Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Writeln('Переставить диск1 со столбика', Source,Содержание книги
Поиск на нашем сайте
'на столбик', Dest) Else Begin {Переставляем n-1 верхних дисков с исходного столбика на вспомогательный, используя целевой диск как промежуточный } Move_Disks(n-1, Source, Tmp, Dest); WriteLn('Переставить диск', п, 'со столбика', Source, 'на столбик', Dest); {Переставляем n-1 дисков, расположенные на вспомогательном столбике, на целевой, используя исходный диск как промежуточный} Move_Disks(n-1, Tmp, Dest, Source); End End; {Move_Disks} {Основная программа} Begin {Hanoi_Towers} Writeln('Введите число дисков:'); ReadLn(n); Move_Disks(n, 'А', 'С, 'В'); End. {Hanoi_Towers} Нельзя, однако, рекомендовать применять рекурсию повсеместно, и прежде всего это касается традиционных вычислительных процессов, не являющихся существенно рекурсивными. И не столько из-за времени выполнения рекурсивных программ, сколько из-за сложности их отладки. Поэтому программист должен оценить, насколько целесообразно облегчать работу по написанию программы, подвергая себя при этом опасности усложнить отладку и резко увеличить время счета. Программирование с использованием рекурсии Если процедура или функция в ходе выполнения вызывает саму себя, то мы имеем дело с рекурсией. Такой вызов процедур или функций может возникнуть либо вследствие рекурсивного описания, либо вследствие рекурсивного обращения. Рекурсивное описание предполагает, что в исполняемой части блока процедуры или функции присутствует обращение к ней самой. Примером рекурсивного описания может служить функция вычисления факториала: Function Factorial (N: Integer): Integer; Begin if N = 1 Then Factorial:= 1 Else Factorial:= N*Factorial(N -1) End; Здесь Factorial(N) определяется через значение Factorial(N-i), которое определяется через Factorial(N-2), и т.д. до сведения к значению Factorial(O), которое определено явно и равно 1. Любое рекурсивное описание должно содержать явное определение для некоторых значений аргумента (или аргументов), так как иначе процесс сведения оказался бы бесконечным. Таким образом при рекурсивном описании необходимо наличие базовой части описания, которая обеспечивала бы завершение рекурсивных вызовов функции (процедуры). Рекурсивное обращение можно рассмотреть на примере вычисления определенного двойного интеграла по формуле трапеций. Точность этого приближения тем выше, чем больше число участков разбиения n. Увеличивая число n, можно достигнуть заданной точности. Если, допустим, функция TRAP вычисляет интеграл по методу трапеций при заданном числе интервалов N и А, В - пределы интегрирования, a FN - функция вычисления подынтегрального выражения, вычисление двойного интеграла можно осуществить с помощью следующего рекурсивного обращения к функции TRAP:
J:= TRAP (N1, A1, B1, TRAP (N2, A2, B2, FN)); Пример 7.9 Рекурсивная функция, предназначенная для вычисления наибольшего общего делителя двух целых чисел N1 и N2. Function HighFactor(N1,N2:lnteger):lnteger; Var P: Integer; Begin If N1 > N2 Then p:=HighFactor(N1,N2) Else If N2<=0 Then p:= N1 {нерекурсивное решение} Else P:=HighFactor(N2,N1 Mod N2); HighFactor:= P End; Для того чтобы выполнение рекурсивной программы завершалось, необходимо существование в наиболее простых случаях нерекурсивного решения. В противном случае не исключено зацикливание. Некоторые алгоритмы гораздо проще описать, используя рекурсию, нежели итерацию. Это относится в первую очередь к алгоритмам, работающим с разного рода списковыми структурами. Использование рекурсивных процедур и функций делает программу в целом более гибкой и наглядной, но не всегда эффективной, так как работает такая программа, как правило, медленнее и требуют больше памяти. Дело в том, что при каждом вызове рекурсивной процедуры или функции отводится память под локальные переменные. При сравнении итерационных методов решения и методов, использующих рекурсию, часто эффективными оказываются первые. Таким образом, рекурсию следует применять только там, где нет очевидного итерационного решения. Уровень вложенности рекурсий может быть ограничен в конкретных реализациях языка. Различают прямую и косвенную рекурсию. Функция HighFactor является характерным примером прямой рекурсии. Косвенная рекурсия возникает тогда, когда один блок вызывает второй, а второй, в свою очередь, первый. В Турбо Паскале существует правило: перед употреблением любой элемент программы должен быть объявлен. Если строго следовать этому правилу, то реализовать косвенную рекурсию в Турбо Паскале невозможно. Для того чтобы это все же можно было сделать, в язык введены так называемые опережающие объявления (описания). Для задания опережающих объявлений используется директива компилятора Forward, которая позволяет объявить имя подпрограммы, отложив при этом ее окончательное определение, т.е. объявление проводится в два этапа. На первом задаются имя подпрограммы и параметры, за которыми следует атрибут Forward. Позднее появляется полное определение подпрограммы, но в ее заголовок не включается список параметров. Ниже приведен фрагмент программы, являющийся примером задания косвенной рекурсии.
Пример 7.10 Процедура First вызывает процедуру Second, а та, в свою очередь, процедуру First. Procedure First(A, В: Integer); Forward; {Заголовок первой процедуры} Procedure Second(C: Real); {Вторая процедура) Var X, Y: Integer; begin First(X, Y); end; Procedure First; {Снова краткий вызов первой процедуры} Var Z: Real; begin Second(Z); end; Директиву Forward можно использовать не только в рекурсивных подпрограммах, но и для более удобного размещения подпрограмм: сначала описать все заголовки, а затем - сами подпрограммы. Эту директиву не следует использовать в модулях для подпрограмм, объявленных в интерфейсе модуля. Помимо непосредственной, возможна косвенная рекурсия, при которой подпрограмма а вызывает подпрограмму b, а подпрограмма b, в свою очередь, — подпрограмму а. Но как описать две подпрограммы, вызывающие одна другую? Ведь в описании любой из них, которое расположено первым в разделе описаний основной программы, будет вызов подпрограммы, описываемой дальше (т.е. в момент вызова еще неизвестной). Выход из этого затруднения предоставляет так называемое опережающее описание. В Turbo Pascal допускается применение опережающего описания используемой подпрограммы, которое состоит только из ее заголовка, за которым следует директива FORWARD. В этом случае полный текст подпрограммы может быть расположен дальше в любом месте раздела описаний процедур и функций. Как это будет выглядеть на примере подпрограмм а и b, о которых шла речь выше? Схема исходного текста программы, в которой описаны указанные подпрограммы, может выглядеть так. program к; var i:integer; j:real; procedure a (x:integer); forward; {Опережающее описание} procedure b (y:real); Begin a(i) {Вызов еще не определенной процедуры} end; procedure a; Begin b(j) end; Здесь для процедуры а использовано опережающее описание. Затем идет описание процедуры b, из которой вызывается процедура а. Однако благодаря опережающих описанию процедуры а компилятор не зафиксирует это как наличие неизвестно! идентификатора (т.е. ошибку). За описанием процедуры b следует описание процедуры а (без повторения списка формальных параметров, поскольку информация о параметрах уже содержится в опережающем описании процедуры а).
Глава 8 Файлы Данные, обрабатываемые программой, могут находиться не только в оперативной памяти компьютера, но и располагается на устройствах внешней памяти в файлах. Под файлом понимается либо именованная область внешней памяти ПК (жесткий диск, дискета, CD и т.д.), либо логическое устройство – потенциальный источник или приемник информации. Все что является файлом в MS DOS, является физическим файлом в Паскале. Файл – это поименованная область памяти на внешнем носители, предназначенная для хранения информации. Файл с точки зрения языка Паскаль – это структурированный тип данных, состоящий из последовательности компонентов в большинстве случаев одного типа и одной длины. Число компонентов, называемое длиной файла, определением типа файла не фиксируется.
В зависимости от способа объявления в Паскале можно выделить три вида файлов: - типизированные, может состоять из записей любого типа; - текстовые, состоит из строк символов. Конец записи определяется концом строки. Чтение и запись в файл осуществляется посимвольно; - нетипизированные, фактически представляют собойканалыввода/вывода нижнего уровня, используемые в основном для прямого доступа к любому файлу на диске, независимо от его типа и структуры. Существует два способа доступа к компонентам файла; последовательный и произвольный (прямой). При последовательном способе доступа поиск требуемого элемента начинается с начала файла и проверяется по очереди каждый элемент, пока не будет найден нужный. Произвольный способ доступа позволяет обращаться к элементу файла по его порядковому номеру. Для типизированных и нетипизированных файлов можно организовать прямой доступ к любому элементу с помощью стандартной процедуры Seek, которая перемещает текущую позицию файла к заданному элементу. Когда программа завершает обработку файла, его нужно закрыть. Только после этого связанный с ним внешний набор данных будет обновлен. Затем файловая переменная может быть связана с другим набором данных, или обновленный набор данных может быть связан с другой файловой переменной. Основными операциями над файлами являются: 1. Связь файла с набором данных осуществляется с помощью специальной процедуры Assign, которая в общем виде записывается так: Assign(имя_файла, имя_НД); Эта процедура присваивает имя внешнего набора данных имя_НД переменной файлового типа имя_файла. Например. Assign(dan,’Isx.txt’); связь с файлом текущего каталога Assign(datain,’а:\хх.dat’); связь с файлом на диске а: Assign(datain,’LPT1’); связь с принтером Assign(datain,’’); связь со стандартным файлом, как правило, файлом ‘CON’. В операционной системе внешняя аппаратура, такая как клавиатура, принтер, дисплей, рассматриваются как устройства. С точки зрения программиста устройство можно представлять себе как набор данных и с ним можно работать, используя те же процедуры и функции, которые применяются для работы с файлом. 2. Процедура Rewrite (имя_файла) создает и открывает новый файл. Параметр имя_файла является файловой переменной, соответствующей любому типу файла. Процедура Rewrite создает новый набор данных (внешний файл), имя которого присвоено параметру имя_файла процедурой Assign. Если внешний файл с указанным именем уже существует, то он удаляется и на его месте создается новый пустой файл. Текущая позиция в файле устанавливается на начало файла.
Если открывается текстовый файл, то он становится доступным только для записи. 3. Процедура Reset(имя_файла) открывает существующий файл. Параметр имя_файла является файловой переменной, соответствующей любому типу файла. Если файл уже открыт, то он сначала закрывается, а затем открывается вновь. Текущая позиция файла устанавливается на начало файла. Если открывается текстовый файл, то он становится доступным только для чтения. 4 .Чтение из файла осуществляется с помощью известного оператора Read, который в общем виде записывается так: Read(имя_файла, список); или Readln(имя_файла, список); только для текстового файла! Например. Read (dan,str); Readln (datain,a,b,c); 5 .Запись в файл осуществляется с помощью известного оператора Write, который в общем виде записывается так: Write(имя_файла, список); Writeln(имя_файла, список); - только для текстового файла Например. Write (fl,x,y); 6 .Закрытие выполняется процедурой Сlose(имя_файла) для открытого файла. Параметр имя_файла может соответствовать файлу любого типа, который был предварительно открыт с помощью процедур Reset, ReWrite или Append. В момент закрытия осуществляется полное обновление внешнего набора данных, связанного с файловой переменной имя_файла, после чего связь с набором данных разрывается. Потом файл можно открыть снова. Например. Close(fl); 7. Усечение файла выполняется процедурой Truncate(имя_файла). Параметр имя_файла может соответствовать файлу любого типа. Все записи после текущей позиции в файле имя_файла удаляются и текущая позиция становится концом файла (т.е. функция EoF (имя_файла) принимает значение True).
Текстовые файлы Текстовый файл – это файл, состоящий из элементов, являющихся строками. Каждая строка в текстовом файле завершается маркером конца строки. Текстовый файл завершается маркером конца файла. Для описания файловых переменных текстового типа используется стандартный идентификатор Text. Процедуры обработки текстовых файлов Append (f) - открывает существующий файл для добавления информации в конец файла. Указатель текущего компонента файла устанавливается на конец файла. SetTextBuf (f, buf, size) – установка размера буфера. F: text, size: word; buf – тип задается. Должна выполнятся перед открытием файла f. Буфер размещается в переменной buf. Эта процедура служит для увеличения или уменьшения буфера ввода-вывода. Автоматическое значение размера буфера для текстовых файлов равно 128 байт. Flush (f) – освобождение буфера вывода и запись информации в файл. Read (f, ch) – чтение символа из файла и присваивание его значения символьной переменной ch. Readln (f, s) – чтение строки из файла и присваивание ее строковой переменной s. При этом непрочитанная часть строки, включая признак конца строки, пропускается. Write (f, ch) – запись символьной информации ch в файл. Writeln (f, s) – запись строки s в файл и завершение выводимой информации признаком конца строки. Функции обработки текстовых файлов Eoln (f) – конец строки файла. SeekEof (f) – конец файла. SeekEoln (f) – конец строки файла.
Пример 8.1 Ввести в ЭВМ с клавиатуры n строк текста и записать их в текстовый файл. Имя набора данных необходимо также задать с клавиатуры. Program SozdText; Var Tx: Text; {Имя текстового файла} FilName: String;{Имя набора данных} Stroka: String;{Строка текста} i,n: Integer; {Вспомогательные переменные} Begin Writeln(’Введите имя набора данных’); Readln (FilName); Assign(Tx,FilName); Rewrite (Tx); Writeln (’Введите количество строк текста’); Readln(n); Writeln (’Введите строки’); For i:=1 to n do Begin Readln (Stroka); {Ввод строки с клавиатуры} Writeln(Tx,Stroka); {Запись в файл} End; Close(Tx); End. Работа с существующим файлом обычно включает в себя операции открытия его для чтения, и затем считывания из него записей, пока не появится признак "Конец файла" – Eof(Файл). Поэтому соответствующие Паскаль-программы содержат циклы вида While Not Eof (Файл) do Begin Readln(Файл, Запись); - - - - - - - - End; Пример 8.2 Вывода на экран содержимого файла. Рассмотрим ее на примере набора, созданного в предыдущем пункте. Program VivodFile; Var Tx: Text; FilName,Str: String; KolStr: Integer; Begin Writeln(’Введите имя НД ’); Readln(FilName); Assign(Tx,FilName); Reset(Tx,FilName); KolStr:= 0; Writeln(’Содержимое набора’); While Not Eof(Tx) do Begin Readln (Tx,Str); KolStr:= KolStr+1; Writeln(Str); {вывод на экран} End; Writeln(’Количество строк в наборе данных - ’, kolstr); Close(Tx); End.
Типизированные файлы Типизированный или компонентный файл – это файл с объявленным типом его компонентов, т.е. файл с наборами данных одной и той же структуры. Объявление такого файлового типа имеет вид: Var Имя: File Of Тип_Записей; где Тип_Записей – скалярный (число, символ) или сложный (массив, тип Record и др.).
Пример. Type Anketa = Record Fam,Im,Ot: String[10]; Numz: Integer; O: Array[1..5] Of Integer; End; Var FilAnk: file of Anketa; Dan: File Of Real; Fl: File Of Char; Rank: Anketa; X: Real; Процедуры обработки типизированных файлов Read (f,<сп. ввода>) – считывает данные из файла. Здесь <сп. ввода> - список ввода, содержащий одну или более переменных такого же типа, что и компоненты файла. Write (f,<сп. ввода>) – записывает данные в файл. Seek (f,<№ компоненты>) – устанавливает номер текущего компонента файла f. Назначенный компонент будет считан или записан последующей операцией ввода-вывода. Процедура организует прямой доступ в файл. Функции обработки типизированных файлов Eof (f) – возвращает результат типа Boolean: True, если считан последний компонент файла, и False – в противном случае. Файл должен быть открыт. FilePos (f) – возвращает номер текущего компонента. Результат типа Longint. Filesize (f) – возвращает реальное число записей в открытом файле. Результат типа Longint. Пример 8.3 Программа обработки файла, содержащего данные простого типа. При исследовании некоторого технического объекта замерены его параметры Xi и записаны в набор данных StatDan в виде вещественных чисел. Вычислить их среднее значение Mx и стандартное отклонение s по формулам: Program Stat; Var F: File Of Real; X,M,S: Real; N: Integer; Begin Assign(F,’StatDan’);{ Здесь имя набора задано в виде} Reset(F); { строковой константы StatDan} S:= 0; M:= 0; N:= 0; While not Eof(F) do Begin Read(F,X); N:= N+1; M:= M+x; S:= S+Sqr(X); end; M:= M/N; S:= Sqrt(S-Sqr(M))/ N; Writeln(’Количество измерений - ’,N); Writeln(’Среднее: ’,M:8:3,’ Отклонение: ’,S:8:3); End.
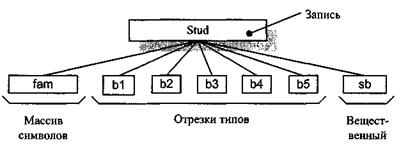
Нетипизированные файлы Нетипизированные файлы манипулируют с данными, не задумываясь об их типе. Нетипизированные файлы - файлы, совместимые с данными любого типа, позволяющие обмениваться информацией блоками; обрабатываются быстрее, чем типизированные. С помощью нетипизированных файлов можно записывать на диск произвольные участки памяти ЭВМ. Объявление такого файлового типа имеет вид: f: File; Принципы работы с нетипизированными файлами такие же, как и с типизированными. Нетипизированные файлы являются файлами прямого■ доступа. Файловая переменная должна быть связана с конкретным физическим файлом оператором Assign. Далее файл должен быть открыт для чтения или записи с помощью процедуры Reset(f) или Rewrite(f). В конце работы файл должен быть закрыт процедурой Close(f). По умолчанию размер буфера передачи данных равен 128 байт. Можно явным способом указать иной размер буфера (чем он больше, тем быстрее происходит ввод-вывод), исходя из ресурсов памяти и удобства работы с данными. Для задания буфера надо после оператора Assign открывать файл расширенной записью процедур: Reset (f, BufSize) и Rewrite (f, BufSize), где f - переменная типа File; BufSize типа Word - задает число байтов, считываемых (или записываемых) из файла за одно обращение к нему. Минимальный блок, который может быть записан или прочитан из файла, - 1 байт. Максимальный размер блока не может превышать 64К. Для обеспечения максимальной скорости обмена данными следует задавать длину, которая была бы кратна длине физического сектора дискового носителя информации. Фактически пространство на диске выделяется любому файлу порциями-кластерами, которые в зависимости от типа диска могут занимать два и более смежных секторов. Как правило, кластер может быть прочитан или записан за один оборот диска, поэтому наивысшую скорость обмена данными можно получить, если указать длину записи, равную длине кластера. При работе с нетипизированными файлами могут применяться все процедуры и функции, доступные типизированным файлам, за исключением Read и Write. Их заменяют процедуры: BlockRead (Var f: file; Var A; n: Word; Var result: Word) и BlockWrite (Var f: file; Var A; n: Word; Var result: Word). Эти процедуры осуществляют чтение в переменную А и запись из переменной А не компонентов файла или его строк, а блоков, состоящих из того количества байтов, которое определено для буфера файла f. Если n больше 1, то за одно обращение будет считано п емкостей буфера. Значение n < 1 не имеет смысла. Всегда должно выполняться условие: n * BtrfSize < 64K. Необязательный параметр result возвращает число буферов, считанное текущей операцией BlockRead. Аналогичный параметр в процедуре BlockWrite после каждой операции записи показывает число буферов, записанное этой операцией. Если операции ввода или чтения прошли успешно, то значения result будут равны соответствующим значениям п. Эти параметры могут использоваться для контроля выполнения BlockRead и BlockWrite. Пример 8.4 Скопировать содержимое файла а1 в файл а2. Использовать нетипизированные файлы. Размер блока нетипизированного файла в операторах Reset и Rewrite зададим равным 1. Количество записей, которые должны быть прочитаны или записаны за одно обращение к диску, в этом случае рассчитывается просто это размер памяти, необходимой для переменной в операторе BlockRead. Если Buf массив из 10000 элементов типа Char, то количество записей, считанных за одно обращение, равно 10000. Окончание считывания определяется по последнему параметру процедуры BlockRead. При последнем вводе количество фактически обработанных записей либо равно 0, либо меньше n.; Program Task8; Const nn = 10000; Var alFile, a2File: String[20]; Buf: Array[1..nn] of Char; {Массив из 10000 символов.} f, f1: File; code: byte; n, n1: Word; Begin Repeat Write ('Введите имя исходного файла'); Readln (a 1 File); Assign (f, alFile); {$1-} Reset (f,1); {$l+} code:= IOResult; If Code <> 0 Then WritelnC Ошибка чтения файла!') Until Code = 0; Write('BBeflHTe имя выходного файла'); Readln(a2File); Assign (f 1, a2File); Rewrite (f1, 1); Repeat BlockRead(f, Buf, Sizeof(Buf), n); BlockWrite(f 1, Buf, n, n1); Until (n = 0) or (noni); Close (f1); Close(f); End. Процедуры обработки нетипизированных файлов Rename (f; NewName) - переименовывает физический файл, ранее связанный с файловой переменной f, в имя NewName; Erase (f) - стирает физический файл, связанный с файловой переменной f, с носителя информации (удаляемый файл должен быть закрыт); GetDir (drive: Byte; Var S: String) - возвращает в строке S текущее имя каталога на диске с индексом drive; ChDir (S: String) - устанавливает текущим каталог с именем, содержащимся в S; MkDir (S: String) - создает каталог с именем S на диске; RmDir (S: String) - удаляет пустой каталог с именем S с диска. Глава 9 Записи Описание записи При использовании массивов основное ограничение заключается в том, что каждый элемент должен иметь один и тот же тип. Однако при решении задач обработки информации возникает необходимость хранить и обрабатывать совокупности данных различных типов, что требует создания отдельных массивов для каждого типа данных, а для установления соответствия между ними - введения соответствующих индексов. Это можно проиллюстрировать на простой задаче по вычислению среднего балла для группы студентов. Пример 9.1 Для каждого студента указаны фамилия и оценки (в баллах), полученные на экзаменах по пяти дисциплинам. Требуется вычислить средний балл для каждого студента и упорядочить список студентов по убыванию среднего балла. Предположим, что в группе 25 студентов. Для хранения одной фамилии студента требуется массив из 15 символов, тогда для хранения всех фамилий необходим двумерный массив размера 15x25. Для хранения информации о баллах, полученных студентами, потребовался бы еще один массив размера 5x25, а для хранения вычисленного среднего балла - третий массив из 25 элементов. Соответствие между фамилиями, полученными баллами и средним определяется индексами соответствующих массивов. Совокупность данных в приведенном примере можно рассматривать как запись (комбинированный тип данных). В общем случае запись представляет собой совокупность ограниченного числа логически связанных компонентов, принадлежащих к разным типам. Например, фамилии студентов представляются данными символьного типа; оценка, полученная на экзамене, интерпретируется как отрезок целочисленного типа (2...5), а средний балл имеет вещественное значение. Определение записи включает указание ее имени, имен отдельных компонентов и соответствующих типов данных: Туре <имя-записи> = record <имя-компонента-1>: <тип>; <имя-компонента-2>: <тип>; <имя-компонента-п>: <тип> end; Данные в примере 9.1 можно описать следующим образом: Туре stud = record fam: string[15]; b1,b2, bЗ, b4, b5:2..5; sb: real; end; Здесь переменная sb имеет смысл среднего балла; b1, b2, bЗ, b4, b5 обозначают баллы по соответствующим дисциплинам; идентификатор fam обозначает строку символов для хранения фамилии студента. Переменная stud в программе на языке Паскаль будет иметь смысл структуры, содержащей информацию об одном студенте. Организация этой записи показана на рис. 9.1.
Рисунок 9.1 - Организация записи Stud Если информацию по всем 25 студентам необходимо хранить в памяти ЭВМ, то вводится массив TBL, представляющий собой массив записей: Var tbl: array [1..25] of stud; Селектор записи Компонент записи определяется (задается) именем записи и именем этого компонента, разделенными точками, например stud.fam, stud.bl, tbl[3].sb. В программах подобные составные имена называются селекторами записи и используются так же, как и переменные других типов. Для нахождения значения среднего балла может быть использован оператор присваивания: tbl[i].sb:= (tbl[i].b1+tbl[i].b2+tbl[i].b3+tbl[i].b4+tbl[i].b5)/5; Возможны и такие операторы присваивания: tbl[3].fam:= 'Иванов'; tbl[20].b2:= 5; tbl[k+1].sb:= 4.666; Имена компонентов внутри записи не должны повторяться. В языке Паскаль нет ни одной операции, которая воспринимала бы запись как нечто целое. Однако значение записи можно пересылать в другие переменные - записи с помощью операторов присваивания. Возвращаясь к рассматриваемому примеру, можно написать: Var z1,z2: stud; Begin z1:= z2; Последний оператор присваивания эквивалентен следующей группе операторов: zi.fam:=z2.fam; zl.bl:=z2.bl; Zl.b2:=z2.b2; Zl.b3:=z2.b3; zl.b4:=z2.b4; zl.b5:=z2.b5; zlsb:=z2.sb; Запись можно передавать в качестве параметра процедуры или функции, но значением функции запись быть не может. Пример 9.1 может быть записана в следующем виде (без упорядочения списка по убыванию среднего балла): {Определение среднего балла} Program Ball; Type Stud = record fam: string[15]; b1,b2, bЗ, b4, b5:2..5; sb: real end; Var tbl:array[1..25]of stud; i: integer; Begin {Ball} WriteLn('Введите массив данных из 25 строк'); for i:= 1 to 25 do ReadLn(tbl[i].fam, tbl[i].b1, tbl[i].b2, tbl[i].b3, tbl[i].b4, tbl[i].b5); for i:= 1 to 25 do Begin tbl[i].sb:= (tbl[i].b1+ tbl[i].b2+tbl[i].b3+tbl[i].b4+tbl[i].b5)/5; WriteLn(tbl[i].sb); end; End. {Ball} Оператор присоединения Использование в программе селекторов записи (составных имен) приводит к ее удлинению и излишней громоздкости. С целью устранения этого неудобства в языке Паскаль используется оператор присоединения (оператор with), который позволяет осуществлять доступ к компонентам записи таким образом, как если бы они были простыми переменными. Общий вид оператора присоединения таков: with <имя записи> do <оператор> В операторе к компонентам записи можно обращаться только с помощью имени компонента. Например, ввод исходных данных для отдельных компонентов записи tbl в предыдущей программе может быть организован следующим образом: for i:= 1 to 25 do with tbl[i] do ReadLn(fam,b1,Ь2,ЬЗ,Ь4,Ь5); Окончательный вариант программы имеет следующий вид: Пример 9.2 Определение среднего балла и сортировка Program Shall; Type stud = record fam: string[15]; b1,b2, bЗ, b4, b5:2..5; sb: real; end; Var tbl:array[1..25]ofstud; у: stud; i, j, k, m: integer; x: real; Begin {Sball} {ввод исходных данных} Writeln('Введите количество записей'); Read(m); {m - число записей в массиве tbl} WriteLn(' Введите компоненты записей'); for i:= 1 to m do with tbl[i] do ReadLn(fam, b1, b2, bЗ, b4, b5); for i:= 1 to m {вычисление среднего балла} with tbl[i] do sb:= (b1+b2+bЗ+b4+b5)/5; for i:= 1 to m-1 do {copтировка списка группы студентов} Begin k:=i; x:= tbl[i]. sb; for i:= i+1 to m do if tbl[i] > x then Begin k:=j; x:= tbl[j]. sb; end; у:= tbl[k]; tbl[k]:= tbl[i]; tbl[i]:= y; end; for i:= 1 to m do {печать результатов} with tbl[i] do WriteLn(fam: 15, sb: 6: 3) End. {Sball} В приведенной программе приняты следующие обозначения: т -число студентов в группе (может быть представлено целым числом от 1 до 25); у - вспомогательная запись, необходимая для промежуточного запоминания элемента массива tbl при перестановке значений его элементов; х, к - вспомогательные переменные для запоминания максимального текущего значения среднего балла и его индекса в массиве записей. Вложенные записи Допускается использование записи в качестве элемента другой записи. В результате получается сложная запись. Пример 9.3 В памяти ЭВМ требуется хранить анкетные данные, представленные в виде следующей таблицы.
Обозначим запись через идентификатор anketa, который определим в разделе описания переменных следующим образом: Var Anketa: record npp: integer; Fio: record fam, im, ot: string[15]; end; Dr: record god: 1900..2100; mes: string[8]; den: 1..31; end; pol: string[3]; end; Элементами записи anketa являются также записи fio и dr. В результате получается сложная запись. Запись anketa содержит анкетные данные одного лица. Если программист намеревается хранить анкетные данные о 100 человеках, то либо запись anketa должна иметь тип массива с числом элементов 100, либо каждый элемент второго уровня (nрр, fiо, dr, pol) должен быть массивом с числом элементов 100. При обращении к компонентам сложных записей можно использовать оператор with, имеющий вложенную структуру с любой степенью вложенности. Например, обращение к полю происходит с помощью составного имени anketa.dr.god, а с использованием оператора присоединения - с помощью конструкции with anketa do with dr do god:= 1965; Или несколько проще: with anketa, dr do god:= 1965; Использование оператора присоединения существенно облегчает написание программ и делает более эффективным многократное обращение к полям одной записи. 9.4 Записи с вариантами Во многих задачах структура записи может меняться в зависимости от некоторых условий, поэтому часто целесообразно при проектировании программ обработки таких данных использовать записи с вариантами. Синтаксис записи с вариантами может быть представлен так: Туре <имя - записи >= record <имя - компонента>: <тип>; <имя - компонента>: <тип>; <имя - компонента>: <тип>; Case <переменная>: <тип> of С1: (<имя - компонента>: <тип>;...); С2: (<имя - компонента>: <тип>;...); СМ: (<имя - компонента>: <тип>;...) end {записи}; Запись с вариантами содержит общую часть и вариантную часть, начинающуюся от зарезервированного слова case. После case стоит конструкция <переменная>: <тип>, которая носит название селектора записи. Последний принимает значения Cl, C2,..., СМ, которые называются константами выбора и определяют, какая составляющая вариантной части будет активизирована при обработке. Констант выбора может быть несколько. Они разделяются запятыми, представляют собой объекты перечислимого типа и играют роль меток, но не являются ими. Обращение к компоненту записи осуществляется по составному имени, как и в случае записи без вариантов. Общая часть может отсутствовать, но обязательно, если она есть, должна предшествовать вариантной части. Имена компонентов в данной записи не должны повторяться. Напомним, что запись можно передавать в качестве параметра процедуре или функции, но значением функции запись быть не может. Записи с вариантами могут быть вложенными. При обработке полей записи с вариантами можно использовать оператор with. Ниже приводится условный пример описания записи с вариантами, содержащей информацию о геометрических объектах: точке, прямой линии и окружности. Эта запись имеет вид: Туре Coordinats = record Absciss, Ordinat: real; end; Form = (Point, Line, Circle); Figure = record Name: string[10]; Case Flag: Form of Point: (Pologenie: Coordinats); Line: (Coefficient, Sdvig: real);
|
||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2017-02-17; просмотров: 267; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.220.60.154 (0.016 с.) |