Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Базовые информационные технологии
Технологии баз данных
Современные авторы часто употребляют термины «банк данных» и «база данных» как синонимы, однако в общеотраслевых руководящих материалах по созданию банков данных Государственного комитета по науке и технике (ГКНТ), изданных в 1982 г., эти понятия различаются. Там приводятся следующие определения банка данных, базы данных и СУБД: Банк данных (БнД) –это система специальным образом организованных данных – баз данных, программных, технических, языковых, организационно-методических средств, предназначенных для обеспечения централизованного накопления и коллективного многоцелевого использования данных. База данных –именованная совокупность данных, отражающая состояние объектов и их отношений в рассматриваемой предметной области. Система управления базами данных (СУБД) –совокупность языковых и программных средств, предназначенных для создания, ведения и совместного использования БД многими пользователями. Понятие «данные» в концепции баз данных – это набор конкретных значений, параметров, характеризующих объект, условие, ситуацию или любые другие факторы. Модель данных – это некоторая абстракция, которая, будучи приложима к конкретным данным, позволяет трактовать их как информацию, то есть сведения, содержащие не только данные, но и взаимосвязь между ними. Программы, с помощью которых пользователи работают с базой данных, называются приложениями. История СУБД как особого вида программного обеспечения неразрывно связана с историей начала использования электронно-вычислительных машин для организации хранения и обработки информации. Именно в то время (конец 60-х, начало 70-х годов) были разработаны основы программного обеспечения для создания и эксплуатации фактографических информационных систем. В конце 70-х, начале 80-х годов направление программного обеспечения под общим названием «СУБД» превратилось в одну из наиболее бурно развивающихся отраслей программной индустрии. С начала своего возникновения в конце 60-х годов автоматизированные информационные системы ориентировались на хранение и обработку больших объемов данных, которые не могли быть одновременно и полностью размещены в оперативной памяти ЭВМ. В структуре программного обеспечения ЭВМ как в то время, так и сейчас за организацию, размещение и оперирование данными во внешней (долговременной) памяти отвечает операционная система ЭВМ, соответствующий компонент которой чаще всего называется «файловой системой». Данные во внешней памяти компьютера представлены именованными совокупностями, называемыми файлами. В большинстве случаев операционная (файловая) система не «знает» внутренней смысловой логики организации данных в файлах и оперирует с ними как с однородной совокупностью байтов или строк символов. С точки зрения смысла и назначения АИС файлы данных имеют структуру, отражающую информационно-логическую схему предметной области АИС. Эта структура данных в файлах должна обязательно учитываться в операциях обработки (собственно, в этом и заключается одна из основных функций АИС). Вместе с тем, в силу невозможности в большинстве случаев размещения файлов баз данных сразу целиком в оперативной памяти компьютера, структуру данных в файлах баз данных приходится учитывать при организации операций обращения к файлам во внешней памяти.
Отсюда вытекает основная особенность СУБД как вида программного обеспечения. Будучи по природе прикладным программным обеспечением, т. е. предназначенным для решения конкретных прикладных задач, СУБД изначально выполняли и системные функции – расширяли возможности файловых систем системного программного обеспечения. В процессе научных исследований, посвященных тому, как именно должна быть устроена СУБД, предлагались различные способы реализации. Самым жизнеспособным из них оказалась предложенная американским комитетом по стандартизации ANSI (American National Standards Institute) трехуровневая система организации БД, изображенная на рис. 25:
Рис. 25. Трехуровневая модель системы управления базой данных
1. Уровень внешних моделей – самый верхний уровень, где каждая модель имеет свое «видение» данных. Этот уровень определяет точку зрения на БД отдельных приложений. Каждое приложение видит и обрабатывает только те данные, которые необходимы именно этому приложению. Например, система распределения работ использует сведения о квалификации сотрудника, но ее не интересуют сведения об окладе, домашнем адресе и телефоне сотрудника, и наоборот, именно эти сведения используются в подсистеме отдела кадров.
2. Концептуальный уровень – центральное управляющее звено, здесь база данных представлена в наиболее общем виде, который объединяет данные, используемые всеми приложениями, работающими с данной базой данных. Фактически концептуальный уровень отражает обобщенную модель предметной области (объектов реального мира), для которой создавалась база данных. Как любая модель, концептуальная модель отражает только существенные, с точки зрения обработки, особенности объектов реального мира. 3. Физический уровень – собственно данные, расположенные в файлах или в страничных структурах, расположенных на внешних носителях информации. Эта архитектура позволяет обеспечить логическую (между уровнями 1 и 2) и физическую (между уровнями 2 и 3) независимость при работе с данными. Логическая независимость предполагает возможность изменения одного приложения без корректировки других приложений, работающих с этой же базой данных. Физическая независимость предполагает возможность переноса хранимой информации с одних носителей на другие при сохранении работоспособности всех приложений, работающих с данной базой данных. Это именно то, чего не хватало при использовании файловых систем. Выделение концептуального уровня позволило разработать аппарат централизованного управления базой данных. В общем плане можно выделить следующие функции, реализуемые СУБД: · организация и поддержание логической структуры данных (схемы базы данных); · организация и поддержание физической структуры данных во внешней памяти; · организация доступа к данным и их обработка в оперативной и внешней памяти. Организация и поддержание логической структуры данных (схемы базы данных) обеспечивается средствами модели организации данных. Модель данных определяется способом организации данных, ограничениями целостности и множеством операций, допустимых над объектами организации данных. Соответственно модель данных разделяют на три составляющие – структурную, целостную и манипуляционную. Известны три основные модели организации данных: иерархическая; сетевая; реляционная. Модель данных, реализуемая СУБД, является одной из основных компонент, определяющих функциональные возможности СУБД по отражению в базах данных информационно-логических схем предметных областей АИС. Модель организации данных, по сути, определяет внутренний информационный язык автоматизированного банка данных, реализующего автоматизированную информационную систему. Модели данных, поддерживаемые СУБД, довольно часто используются в качестве критерия для классификации СУБД. Исходя из этого, различают иерархические СУБД, сетевые СУБД и реляционные СУБД. Другой важной функцией СУБД является организация и поддержание физической структуры данных во внешней памяти. Эта функция включает организацию и поддержание внутренней структуры файлов базы данных, иногда называемой форматом файлов базы данных, а также создание и поддержание специальных структур (индексы, страницы) для эффективного и упорядоченного доступа к данным. В этом плане эта функция тесно связана с третьей функцией СУБД – организацией доступа к данным.
Организация и поддержание физической структуры данных во внешней памяти может производиться как на основе штатных средств файловых систем, так и на уровне непосредственного управления СУБД устройствами внешней памяти. Организация доступа к данным и их обработка в оперативной и внешней памяти осуществляется через реализацию процессов, получивших название транзакций. Транзакцией называют последовательную совокупность операций, имеющую отдельное смысловое значение по отношению к текущему состоянию базы данных. Так, например, транзакция по удалению отдельной записи в базе данных последовательно включает определение страницы файла данных, содержащей указанную запись, считывание и пересылку соответствующей страницы в буфер оперативной памяти, собственно удаление записи в буфере ОЗУ, проверку ограничений целостности по связям и другим параметрам после удаления и, наконец, «выталкивание» и фиксацию в файле базы данных нового состояния соответствующей страницы данных. Транзакции принято разделять на две разновидности – изменяющие состояние базы данных после завершения транзакции и изменяющие состояние БД лишь временно, с восстановлением исходного состояния данных после завершения транзакции. Совокупность функций СУБД по организации и управлению транзакциями называют монитором транзакций. Транзакции в теории и практике СУБД по отношению к базе данных выступают внешними процессами, отождествляемыми с действиями пользователей банка данных. При этом источником, инициатором транзакций может быть как один пользователь, так и несколько пользователей сразу. По этому критерию СУБД классифицируются на однопользовательские (или так называемые «настольные») и многопользовательские («тяжелые», «промышленные») СУБД. Соответственно в многопользовательских СУБД главной функцией монитора транзакций является обеспечение эффективного совместного выполнения транзакций над общими данными сразу от нескольких пользователей. Непосредственная обработка и доступ к данным в большинстве СУБД осуществляется через организацию в оперативной памяти штатными средствами операционной системы или собственными средствами системы буферов оперативной памяти, куда на время обработки и доступа помещаются отдельные компоненты файла базы данных (страницы). Поэтому другой составной частью функций СУБД по организации доступа и обработки данных является управление буферами оперативной памяти.
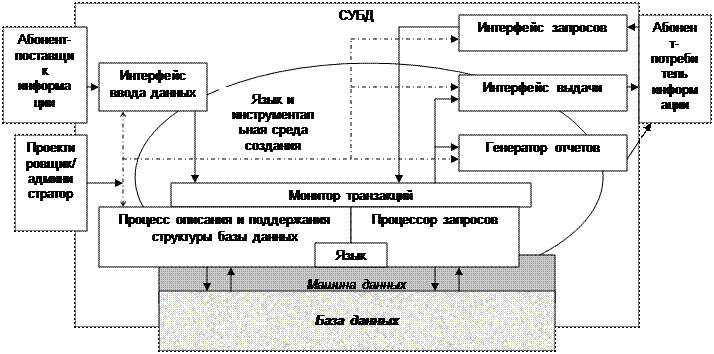
Еще одной важной функцией СУБД с точки зрения организации доступа и обработки данных является так называемая журнализация всех текущих изменений базы данных. Журнализация представляет собой основное средство обеспечения сохранности данных при всевозможных сбоях и разрушениях данных. Во многих СУБД для нейтрализации подобных угроз создается журнал изменений базы данных с особым режимом хранения и размещения. Вместе с установкой режима периодического сохранения резервной копии БД журнал изменений при сбоях и разрушениях данных позволяет восстанавливать данные по произведенным изменениям с момента последнего резервирования до момента сбоя. Во многих предметных областях АИС (например, БД с финансово-хозяйственными данными) такие ситуации сбоя и порчи данных являются критическими и возможности восстановления данных обязательны для используемой СУБД. Исходя из рассмотренных функций, в структуре СУБД всовременном представлении можно выделить следующие функциональные блоки: • процессор описания и поддержания структуры базы данных; • процессор запросов к базе данных; • монитор транзакций; • интерфейс ввода данных; • интерфейс запросов; • интерфейс выдачи сведений; • генератор отчетов. Схематично взаимодействие компонент СУБД представлено на рис. 26. Ядром СУБД является процессор описания и поддержания структуры базы данных. Онреализует модель организации данных, средствами которой проектировщик строит логическую структуру (схему) базы данных, соответствующую инфологической схеме предметной области АИС, и обеспечивает построение и поддержание внутренней схемы базы данных. Процессором описания и поддержания структуры данных в терминах используемой модели данных (иерархическая, сетевая, реляционная) обеспечиваются установки заданной логической структуры базы данных, а также трансляция (перевод) структуры базы данных во внутреннюю схему базы данных (в физические структуры данных). В АИС на базе реляционных СУБД процессор описания и поддержания структуры базы данных реализуется на основе языка базы данных, являющегося составной частью языка структурированных запросов (SQL). Интерфейс ввода данных СУБД реализует входной информационный язык банка данных, обеспечивая абонентам-поставщикам информации средства описания и ввода данных в информационную систему. Одной из современных тенденций развития СУБД является стремление приблизить входные информационные языки и интерфейс ввода к естественному языку общения с пользователем в целях упрощения эксплуатации информационных систем так называемых «неподготовленными» пользователями. Данная проблема решается через применение диалоговых методов организации интерфейса и использование входных форм. Входные формы, по сути, представляют собой электронные аналоги различного рода анкет, стандартизованных бланков и таблиц, широко используемых в делопроизводстве и интуитивно понятных большинству людей (неподготовленных пользователей). Интерфейс ввода при этом обеспечивает средства создания, хранения входных форм и их интерпретацию в терминах описания логической структуры базы данных для передачи вводимых через формы сведений процессору описания и поддержания структуры базы данных.
Интерфейс запросов совместно с процессором запросов обеспечивает концептуальную модель использования информационной системы в части стандартных типовых запросов, отражающих информационные потребности пользователей-абонентов системы. Интерфейс запросов предоставляет пользователю средства выражения своих информационных потребностей. Современной тенденцией развития СУБД является использование диалогово-наглядных средств в виде специальных «конструкторов» или пошаговых «мастеров» формирования запросов.
Рис. 26. Структура и взаимодействие компонент СУБД
Процессор запросов интерпретирует сформированные запросы в терминах языка манипулирования данными и совместно с процессором описания и поддержания структуры базы данных собственно и исполняет запросы. В реляционных СУБД основу процессора запросов составляет язык манипулирования данными, являющийся основной частью языка SQL. Тем самым на базе процессора запросов и процессора описания и поддержания структуры базы данных образуется низший уровень оперирования данными в СУБД, который иногда называют машиной данных. Стандартные функции и возможности машины данных используют компоненты СУБД более высокого порядка (см. рис. 26), что позволяет разделить и стандартизировать компоненты СУБД и банка данных на три уровня – логический уровень, машина данных и собственно сами данные. Функции монитора транзакций, как уже отмечалось, заключаются в организации совместного выполнения транзакций от нескольких пользователей над общими данными. При этом дополнительной функцией, неразрывно связанной, в том числе и с основной функцией, является обеспечение целостности данных и ограничений над данными, определяемыми правилами предметной области АИС. Интерфейс выдачи СУБД получает от процессора запросов результаты исполнения запросов (обращений к базе данных) и переводит эти результаты в форму, удобную для восприятия и выдачи пользователю-абоненту информационной системы. Для отображения результатов исполнения запросов в современных СУБД используются различные приемы, позволяющие «визуализировать» данные в привычной и интуитивно понятной неподготовленному пользователю форме. Обычно для этого применяются табличные способы представления структурированных данных, а также специальные формы выдачи данных, представляющие так же, как и формы ввода, электронные аналоги различных стандартизованных бланков и отчетов в делопроизводстве. Формы выдачи лежат также и в основе формирования так называемых «отчетов», выдающих результаты поиска и отбора информации из БД в письменной форме для формализованного создания соответствующих текстовых документов, т. е. для документирования выводимых данных. Для подобных целей в состав современных СУБД включаются генераторы отчетов. В заключение по структуре и составу СУБД следует также добавить, что современные программные средства, реализующие те или иные СУБД, представляют собой совокупность инструментальной среды создания и использования баз данных в рамках определенной модели данных (реляционной, сетевой, иерархической или смешанной) и языка СУБД (языкописания данных, язык манипулирования данными, язык и средства создания интерфейса). На основе программных средств СУБД проектировщики строят в целях реализации конкретной информационной системы (инфологичсская схема предметной области, задачи и модель использования, категории пользователей и т. д.) автоматизированный банк данных, функционирование которого в дальнейшем поддерживают администраторы системы и услугами которого пользуются абоненты системы.
Гипертекстовые технологии
В 1945 г. Ваневар Буш – научный советник президента США Г. Трумена, проанализировал способы представления информации в виде отчетов, докладов, проектов, графиков, планов и, осознав неэффективность такого представления, предложил способ размещения информации по принципу ассоциативного мышления. На основе этого принципа была разработана модель гипотетической машины «МЕ-МЕКС» – машины, которая не только хранила бы информацию, но и связывала между собой имеющие друг к другу отношение текст и картинки. «МЕМЕКС» так и остался в проекте, но через 20 лет Теодор Нельсон реализовал этот принцип на ЭВМ и назвал его гипертекстом. Под влиянием идей Буша Теодор Нельсон создал компьютерный язык, который давал возможность пользователю переходить от одного источника информации к другому через электронные ссылки. Гипертекст – это текст представленный в виде ассоциативно связанных автономных блоков. Гипертекст обладает нелинейной сетевой формой организации материала, разделенного на фрагменты, для каждого из которых указан переход к другим фрагментам по определенным типам связей. При установлении связей можно опираться на разные основания (ключи), но в любом случае речь идет о смысловой, семантической близости связываемых фрагментов. Следуя по ключу, можно получить более подробные или сжатые сведения об изучаемом объекте, можно читать весь текст или осваивать материал, пропуская известные подробности. Текст теряет свою замкнутость, становится принципиально открытым, в него можно вставлять новые фрагменты, указывая для них связи с имеющимися фрагментами. Фактически гипертекст – это технология работы с текстовыми данными, позволяющая устанавливать ассоциативные связи типа гиперсвязей или гиперссылок между фрагментами, статьями и графикой в текстовых массивах. Благодаря этому становится доступной не только последовательная, линейная работа с текстом, как при обычном чтении, но и произвольный ассоциативный просмотр в соответствии с установленной структурой связей, а также с учетом личного опыта, интересов и настроения пользователей. Гипертекстовый документ таким образом получает дополнительные измерения. С одной стороны, он подобен обычному текстовому документу, имеющему фиксированное начало и конец. С другой стороны, гипертекст одновременно организован по тематическим линиям, по индексам и библиографическим указателям. Структурно гипертекст состоит из следующих элементов, представленных на рис. 27.
Рис. 27. Структурные элементы гипертекста
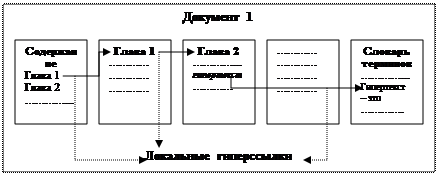
Информационный материал подразделяется на информационные статьи, состоящие из заголовка статьи и текста. Информационная статья может представлять собой файл, закладку в тексте, web-страницу. Заголовок – это название темы или наименование описываемого в информационной статье понятия. Текст информационной статьи содержит традиционные определения и понятия, т. е. описание темы. Текст, включаемый в информационную статью, может сопровождаться пояснениями, числовыми и табличными примерами, графиками, документами и видеоизображениями объектов реального мира. Гиперссылка – средство указания смысловой связи фрагмента одного документа с другим документом или его фрагментом. В тексте информационной статьи выделяют ключи или гиперссылки, являющиеся заголовками связанных статей, в которых может быть дано определение, разъяснение или обобщение выделенного понятия. Гиперссылкой может служить слово или предложение. Гиперссылки визуально отличаются от остального текста путем подсветки, выделения, оформления другим шрифтом или цветом и т. д. Они обеспечивают ассоциативную, семантическую, смысловую связь или отношения между информационными статьями. Все гиперссылки можно разделить на две категории: • локальные гиперссылки; • глобальные гиперссылки. Локальные гиперссылки – это ссылки на другие части того самого документа, откуда они осуществляются. Примерами локальных гиперссылок являются: • ссылки из содержания на главы текста; • ссылки из одной главы текста на другую главу; • ссылки от какого-либо термина на его определение, расположенное в словаре терминов данного текста и т. п. Пример локальной гиперссылки приведен на рис. 28.
Рис. 28. Примеры локальных гиперссылок
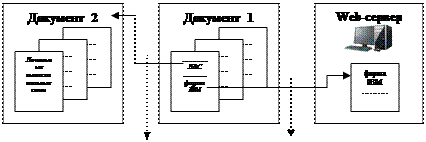
Локальные гиперссылки практически всегда выполнимы, т. е. выполнение данной ссылки приводит к появлению той части документа, куда должен осуществляться переход по ссылке. Глобальные гиперссылки – это ссылки на другие документы, в общем случае на какие-либо ресурсы, расположенные вне данного документа. Примерами глобальных ссылок являются: • ссылки на другой файл, логически не связанный с документом и существующий независимо от него; • ссылки на страницу удаленного Web-сервера. Примеры глобальных гиперссылок приведены на рис. 29.
Глобальные гиперссылки
Рис. 29. Примеры глобальных гиперссылок
Для глобальных гиперссылок возможны случаи, когда требуемый ресурс, на который производится ссылка, по тем или иным причинам отсутствует. Например, файл, на который следует перейти по ссылке, удален или устарела страница Web-сервера. Тезаурус гипертекста– это автоматизированный словарь, отображающий семантические отношения между информационными статьями и предназначенный для поиска слов по их смысловому содержанию. Термин «тезаурус» был введен в XIII в. флорентийцем Брунетто Лотики для названия энциклопедии. С греческого языка этот термин переводится как «сокровище, запас, богатство». Тезаурус гипертекста состоит из тезаурусных статей, каждая из которых имеет заголовок и список заголовков родственных тезаурусных статей. Заголовок тезаурусной статьи совпадает с заголовком информационной статьи и содержит данные о типах отношений с другими информационными статьями. Тип отношений определяет наличие или отсутствие смысловой связи. Существует два типа отношений информационных статей: • референтные отношения; • организационные отношения. Референтные отношения указывают на смысловую, семантическую, ассоциативную связь двух информационных статей. В информационной статье, на которую сделана ссылка, может быть дано определение, разъяснение, понятие, обобщение, детализация понятия, выделенного в качестве гиперссылки. Референтные отношения образуют связь типа: род – вид, вид – род, целое – часть, часть – целое. Пользователь получает более общую информацию по родовому типу связи, а по видовому – более детальную информацию без повторения общих сведений из родовых тем. Примеры референтных отношений информационных статей приведены на рис. 30.
Рис. 30. Примеры референтных отношений информационных статей
К организационным отношениям относятся те, для которых нет ссылок с отношениями род – вид, целое – часть, т. е. между информационными отношениями нет смысловых связей. Они позволяют создать список главных тем, оглавление, меню, алфавитный словарь. Пример организационных отношений приведен на рис. 31.
Рис. 31. Пример организационных отношений информационных статей Список главных тем содержит заголовки информационных статей с организационными отношениями. Обычно он представляет собой меню, содержание книги, отчета или информационного материала. Алфавитный словарь содержит перечень наименований всех информационных статей в алфавитном порядке. Он также реализует организационные отношения. Изучая информацию, представленную в виде гипертекста, пользователь может знакомиться с информационными фрагментами гипертекста впроизвольном порядке. Процесс перемещения пользователя по информационным фрагментам называется навигацией. Навигация – процесс перемещения пользователя по информационным фрагментам гипертекста. Взависимости от признака классификации можно выделить следующие виды навигации, представленные на рис. 32:
Рис. 32. Виды навигации по гипертекстовому документу
По способу изучения материала выделяют: • терминологическую навигацию – последовательное движение пользователя по терминам, вытекающим друг из друга; • тематическую навигацию – получение пользователем всех статей, необходимых для изучения выбранной темы. По способу просмотра информационных статей различают: • последовательную навигацию – просмотр информации в порядке расположения ее в гипертекстовом документе, т. е. в естественном порядке; • иерархическую навигацию – просмотр информационных статей, характеризующих общие понятия по выбранной теме, затем переход к информационным статьям, детализирующим общие понятия и т. д.; • произвольную навигацию – произвольное перемещение по ссылкам гипертекстового документа, порядок которого определяется личным опытом, интересами и настроением пользователя. Переход пользователя от одной информационной статьи к другой может быть постоянным или временным. Постоянный переход Пользователь имеет возможность ознакомиться с новым информационным фрагментом, а затем выбрать следующую информационную статью для перехода без возврата к первоначальному фрагменту Временный переход Пользователь имеет возможность ознакомиться с примечанием, пояснением, толкованием термина, а затем обязательно должен вернуться к первоначальному информационному фрагменту Гипертекстовые технологии реализуют следующие сервисные инструменты пользователя, представленные в табл. 13.
Таблица 13
|
|||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2017-02-22; просмотров: 466; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.224.44.108 (0.109 с.) |