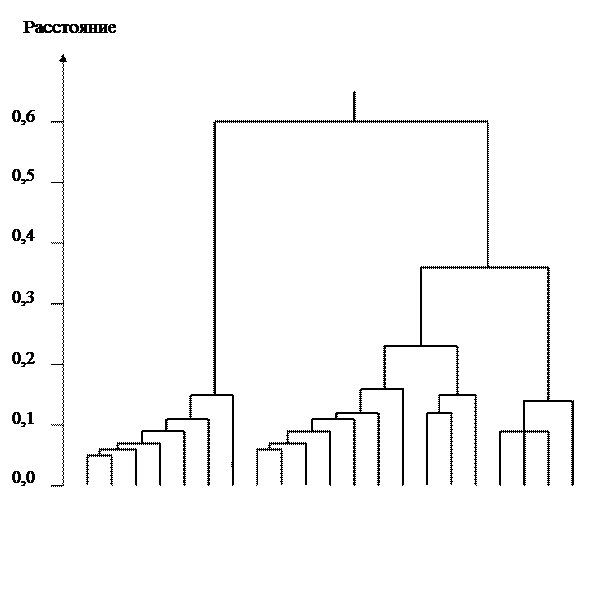Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Теоретическая платформа выполнения работыСодержание книги
Поиск на нашем сайте
Теоретической основой метода выступает представление о каждом конкретном объекте как о некой «точке», помещенной во вполне конкретное место многомерного пространства (поля или, если хотите, информационного поля), каждая координатная ось которого соответствует одному из признаков в системе признаков, используемых для анализа. При этом каждая характеристика объекта (каждое проявление каждого из его признаков) рассматривается как соответствующая количественная величина одного из многочисленных (по количеству мерности многомерного пространства) векторов. Иными словами, местоположение «точки» в многомерном пространстве определяется многочисленными координатами (по количеству мерности многомерного пространства), выраженными в количественном виде. В свою очередь расстояние между объектами в таком многомерном пространстве есть обобщенная разница в их координатах. Для наглядности и детализации представления о таком подходе к организации исследований рассмотрим ряд очевидных (понимаемых однозначно) позиций или примеров. Для ответа на вопрос о степени близости или отдаленности сравниваемых между собой многопараметрических объектов предусматривается решение идентификационных и классификационных задач. Достаточно широко распространенным на современном этапе и наиболее эффективным средством решения подобных задач выступают методы комплексного анализа, в частности факторный и кластерный анализ (Харман, 1972; Окунь, 1974; Лейтас, 1983; Бессчетнова, 2004б, в, г; 2013 в; 2014в; Семихов, 2007б; Maltamo, 2001; Sironen, 2001; Temesgen, 2008; Kesari, 2010; Androsiuk, 2011). Одной из форм реализации такого анализа является определение обобщенного статистического расстояния в многомерном пространстве признаков, в частности евклидова расстояния, линейного расстояния, расстояния Махаланобиса (Никитин, 1978; Песенко, 1982; Лейтас, 1983; Мандель, 1988; Мэйндональд, 1988; Марущак, 1991; Kaushik, 2007). Оно позволяет выявить дивергенцию и генотипические различия объектов по комплексу признаков, исключая изменчивость под воздействием окружающей среды (Кукеков, 1978; Петров, 1984; Tausz, 2001). Сравнив полученные оценки, удается сделать заключение о том, какие из многопараметрических объектов, размещенных в едином многомерном пространстве, наиболее близки между собой, а какие – отдалены друг от друга по всему комплексу анализируемых признаков.
Важной теоретической позицией факторного или кластерного анализа принимается условие о том, что признаков, по которым выполняют эти многомерные анализы, может быть неограниченное количество (на современном этапе развития теоретических положений метода это не определено), но при этом все объекты должны характеризоваться одним и тем же набором параметров (признаков), т.е. должны располагаться в едином многомерном пространстве, каждая точка которого характеризуется (описывается, определяется) одним и тем же набором координат. Значение признака может быть равным «нулю», когда проявление признака отсутствует (количество колючек на единице длины побега у неколючих особей или плотность волосков на единице площади листовой пластинки при отсутствии опушенности и т.п.). В этом случае координата признака (величина или длина соответствующего вектора) равна «нулю», но сам признак не отсутствует в системе отсчета как координатный элемент. Это условие является одним из основных условий проведения такого анализа. В контексте вышесказанного необходимо обеспечить наличие одинакового набора анализируемых признаков у каждого из объектов многомерного комплекса сравнения. Лесоводственнные объекты (насаждения, отдельные плюсовые деревья или их клоны), не имеющие (по той или иной причине), хотя бы одной из характеристик, должны исключаться из схемы опыта (Булыгин, 1978, Никитин, 1978; Лейтас, 1983; Петров, 1984; Марущак, 1991; Насонов, 1996; Бессчетнова, 2006; 2011; 2014; 2015). Организация комплекса должна предусматривать такой подход, при котором каждый многомерный объект описывался однозначными оценками учитываемых параметров, каждая из которых имела отношение только к данному объекту (насаждению, лесничеству, плюсовому дереву и т.д). То есть каждый из объектов в ходе первичного изучения получает некоторый, но одинаковый для всех объектов, набор количественных характеристик, число которых определяет мерность собственно многомерного пространства признаков. Следовательно, принципом формирования числовых массивов должно явиться то, что относительно каждого из признаков существует возможность вычисления оценок корреляции и ковариации со всеми остальными признаками объектов в многомерном комплексе сравнения. Вычисление на этих условиях обобщенных расстояний между объектами в многомерном пространстве признаков позволяет дать для комплекса анализируемых объектов сопоставимые оценки того, насколько близко или отдаленно друг от друга объекты расположены в заданном для анализа многомерном пространстве. При выборе признаков для многомерного анализа следует исходить из того, что объекты, их носители, должны иметь некоторую принципиальную общность и системность характеристик (принадлежность к одному биологическому виду или к одинаковой селекционной категории, размещение на одном лесном участке, одинаковый возраст, одинаковую степень развития учитываемых метамеров и т.п.).
Порядок проведения занятия. 18. Прочитать текст. 19. Скопировать исходный файл (Лист-1) на следующий лист (Лист-2). 20. Вычислить средние значения и величины среднего квадратического отклонения по каждому признаку, используя встроенные функции Excel. 21. Используя полученные величины и матрицу исходных значений признаков, вычислить нормированные значения каждого признака для каждого из объектов и сформировать из них матрицу нормированных значений. 22. Проверить правильность расчетов, вычислив среднее значение нормированных признаков и их общую дисперсию и среднее квадратическое отклонение: среднее значение должно быть равно «0», а СКО – «1». 23. Последовательно рассчитать разности нормированных значений соответствующих признаков двух сравниваемых селекционных объектов (двух плюсовых деревьев). 24. Вычислить квадраты полученных разностей нормированных значений и внести их в соответствующую строку рабочей таблицы Excel. 25. Рассчитать обобщенное статистическое расстояние для данной пары объектов и записать его значение в таблицу на листе 3. Использовать непосредственную запись или копирование с использованием функции «Специальная вставка» - «Вставить значение». Функцию «Вставить связь» в этом алгоритме расчета не использовать! 26. Продолжить вычисления указанных величин для следующей пары сравниваемых многомерных объектов. 27. Используя шаблоны расчетных таблиц (Лист 4), сформировать таблицу исходных данных, содержащую информацию об «эталонном объекте». Эталонный объект представляется как «абстракция идеализации» - абстрактное плюсовое дерево, характеристики которого соответствуют «лучшим» значениям соответствующих признаков в комплексе сравниваемых между собой реальных плюсовых деревьев (любых объектов селекции). 28. Вычислить средние значения и величины среднеквадратического отклонения по каждому признаку, используя встроенные функции Excel, для матрицы исходных значений с учетом наличия в её составе «эталонного объекта». 29. Произвести процедуру нормирования исходных значений и вычислить обобщенное статистическое расстояние каждого из реальных объектов от «эталонного объекта».
Техника применения метода. Матрица средних значений (табл. 1) представлена размерными и безразмерными неравнозначными и разно-размерными величинами, характеризующими объект (популяцию, экотип и т.п.), например: длина или ширина листовой пластинки – в сантиметрах, масса плода (или шишки) – в граммах или миллиграммах, площадь листовой пластинки или площадь поперечного сечения ствола – в сантиметрах квадратных, коэффициент формы плода или листовой пластинки у цветковых растений – в безразмерных величинах, коэффициент формы шишки у хвойных – в безразмерных величинах.
ПРИМЕР. Примером такой матрицы исходных размерных и неоднородных значений может служить таблица средних значений признаков у особей различных популяций облепихи крушиновидной (табл. 1), полученные в ходе селекционной инвентаризации природных популяций этого растения.
Особенностью метода является возможность использования в расчетах статистических комплексов, представленных только однородными величинами, что наиболее удобно представлять в форме безразмерных величин. Для этой цели матрица исходных данных преобразуется в матрицу нормированных значений (табл. 2). При этом все они (нормированные значения) являются безразмерными, их распределение обеспечивает нулевое среднее значение (среднее значение всех нормированных величин в пределах каждого признака в сумме даст «ноль»), а среднеквадратическое отклонение равно единице (учитывается среднеквадратическое отклонение каждого из средних, введенных в комплекс сравнения, от обобщенного среднего).
ПРИМЕР. Примером матрицы нормированных значений может явиться таблица нормированных значений признаков популяций облепихи (табл.2).
Таблица 1. Средние значения признаков популяций облепихи (исходная матрица)
Таблица 2. Нормированные значения признаков популяций облепихи (матрица нормированных значений)
Нормирование производится путем следующего преобразования каждого исходного значения, включенного в исходную матрицу. 1. Разница между каждым исходным значением признака и его обобщенным средним значением делится на обобщенное среднеквадратическое отклонение. Здесь каждое исходное значение признака – это среднее его значение для популяции (или экотипа, или плюсового дерева, представленного клонами и т.п.), полученное в результате статистической обработки исходного фактического материала, полученного на объекте (в популяции, в пределах сорта или экотипа и т.д.) в ходе биометрирования учетных растений, составляющих выборку. Обобщенное среднее значение получается в результате математической обработки всего обобщенного цифрового массива, представляющего совокупность всех частных (в пределах популяции, сорта, экотипа и т.п.) выборок. Обобщенное среднеквадратическое отклонение высчитывается в ходе статистической обработки обобщенной выборки (обобщенного цифрового массива, включающего в себя все частные выборки по популяциям или экотипам). Следовательно, обобщенный статистический анализ дает две статистики (две величины), используемые для нормирования: обобщенное среднее значение по каждому признаку и обобщенное среднеквадратическое отклонение по каждому признаку. 2. Для расчета обобщенного среднего значения каждого признака и обобщенного среднеквадратического отклонения по нему формируется обобщенная выборка – обобщенный цифровой массив из результатов замеров признака на всех учетных растениях (клонах плюсового дерева, учетных площадках и т.п.) во всех популяциях или экотипах (или сортах, формах, плюсовых деревьях и т.п.). Обработка ведется по каждому признаку отдельно.
3. Кроме этого предусматривается статистическая обработка данных в пределах каждой популяции (экотипа, сорта и т.д.) с расчетом популяционных средних (и всех необходимых статистик). Для этого применяются такие же программы статистических расчетов, ориентированные на объем выборки в пределах отдельного объекта в комплексе сравниваемых объектов (популяции, сорта, экотипа и т.п.). 4. Полученные в ходе этих (и на популяционном уровне, и на обобщенном уровне) расчетов данные (популяционные средние, обобщенные средние, обобщенные среднеквадратические отклонения по каждому признаку) используются для получения нормированных безразмерных однородных значений. Для этого применяется формула (1):
- i = 1,… n – индекс значения (порядковый номер) объекта, (популяции, экотипа или т.п.); - j = 1,…k – индекс значения (порядковый номер) анализируемого признака; - bij – элемент матрицы нормированных значений; - aij – элемент матрицы исходных значений; - Aj – обобщенное среднее значение j-го признака; - Sj – обобщенное среднеквадратическое отклонение j-го признака; - n – количество сравниваемых объектов в комплексе сравнения (популяций, экотипов, клоновых групп и т.д.); - k – количество анализируемых признаков, введенных в комплекс сравнения.
Полученная в таком порядке матрица (таблица) преобразованных нормированных значений обладает следующими свойствами: - каждый столбец (соответствует набору значений нормированных показателей какого-либо признака у разных объектов сравниваемого комплекса объектов – популяций, экотипов, сортов, клонов и т.п.) имеет нулевое среднее значение, т.е. сумма всех значений нормированного показателя равна «нулю»; - среднее квадратическое отклонение нормированных значений от их средней величины «0» равно «единице».
Метод предусматривает возможность оценки статистического расстояния в евклидовом пространстве между реальными объектами – реальными популяциями, экотипами, клоновыми группами и т.п. при попарном их сравнении каждого с каждым. В этом случае количество сравнений будет существенно больше, чем при сравнении реальных объектов только с эталонным объектом. Существенно важным моментом в этом случае является возникающая возможность оценки статистической близости или удаленности одного объекта от другого по комплексу (из всех анализируемых) признаков. Тогда возникает и возможность оценки генетической близости сравниваемых объектов (при селекционной оценке): т.е. удается установить, какие из объектов наиболее сходны между собой по всему комплексу признаков, а какие – наиболее удалены друг от друга. Принципиально используется схема сравнения, как и при сравнении с эталонным объектом, только в этом случае каждый раз в качестве объекта сравнения поочередно выступает один из реальных объектов, и с ним сравниваются все остальные объекты. В этом случае расчет обобщенного статистического расстояния между реальными объектами при их попарном сравнении будет иметь вид (2):
- d iy – обобщенное статистическое расстояние между двумя сравниваемыми объектами.; - i = 1, 2, 3,… n – индекс порядкового номера одного из двух сравниваемых объектов; - y = 1, 2, 3,… n – индекс порядкового номера другого из двух сравниваемых объектов; - k – количество анализируемых признаков, введенных в комплекс сравнения.
Получаемые в итоге такого анализа результаты, представляют собой статистическую оценку обобщенного статистического расстояния между каждой из проанализированных пар объектов. Они неодинаковы, что соответствует различной степени статистической удаленности или близости между конкретными объектами, но при этом, и это очень важно, все полученные оценки сравнимы между собой, поскольку получены для единого многомерного статистического пространства, для одной и той же многомерной системы координат. На основании этого представляется возможным дать обобщенную оценку (единую для всех сравниваемых пар объектов) статистической близости или удаленности сравниваемых объектов: представляется возможным оценить какой из объектов наиболее близок к каждому из других или удален от него. Обобщенное статистическое расстояние измеряется единым критерием, единой единицей измерения общей для всех случаев сравнения объектов. Принципиально это соответствует любому измерению вообще, поскольку измерение есть сравнение с эталоном. При использовании многочисленных признаков (целого комплекса различных признаков) для комплексного сравнительного анализа необходимо выдвижение рабочего условия о равной информативной значимости каждого из анализируемых признаков. В противном случае, когда признаки не равнозначны в информативном плане (существуют более значимые и менее значимые признаки) вводят так называемые коэффициенты ценности признака или весовые коэффициенты. Базой обобщенного сравнения может выступать «эталонный объект» (эталонная популяция или эталонный экотип, эталонный сорт, эталонное насаждение эталонное плюсовое дерево и т.д.), имеющий наилучшие (наибольшие в смысле размеров плодов, семян, ствола и т.п. или наименьшие в смысле количества колючек на побегах, отпада за единицу времени, поражаемости вредителями и болезнями и т.п.) показатели. При этом наилучшие показатели могут быть введены только как комплекс наилучших показателей анализируемого комплекса популяций, экотипов, плюсовых деревьев, сортов и т.п. Здесь следует учитывать то, что «наилучшее значение» признака устанавливается по его реальному ненормированному значению (при сравнении показателей в исходной матрице), но в расчете статистического обобщенного расстояния используются соответствующие ему («лучшему значению») нормированные значения того же признака. В методологическом плане эталонный объект является абстракцией идеализации. В этом случае статистические координаты (С) эталонного объекта можно представить в виде (3): С = (С 1, С 2, С 3, …, С k) (3)
Тогда расчет обобщенного статистического расстояния между эталонным объектом и каждым конкретным (i -м) реальным объектом (между эталонной популяцией и любой из реальных популяций) может быть представлен в виде (4): d i = - d i – обобщенное статистическое расстояние между i -м реальным объектом и эталонным объектом.
Вместе с тем не исключена возможность введения параметров эталонного объекта как комплекса гипотетических параметров, которые должен иметь эталонный объект в соответствии с установленными задачами селекции или другой отрасли лесного хозяйства или лесной науки, даже если они не зафиксированы ни у одного объекта анализируемого комплекса. В этом случае параметры эталонного объекта вводятся в исходную матрицу и учитываются при расчете обобщенного среднего и обобщенного среднеквадратического отклонения. После этого преобразование матрицы исходных значений в матрицу нормированных значений производится по принятой ранее схеме. Ограничением в этом случае может выступать то обстоятельство, что при расчетах обобщенного среднего и обобщенного среднеквадратического отклонения (используемых при нормировании материалов исходной матрицы) трудно учесть статистическое влияние гипотетических параметров гипотетического объекта на обобщенное среднее и обобщенное среднеквадратическое отклонение. Одним из путей преодоления этого ограничения может явиться такая схема расчета, при которой обобщенные статистики рассчитываются на основе статистической обработки материалов исходной матрицы средних, с условием введения в неё параметров гипотетического объекта: в исходную матрицу и соответственно ей – матрицу нормированных значений вводят дополнительную строку, содержащую оценки всех признаков эталонного объекта в количестве, соответствующем их количеству в исходной матрице. Введение в комплекс сравнения эталонного объекта и оценка статистического расстояния между ним и каждым из реальных объектов позволяет дать оценку каждому из реальных объектов в смысле степени его приближения к эталонному объекту. Возникает возможность ранжировать анализируемые реальные объекты по критерию статистического расстояния между ними и эталонным объектом: чем ближе реальный объект к эталонному объекту, тем выше его оценка в принятой системе оценочных координат (признаков). При этом каждому из реальных объектов присваивается соответствующий ранг (от 1 до n) в зависимости от близости к эталонному объекту (табл. 3).
Таблица 3 Статистическое расстояние между природными (реальными) и эталонной (гипотетической) популяциями облепихи
Используя критерий «норма», можно разделить весь комплекс сравниваемых объектов на три категории: «лучшие», «нормальные», «худшие». Критерий «норма» устанавливается в соответствии с величиной среднеквадратического отклонения обобщенного статистического расстояния. К «нормальным» относят объекты, имеющие величины обобщенного статистического расстояния, отклоняющиеся от средней величины обобщенного статистического расстояния на величину, равную При выполнении настоящей лабораторной работы вычисление значений обобщенного статистического расстояния в многомерном пространстве признаков осуществляют для примера (Приложение 7.1 и 7.2) с плюсовыми деревьями сосны обыкновенной. Перечень и нумерация используемых в расчетах признаков плюсовых деревьев сосны обыкновенной представлены ниже. Вычисления ведут в электронных таблицах Excel. При выборе признаков для комплексного анализа исходим из того, что объекты, их носители, должны иметь некоторую принципиальную общность характеристик (размещение на одном участке, одинаковый возраст, одинаковую степень развития учитываемых метамеров и т.п.). В комплекс анализируемых признаков включались те, которые имеют хозяйственное, адаптивное и идентификационное значение. Для удобства введения в таблицы признакам были присвоены индексы (сокращенные названия). В частности для анализа ЛСП № 2 были задействованы как прямые признаки (непосредственно фиксируемые на объекте): высота дерева (пр. 1), диаметр ствола на высоте 1.3 м (пр. 2), протяженность кроны по стволу (пр. 3), расстояние от корневой шейки до первого живого сучка (пр. 4), диаметр кроны вдоль ряда (пр. 5), диаметр кроны поперек ряда (пр. 6), длина хвои (пр. 7); так и производные признаки (получаемые посредством математических преобразований прямых признаков) абсолютный сбег ствола как отношение длины ствола к его диаметру на высоте 1.3 м (пр. 8), объем ствола, вычисляемый по общепринятым формулам (пр. 9), относительное расстояние до первого живого сучка как отношение протяженности ствола до первого живого сучка к высоте дерева (пр. 10), относительная протяженность кроны как отношение протяженности кроны к высоте дерева (пр. 11), средний диаметр кроны как среднее арифметическое двух диаметров вдоль и поперек ряда (пр. 12), площадь проекции кроны как площадь круга с диаметром, равным среднему диаметру кроны (пр. 13), коэффициент пространственного объема кроны как объем цилиндра с высотой, равной высоте дерева, и с основанием, равным площади круга, диаметр которого равен среднему диаметру кроны (пр. 14), коэффициент пространственного объема дерева как объем цилиндра с высотой, равной высоте дерева, и с основанием, равным площади круга, диаметр которого равен среднему диаметру кроны (пр. 15), коэффициент формы кроны как отношение протяженности кроны к её среднему диаметру (пр. 16). Общее количество признаков многомерного пространства составило 16. На основе обобщенных расстояний в многомерном евклидовом пространстве (пространстве признаков) осуществляют кластерный анализ и построение дендрограмм, примеры которых приведены ниже (рис. 7.1)
Рисунок 7.1 – Дендрограмма соотносительной близости 21 плюсового дерева в архиве клонов № 1, построенная в евклидовом пространстве 18 признаков (представлены плюсовые деревья сосны обыкновенной)
Литература 1. Бессчетнов, В.П., Сравнительная оценка клонов на лесосеменной плантации Семеновского лесхоза/ В.П. Бессчетнов, Н.Н. Бессчетнова, Н.Н. Савина// Актуальные проблемы лесного хозяйства и рациональное использование природных ресурсов Нижегородской области: Сб. науч. тр. – Нижний Новгород, 2002 г. – С. 22 – 29. 2. Бессчетнова, Н.Н. Изменчивость клонов плюсовых деревьев сосны обыкновенной на лесосеменных плантациях/ Н.Н. Бессчетнова// Адаптивный потенциал сельскохозяйственных растений и пути его реализации в современных условиях: Сб. науч. тр. – Н. Новгород, 2002. – С. 87 – 91. 3. Бессчетнова, Н.Н. Динамика содержания крахмала в побегах представителей клоновых репродукций плюсовых деревьев сосны обыкновенной в Нижегородской области/ Н.Н. Бессчетнова// Лесной комплекс: состояние и перспективы развития: Сб. науч. тр.– Брянск, 2003а. – Вып. 5. – С.13 – 17. 4. Бессчетнова, Н.Н. Семеноводство сосны обыкновенной в Нижегородской области/ Н.Н. Бессчетнова// Плодоводство, семеноводство, интродукция древесных растений: материалы VI Международной научной конференции. г. Красноярск, 22 – 24 октября 2003 г. – Красноярск: СибГТУ, 2003б. – С. 10 – 13. 5. Бессчетнова, Н.Н. Состояние и перспективы развития лесосеменных плантаций сосны обыкновенной (Pinus sylvestris L.) в Нижегородской области/ Н.Н. Бессчетнова// Леса и лесное хозяйство в условиях рынка: проблемы и перспективы устойчивого развития: материалы Международной науч.-практ. конф., г. Алматы, 27 – 28 ноября 2003 г. – Алматы: Казахский национальный университет, 2003в. Кн. 2. – С. 59 – 64. 6. Бессчетнова, Н.Н. Корреляция признаков сосны обыкновенной на лесосеменных плантациях/ Н.Н. Бессчетнова// Лесоэкологические проблемы Поволжья: сб. науч. тр. Нижегородской гос. с.-х. акад. – Нижний Новгород, 2003 г. – С. 15 – 20. 7. Бессчетнова, Н.Н. Стратегия формирования баз данных о репродукциях клонов плюсовых деревьев сосны обыкновенной и их использование в селекционном улучшении лесов Нижегородской области/ Н.Н. Бессчетнова// Стратегия развития сельского, лесного хозяйства и сферы услуг в Российской Федерации и в мире: материалы Междунар. симпоз., г. Нижний Новгород, 4 – 5 ноября 2003 г. – Нижний Новгород, 2003д. – С. 84 – 86. 8. Бессчетнова, Н.Н. Изменчивость шишек у представителей клоновых репродукций плюсовых деревьев сосны обыкновенной/ Н.Н. Бессчетнова// Плодоводство, семеноводство, интродукция древесных растений / материалы VII Международной научной конференции, г. Красноярск, 15 – 17 сентября 2004 г. – Красноярск: СибГТУ, 2004а. – С. 27 – 30. 9. Бессчетнова, Н.Н. Сравнительный анализ вегетативного потомства плюсовых деревьев сосны обыкновенной по параметрам хвои/ Н.Н. Бессчетнова// Актуальные проблемы лесного комплекса: сб. науч. тр. по итогам 5-ой международной научно-технической конференции «Лес-2004».– Брянск: БГИТА, 2004б. – Вып. 8. – С. 11 – 13. 10. Бессчетнова, Н.Н. Изменчивость вегетативного потомства плюсовых деревьев сосны обыкновенной по морфологическим признакам хвои/ Структурно-функциональная организация и динамика лесов/ Н.Н. Бессчетнова// Материалы Всероссийской конф., посвященной 60-летию Института леса им. В.Н. Сукачева СО РАН и 70-летию образования Красноярского края, г. Красноярск, 1 – 3 сентября 2004в г. – Красноярск: Институт леса им. В.Н. Сукачева СО РАН, 2004. – С. 406 – 408. 11. Бессчетнова, Н.Н. Экологические аспекты формирования ассортимента лесосеменных плантаций сосны обыкновенной в Нижегородской области/ Н.Н. Бессчетнова// Вестник БГТУ им. В.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2021-03-09; просмотров: 102; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.16.10.2 (0.014 с.) |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

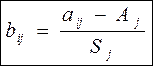 , где: (1)
, где: (1)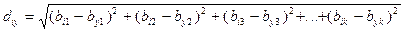
 , где: (2):
, где: (2):
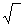 (b i1- c 1)2+(b i2- c 2)2+(b i3- c 3)2+…+(b ik- c k)2, где: (4)
(b i1- c 1)2+(b i2- c 2)2+(b i3- c 3)2+…+(b ik- c k)2, где: (4)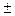 2/3 σ. В эту категорию будут отнесены все объекты, которые имеют величину обобщенного статистического расстояния от эталонного объекта в пределах
2/3 σ. В эту категорию будут отнесены все объекты, которые имеют величину обобщенного статистического расстояния от эталонного объекта в пределах