Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Линейные методы снижения размерности
Линейные методы снижения размерности направлены на нахождение нового координатного пространства Всесторонне изученным является использование в качестве осей нового пространства Метод главных компонент (МГК) был предложен Пирсоном в 1901 году и затем вновь открыт и детально разработан Хоттелингом /1933/. Ему посвящено большое количество исследований, и он широко представлен в литературных источниках. Обратим внимание на основные феномены МГК. МГК осуществляет переход к новой системе координат y 1, …, yp в исходном пространстве признаков x 1, …, xp, которая является системой ортонормированных линейных комбинаций /Айвазян С. А. и др., 1974, 1983, 1989/
где mi — математическое ожидание признака xi. Линейные комбинации выбираются таким образом, что среди всех возможных линейных нормированных комбинаций исходных признаков первая главная компонента y 1(x) обладает наибольшей дисперсией. Геометрически это выглядит как ориентация новой координатной оси y 1 вдоль направления наибольшей вытянутости эллипсоида рассеивания объектов исследуемой выборки в пространстве признаков x 1, …, xp. Вторая главная компонента имеет наибольшую дисперсию среди всех оставшихся линейных преобразований, некоррелированных с первой главной компонентой. Она интерпретируется как направление наибольшей вытянутости эллипсоида рассеивания, перпендикулярное первой главной компоненте. Следующие главные компоненты определяются по аналогичной схеме. Вычисление коэффициентов главных компонент wij основано на том факте, что векторы w1 = (w 11, …, wp 1)T, …, wp = (w 1 p , …, wpp)T являются собственными (характеристическими) векторами корреляционной матрицы S. В свою очередь, соответствующие собственные числа этой матрицы равны дисперсиям проекций множества объектов на оси главных компонент. Из ряда ценных свойств главных компонент с точки зрения визуализации многомерных данных выделяют свойства наименьшего искажения структуры исходных точек (объектов) при их проецировании в пространство меньшей размерности, «натянутое» на первые главные компоненты. Этими свойствами определяется полезность МГК при изучении структуры многомерных данных. Практически ни одно современное исследование такой структуры не обходится без того, чтобы не рассмотреть проекции объектов в пространстве, натянутом на первую, первые две и, реже, первые три главные компоненты. Нередко прибегают к анализу проекций объектов в пространства, образованные комбинациями главных компонент более высокого порядка, например 3‑й и 4‑й ГК, 5‑й и 6‑й и т.п.
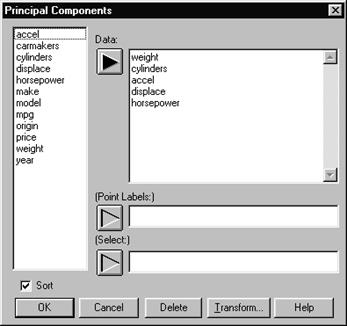
Пример применения метода главных компонент Ниже рассматривается пример, относящийся к сравнительному оцениванию изделий, характеризующихся одновременно несколькими параметрами. Это — автомобили. В таблице приводятся выборочные сведения о фирме-изготовителе автомобиля, названии модели, а также оценочные параметры — вес (переменная weight), число цилиндров (переменная cylinders), ускорение (переменная accel), объем двигателя (переменная displace) и мощность в лошадиных силах (переменная horspower). Таблица 7. 2
Введем эти данные в электронную таблицу STATGRAPHICS (в ней присутствуют также другие дополнительные параметры). Назовем файл данных cardata. Выберем Special | Multivariate Methods | Principal Components. Появляется окно диалога для задания анализируемых переменных (Рис. 7. 1).
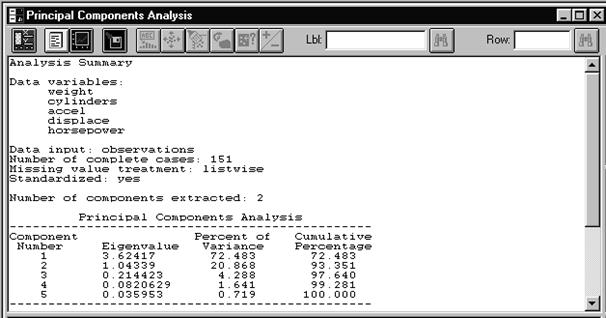
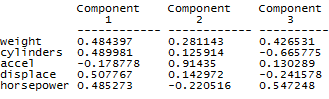
Рис. 7. 1. Окно задания переменных для анализа по методу главных компонент Нажимаем OK. Получаем исходную сводку анализа МГК (Рис. 7. 2). Из полученной сводки заключаем, что анализу подвергаются переменные weight, cylinders, accel, displace и horspower, и что число объектов составляет 151. Далее следует информация непосредственно МГК: собственные значения главных компонент, упорядоченные по величине (Eigenvalue); процент дисперсии, приходящийся на каждую выделенную главную компоненту (Percent of Variance); накопленный процент дисперсии (Cumulative Percentage). Приведенные цифры говорят о том, что уже первые две главные компоненты описывают 93,4 % дисперсии исходных данных. Третья главная компонента добавляет еще приблизительно 4,2 % дисперсии, так что в сумме это получается 97, 6% дисперсии. Для более детального анализа нажмем кнопку табличных опций (вторая слева в верхнем ряду) и в соответствующем окне диалога (Рис. 7. 3) установим флажок компонентных весов (Component Weights). Получим следующую таблицу (Рис. 7. 4).
Рис. 7. 2. Исходная сводка МГК
Рис. 7. 3. Окно диалога табличных опций МГК
Рис. 7. 4. Веса признаков в главных компонентах Как следует из полученных цифр, в первой главной компоненте примерно одинаковые по величине положительные коэффициенты имеют: вес, количество цилиндров, объем двигателя и мощность в лошадиных силах. Вместе с тем, во второй главной компоненте превалирует только одна величина: ускорение. А в третьей главной компоненте наблюдается сочетание веса машины и ее мощности (с положительным знаком), которому противопоставляется количество цилиндров (с отрицательным знаком). Не углубляясь в интерпретацию полученных главных компонент, которая, конечно, может представлять интерес для специалистов, перейдем к рассмотрению диаграммы рассеивания всей совокупности автомашин в пространстве выделенных трех первых главных компонент. Для этого щелкнем левой кнопкой мыши на кнопке графических опций и инициализируем данное трехмерное отображение.
Рис. 7. 5. Графические опции метода главных компонент
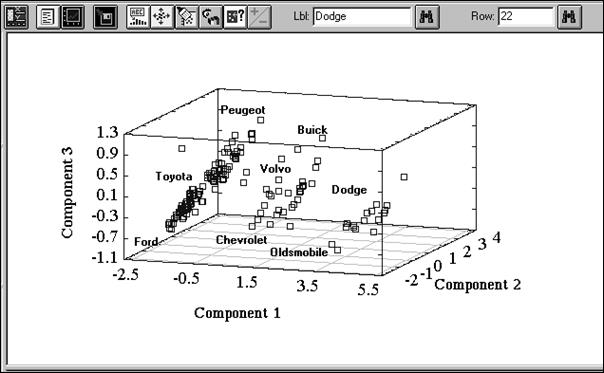
Рис. 7. 6. Проекция исследуемых автомобилей в пространство первых трех ГК На представленном рисунке хорошо видно, что вся исследуемая совокупность автомашин разделилась на три достаточно четко выраженные группы. Для большей выразительности на рисунке даны названия некоторых фирм, производящих автомобили, которые выдаются в специальных окнах STATGRAPHICS после нажатия пятой справа кнопки в верхнем ряду и маркировки интересующей точки.
Для первой наиболее многочисленной группировки характерны сравнительно небольшие: вес, количество цилиндров, мощность и объем двигателя (первая слева группа). Вместе с тем, большая доля автомашин этой группы обладают хорошим ускорением (высокие значения 2‑й ГК) и высоким соотношением веса и мощности к количеству цилиндров (3‑я ГК). Вторая группировка не столь многочисленна, но для нее также свойственны указанные характеристики, хотя и менее ярко выраженные. И, наконец, третья группа автомашин (сравнительно малочисленная) имеет большой вес, мощность, количество, цилиндров. В то же время, показатели ускорения и соотношение веса и мощности к количеству цилиндров здесь (если говорить в целом) гораздо меньшие. Таким образом, произведенный анализ данных с помощью метода главных компонент позволяет получить более «объемное» видение современного автомобильного рынка, что может способствовать лучшей ориентации как потребителей этой продукции, так и производителей с позиций оценки существующих тенденций. Факторный анализ. В отличие от метода главных компонент факторный анализ основан не на дисперсионном критерии автоинформативности системы признаков, а ориентирован на объяснение имеющихся между признаками корреляций. Основная модель факторного анализа записывается следующей системой равенств /Налимов В. В., 1971/
То есть полагается, что значения каждого признака xi могут быть выражены взвешенной суммой латентных переменных (простых факторов) fj, количество которых меньше числа исходных признаков, и остаточным членом ei с дисперсией s 2(ei), действующей только на xi, который называют специфическим фактором. Коэффициенты lij называются нагрузкой i -й переменной на j -й фактор или нагрузкой j -го фактора на i -ю переменную. В самой простой модели факторного анализа считается, что факторы fj взаимно независимы и их дисперсии равны единице, а случайные величины ei тоже независимы друг от друга и от какого-либо фактора fj. Максимально возможное количество факторов m при заданном числе признаков p определяется неравенством
которое должно выполняться, чтобы задача не вырождалась в тривиальную. Данное неравенство получается на основании подсчета степеней свободы, имеющихся в задаче /Лоули Д. и др., 1967/. Сумму квадратов нагрузок называют общностью соответствующего признака xi и чем больше это значение, тем лучше описывается признак xi выделенными факторами fj. Общность есть часть дисперсии признака, которую объясняют факторы. В свою очередь,
дисперсия признака = общность Основное выражение факторного анализа показывает, что коэффициент корреляции любых двух признаков xi и xj можно выразить суммой произведения нагрузок некоррелированных факторов
Задачу факторного анализа нельзя решить однозначно. Равенства в факторной модели не поддаются непосредственной проверке, так как p исходных признаков задается через (p + m) других переменных — простых и специфических факторов. Поэтому представление корреляционной матрицы факторами, как говорят ее факторизацию можно произвести бесконечно большим числом способов. Если удалось произвести факторизацию корреляционной матрицы с помощью некоторой матрицы факторных нагрузок F, то любое линейное ортогональное преобразование F (ортогональное вращение) приведен к такой же факторизации /Налимов В. В., 1971/. Поэтому нередко в одном и том же пакете программ анализа данных реализовано сразу несколько версий методов факторизации, и у исследователей возникает закономерный вопрос, какой из них лучше. Здесь сошлемся на слова одного из основоположников современного факторного анализа Г. Хартмана: «Ни в одной из работ не было показано, что какой-либо один метод приближается к ²истинным² значениям общностей лучше, чем другие методы… Выбор среди группы методов наилучшего производится в основном с точки зрения вычислительных удобств, а также склонностей и привязанностей исследователя, которому тот или иной метод казался более адекватным его представлениям об общности» /цит. по Александров В. В. и др., 1990/. В настоящее время одними из наиболее популярных являются три метода вращения факторов: варимакс, квартимакс и эквимакс. Вращение методом варимакс ставит целью упростить столбцы факторной матрицы, сводя все значения к 1 или 0. Вращение методом квартимакс ставит целью аналогичное упрощение только по отношению к строкам факторной матрицы. И, наконец, эквимакс занимает промежуточное положение — при вращении факторов по этому методу одновременно делается попытка упростить и столбцы и строки. Кроме перечисленных трех методов нередко осуществляют вращение факторов до тех пор, пока не получатся результаты, поддающиеся содержательной интерпретации. Можно, например, потребовать, чтобы один фактор был нагружен преимущественно признаками одного типа, а другой — признаками другого типа. Или, скажем можно потребовать, чтобы исчезли какие-то трудно интерпретируемые нагрузки с отрицательными знаками. Нередко исследователи идут дальше и рассматривают прямоугольную систему факторов как частный случай косоугольной, то есть ради содержания жертвуют условием некоррелированности факторов. В целом по факторному анализу можно отметить следующее. С помощью такого анализа снижение размерности достигается за счет существования групп взаимосвязанных признаков, которые агрегируются в строящихся факторах. Как и при использовании метода главных компонент, полезные сведения о структуре данных можно почерпнуть на основании визуального анализа проектов объектов в одно-, двух- и трехмерные пространства, образованные комбинациями различных факторов. Также ценную информацию о структуре исследуемой выборки могут дать результаты факторного анализа, проведенного раздельно в различных подгруппах объектов. Другие методы линейного проецирования данных, развиваются в рамках направления, получившего название разведочный анализ данных /Тьюки Дж., 1981/. Современные методы проецирования, в частности методы целенаправленного проецирования, являются естественным обобщением охарактеризованных выше классических методов анализа данных. Их систематизация и характеристики представлены в /Айвазян С. А. и др., 1989/. Пример применения факторного анализа Факторный анализ широко применяется в экономике, социологии, медицине для выявления скрытых закономерностей в данных. Но, может быть, наиболее широко он используется в психологии, из которой собственно идут корни факторной статистической техники. Этим объясняется выбор нижеследующего примера, связанного с изучением структуры интеллекта на основе данных, полученных с помощью психологического тестирования. Настоящий пример адаптирован по данным, приведенным в отчете об изучении пожилых людей /Morrison D. F., 1990/. Испытуемые были разбиты с помощью теста Векслера на две полярные группы. Для первой группы характерно наличие признаков старения, для второй такие признаки отсутствуют. В нашем случае будут рассмотрены 37 человек, у которых признаки старения выражены. Мы выделим (на основе экспериментальных данных) факторы и проинтерпретируем их. Откроем файл данных с названием Senile.sf. Таблица 7. 3. Таблица с экспериментальными данными
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2021-03-10; просмотров: 265; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 13.58.121.131 (0.026 с.) |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
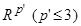 , в котором каждая координатная ось является линейной комбинацией исходных признаков. Популярность данного подхода объясняется тем, что линейные комбинации признаков хорошо интерпретируются — коэффициенты в уравнениях координатных осей трактуются, например, как веса или вклады признаков.
, в котором каждая координатная ось является линейной комбинацией исходных признаков. Популярность данного подхода объясняется тем, что линейные комбинации признаков хорошо интерпретируются — коэффициенты в уравнениях координатных осей трактуются, например, как веса или вклады признаков.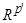 первых главных компонент (ГК).
первых главных компонент (ГК).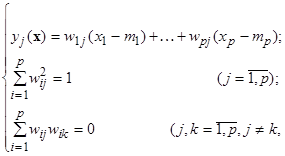
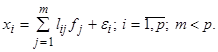
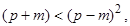
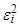 показывает, какая часть дисперсии исходного признака остается необъясненной при используемом наборе факторов, и данную величину называют специфичностью признака. Таким образом,
показывает, какая часть дисперсии исходного признака остается необъясненной при используемом наборе факторов, и данную величину называют специфичностью признака. Таким образом,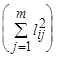 + специфичность
+ специфичность