
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Розділ 2. Методи оцінки параметрів розподілівСтр 1 из 14Следующая ⇒
РОЗДІЛ 2. МЕТОДИ ОЦІНКИ ПАРАМЕТРІВ РОЗПОДІЛІВ Предмет і задачі математичної статистики Математична статистика – це математична дисципліна, яка займається розробкою методів і моделей аналізу даних з метою виявлення закономірностей у результаті спостережень над масовими випадковими явищами та процесами. Математична статистика базується на поняттях і методах теорії ймовірностей, але розв’язує свої специфічні задачі. У теорії ймовірностей припускається, що імовірності настання окремих подій відомі. Вважаються відомими закони розподілу випадкових величин або їх числові характеристики. Оперуючи цими поняттями, у теорії ймовірностей знаходять закони розподілу і числові характеристики інших більш складних подій і випадкових величин. Як правило, на практиці ймовірності настання подій, закони розподілу випадкових величин або параметри цих розподілів невідомі. Для їх визначення (оцінювання) проводяться спеціальні спостереження або експерименти. При обробці результатів експериментів статистичними методами основні поняття теорії ймовірностей – імовірності випадкових подій, закони розподілу випадкових величин тощо, виступають як деякі математичні моделі реальних закономірностей. Таким чином, теорія ймовірностей розробляє математичні моделі для описання реальних закономірностей масових випадкових явищ, формує систему поглядів на статистичну обробку та аналіз результатів експериментів. Математична статистика розробляє методи математичної обробки результатів випробувань і визначення ймовірнісних характеристик випадкових явищ на основі експериментальних даних. Сучасну математичну статистику визначають як науку про прийняття рішень в умовах невизначеності. Основні задачі математичної статистики полягають у розробці методів: · планування і організації статистичних спостережень; · збору статистичних даних; · «згортки інформації», тобто групування і скорочення статистичних даних з метою зведення великої кількості даних до невеликого числа параметрів, які у стислому вигляді характеризують усю досліджувану сукупність; · аналізу статистичних даних; · прогнозування випадкових подій і явищ. Методи і засоби наукового аналізу даних, які належать до масових явищ, з метою визначення деяких узагальнюючих ці дані характеристик і виявлення статистичних закономірностей і складають предмет математичної статистики.
До основних задач статистичного аналізу відносяться такі задачі: · визначення розподілів випадкових величин за результатами їх спостережень. До цієї загальної задачі зводиться багато частинних, наприклад, визначення ймовірностей подій, функцій розподілу, параметрів розподілу тощо; · перевірка статистичних гіпотез про вигляд невідомого розподілу або про величини параметрів розподілу, вид якого відомий, перевірка гіпотез про однорідність та незалежність вибірок; · аналіз залежностей між випадковими величинами (кореляційний і регресійний аналіз). Варіаційні ряди та їх характеристики Варіаційні ряди Вихідним матеріалом при розв’язанні задач математичної статистики є послідовність незалежних спостережень випадкових величин. Це означає, що є ймовірнісний експеримент, у якому спостерігається випадкова величина Х і виконується n незалежних реалізацій цього експерименту. Спостережувані значення випадкової величини Задачі математичної статистики виникають, коли закон розподілу ймовірностей випадкової величини X невідомий, при цьому методи статистичного аналізу дозволяють одержати інформацію про різні закономірності у генеральній сукупності. У залежності від того, який клас можливих розподілів генеральної сукупності і що потрібно знати про функцію розподілу, виникають різні статистичні задачі. У практиці статистичних спостережень розрізняють два види спостережень: суцільне, коли вивчаються усі об’єкти (елементи) сукупності, і несуцільне, вибіркове, коли вивчається частина об’єктів. Прикладом суцільного спостереження є перепис населення, який охоплює усе населення країни. Вибірковим спостереженням є, наприклад, вибірковий контроль якості продукції, коли для контролю вибирається частина продукції з усієї продукції, що виготовляється.
Сутність вибіркового методу полягає у тому, що за деякою частиною генеральної сукупності (за вибіркою) судять про її властивості в цілому. Для того, щоб за даними вибірки мати можливість судити про генеральну сукупність, вона повинна бути відібрана випадково. Вибірка називається репрезентативною (представницькою), якщо вона досить добре відтворює генеральну сукупність. Використовують два способи утворення вибірки: ● повторний вибір (за схемою поверненої кулі), коли випадково відібраний і обстежений елемент повертається у загальну сукупність і може бути повторно відібраний; ● безповторний вибір (за схемою неповерненої кулі), коли випадково відібраний елемент не повертається у загальну сукупність. Нехай ØПослідовність Ø Розмахом варіювання або шириною вибірки називається статистика
Ø Рангом елемента Так, ранг 1 одержить найменше із спостережених значень вибірки, ранг 2 – друге за величиною значення і т. д., ранг Оскільки розгляд і осмислення вибіркових даних (особливо при великій кількості спостережень n) ускладнено і за ними практично неможливо уявити характер розподілу випадкової величини X, то вибірки групують. Кількість інтервалів (розрядів) групування вибирають таким чином, щоб згрупований варіаційний ряд не був громіздким, але і не дуже малим, щоб не втратити особливості розподілу ознаки. Якщо коливання щільності розподілу ймовірності не дуже великі, то бажано вибирати однакові розряди. Якщо ж є згущення варіант, то бажано розряди вибирати так, щоб згущення були якомога ближче до середини розрядів. Із границями розрядів повинно як можна менше співпадати значень варіант. У сукупностях з розподілами, близькими до нормального, кількість груп k (нижня оцінка) орієнтовно можна визначити за формулою Стерджеса:
де n – об’єм вибірки. ØЧисла, які дорівнюють кількості варіант із даного розряду, називаються частотами (позначимо їх як
При вивченні варіаційних рядів поряд, з поняттям частота, використовується поняття накопиченої частоти
ØВаріаційний ряд називається дискретним, якщо будь-які його варіанти відрізняються на постійну величину, i – неперервним (інтервальним), якщо варіанти відрізняються на скільки завгодно малу величину.
Дискретний і інтервальний варіаційні ряди представляються у вигляді: а) дискретний варіаційний ряд:
де
б) інтервальний варіаційний ряд:
де Алгоритм групування варіаційного ряду: · визначаємо розмах вибірки R; · задаємо кількість розрядів групування k і визначаємо їх довжину: · визначаємо границі розрядів:
· визначаємо частоти або частки попадання варіант у задані розряди. Функції Mathcad, які застосовуються при групуванні варіаційних рядів: Емпірична функція розподілу Ø Емпіричною функцією розподілу (статистичною функцією розподілу, функцією розподілу вибірки) називається функція
де Іншими словами, для даного Якщо вибірка представлена варіаційним рядом, то
На відміну від емпіричної функції розподілу вибірки Емпірична функція розподілу має усі властивості, що і функція розподілу ймовірностей 1. Значення функції 2. 3. Якщо 4. Якщо Згідно з законом великих чисел, функція
Більш того має місце теорема Глівенка: емпірична функція розподілу
Розглянемо тепер задачу статистичного аналізу щільності розподілу неперервно розподіленої випадкової величини. Така задача в практичних застосуваннях зустрічається частіше, ніж розглянута задача статистичного аналізу функції розподілу.
Нехай Ø Статистика
називається емпіричною щільністю розподілу. Середні величини Кожній числовій характеристиці випадкової величини Середня величина характеризує типовий для сукупності розмір ознаки або, як іноді говорять, центральну тенденцію у розподілі. Очевидно практичне використання такої характеристики доцільне у тому випадку, коли окремі варіанти ряду розподілу концентруються поблизу деякого значення. Якщо ж сукупність дуже неоднорідна, результати спостережень значно відрізняються один від одного і не виявляють загальної тенденції, її використання стає чисто формальним. Існують різні форми середніх. До вибору форми середнього слід підходити керуючись задачею дослідження і визначальною властивістю розподілу, яка повинна бути виражена цією характеристикою. Основним видом середніх є середнє арифметичне. Ø Середнім арифметичним
де
Важливіша властивість середнього арифметичного – сума відхилень варіант від середнього значення дорівнює 0:
При розв’язанні практичних задач можуть застосовуватись і інші форми середнього – середнє геометричне і середнє гармонічне. Ø Емпіричним середнім геометричним
Середнє геометричне знаходить застосування при розрахунках темпів зміни величини, зокрема, у тих випадках, коли мають справу з величиною, зміни якої відбуваються приблизно у прямо пропорційній залежності з досягнутим до цього моменту рівнем самої величини, наприклад, рівнем доходу, або ж коли мають справу із середнім з відношень, наприклад, при розрахунках індексів цін. Ø Емпіричним середнім гармонічним
Гармонічне середнє значення ряду чисел завжди менше середнього геометричного значення тих же чисел, а тим більше – їх середнього арифметичного. Область його застосування досить обмежена. В економіці, зокрема, користуються іноді середнім гармонічним при аналізі середніх норм часу, а також у деяких видах індексних розрахунків. Окрім розглянутих середніх, які називаються аналітичними у статистичному аналізі, застосовують структурні або порядкові середні. Із них найбільш широко застосовуються медіана і мода.
Ø Медіаною Ме варіаційного ряду називається значення ознаки, яке розділяє ранжовану сукупність на дві рівні за чисельністю групи: перша містить варіанти із значеннями меншими Me, друга – зі значеннями варіант більшими Me. Із означення емпіричної функції розподілу (накопиченої частоти) випливає, що:
Для дискретного варіаційного ряду з непарним числом членів медіана дорівнює середньому члену, а для ряду з парним числом членів – півсумі двох середніх членів. Для інтервального варіаційного ряду знаходиться медіанний інтервал
де Зазначимо, що медіана може бути приблизно визначена за допомогою емпіричної функції розподілу Ø Модою Mo варіаційного ряду називається значення варіанти, якій відповідає найбільша частота. У багатьох випадках мода є найбільш характерною для ряду розподілу і навколо неї концентрується більша частина варіант. При зміні крайніх членів ряду мода не змінюється, тобто вона має певну сталість до варіації ознаки. Тому її особливо зручно застосовувати при дослідженні рядів з невизначеними границями. Моду доцільно застосовувати також і в тому випадку, коли при вивченні варіації ознаки важко визначити одну превалюючу над усіма іншими частоту. Для дискретного варіаційного ряду мода знаходиться безпосередньо за означенням. Для інтервального варіаційного ряду визначається модальний інтервал
де Якщо визначений модальний інтервал, то реалізація такої формули не викликає труднощів. Для строго симетричного розподілу, у якого частоти варіант, які рівновіддалені від моди, рівні, значення середньої арифметичної, медіани і моди співпадають, тобто
На гістограмі розподілу мода визначається таким чином. Знаходиться прямокутник з найбільшою частотою (відносною частотою). З’єднуючи відрізками прямих вершини цього прямокутника з відповідними вершинами двох сусідніх прямокутників, одержують точку перетину цих відрізків (діагоналей), абсциса якої і буде модою варіаційного ряду. Показники варіації Середні величини тим більш характерні для даного розподілу, чим тісніше групуються окремі варіанти навколо середньої, тобто чим менше вони розсіяні. Тому середні характеристики повинні бути доповнені вимірюванням варіації ознаки відносно середньої, тобто характеристиками розсіювання. Сама груба оцінка розсіювання, яка оцінюється за даними варіаційного ряду, може бути одержана за допомогою розмаху варіювання:
де Однак цей показник не дає уявлення про характер варіаційного ряду, розташування варіант навколо середньої і може сильно змінюватись від додавання або виключення крайніх варіант навіть із найменшою частотою. Для оцінки варіювання значень ознаки відносно середньої використовуються різні характеристики розсіювання, які відрізняються одна від одної вибраною формою середнього і способами оцінки відхилень від неї окремих варіант. Ø Середнім лінійним відхиленнямd варіаційного ряду називається середнє арифметичне абсолютних відхилень значень варіант від їх середньої арифметичної:
Ø Дисперсією
Дисперсія дає характеристику варіації у квадратних одиницях. Для характеристики варіації у тих же одиницях, що і значення ознаки, на базі дисперсії визначається середнє квадратичне відхилення. Ø Середнім квадратичним відхиленнямs називається корінь квадратний із дисперсії:
Характеристикою варіації є також і коефіцієнт варіації, який дорівнює процентному відношенню середнього квадратичного відхилення до середнього арифметичного:
Коефіцієнт варіації має ту ж природу, що і Якщо коефіцієнт варіації ознаки, яка приймає тільки додатні значення, високий (наприклад більше 100%), то як правило, це свідчить про неоднорідність вибірки. Властивості дисперсії: 1. Дисперсія постійної величини дорівнює 0. 2. Якщо усі варіанти збільшити (зменшити) у одне і теж число разів k, то дисперсія збільшиться (зменшиться) у
3. Якщо усі варіанти збільшити (зменшити) на одне і теж число, то дисперсія не зміниться:
4. Дисперсія дорівнює різниці між середнім арифметичним квадратів варіант і квадратом середнього арифметичного:
Дійсно,
5. Якщо варіаційний ряд складається із декількох груп спостережень, то загальна дисперсія дорівнює сумі середнього арифметичного групових дисперсій та міжгрупової дисперсії (правило складання дисперсій):
де
– середнє арифметичне групових дисперсій, m – кількість груп,
– дисперсія j-ї групи,
– міжгрупова дисперсія. Алгоритм реалізації моделі ● задаємо початкові дані моделі ● утворюємо простий варіаційний ряд ● знаходимо мінімальне ● визначаємо масив границь інтервалів групування варіаційного ряду ● за допомогою функції ● визначаємо числові характеристики варіаційного ряду: середнє значення ● будуємо гістограму частот і графік щільності теоретичного розподілу; ● визначаємо емпіричну функцію розподілу Алгоритм у Mathcad
Початкові дані Моделювання вибірки об’єму
Фрагмент варіаційного ряду
Визначення розмаху вибірки
Задання кількості інтервалів групування і визначення довжини інтервалів групування
Визначення масиву границь інтервалів групування
Визначення масиву частотного розподілу варіаційного ряду
Числові характеристики:середнє арифметичне, дисперсія, середнє квадратичне відхилення емпіричного розподілу
Медіана Модальний інтервал (
Коефіцієнт асиметрії
Ексцес
Щільність нормального розподілу з параметрами
Середини інтервалів Емпірична функція розподілу
Рис.2.1. Гістограма частот і графік щільності нормального розподілу
Рис. 2.2. Графіки емпіричної і теоретичної функцій розподілу F i G і значення функції розподілу у точці Теоретична функція розподілу
Значення теоретичної функції розподілу у точці Ме
Метод моментів Метод моментів ґрунтується на тому, що невідомі параметри теоретичного розподілу (розподілу генеральної сукупності) визначаються із рівнянь, які дістаються прирівнюванням важливіших числових характеристик (моментів) теоретичного розподілу відповідним числовим характеристикам емпіричного розподілу. Так, нехай заданий, наприклад, вид теоретичного розподілу
і функцію вибірки:
Прирівнюючи їх, одержуємо рівняння для визначення оцінки невідомого параметра
Для знаходження оцінок двох невідомих параметрів
Розв’язуючи цю систему, знаходять відповідні оцінки
|
|||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2017-02-10; просмотров: 548; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.142.119.241 (0.147 с.) |
 – називаються випадковою вибіркою або просто вибіркою. Кількість спостережень n – об’ємом вибірки. Множина можливих значень випадкової величини X, які можуть спостерігатися при багатократній реалізації експерименту, називається генеральною сукупністю або вибірковим простором. З точки зору теорії ймовірностей вибірка
– називаються випадковою вибіркою або просто вибіркою. Кількість спостережень n – об’ємом вибірки. Множина можливих значень випадкової величини X, які можуть спостерігатися при багатократній реалізації експерименту, називається генеральною сукупністю або вибірковим простором. З точки зору теорії ймовірностей вибірка 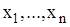 є реалізацією деякої випадкової величини X. Отже, поняття генеральної сукупності, у певному сенсі, аналогічно поняттю випадкової величини, оскільки повністю обумовлено певним комплексом умов.
є реалізацією деякої випадкової величини X. Отже, поняття генеральної сукупності, у певному сенсі, аналогічно поняттю випадкової величини, оскільки повністю обумовлено певним комплексом умов.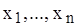 – деяка вибірка (
– деяка вибірка ( -вимірний випадковий вектор). Побудуємо на основі цієї вибірки упорядкований за зростанням випадковий вектор
-вимірний випадковий вектор). Побудуємо на основі цієї вибірки упорядкований за зростанням випадковий вектор  тобто вектор, у якому
тобто вектор, у якому 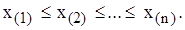
 у якій
у якій 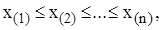 називається варіаційним рядом. Спостережені значення випадкової величини X (ознаки)
називається варіаційним рядом. Спостережені значення випадкової величини X (ознаки)  (2.1)
(2.1)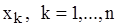 вибірки
вибірки  називається номер, який він одержує в упорядкованій за зростанням послідовності
називається номер, який він одержує в упорядкованій за зростанням послідовності  , тобто у варіаційному ряді.
, тобто у варіаційному ряді.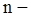 найбільше із чисел
найбільше із чисел  .
.
 , а відношення їх до загальної кількості спостережень n – відносними частотами або частками:
, а відношення їх до загальної кількості спостережень n – відносними частотами або частками: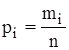 .
. , яка показує кількість варіант із значенням, меншим за x. Відношення накопиченої частоти
, яка показує кількість варіант із значенням, меншим за x. Відношення накопиченої частоти  .
.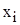
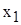
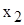
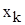
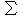

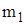



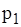

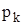

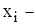 значення випадкової величини X, які спостерігались у експерименті;
значення випадкової величини X, які спостерігались у експерименті; кількість спостережень (частота)
кількість спостережень (частота)  ;
;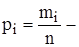 відносна частота
відносна частота 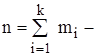 об’єм вибірки.
об’єм вибірки.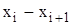

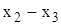
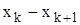
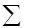

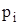
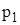
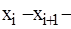 інтервали, на які розбитий діапазон значень випадкової величини X;
інтервали, на які розбитий діапазон значень випадкової величини X;  частота попадань
частота попадань 

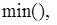

 , яка визначає для кожного значення x відносну частоту події
, яка визначає для кожного значення x відносну частоту події 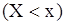 . Отже, за означенням:
. Отже, за означенням: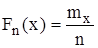 , (2.2)
, (2.2)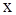 ;
;  величини
величини 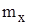 , а отже і
, а отже і 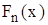 є випадковими.
є випадковими.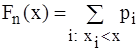 . (2.3)
. (2.3)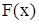 генеральної сукупності називають теоретичною функцією розподілу. Відмінність між ними полягає у тому, що
генеральної сукупності називають теоретичною функцією розподілу. Відмінність між ними полягає у тому, що 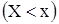 , а
, а 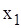 – найменша варіанта, то
– найменша варіанта, то 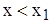 ;
;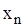 – найбільша варіанта, то
– найбільша варіанта, то  ;
; числа
числа  і
і 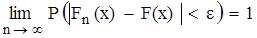 при будь-якому
при будь-якому 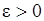 .
. до теоретичного розподілу
до теоретичного розподілу 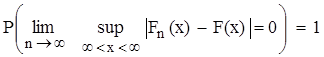 .
.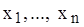 – повторна вибірка, кожний елемент якої має щільність розподілу
– повторна вибірка, кожний елемент якої має щільність розподілу 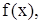
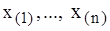 – відповідний варіаційний ряд з розмахом варіювання
– відповідний варіаційний ряд з розмахом варіювання 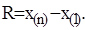 Розіб’ємо інтервал
Розіб’ємо інтервал 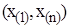 на
на 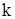 інтервалів
інтервалів 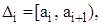
 де
де 

 Нехай
Нехай 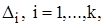
 .
. (2.4)
(2.4) варіаційного ряду називається величина, яка обчислюється на основі вибіркових даних за формулами
варіаційного ряду називається величина, яка обчислюється на основі вибіркових даних за формулами
 – варіанти дискретного варіаційного ряду або середини інтервалів інтервального варіаційного ряду,
– варіанти дискретного варіаційного ряду або середини інтервалів інтервального варіаційного ряду,  – частоти,
– частоти,  .
.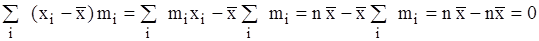 .
. називається величина, яка обчислюється на основі вибіркових даних (для ознак з додатними можливими значеннями) за формулою:
називається величина, яка обчислюється на основі вибіркових даних (для ознак з додатними можливими значеннями) за формулою: (2.6)
(2.6)
 називається величина, яка обчислюється на основі вибіркових даних за формулою:
називається величина, яка обчислюється на основі вибіркових даних за формулою: (2.7)
(2.7) . (2.8)
. (2.8) із умови
із умови  . Значення медіани на цьому інтервалі знаходиться за інтерполяційною формулою:
. Значення медіани на цьому інтервалі знаходиться за інтерполяційною формулою: , (2.9)
, (2.9) – накопичена частота, менша n/2,
– накопичена частота, менша n/2,  – наступна накопичена частота, більша або рівна n/2.
– наступна накопичена частота, більша або рівна n/2.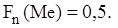 Це зручно зробити графічно.
Це зручно зробити графічно. , якому відповідає найбільша щільність відносної частоти. Величина моди всередині модального інтервалу визначається за інтерполяційною формулою
, якому відповідає найбільша щільність відносної частоти. Величина моди всередині модального інтервалу визначається за інтерполяційною формулою , (2.10)
, (2.10) ,
,  ,
,  – частоти відповідно модального, попереднього до модального і наступного за модальним інтервалів. У цій формулі замість частот можна використовувати частки.
– частоти відповідно модального, попереднього до модального і наступного за модальним інтервалів. У цій формулі замість частот можна використовувати частки. . При порушенні симетрії ці три показника розходяться. Але якщо порушення симетрії не дуже сильно виражене, то між вказаними трьома видами середньої буде виконуватись наближена рівність
. При порушенні симетрії ці три показника розходяться. Але якщо порушення симетрії не дуже сильно виражене, то між вказаними трьома видами середньої буде виконуватись наближена рівність . (2.11)
. (2.11) , (2.12)
, (2.12) ,
,  – найменша і найбільша варіанти ряду.
– найменша і найбільша варіанти ряду.
 варіаційного ряду (вибірковою дисперсією) називається середнє арифметичне квадратів відхилень значень варіант від їх середньої арифметичної:
варіаційного ряду (вибірковою дисперсією) називається середнє арифметичне квадратів відхилень значень варіант від їх середньої арифметичної:
 . (2.15)
. (2.15) . (2.16)
. (2.16)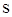 , і виявляється більш зручним для порівняльної оцінки варіації у розподілах з різними значеннями середнього арифметичного. Однак він втрачає смисл при
, і виявляється більш зручним для порівняльної оцінки варіації у розподілах з різними значеннями середнього арифметичного. Однак він втрачає смисл при  і стає малонадійним при близьких до 0 значеннях середнього.
і стає малонадійним при близьких до 0 значеннях середнього. разів:
разів:

 .
.
 ,
, – загальна дисперсія, n – об’єм усієї сукупності,
– загальна дисперсія, n – об’єм усієї сукупності,  – загальне середнє;
– загальне середнє;
 – об’єм j-ї групи;
– об’єм j-ї групи;
 -i-та варіанта у j-й групі,
-i-та варіанта у j-й групі, 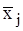 – середнє арифметичне j-ї групи;
– середнє арифметичне j-ї групи;
 і генеруємо вибірку
і генеруємо вибірку 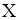 ;
; );
); і максимальне
і максимальне  значення варіаційного ряду, визначаємо розмах вибірки
значення варіаційного ряду, визначаємо розмах вибірки  знаходимо довжину інтервалів групування варіаційного ряду
знаходимо довжину інтервалів групування варіаційного ряду  для заданої кількості інтервалів
для заданої кількості інтервалів  (функції
(функції 
 ;
; знаходимо масив частотного розподілу варіаційного ряду
знаходимо масив частотного розподілу варіаційного ряду  ;
; дисперсію
дисперсію  середнє квадратичне відхилення
середнє квадратичне відхилення  медіану
медіану  , моду
, моду  , коефіцієнт асиметрії
, коефіцієнт асиметрії  ексцес
ексцес  (функції Mathcad
(функції Mathcad 
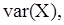
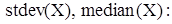
 і будуємо її графік.
і будуємо її графік.



 і одержання варіаційного ряду
і одержання варіаційного ряду























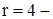 номер модального інтервалу) і мода
номер модального інтервалу) і мода


















 (відмічено знаком +).
(відмічено знаком +). з параметрами
з параметрами 

 ◄
◄ , який визначається невідомим параметром
, який визначається невідомим параметром 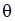 . Для знаходження одного параметра необхідне одне рівняння відносно даного параметра. Для цього використовується момент 1-го порядку (математичне сподівання) теоретичного розподілу і відповідна числова характеристика емпіричного розподілу – вибіркове середнє. Знаходимо математичне сподівання як функцію від
. Для знаходження одного параметра необхідне одне рівняння відносно даного параметра. Для цього використовується момент 1-го порядку (математичне сподівання) теоретичного розподілу і відповідна числова характеристика емпіричного розподілу – вибіркове середнє. Знаходимо математичне сподівання як функцію від 

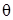 :
: (2.28)
(2.28) ,
,  звичайно беруть математичне сподівання і дисперсію теоретичного розподілу та відповідні їм числові характеристики емпіричного розподілу – вибіркове середнє
звичайно беруть математичне сподівання і дисперсію теоретичного розподілу та відповідні їм числові характеристики емпіричного розподілу – вибіркове середнє  . Одержують два рівняння:
. Одержують два рівняння: (2.29)
(2.29) .
.


