
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Заполняющие пространство кривые
Суть данной группы методов состоит в заполнении пространства признаков гиперкривой таким образом, чтобы близкие в пространстве объекты оказались по возможности близкими и на этой кривой. Визуальному анализу подвергаются гистограммы распределений объектов на построенной гиперкривой. Весь процесс называется разверткой пространства признаков. В /Александров В. В. и др., 1978/ описан рекурсивный алгоритм порождения кривой, заполняющей многомерный интервал, дальнейшее исследование которого проводилось, например, в /Горский Н. Д., 1981/. Для построения заполняющей пространство кривой (ЗПК) табличные данные приводятся к единичному p -мерному гиперкубу. Стороны этого гиперкуба разбиваются на части и получают квантованное p -мерное. ЗПК порождается путем задания рекурсивного правила обхода данных квантов. Главными свойствами отображений объектов на ЗПК является взаимная однозначность, сходимость по разбиениям и квазинепрерывность. Взаимная однозначность выражает строго определенное соответствие каждого кванта p -мерного пространства какому-либо участку ЗПК. Сходимость по разбиениям означает, что при очередном дроблении пространства Приведенные свойства дают основание считать ЗПК полезным инструментом исследования структуры данных. Развертки пространства признаков
Методы автоматического группирования Факторный анализ объектов. При факторном анализе объектов используется формальный аппарат факторного анализа, изначально предназначавшийся для агрегирования взаимосвязанных признаков. Этому аппарату была дана характеристика в предыдущем подразделе. Отличие состоит в том, что в факторном анализе объектов таблица экспериментальных данных поворачивается на 90 0 (транспонируется), то есть объекты и признаки меняются местами. Если при факторном анализе признаков ищутся группы близких (коррелированных) признаков на основе корреляционной матрицы, то для транспонированных данных аналогом корреляционной матрицы является матрица, описывающая попарные коэффициенты корреляции (сходства) объектов. Она вводится в алгоритм формального факторного анализа, и в результате получаются факторы, описывающие уже не группы коррелированных признаков, а группы сходных объектов /Александров В. В. и др., 1990/. Особенности данной процедуры подробно рассмотрены в /Айвазян С. А. и др., 1974/. Кластерный анализ. Этот анализ предназначен для разбиения множества объектов на заданное или неизвестное число классов на основании некоторого математического критерия качества классификации (cluster (англ.) — гроздь, пучок, скопление, группа элементов, характеризуемых каким-либо общим свойством). Критерий качества кластеризации в той или иной мере отражает следующие неформальные требования /Миркин Б. Г., 1980/: a) внутри групп объекты должны быть тесно связаны между собой; b) объекты разных групп должны быть далеки друг от друга; c) при прочих равных условиях распределения объектов по группам должны быть равномерными. Требования a) и b) выражают стандартную концепцию компактности классов разбиения /Аркадьев А. Г. и др., 1971/; требование c) состоит в том, чтобы критерий не навязывал объединения отдельных групп объектов. Узловым моментом в кластерном анализе считается выбор метрики (или меры близости объектов), от которого решающим образом зависит окончательный вариант разбиения объектов на группы при заданном алгоритме разбиения /Айвазян С. А. и др., 1989/. В каждой конкретной задаче этот выбор производится по-своему, с учетом главных целей исследования, физической и статистической природы исследуемой информации и т.п.
Другой важной величиной в кластерном анализе является расстояние между целыми группами объектов. Приведем примеры наиболее распространенных расстояний, характеризующих взаимное расположение отдельных групп объектов. Пусть wl — l ‑я группа (класс, кластер) объектов, Nl — число объектов, образующих группу, вектор ml — среднее арифметическое объектов, входящих в wl (другими словами «центр тяжести» l -й группы), а r (wl, wm ) — расстояние между группами wl и wm.
Рис. 7. 18. Различные способы определения расстояния между кластерами: 1 — по ближайшим объектам, 2 — по центрам тяжести, 3 — по самым дальним объектам Расстояние ближайшего соседа есть расстояние между ближайшими объектами кластеров:
Расстояние центров тяжести равно расстоянию между центральными точками кластеров
Расстояние дальнего соседа — расстояние между самыми дальними объектами кластеров
Выбор той или иной меры расстояния между кластерами влияет, главным образом, на вид выделяемых алгоритмами кластерного анализа геометрических группировок объектов в пространстве признаков. Так, алгоритмы, основанные на расстоянии ближайшего соседа, хорошо работают в случае группировок, имеющих сложную, в частности, цепочечную структуру. Расстояние дальнего соседа применяется, когда искомые группировки образуют в пространстве признаков шаровидные облака. И промежуточное место занимают алгоритмы, использующие расстояние центров тяжести и средней связи, которые лучше всего работают в случае группировок эллипсоидной формы. Нацеленность алгоритмов кластерного анализа на определенную структуру группировок объектов в пространстве признаков может приводить к неоптимальным или даже неправильным результатам, если гипотеза о типе группировок неверна. В случае отличия реальных распределений от гипотетических указанные алгоритмы часто «навязывают» данным не присущую им структуру и дезориентируют исследователя. Поэтому экспериментатор, учитывающий данный факт в условиях априорной неопределенности прибегает к применению батареи алгоритмов кластерного анализа и отдает предпочтение какому либо выводу на основании комплексной оценки результатов работы этих алгоритмов. Алгоритмы кластерного анализа отличаются большим разнообразием. Это могут быть, например, алгоритмы, реализующие полный перебор сочетаний объектов или осуществляющие случайные разбиения множества объектов. Вместе с тем, большинство таких алгоритмов состоит из двух этапов. На первом этапе задается начальное (возможно, искусственное или даже произвольное) разбиение множества объектов на классы и определяется некоторый математический критерий качества автоматической классификации. Затем, на втором этапе, объекты переносятся из класса в класс до тех пор, пока значение критерия не перестанет улучшаться. Многообразие алгоритмов кластерного анализа обусловлено также множеством различных критериев, отражающих те или иные аспекты качества автоматического группирования. Простейший критерий качества непосредственно базируется на величине расстояния между кластерами. Однако такой критерий не учитывает «населенность» кластеров — относительную плотность распределения объектов внутри выделяемых группировок. Поэтому другие критерии основываются на вычислении средних расстояний между объектами внутри кластеров. Но наиболее часто применяют критерии в виде отношений показателей «населенности» кластеров к расстоянию между ними. Это, например, может быть отношение суммы межклассовых расстояний к сумме внутриклассовых (между объектами) расстояний или отношение общей дисперсии данных к сумме внутриклассовых дисперсии и дисперсий центров кластеров.
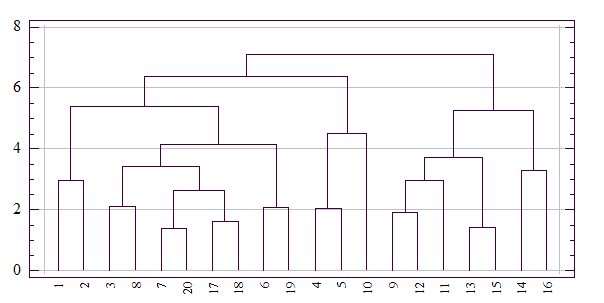
Функционалы качества и конкретные алгоритмы автоматической классификации (группирования) достаточно полно и подробно рассмотрены в /Айвазян С. А. и др., 1989/. Иерархическое группирование Процедуры иерархического типа предназначены для получения наглядного представления о стратификационной структуре всей исследуемой совокупности объектов. Эти процедуры основаны на последовательном объединении кластеров (агломеративные процедуры) и на последовательном разбиении (дивизимные процедуры). Наибольшее распространение получили агломеративные процедуры. Они выглядят следующим образом. На первом шаге все объекты считаются отдельными кластерами. Затем на каждом шаге два ближайших кластера объединяются в один. Каждое объединение уменьшает число кластеров на один так, что в конце концов все объекты объединяются в один кластер. Наиболее подходящее разбиение выбирает чаще всего сам исследователь, которому предоставляется дендрограмма, отображающая результаты группирования на всех шагах алгоритма (рис. 7. 19). Могут одновременно также использоваться и математические критерии качества группирования.
Рис. 7. 19. Результаты работы иерархической агломеративной процедуры группирования объектов, представленные в виде дендрограммы (количество объектов — 20, расстояние между кластерами — дальний сосед, евклидова метрика) Различные варианты определения расстояния между кластерами дают различные варианты иерархических процедур. Учитывая их специфику, для задания расстояния между кластерами оказывается достаточным указать порядок пересчета расстояний между кластером k и кластером (i, j), являющимся объединением двух других кластеров i и j по расстояниям
где В отличие от оптимизационных кластерных алгоритмов, предоставляющих исследователю конечный результат группирования объектов, иерархические процедуры позволяют проследить процесс выделения кластеров, образующихся на разных шагах агломеративного или дивизимного алгоритма. Это стимулирует воображение исследователя и помогает ему привлекать для оценки структуры данных дополнительные формальные и неформальные представления.
|
||||||||
|
|
Последнее изменение этой страницы: 2021-03-10; просмотров: 113; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.138.134.107 (0.02 с.) |
 на ЗПК сохраняется закон принадлежности отображений новых, более мелких квантов старому — более крупному. Под квазинепрерывностью понимается то, что два соседних отображения квантов на ЗПК обязательно являются также соседними в многомерном пространстве
на ЗПК сохраняется закон принадлежности отображений новых, более мелких квантов старому — более крупному. Под квазинепрерывностью понимается то, что два соседних отображения квантов на ЗПК обязательно являются также соседними в многомерном пространстве 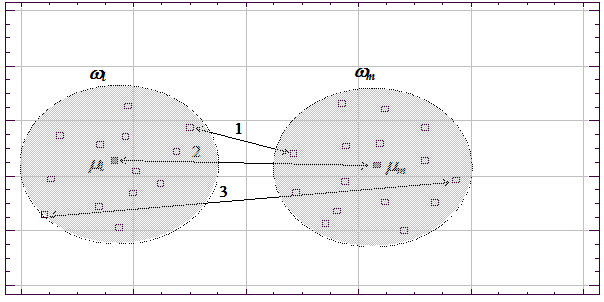
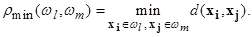
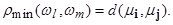

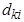 ,
,  и
и 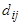 . Для этого используется широко известная формула
. Для этого используется широко известная формула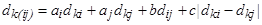 ,
,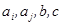 — параметры, которыми определяется тот или иной вид расстояния между кластерами. Например, при
— параметры, которыми определяется тот или иной вид расстояния между кластерами. Например, при 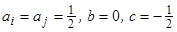 приходим к расстоянию, измеряемому по принципу «ближайших соседей» между двумя кластерами;
приходим к расстоянию, измеряемому по принципу «ближайших соседей» между двумя кластерами;  дает расстояние, измеряемое по принципу «дальнего соседа» и т. д.
дает расстояние, измеряемое по принципу «дальнего соседа» и т. д.


