вырабатывает значение FALSE, кроме операции сравнения на совпадение со специальной литеральной константой NULL). В результате выполнения этих операций заводится описатель в служебном отношении описателей отношений или оперативной памяти (в зависимости от того, создается ли постоянный объект или временный), и вырабатывается идентификатор объекта, который служит входным параметром других операций, относящихся к соответствующему объекту (в частности, параметром операции OPEN при открытии сканирования объекта). Входными параметрами операции CREATE IMAGE являются идентификатор таблицы, для которой создается индекс, список номеров полей, значения которых составляют ключ индекса, и признаки упорядочения по возрастанию или убыванию для всех составляющих ключ полей. Кроме того, может быть указан признак уникальности индекса, т.е. запрещения наличия в данном индексе ключей-дубликатов. Если операция выполняется по отношению к пустой в этот момент таблице, то выполнение операции такое же простое, как и для операций создания таблиц и списков: создается описатель в служебном отношении описателей индексов и возвращается идентификатор индекса (который, в частности, используется в качестве входного параметра операции открытия сканирования отношения по индексу). Если же к моменту создания индекса соответствующая таблица не пуста (а это допускается), то операция становится существенно более дорогостоящей, поскольку при ее выполнении происходит реальное создание B-дерева индекса, что требует по меньшей мере одного последовательного просмотра отношения. При этом, если создаваемый индекс имеет признак уникальности, то это контролируется при создании B-дерева, и если уникальность нарушается, то операция не выполняется (т.е. индекс не создается). Из этого следует, что хотя создание индексов в динамике не запрещается, более эффективно создавать все индексы на данной таблице до ее заполнения. Заметим, что создание кластеризованного индекса для непустого отношения запрещено, поскольку соответствующую кластеризацию отношения без его реструктуризации получить невозможно. Операции DROP TABLE, DROP LIST и DROP IMAGE могут быть выполнены в любой момент независимо от состояния объектов. Выполнение операции приводит к уничтожению соответствующего объекта и, вследствие этого, недействительности его идентификатора. Следует отметить, что массовые операции над постоянными объектами (CREATE IMAGE, DROP TABLE и DROP IMAGE) требуют дополнительных накладных расходов в связи с необходимостью обеспечения возможности откатов транзакции, в результате чего требуется выполнение массовых обратных действий. Особенно сильно это затрагивает операцию уничтожения непустых таблиц, поскольку требует журнализации всех содержащихся в них к моменту уничтожения кортежей. Поэтому, хотя уничтожение непустых таблиц и не запрещено, нужно иметь в виду, что это очень дорогостоящая операция. Группа операций модификации отношений и списков включает операции вставки кортежа в отношение или список (INSERT), удаления кортежа из отношения (DELETE) и модификации кортежа в отношении (UPDATE). Параметрами операции вставки кортежа являются идентификатор отношения или списка и набор значений полей кортежа. Среди значений полей могут быть литеральные неопределенные значения NULL. Естественно, при выполнении операции контролируется допуcтимость неопределенных значений в соответствующих полях. При занесении кортежа в кластеризованное отношение поиск места в сегменте под кортеж производится с использованием кластеризованного индекса: система пытается вставить кортеж в страницу данных, уже содержащую кортежи с теми же или близкими значениями полей кластеризации. При занесении кортежа в некластеризованное отношение место под кортеж выделяется в первой подходящей странице данных. Наконец, при вставке кортежа в список он помещается в конец списка. При занесении кортежа в постоянное отношение производится коррекция всех индексов, определенных на этом отношении. Реально это выражается во вставке новой записи во все B-деревья индексов. При этом могут произойти переполнения одной или нескольких страниц индекса, что вызовет переливание части записей в соседние страницы или расщепление страниц. Если индекс определен с атрибутом уникальности, то проверяется соблюдение этого условия, и если оно нарушено, операция вставки считается невыполненной. Из этого видно, что операция вставки кортежа тем более накладна, чем больше индексов определено для данной таблицы (это относится и к операциям удаления и модификации кортежей). В результате успешного выполнения операции вставки кортежа в отношение вырабатывается tid нового кортежа, который сообщается в качестве ответного параметра и может быть в дальнейшем использован как прямой параметр операций удаления и модификации кортежей отношения. При занесении кортежа в список значение tid'а не вырабатывается (списки допускают только последовательное сканирование и добавление новых кортежей в конец, над ними нельзя определить индексов, поэтому косвенная адресация кортежей списков через tid'ы не требуется). Операции удаления и модификации кортежей допускаются только для кортежей постоянных таблиц. Естественно, что для выполнения этих операций необходимо идентифицировать соответствующий кортеж. Интерфейс RSS допускает два способа такой идентификации: с помощью tid'а кортежа (явная адресация) и с использованием идентификатора открытого к этому времени сканирования. Первый вариант возможен, поскольку tid кортежа сообщается как ответный параметр операции занесения кортежа в постоянную таблицу. При идентификации кортежа с помощью идентификатора сканирования имеется в виду кортеж, прочитанный с помощью последней операции NEXT. Если при такой идентификации выполнена операция DELETE или UPDATE, задевающая порядок сканирования (т.е. сканирование ведется по индексу и операция модификации меняет поле кортежа, входящее в состав ключа этого индекса), то текущий кортеж скана теряется, и его идентификатор нельзя использовать для идентификации кортежа до выполнения следующей операции NEXT. Единственным параметром операции DELETE является идентификатор кортежа (tid или идентификатор сканирования). Параметры операции UPDATE включают, кроме этого идентификатора, спецификацию изменяемых полей кортежа (список номеров полей и их новых значений). Среди значений могут находиться литеральные изображения неопределенных значений, если соответствующие поля отношения допускают хранение неопределенных значений. При выполнении операции DELETE производится коррекция всех индексов, определенных на данном отношении. Операция UPDATE также может повлечь коррекцию индексов, если затрагивает поля, входящие в состав их ключей. Кроме описанных "атомарных" операций сканирования и модификации таблиц и списков, интерфейс RSS включает одну "макрооперацию", позволяющую за одно обращение к RSS построить отсортированный по значением заданных полей список. Эта операция - BUILDLIST - включает сканирование заданного отношения или списка, создание нового списка, в который включаются указанные поля выбираемых кортежей, и сортировку построенного списка в соответствии со значениями указанных полей. Идентификатор заново построенного отсортированного списка является ответным параметром операции. Соответственно, параметрами операции BUILDLIST являются набор параметров для открытия сканирования (допускается любой способ сканирования), список номеров полей, составляющих кортежи нового списка, и список номеров полей, по которым нужно производить сортировку (как и в случае создания нового индекса, можно отдельно для каждого из этих полей указать требование к сортировке по возрастанию или убыванию значений данного поля). Отдельным параметром операции BUILDLIST является признак, в соответствии со значением которого допускаются или не допускаются кортежи-дубликаты в новом списке. Забегая вперед, заметим, что допущение или недопущение дубликатов в отсортированном списке зависит от того, для каких целей он строится. Например, если список строится для выполнения операции соединения, то дубликатов в нем быть не должно. Если же список строится для вычисления агрегатных функций (COUNT, AVG и т.д.), то дубликаты из него убирать нельзя. Более подробно мы рассмотрим этот и близкие вопросы в связи с проблемами оптимизации запросов в System R. Операция RSS добавления поля к существующему отношению позволяет в динамике изменять схему таблицы. Параметрами операции CHANGE являются идентификатор существующей таблицы и спецификация нового поля (его тип). При выполнении операции изменяется только описатель данного отношения в служебном отношении описателей отношений. Как мы уже отмечали в предыдущем подразделе, до выполнения первой операции UPDATE, затрагивающей новое поле таблицы, реально ни в одном кортеже таблицы память под новое поле выделяться не будет. По умолчанию значения нового поля во всех кортежах таблицы, в которые еще не производилось явное занесение значения, считаются неопределенными. Тем самым, ни для одного поля, динамически добавленного к существующей таблице, не может быть запрещено хранение неопределенных значений. Каждая операция RSS выполняется в пределах некоторой транзакции. Интерфейс RSS включает набор операций управления прохождением транзакции: начать транзакцию (BEGIN TRANSACTION), закончить транзакцию (END TRANSACTION), установить точку сохранения (SAVE) и выполнить откат до указанной точки сохранения или до начала транзакции (RESTORE). Мы не отмечали этого раньше, но на самом деле при обращении к любой функции RSS, кроме BEGIN TRANSACTION, должен указываться еще один параметр - идентификатор транзакции. Этот идентификатор и вырабатывается при выполнении операции BEGIN TRANSACTION, которая сама входных параметров не требует. В любой точке транзакции до выполнения операции END TRANSACTION может быть выполнен откат данной транзакции, т.е. обратное выполнение всех изменений, произведенных в данной транзакции, и восстановление состояния сканов. Откат может быть произведен до начала транзакции (в этом случае о восстановлении состояния сканов говорить бессмысленно) или до установленной ранее в транзакции точке сохранения. Точка сохранения устанавливается с помощью операции SAVE. При выполнении этой операции запоминается состояние сканов данной транзакции, открытых к моменту выполнения SAVE, и координаты последней записи об изменениях в базе данных в журнале, произведенной от имени данной транзакции. Ответным параметром операции SAVE (а прямых параметров, кроме идентификатора транзакции, она не требует) является идентификатор точки сохранения. Этот идентификатор в дальнейшем может быть использован как прямой параметр операции RESTORE, при выполнении которой производится восстановление базы данных по журналу, с использованием записей о ее изменениях от данной транзакции до того состояния, в котором находилась база данных к моменту установления указанной точки сохранения. Кроме того, по локальной информации в оперативной памяти, привязанной к транзакции, восстанавливается состояние ее сканов. Откат к началу транзакции инициируется также обращением к операции RESTORE, но с указанием некоторого предопределенного идентификатора точки сохранения. При выполнении своих транзакций пользователи System R изолированы один от другого, т.е. не ощущают того, что система функционирует в многопользовательском режиме. Это достигается за счет наличия в RSS механизма неявной синхронизации (более полно это мы обсудим в следующем подразделе). Пока заметим лишь, что до конца транзакции никакие изменения базы данных, произведенные в пределах этой транзакции, не могут быть использованы в других транзакциях (попытка использования таких данных приводит к временным синхронизационным блокировкам этих транзакций). При выполнении операции END TRANSACTION происходит "фиксация" изменений, произведенных в данной транзакции, т.е. они становятся видимыми в других транзакциях. Реально это означает снятие синхронизационных захватов с объектов базы данных, изменявшихся в транзакции. Из этого следует, что после выполнения END TRANSACTION невозможны индивидуальные откаты данной транзакции. RSS просто делает недействительным идентификатор данной транзакции, и после выполнения операции окончания транзакции отвергает все операции с таким идентификатором. Последняя операция интерфейса RSS - операция явной синхронизации LOCK. Эта операция позволяет установить явный синхронизационный захват на указанное отношение (параметром операции является идентификатор таблицы). Выполнение операции LOCK гарантирует, что никакая другая транзакция до конца данной не сможет изменить данное отношение (вставить в него новый кортеж, удалить или модифицировать существующий), если установлен захват отношения в режиме чтения, или даже прочитать любой кортеж этого отношения, если установлен захват в режиме изменения. Из всего, что говорилось раньше по поводу подхода к синхронизации в System R и соответствующего разбиения системы на уровни, следует нелогичность наличия этой операции в интерфейсе RSS. На самом деле, логически эта операция избыточна, т.е. если бы ее не было, можно вполне реализовать SQL на оставшейся части операций. До изложения материала следующего подраздела об этом трудно говорить, но предварительно заметим, что операция LOCK введена в интерфейс RSS для возможности оптимизации выполнения запросов. Дело в том, что, как видно из описания интерфейса, он покортежный. Следовательно, и информация для синхронизации носит достаточно узкий характер. В то же время на уровне SQL имеется более полная информация. Например, если обрабатывается предложение SQL DELETE FROM EMP, то известно, что будут удалены все кортежи указанной таблицы. Понятно, что как бы не реализовывался механизм синхронизации в RSS, в данном случае выгоднее сообщить сразу, что изменения касаются всего отношения. Но снова забегая вперед, заметим, что ситуации в компиляторе SQL, когда очевидна выгода от использования явной синхронизации, достаточно редки. Пользоваться этим средством можно только очень осмотрительно, потому что неоправданные захваты таких крупных объектов могут резко ограничить степень асинхронности выполнения транзакций. Синхронизация в System R System R с самого начала задумывалась как многопользовательская система, обеспечивающая режим мультидоступа к базам данных. Поэтому вопросам синхронизации доступа всегда уделялось очень большое внимание. Разработчики System R сформулировали и частично решили много проблем синхронизации, соответствующие публикации давно стали классикой, и на них ссылаются практически во всех работах, связанных с синхронизацией в системах управления базами данных. Мы постараемся привести историческую ретроспективу решений в области синхронизации в System R. Предварительно заметим, что вопросы синхронизации находятся в тесной связи с вопросами журнализации изменений и восстановления состояния базы данных. Начнем с рассмотрения целей, которыми руководствовались разработчики System R при выработке своего подхода к синхронизации. Дело в том, что начальной целью синхронизации операций было не обеспечение изолированности пользователей, а поддержка средств обеспечения логической целостности баз данных. Как мы отмечали во введении, логическая целостность баз данных System R поддерживается на основе наличия ранее сформулированных и запомненных в каталогах базы данных ограничений целостности. В конце каждой транзакции или при выполнении явного предложения SQL проверяется ненарушение ограничений целостности изменениями, произведенными в данной транзакции. Если обнаруживается нарушение ограничений целостности, то с помощью операции RSS RESTORE производится откат транзакции, нарушившей ограничения. Для того, чтобы можно было корректно выполнить такой откат, необходимо, чтобы до конца транзакции объекты базы данных, изменявшиеся транзакцией, не могли изменяться другими транзакциями. В противном случае возникает так называемая проблема потерянных изменений. Действительно, пусть транзакция 1 изменяет некоторый объект базы данных A. Затем другая транзакция 2 также изменяет объект A, после чего производится откат транзакции 1 (по причине, например, нарушения ей ограничений целостности). Тогда при следующем чтении объекта A транзакция 2 увидит его состояние, отличное от того, в которое он перешел в результате его изменения транзакцией 2. Исходным постулатом System R было то, что потерянные изменения допускать нельзя, и обеспечение этого являлось минимальным требованием к системе синхронизации. Соответствующий режим выполнения транзакций называется в System R первым уровнем совместимости транзакций. Это наиболее низкий уровень синхронизации, вызывающий минимальные накладные расходы в системе. Технически синхронизация на первом уровне совместимости предполагает долговременные (до конца транзакции) синхронизационные захваты изменяемых объектов базы данных и отсутствие каких-либо захватов для читаемых объектов. С точки зрения обеспечения логической целостности баз данных первый уровень совместимости вполне удовлетворителен, но вызывает некоторые проблемы внутри транзакций. Основная проблема - возможность чтения грязных данных. Действительно, читающая транзакция абсолютно не синхронизуется с изменяющими транзакциями, и поэтому в ней может быть прочитано некоторое промежуточное с логической точки зрения состояние объекта (мы подчеркиваем, что "грязным" объект может быть только на логическом уровне; физическую согласованность в базе данных поддерживает другой, "физический" уровень синхронизации RSS, на котором мы остановимся позже). Следующий, второй уровень совместимости транзакций System R обеспечивает отсутствие грязных данных. Технически синхронизация на втором уровне совместимости предполагает долговременные синхронизационные захваты (до конца транзакции) изменяемых объектов и кратковременные (на время выполнения операции) захваты читаемых объектов. Второй уровень совместимости транзакций System R гарантирует отсутствие грязных данных, но не свободен от еще одной проблемы - неповторяющихся чтений. Если транзакция два раза (подряд или с некоторым временным промежутком) читает один и тот же объект базы данных, то состояние этого объекта может быть разным при разных чтениях, поскольку в промежутке между ними (а он может возникнуть, даже если чтения идут в транзакции подряд) другая транзакция может модифицировать объект. Эту проблему решает третий уро
|
|||||||||
|
|
Последнее изменение этой страницы: 2016-06-06; просмотров: 375; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.118.252.215 (0.011 с.) |