
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Описательная статистика и статистика вывода
Два самых общих вида статистической обработки данных — это описательная статистика и статистика вывода. Различия между ними соответствуют различию между выборкой и популяцией. Говоря просто, описательная статистика обобщает данные, собранные на выборке участников занятых в вашем исследовании, а статистика вывода позволяет вам делать такие выводы об этих данных, которые могут быть применены к популяции в целом. Описательная статистика По сути, методы описательной статистики позволяют вам свести огромное количество чисел, смысл которых невозможно охватить сразу, к очень небольшому набору, значение которого понять гораздо легче. Описательная статистика включает оценку общей тенденции, изменчивости и взаимосвязей, представленных как численно, так и наглядно (в виде графиков). В этой главе мы рассмотрим основные процедуры оценки общей тенденции и изменчивости. Оценка взаимосвязей (вычисление коэффициентов корреляции) будет описана в главе 9. Для иллюстрации оценки общей тенденции и изменчивости рассмотрим данные гипотетического исследования памяти, в котором 20 человек запоминали, а затем пытались воспроизвести список из 25 слов. Каждое представленное ниже число соответствует количеству слов, запомненных каждым из 20 участников:
Сразу видно, что обобщение результатов этого исследования требует чего-то большего, чем простой демонстрации набора из 20 чисел. Например, можно попытаться вычислить типичную оценку, или так называемую «общую тенденцию». Чаще всего психологи-исследователи определяют общую тенденцию вычисляя среднее арифметическое. Для этого складывают все оценки и делят полученную сумму на общее количество оценок:
где X = среднее арифметическое; XX = сумма отдельных оценок; п = количество оценок в примере. В случае данных, собранных при исследовании памяти, получаем:
Два других способа нахождения общей тенденции — это вычисление медианы и моды. Медиана представляет собой оценку, находящуюся строго в середине набора оценок. Одна половина оценок выше, а другая — ниже значения медианы. Для определения медианы в первую очередь нужно составить последовательность оценок, от наименьших к наибольшим. В случае данных, собранных при исследовании памяти, последовательность будет следующая:
14 15 15 15 16 16 17 17 17 17 17 18 18 18 18 19 19 19 20 21 ft Далее нужно определить местоположение медианы — позицию в последовательности оценок, где проходит медиана (Howell, 1997). Это вычисляется по формуле: и + 1 местоположение медианы = —— ■ Для данных из исследования памяти местоположение медианы следующее: (20+1)/2 = 10,5. Это означает, что она лежит посередине (0,5) между 10-м и 11-м номерами в последовательности. Считая слева направо, видим, что и 10-й, и 11-й номера — это число 17 (я отметил это место в показанной выше последовательности знаком IT). Медиана является точной серединой набора оценок: с каждой стороны от нее лежит по 10 чисел. Иногда медиану используют, если набор оценок содержит одну или две, сильно отличающихся от остальных. В такой ситуации среднее арифметическое дает искаженное представление о типичной оценке. Предположим, к примеру, что пять преподавателей с вашего факультета психологии получили следующие оценки IQ. 93,81,81,95 и 200 (последняя оценка вероятно принадлежит преподавателю методов исследований). Среднее арифметическое оценок IQ, равное НО (вы можете проверить), дает ложное представление о том, что в целом преподаватели психологического факультета имеют умственные способности заметно выше среднего. Медиана в данном случае позволяет лучше оценить типичную /Q-оценку. Местоположение медианы равно (5+1)/2 = 3, а в последовательности оценок третье число равно 93: 81 81 93 95 200 ft Очевидно, что медиана оценок IQ, равная 93, гораздо лучше отражает обычный уровень интеллектуальных способностей на данном гипотетическом факультете психологии. Мода — это значение, чаще всего встречающееся в наборе оценок. В приведенном выше примере значение моды равно 81. Мода гипотетических оценок теста памяти равна медиане: число 17 встречается 5 раз, т. е. чаще всех других чисел. Так как в данных теста памяти отсутствуют необычно высокие или низкие оценки, значения среднего арифметического (17,3), медианы (17) и моды (17) довольно близки друг другу, и каждое из них дает верное представление об общей тенденции.
Очевидно, что оценка общей тенденции требует суммирования данных. Менее очевидна, но не менее важна необходимость анализа изменчивости набора оценок. Предположим, вы — гольфер-профессионал и собираетесь вести занятия в местном клубе для двух групп: в 8:00 и 9:00. Вы измерили их способности, определив среднюю оценку для 9 лунок. Ниже приведены полученные вами данные: Группа, занимающаяся в 8:00: 50 52 58 46 54 Группа, занимающаяся в 9:00: 36 62 50 72 40 Обратите внимание, что среднее арифметическое для каждого набора оценок гольферов равняется 260/5 = 52 ударам. Профессионалу будет о чем поговорить с каждым членом обеих групп. В группе, занимающейся в 8:00, оценки близки друг к другу и все ее участники имеют примерно одинаковый уровень способностей, однако вторая группа не настолько благополучна — оценки в ней варьируются от 36 (довольно хорошо) до 72 (ай-ай-ай!). Понятно, что перед началом занятий гольфер-профессионал предпочел бы знать не только среднюю оценку группы. Самый простой и весьма приблизительный способ оценить изменчивость — это найти разброс — разницу между наибольшей и наименьшей оценками в группе. Диапазон данных для приведенного ранее теста памяти равен 7 (21-14). Разброс оценок 8-часовой группы в примере с занятиями гольфом равен 12 (58 - 46), а разброс оценок 9-часовой — 36 (72 - 36). Разброс дает грубую оценку изменчивости и показывает лишь разницу между крайними значениями. Более сложный способ измерения изменчивости — нахождение стандартного отклонения. Этот способ чаще всего применяется при создании сводного отчета о собранных данных. Стандартное отклонение для выбранного набора оценок — это среднее значение, на которое оценки данного распределения отклоняются от среднего арифметического этих оценок. В табл. 4.4 показаны два способа вычисления стандартного отклонения. Первый способ вытекает непосредственно из определения и позволяет лучше понять сущность стандартного отклонения. Второй — это вычислительная формула, использовать которую удобнее при работе с калькулятором. Для примера с гипотетическим исследованием памяти стандартное отклонение равняется 1,81 словам. Для примера с занятиями гольфом стандартное отклонение для 8- часовой группы равняется 4,47, а для 9-часовой — 15,03 ударам. Таблица 4.4 Вычисление стандартного отклонения Если вы пользуетесь пакетом статистических программ SPSS или SAS, практически любой анализ будет включать нахождение стандартного отклонения. Кроме того, большинство калькуляторов способны к вычислению основных статистических функций, в том числе стандартного отклонения. Поэтому вам, может быть, не придется подсчитывать на бумаге. Однако у вас может оказаться устаревший калькулятор или увлеченный преподаватель, который будет разделять мои представления о том, что подсчет вручную дает более глубокое понимание происходящего. Есть два способа вычислить стандартное отклонение. Первый — использовать так называемую «формулу отклонения». Внимательно изучив ее, вы лучше поймете суть стандартного отклонения, которое по определению является приблизительной характеристикой средней величины отклонения каждой оценки от среднего арифметического. Ниже показано, как найти стандартное отклонение для 20 оценок, полученных при исследовании памяти.
Шаг 2 Вычислите оценки отклонения, каждую возведите в квадрат и найдите их
сумму. Оценки отклонения (х малое) находятся вычитанием среднего арифметического из каждой оценки (X большое). Таким образом, х = X - X. Возведение в квадрат предотвращает появление отрицательных чисел: По формуле отклонения найти стандартное отклонение довольно просто, но для калькулятора она не совсем подходит. Более простой способ — использовать так называемую формулу для вычислений, которая математически равнозначна формуле отклонения. Она имеет следующий вид:
Одной из характеристик изменчивости является дисперсия. Дисперсия представляет собой число, получаемое в ходе вычисления стандартного отклонения, сразу перед нахождением квадратного корня (3,27 для оценок исследования памяти). Это число редко попадает в отчеты, включающие описание данных, так как оно отражает измеряемую величину, возведенную в квадрат (например, «количество запомненных слов в квадрате»). Однако оно находится в центре вероятно самой известной в психологии процедуры статистики вывода — «дисперсионного анализа». О нем рассказывается в главах 7 и 8, а также более подробно в приложении С. Общая тенденция и изменчивость — это универсальные характеристики, используемые при любом описании данных, но исследователи также изучают и весь набор оценок в целом. Простой просмотр данных малоэффективен, но есть и другие способы организации оценок, с помощью которых можно получить значимую картину результатов. Один из способов представления данных — это гистограмма. Гистограмма представляет собой график, показывающий, сколько раз встречается каждая оценка в данном наборе, или, при большом количестве оценок, частоту появления оценок в пределах определенного интервала. Чтобы построить гистограмму, необходимо предварительно построить частотное распределение — таблицу, в которой указывается, сколько раз встречается каждая оценка. Частотное распределение оценок, полученных при исследовании памяти, имеет следующий вид: Оценка Частота Частота, обозначенная звездочками 14 1 15 3 *** 16 2
Построив таблицу частотного распределения, несложно начертить гистограмму. На оси X графика отметьте сами оценки, а на оси У— частоту их появления, а затем постройте соответствующие столбцы графика. Результат должен выглядеть, как показано на рис. 4.6. Обратите внимание, что если взять столбец со звездочками из частотного распределения и повернуть его на 90°, результат будет такой же, как на рис. 4.6.
Также следует отметить, что гистограмма выступает вверх в районе середины и уплощается по краям, что приблизительно соответствует распределению оценок для целой популяции, а не только для 20 человек из описанного выше примера. Распределение оценок для популяции представляет собой известную колокообраз-ную кривую, называемую нормальной кривой, или нормальным распределением. Вы уже встречались с ней; она представлена на рис. 4.7.
Обратите внимание, что на нормальной кривой, показанной на рис. 4.7, я отметил по два стандартных отклонения с обеих сторон от среднего арифметического. Математические характеристики кривой таковы, что около 68% всех оценок для популяции лежат в интервале между двумя первыми стандартными отклонениями, а около 95% — между вторыми. Очевидно, что оценок, попавших за пределы вторых стандартных отклонений, немного — всего 5% от общего количества. Все эти явления можно назвать «статистически значимыми». Запомните данные характеристики распределения, мы к ним очень скоро вернемся. Кроме частотного распределения и гистограммы есть еще один способ отображения набора данных, который позволяет выявить их особенности. Это метод стебля и листа (Turkey, 1977). Чаще всего его используют, когда набор оценок так велик, что частотное распределение или гистограмма были бы очень громоздкими. Например, если вы протестировали 20 испытуемых на застенчивость и полученные ими оценки варьируются от 10 до 70, простое частотное распределение, подобное построенному для данных исследования памяти, будет огромным, а ось X гистограммы будет в милю длиной. Проблему можно решить сгруппировав данные по интервалам (10-19,20-29,30-39 и т. д.). Каждый столбец диаграммы будет отражать количество оценок в пределах определенного интервала. Обратите внимание, что подобная группировка данных приводит к потере некоторой информации. Если шесть человек при тестировании на застенчивость получат оценки между 30 и 39, то все, что вы увидите после такого обобщения, — это один столбец, отображающий частоту, равную шести, и вы не будете знать, какую оценку получил каждый из шести участников. Организовав данные методом стебля и листа, вы сможете получить эту информацию. Метод состоит в следующем. Предположим, что при тестировании на застенчивость 20 человек получены следующие оценки (я выделил жирным шрифтом шесть оценок в пределах от 30 до 39):
В методе стебля и листа с двухзначными числами «листом» будет наименьший разряд (разряд единиц), а «стеблем» — наибольший (разряд десятков). Таким образом, для первого числа (49), стеблем будет число 4, а листом число 9. Для числа 36 стебель равен 3, а лист — 6. Для организации стеблей и листов по одноименному методу сначала требуется расположить числа в порядке возрастания, как вы делали при нахождении медианы (числа от 30 до 39 выделены жирным шрифтом). Получаем: 22 32 33 36 36 37 39 41 41 43 43 43 46 47 49 49 61 64 67 68 Далее поместите стебли в левый столбец таблицы, а листы в соответствующие ряды правого столбца, как показано ниже: СтеблиЛисты 2 2 3 236679 4 113336799 5 6 1478 Повернув таблицу влево на 90° и представив, как заполняются цветом цифры листов, образуя столбцы, вы получите аналог гистограммы для сгруппированных данных. Но обратите внимание, что по сравнению с обычной гистограммой метод стебля и листа обладает заметным преимуществом. На гистограмме, к примеру, в интервале 30-39 будет изображен один столбец, достигающий по шкале У отметки 6. В таблице, построенной методом стебля и листа, вы не только увидите «высоту» оценок в интервале, но также сможете изучать сами оценки. Кроме того, метод стебля и листа позволяет обнаружить оценки, относительно далеко отстоящие от остальных. В приведенном выше примере отсутствие оценок в интервале 50-59 сразу заметно, а четыре оценки в интервале 60-69 выделяются и несколько отстоят от остальных. В статьях, посвященных результатам исследований, полученных с помощью описательной статистики, встречается три способа представления данных. Во-первых, если необходимо представить лишь несколько чисел (например, значения среднего арифметического и стандартного отклонения для двух экспериментальных групп), можно использовать повествовательное изложение результатов. Во-вторых, значения среднего арифметического и стандартного отклонения можно представить в виде таблицы, а в третьих — наглядно в виде графика. Как строить таблицы и графики, соответствующие стандартам АРА, вы узнаете из приложения А, в котором приведен пример отчета об исследовании. Также, некоторую информацию о построении графиков можно найти в главах 7 и 8. Этический аспект статистического анализа и построения графиков освещается во вставке 4.3. ВСТАВКА 4.3
|
|||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2017-02-17; просмотров: 1479; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 13.59.34.87 (0.024 с.) |








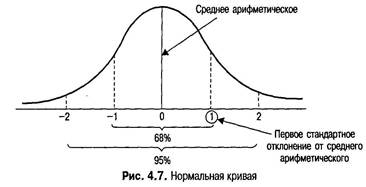
 Так же как кривая, построенная для оценок исследования памяти, нормальная кривая представляет собой частотное распределение. Но в отличие от первой она является нереальным (или «эмпирическим») распределением оценок конкретной выборки, а гипотетическим (или «теоретическим») распределением оценок, которые могут получить члены популяции, если все они примут участие в исследовании. Среднее арифметическое, медиана и мода находятся точно в центре нормального распределения. Важнейшая особенность статистического анализа частотного распределения заключается в том, что если эмпирическое распределение оценок сходно с нормальным распределением, то математические характеристики последнего можно использовать для построения выводов о первом.
Так же как кривая, построенная для оценок исследования памяти, нормальная кривая представляет собой частотное распределение. Но в отличие от первой она является нереальным (или «эмпирическим») распределением оценок конкретной выборки, а гипотетическим (или «теоретическим») распределением оценок, которые могут получить члены популяции, если все они примут участие в исследовании. Среднее арифметическое, медиана и мода находятся точно в центре нормального распределения. Важнейшая особенность статистического анализа частотного распределения заключается в том, что если эмпирическое распределение оценок сходно с нормальным распределением, то математические характеристики последнего можно использовать для построения выводов о первом.


