
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Сортировка фон Неймана (слиянием)Содержание книги
Поиск на нашем сайте
Метод основан на идее слияния двух отсортированных частей массива, поэтому первоначально массив разбивается на две части, которые независимо сортируются, а затем результаты сливаются в единое целое. С каждой из частей выполняются аналогичные действия, до тех пор, пока количество элементов в сортируемой части массива не станет равно двум. В этом случае выполняется простое сравнение элементов и их перестановка, если она необходима.
Пирамидальная сортировка: 1. Построение пирамиды Если в исходном массиве n элементов, то последние (n / 2) элемента становятся основанием пирамиды (эти элементы являются листьями дерева, т.е. у них нет потомков, поэтому для них вышеуказанное правило выполняется автоматически). Удобнее всего поместить пирамиду в массив. При этом распределение индексов массива по узлам дерева будет выглядеть так (на этом рисунке все цифры - это индексы элементов массива, а ни в коем случае не значения этих элементов): Таким образом, для того, чтобы каждый узел дерева был больше своих потомков, каждый элемент массива a[i] должен быть больше или равен элементам a[2 * i + 1] и a[2 * i + 2]. 2. Сортировка Шейкер сортировка: Это модификация метода «пузырька», которая учитывает два дополнительных требования: 1) устранение «лишних» просмотров массива, т.е. если массив уже отсортирован за первые проходы, последующие проходы не делаем. Пример: 12,3,5,7,9,10. 2) смена направлений прохода массива: сначала проходим от начала к концу, по том – от конца к началу, потом снова от начала к концу и т.д. Это позволяет уменьшить число проходов по массиву. Пример: 5,7,9,10,12,3.
Сортировка подсчетом: Идея алгоритма состоит в том, чтобы для каждого элемента x предварительно подсчитать, сколько элементов входной последовательности меньше x. После этого х записывается напрямую в выходной массив в соответствии с этим числом. Например, если семнадцать элементов входного массива меньше х, то в выходном массиве х должен быть записан на место с номером восемнадцать. Используются следующие обозначения: Работа алгоритма заключается в следующем.
Цифровая сортировка: Этой сортировкой можно сортировать целые неотрицательные числа большого диапазона. Идея состоит в следующем: отсортировать числа по младшему разряду, потом устойчивой сортировкой сортируем по второму, третьему, и так до старшего разряда.
17)
Линейный, последовательный поиск — алгоритм нахождения заданного значения произвольной функции на некотором отрезке. Данный алгоритм является простейшим алгоритмом поиска и в отличие, например, от двоичного поиска, не накладывает никаких ограничений на функцию и имеет простейшую реализацию. Поиск значения функции осуществляется простым сравнением очередного рассматриваемого значения (как правило поиск происходит слева направо, то есть от меньших значений аргумента к большим) и, если значения совпадают (с той или иной точностью), то поиск считается завершённым.
Бинарный поиск – Если у нас есть массив, содержащий упорядоченную последовательность данных, то очень эффективен двоичный поиск. Переменные Lb и Ub содержат, соответственно, левую и правую границы отрезка массива, где находится нужный нам элемент. Мы начинаем всегда с исследования среднего элемента отрезка. Если искомое значение меньше среднего элемента, мы переходим к поиску в верхней половине отрезка, где все элементы меньше только что проверенного. Другими словами, значением Ub становится (M – 1) и на следующей итерации мы работаем с половиной массива. Таким образом, в результате каждой проверки мы вдвое сужаем область поиска. Так, в нашем примере, после первой итерации область поиска – всего лишь три элемента, после второй остается всего лишь один элемент. Таким образом, если длина массива равна 6, нам достаточно трех итераций, чтобы найти нужное число.
|
||||
|
|
Последнее изменение этой страницы: 2020-12-09; просмотров: 216; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.188.245.152 (0.006 с.) |

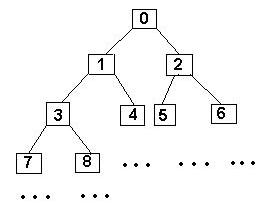

 Методы поиска: линейный поиск, метод бинарного писка, поиск с помощью бинарного дерева, метод случайного поиска.
Методы поиска: линейный поиск, метод бинарного писка, поиск с помощью бинарного дерева, метод случайного поиска.


