
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Дослідження основних проблем предметної областіСодержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте ВСТУП Одним з важливих засобів обміну інформацією між людьми і обчислювальними машинами є сигнали і зображення. У зв'язку з цим актуальними є питання реєстрації, зберігання, передачі, автоматичної обробки та розуміння візуальної інформації. Особливий інтерес представляють цифрові сигнали і зображення, отримані з природних безперервних сигналів і зображень [1-5]. Саме по собі поняття зображення являє собою складний об'єкт в силу ряду специфічних інформаційних характеристик: інформаційної ємності, компактності, наочності, внутрішньої структури, що відбиває логічні і фізичні взаємозв'язку навколишнього світу, контекстної інформації, статистичних властивостей і т.д. Така складність об'єкта дослідження зображення призводить до того, що на сьогоднішній день не існує єдиної точки зору на теорію обробки та розуміння зображень. Тому немає остаточного формулювання навіть такого найважливішого і первісного поняття теорії, як алгебра зображень. Зазначені фактори призводять до того, що на сучасному етапі для аналізу зображень застосовується величезна кількість найрізноманітніших за своєю природою підходів, серед яких не останнє місце займають евристичні і слабо перевірені методи [6-7]. У зв'язку з цим становлять інтерес підходи, що базуються на строгих теоретичних положеннях, наприклад, використовують апарат теорії сигналів, але застосовують спрощені моделі зображень об'єктів, що не пов'язані зі значною втратою інформації. Один з таких підходів полягає у відмові від обробки кожної точки зображення і переході до обробки його контурів. Контури є областями з високою концентрацією інформації, слабо залежать від кольору і яскравості. Вони стійкі до зміни типу датчика, що формує зображення, до частотного діапазону, в якому він використовується, не залежать від часу доби і року. Інші характеристики зображення при цьому значно варіюються. Контур цілком визначає форму зображення і містить всю необхідну інформацію для розпізнавання зображень за їх формам. Такий підхід дозволяє не розглядати внутрішні точки плоского зображення і тим самим значно скоротити обсяг оброблюваної інформації за рахунок переходу від аналізу функції двох змінних до функції однієї змінної. Наслідком цього є можливість забезпечення роботи системи обробки в масштабі часу близькому до реального. Але навіть в тих завданнях, де не можна знехтувати обробкою внутрішніх точок, методи контурного аналізу доповнюють інші і тому, безумовно, є корисними. Методи контурного аналізу в більшій мірі, ніж растрові методи, дають можливість використовувати моделі, інваріантні до випадкових переносах, поворотах та змінам масштабів зображень. Контурний аналіз значно розширює кругозір фахівця, дозволяючи з єдиних позицій підходити до обробки як акустичних, радіотехнічних та оптичних сигналів, так і радіолокаційних, телевізійних, оптичних та інших видів зображень. В цьому плані оригінальними є монографії авторського колективу під керівництвом проф. Фурмана Я.А. [14-16], повністю присвячені питанням контурного аналізу і його застосувань до обробки сигналів і зображень. У теорію контурного аналізу і його застосувань до обробки сигналів та зображень помітний вклад внесли роботи авторів: Прюїтта, Щарра, Собеля, Робертса, Кірша, Лапласа, Уолліса, Кенні.
ДОСЛІДЖЕННЯ ОСНОВНИХ ПРОБЛЕМ ПРЕДМЕТНОЇ ОБЛАСТІ Актуальність даної теми. В рамках цієї роботи розробляється метод і алгоритми автоматизованого розпізнавання образів на базі алгоритмів контурного аналізу. Досліджуються у окремому завданні: розпізнавання Герба України. Методи що розробляються носять загальний характер і можуть застосовуватися для розпізнавання широкого кола об'єктів на базі шаблонів - контурів. У методі застосовується еквалізація що дозволяє відкоригувати зображення. Застосовуються фільтри для усунення паразитних шумів. Також в даній роботі використовуються методи Віоли і Джонса, які дозволяють навчити нейронну мережу і отримати на виході каскад Хаара, завдяки якому можна розпізнавати той же об'єкт (Герб України). І це дозволить провести порівняльний аналіз отриманих результатів від розробленого методу і від навченого каскаду, який використовує зовсім інші методи виявлення об'єктів. Після закінчення дослідження, будуть запропоновані рекомендації для використання того чи іншого методу, в таких чи інших завданнях. Так як в Україні поки що не ведуться такого роду розробки, на відміну від західних країн, в яких комп'ютерний зір поступово знаходить своє застосування, і дозволяє зекономити на виробництві значні суми грошей. Даною роботою можуть зацікавитися наші державні військові служби або комерційні підприємства, з метою автоматизації процесів та зниженні витрат на виробництві, шляхом впровадження систем комп'ютерного зору і базуючись на дослідження даної роботи, знизити ризик вибору непідходящого методу детектування об'єктів.
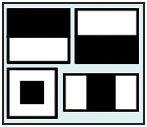
АНАЛІЗ ІСНУЮЧИХ АНАЛОГІВ Метод Віоли-Джонса Метод П.Віоли і М.Джонса, був опублікований в 2001. Цей підхід до детектування об'єктів на зображенні комбінує чотири ключові концепції: - Прості прямокутні функції, які називаються функціями Хаара. - Інтегральне зображення для швидкого виявлення функції. - Метод машинного навчання AdaBoost. - Каскадний класифікатор для ефективного поєднання множинних функцій. Особливості, які використовували Віола і Джонс, базуються на вейвлетах Хаара. Вейвлети Хаара представляють собою прямокутні хвилі однакової довжини (один високий інтервал і один низький інтервал). У двох вимірах, прямокутна хвиля являє собою пару сусідніх прямокутників - один світлий і один темний [23-30].
Рисунок 2.1.1 – Приклад функцій Хаара Фактично прямокутні комбінації, що використовуються для візуального виявлення об'єкта не є справжніми вейвлетами Хаара. Замість цього, вони містять прямокутні комбінації, які краще підходять для візуальних завдань розпізнавання. Через цю різницю, ці функції називаються функціями Хаара (або Хаар-подібними функціями), а не вейвлетами. Рисунок 2.1.1 показує ті функції, що використовуються в OpenCV. Наявність функції Хаара визначається за допомогою вирахування середнього значення області темних пікселів із середнього значення області світлих пікселів. Якщо різниця перевищує поріг (визначається в процесі навчання), тоді кажуть, що функція є існуючою. Щоб ефективно визначити наявність і відсутність сотень функцій Хаара на кожній локації зображенні і в декількох масштабах, Віола і Джонс використовували технологію Інтегрального Зображення. Загалом, «інтеграція» означає складання маленьких блоків разом. В цьому випадку, маленькі блоки є піксельними значеннями. Інтегральне значення для кожного пікселя є сума всіх пікселів над ним і ліворуч від нього. Починаючи з лівого верхнього кута і здійснюючи обхід вправо і вниз, все зображення може бути інтегровано з кількома цілочисельними операціями на піксель.
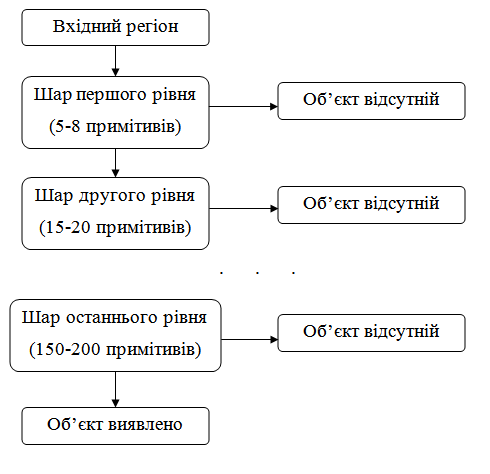
Рисунок 2.1.2 – Трюк Интегрального Изображения. Як показано на Рисунок 2.1.2.a, після інтеграції, значення в кожнго пікселя (х, у) містить суму всіх піксельних значень всередині прямокутної області, яка має один кут у лівій верхній частині зображення і інший в положенні (х, у). Щоб знайти середнє піксельне значення в цьому прямокутнику, необхідно тільки розділити значення в (х, у) на площу прямокутника. Але що якщо цікавлять підсумовані значення для деяких інших прямокутників, які не мають жодного кутка в лівій верхній частині зображення, Рисунок 2.1.2.b ілюструє вирішення цієї проблеми. Припустимо, потрібно дізнатися підсумовані значення в D = (x4, y4) - (x2, y2) - (x3, y3) + (x1, y1) [28-34]. Для вибору конкретних функцій Хаара і встановлення граничних рівнів, Віола і Джонс використовують метод машинного навчання під назвою AdaBoost. AdaBoost комбінує багато «слабких» класифікаторів з метою створення одного «сильного» класифікатора. «Слабкий» тут означає такий класифікатор, який отримує правильну відповідь ненабагато частіше, ніж випадкове вгадування. Це не є добре. Але якщо у вас є безліч таких слабких класифікаторів, і кожен з них «висунув» остаточну відповідь трохи у вірному напрямку, ви можете отримати серйозну, комбіновану силу для досягнення коректного рішення. AdaBoost вибирає набір слабких класифікаторів для об'єднання і привласнює кожному з них свою вагу. Ця зважена комбінація і є сильним класифікатором. Віола і Джонс об'єднали серії класифікаторів AdaBoost як послідовність фільтрів, показаних на Рисунку 2.1.3, що особливо ефективно для класифікації областей зображення. Кожен фільтр є окремим класифікатором AdaBoost з досить невеликим числом слабких класифікаторів [28-34].
Рисунок 2.1.3 – Каскад фільтрів Хаара
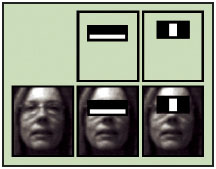
Прийнятий поріг на кожному рівні встановлюється досить низьким, щоб пройти всі (або майже всі) особові зразки в тренувальному наборі. Фільтри на кожному рівні навчені класифікувати тренувальні зображення, які пройшли всі попередні етапи (навчальна вибірка являє собою велику базу осіб, може бути, близько тисячі або близько до цього). Під час роботи, якщо якийсь будь-який з цих фільтрів не пропускає область зображення, то тоді область відразу ж класифікується як «Об’єкт відсутній». Коли фільтр пропускає область зображення, вона переходить до наступного фільтру в послідовності. Область зображення, що пройшли через всі фільтри, класифікуються як «Об’єкт виявлено». Віола і Джонс називали це фільтрацією ланцюга каскаду. Порядок фільтрів в каскаді грунтується на ваговому значенні, які присвоює AdaBoost. Більш важкі зважені фільтри йдуть в першу чергу, з метою якомога більш швидкого усунення областей що не містять цільового об’єкта. Рисунок 2.1.4 показує перші дві функції Хаара, що накладені на обличчя. Перший налаштовує дальню область щік більш «світлою», ніж область очей. Другий використовує факт того, що носова перегородка більше світла, ніж очі.
Рисунок 2.1.4 – Накладання функцій Хаара на зображення Метод SURF SURF вирішує дві задачі - пошук особливих точок зображення і створення їх дескрипторів, інваріантних до масштабу і обертанню. Це означає, що опис ключової точки буде однаково, навіть якщо зразок змінить розмір і буде обернутий. Крім того, сам пошук ключових точок володіє інваріантністю. Так, що повернений об'єкт сцени має той же набір ключових точок, що і зразок. Метод шукає особливі точки за допомогою матриці Гессе. Детермінант матриці Гессе (т.зв. гессіан) досягає екстремуму в точках максимальної зміни градієнта яскравості. Він детектує плями, кути і краї ліній. На рисунку 2.2.1 зображені особливі точки зображення будівлі, знайдені за допомогою матриці Гессе. Діаметр кола показує масштаб особливої точки, а зелена лінія - напрямок градієнта яскравості.
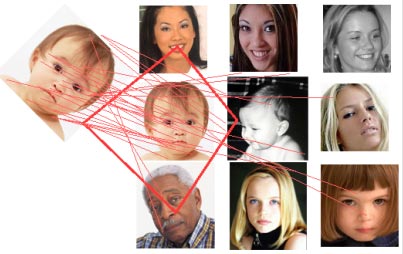
Рисунок 2.2.1 – Особливі точки зображення будівлі Гессіан інваріантний до обертання. Але не інваріантний масштабу. Тому SURF використовує різномасштабні фільтри для знаходження гессіанів. Для кожної ключової точки розраховується напрямок максимальної зміни яскравості (градієнт) і масштаб, взятий з масштабного коефіцієнта матриці Гессе. Градієнт в точці обчислюється за допомогою фільтрів Хаара. Після знаходження ключових точок, SURF формує їх дескриптори. Дескриптор являє собою набір з 64 (або 128) чисел для кожної ключової точки. Ці числа відображають флуктуації градієнта навколо ключової точки. Оскільки ключова точка являє собою максимум гессіан, то це гарантує, що в околиці точки повинні бути ділянки з різними градієнтами. Таким чином, забезпечується дисперсія (відмінність) дескрипторів для різних ключових точок. Флуктуації градієнта околиць ключової точки розраховуються відносно направлення градієнта навколо точки в цілому (по всій околиці ключової точки). Таким чином, досягається інваріантність дескриптора щодо обертання. Розмір області, на якій розраховується дескриптор, визначається масштабом матриці Гессе, що забезпечує інваріантність щодо масштабу. Флуктуації градієнта також розраховується за допомогою фільтра Хаара. На рисунку 2.2.2, зліва знаходиться зразок, справа - сцена. Червоні лінії показують максимально схожі особливі точки зразка і сцени. Червона трапеція - показує виявлений на сцені об'єкт.
Рисунок 2.2.2 – Приклад роботи SURF Метод SIFT Виявлення об'єктів за допомогою методу SIFT полягає в порівнянні зображень по ключових точках. Схема рішення задачі порівняння зображень: - На зображеннях виділяються ключові точки і їх дескриптори. - За збігом дескрипторів виділяються відповідно один одному ключові точки. - На основі набору ключових точок що співпали будується модель перетворення зображень, за допомогою якого з одного зображення можна отримати інше. Основним моментом у детектуванні особливих точок є побудова піраміди гаусіан (Gaussian) і різниць гаусіан (Difference of Gaussian, DoG). Гаусіаном (або зображення розмите гаусовим фільтром) є зображення. Різницею гаусіанів називають зображення, отримане шляхом попіксельного віднімання одного гаусіана вихідного зображення від гаусіани з іншим радіусом розмиття [31]. Інваріантність щодо масштабу досягається за рахунок знаходження ключових точок для вихідного зображення, взятого в різних масштабах. Для цього будується піраміда гаусіанів: весь масштабований простір розбивається на деякі ділянки - октави, причому частина масштабованого простору, займаного наступної октавою, в два рази більше частини, займаної попередньої. До того ж, при переході від однієї октави до іншої робиться ресемплінг зображення, його розміри зменшуються вдвічі. Звісно, що кожна октава охоплює безліч гаусіанів зображення, тому будується тільки деяка їх кількість N, з певним кроком по радіусу розмиття. З тим же кроком добудовуються два додаткові гаусіани (всього виходить N +2), що виходять за межі октави. Масштаб першого зображення наступної октави дорівнює масштабу зображення з попередньої октави з номером N. Паралельно з побудовою піраміди гаусіанів, будується піраміда різниць гаусіанів, що складається з різниць сусідніх зображень в піраміді гаусіанів [31]. Відповідно, кількість зображень в цій піраміді буде N +1. На рисунку 2.3.1 зліва зображена піраміда гаусіанів, а праворуч - їх різниця. Схематично показано, що кожна різниця виходить з двох сусідніх гаусіанів, кількість різниць на одиницю менше кількості гаусіанів, при переході до наступної октаві розмір зображень зменшується вдвічі.
Рисунок 2.3.1 – Піраміда гаусіанів
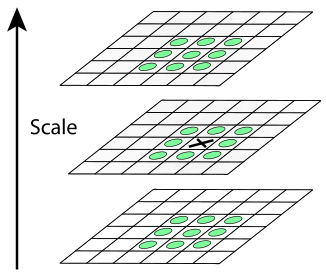
Точка вважається особливою, якщо вона є локальним екстремумів різниці гаусіанів. Для пошуку екстремумів використовується метод, схематично зображений на рисунку 2.3.2.
Рисунок 2.3.2 – Особлива точка
Якщо значення різниці гаусіанів в точці поміченої хрестиком, більше або менше за всіх значень в точках, позначених зеленими кружальцями, то ця точка вважається точкою екстремуму. У методі SIFT дескриптором є вектор. Як і напрямок ключової точки, дескриптор обчислюється на гаусіані, що є найближчою за масштабом до ключової точки, і виходячи з градієнтів в деякому вікні ключової точки. Перед обчисленням дескриптора це вікно повертають на кут напрямку ключової точки, чим і досягається інваріантність щодо поворотів. .
Рисунок 2.3.3 – Дескриптор ключових точок
Отриманий дескриптор нормалізується, після чого всі його компоненти, значення яких більше 0.2, урізуються до значення 0.2 і потім дескриптор нормалізується ще раз. У такому вигляді дескриптори готові до використання. SIFT дескриптори не позбавлені недоліків. Не всі отримані точки і їх дескриптори будуть відповідати вимогам, що пред'являються. Звісно це буде позначатися на подальшому вирішенні задачі порівняння зображень. У деяких випадках рішення може бути не знайдено, навіть якщо воно існує. Наприклад, при пошуку афінних перетворень (або фундаментальної матриці) за двома зображеннями цегляної стіни, рішення може бути не знайдено через те, що стіна складається з повторюваних об'єктів (цеглин), які роблять схожими між собою дескриптори різних ключових точок. Незважаючи на цю обставину, дані дескриптори добре працюють в багатьох практично важливих випадках. Метод ORC Оптичне розпізнавання символів (англ. optical character recognition, OCR) - механічний або електронний переказ зображень рукописного, машинописного або друкованого тексту в послідовність кодів, що використовуються для подання в текстовому редакторі. Розпізнавання широко використовується для конвертації книг і документів в електронний вигляд, для автоматизації систем обліку в бізнесі або для публікації тексту на веб-сторінці. Оптичне розпізнавання тексту дозволяє редагувати текст, здійснювати пошук слова чи фрази, зберігати його в більш компактній формі, демонструвати або роздруковувати матеріал, не втрачаючи якості, аналізувати інформацію, а також застосовувати до тесту електронний переказ, форматування або перетворення в мову. Оптичне розпізнавання тексту є досліджуваною проблемою в областях розпізнавання образів, штучного інтелекту та комп'ютерного зору. Системи оптичного розпізнавання тексту вимагають калібрування для роботи з конкретним шрифтом; в ранніх версіях для програмування було необхідно зображення кожного символу, програма одночасно могла працювати тільки з одним шрифтом. В даний час найбільше поширені так звані «інтелектуальні» системи, з високим ступенем точності розпізнають більшість шрифтів. Деякі системи оптичного розпізнавання тексту здатні відновлювати початкове форматування тексту, включаючи зображення, колонки та інші нетекстові компоненти. Точне розпізнавання латинських символів в друкованому тексті в даний час можливо тільки якщо доступні чіткі зображення, такі як скановані друковані документи. Точність при такій постановці завдання перевищує 99%, абсолютна точність може бути досягнута тільки шляхом наступного редагування людиною. Проблеми розпізнавання рукописного «друкарського» і стандартного рукописного тексту, а також друкованих текстів інших форматів (особливо з дуже великим числом символів) в даний час є предметом активних досліджень. Порівняльна характеристика Таблиця 2.5.1 – Порівняння аналогів
МЕТА КВАЛІФІКАЦІЙНОЇ РОБОТИ Метою магістерської роботи, є дослідження методів контурного аналізу, вивчення проблем та досягнень в цій галузі. Розробка автоматизованої системи розпізнавання об’єктів на базі алгоритмів контурного аналізу, яка дозволить провести аналіз ефективності двох методів розпізнавання об'єктів за допомогою контурного аналізу та каскаду Хаара. Так як на сьогоднішній день, немає універсальних методів, необхідно визначити ефективність та швидкодію роботи методів, виявити переваги і недоліки методів.
ПОСТАНОВКА ЗАДАЧІ Для досягнення мети необхідно: 1. Вивчити предметну область; 2. Провести огляд аналогів; 3. Навчити нейронну мережу, за допомогою утиліт що поставляються бібліотекою OpenCV, та отримати на виході каскад Хаара. 4. Розробити метод автоматизованого розпізнавання об’єктів на базі алгоритмів контурного аналізу. 5. Розробити програмний продукт, в якому використовуються два методи детектування об'єктів за допомогою «Контурного аналізу» та «Каскаду Хаара». 6. Провести аналіз ефективності детектування обох методів. Скласти таблицю ефективності з отриманих результатів. Інформаційна модель системи У загальному вигляді алгоритм виявлення об'єктів за допомогою контурного аналізу, може бути представлений в наступному вигляді:
Рисунок 6.1.1 – Загальна схема алгоритму Контурного Аналізу Вхідний потік може бути узятим з файлу або з веб-камери. Кожен кадр відеопотоку попередньо обробляється – застосовується фільтр Гауса, що сприяє зменшенню рівня шумів або артефактів, на обробку яких були б потрібні додаткові ресурси. Для підкреслення границь застосовується оператор виявлення границь Canny. Оператор є оптимальним за критеріями виділення, локалізації та мінімізації кількох відгуків одного краю. В алгоритмі використовуються два пороги (Рисунок 6.2) за допомогою яких видаляються слабкі границі. Фрагмент кордону при цьому обробляється як ціле. Якщо значення градієнта десь на фрагменті перевищить верхній поріг, то цей фрагмент стає «допустимою» границею і залишається допустимою до тих пір, поки значення градієнта не впаде нижче нижнього порогу.
Рисунок 6.1.2 – Видалення слабких границь Перед застосуванням оператора, зображення зазвичай перетворюють у відтінки сірого, щоб зменшити обчислювальні витрати. Цей етап характерний для багатьох методів обробки зображень. Результати роботи оператора, показано на рисунку 5.5. Для пошуку контурів застосовується функція cvFindContours() з бібліотеки OpenCV. Контур - це список точок, які в тій чи іншій формі представляють криву на зображенні. Це подання може бути різним в залежності від обставин. Є багато способів для представлення кривої. В OpenCV контури представлені послідовністю, в якій кожен запис містить інформацію про знаходження наступної точки на кривій. На рисунку 6.2 зображена функціональність cvFindContours (). У верхній частині малюнка показано тестове зображення, що містить кілька білих регіонів (позначені від A до E) на темному фоні. У нижній частині малюнка знаходиться теж зображення разом з контурами, які позначені cx або hx, де c розшифровується як контур, а h як "дірка" і x деяке число. Деякі з цих контурів намальовані пунктирними лініями, вони представляють зовнішні кордони білих регіонів (тобто ненульових регіонів). OpenCV і cvFindContours() розрізняють ці зовнішні кордони і пунктирні лінії, яких можна уявляти або як внутрішні кордони або як зовнішні кордони дір (тобто нульових регіонів).
Рисунок 6.1.2 – Принцип роботи cvFindContours()
Концепція "вкладеності" тут відіграє важливу роль. З цієї причини можна зібрати знайдені контури в дерево контурів, яке відображає ставлення вкладеності контурів у своїй структурі. Дерево контурів для цього тестового зображення буде мати контур c0 як кореневий вузол, з "дірками" h00 і h01, як своїх нащадків. Вони в свою чергу матимуть нащадків - контурів, і т.д. (Рисунок 6.1.3)
Рисунок 6.1.3 – Дерево контурів
Альтернативне представлення послідовності є код Фрімена (Рисунок 6.1.3). У коді Фрімена полігон представляється як послідовність кроків в одному з 8-ми напрямків, кожен крок позначається числом від 0 до 7.
Рисунок 6.1.3 – Код Фрімена Найбільш поширена задача яка пов'язана з контурами - це порівняння їх між собою якимось чином. В даному випадку необхідно порівняти один обчислений контур і один абстрактний шаблон. Один зі способів порівняти два контури - це обчислити їх моменти. Грубо кажучи момент є грубою характеристикою контуру, що обчислюється за формулою (5.7), шляхом інтегрування (або додавання) всіх пікселів контуру. Вихідним зображенням є зображення з підкресленим контуром, який відповідає шаблону. У випадку з методом розпізнавання об’єктів за допомогою каскаду Хаара, загальний вигляд алгоритму можна представити в такому вигляді:
Рисунок 6.1.4 – Загальна схема розпізнавання за допомогою каскаду Хаара Для того щоб розпізнавати об’єкти за допомогою каскаду Хаара, необхідно спершу навчити систему розпізнавати цей об’єкт. Навчання класифікації об’єкт/фон виконується на основі методу AdaBoost. Для навчання використовується база даних зображень Герба України, що містить 2500 зображень. Кожне зображення розмічається вручну і масштабується до масштабу 20х30 пікселів. У базі даних містяться зображення Гербів України, котрі утворюються при різному куті та інтенсивності освітлення. Для розширення бази даних та обліку зміни напрямку освітлення вона може бути доповнена дзеркальними відображеннями кожного зображення. Таким чином, підсумкова база зображень Гербів України міститиме 5000 зображень розміром 20х30 пікселів. Для формування бази зображень фону беруться зображення різного розміру, які не містять цільовий об’єкт. Кількість фонових зображень повинно нараховуватись приблизно 5000. Алгоритм бустінга для пошуку об’єктів, можна розписати в п’ять кроків: a) Визначення слабких класифікаторів з прямокутними ознаками; b) Для кожного переміщення скануючого вікна обчислюється прямокутна ознака на кожному прикладі; c) Вибирається найбільш відповідний поріг для кожної ознаки; d) Відбираються кращі ознаки і кращий відповідний поріг; e) Перевзвешується вибірка. Каскадна модель сильних класифікаторів - це по суті те ж дерево прийняття рішень, де кожен вузол дерева побудований таким чином, щоб детектувати майже всі цікаві образи і відхиляти регіони, які не є образами. Крім цього, вузли дерева розміщені таким чином, що чим ближче вузол знаходиться до кореня дерева, тим з меншої кількості примітивів він складається і тим самим вимагає меншого часу на прийняття рішення. Даний вид каскадної моделі добре підходить для обробки зображень, на яких загальна кількість детектуємих образів мало. В цьому випадку метод може швидше ухвалити рішення про те, що даний регіон не містить образ, і перейти до наступного. Приклад каскадної моделі сильних класифікаторів:
Рисунок 6.1.5 – Каскадна модель ПОРІВНЯЛЬНИЙ АНАЛІЗ МЕТОДІВ ОХОРОНА ПРАЦІ Тема дипломної роботи «Алгоритми контурного аналізу, в задачах комп’ютерного зору». Кінцевим продуктом даного проекту є створення системи, що дозволяє аналізувати ефективність роботи алгоритмів контурного аналізу в задачах комп’ютерного зору. Тому розділ охорони праці повинен містити вимоги до робочого місця користувача, розрахунки безпеки роботи з ЕОМ. Правила охорони праці під час експлуатації електронно-обчислювальних машин поширюються на усі підприємства, установи, організації, юридичних осіб, незалежно від форми власності, відомчої приналежності, видів діяльності і на фізичних осіб, що здійснюють розробку, виробництво і застосування електронно-обчислювальних машин і персональних комп'ютерів у тому числі і на тих, які мають робочі місця, обладнані ЕОМ, чи виконують обслуговування, ремонт і наладку ЕОМ. Також необхідно дотримуватись загальних вимог, що пред’являються до приміщень в яких будуть експлуатуватися ЕОМ, а саме: Облаштування робочих місць з ВДТ (відео дисплейний термінал) повинне забезпечити: · Належні умови освітлення і відсутність відблисків. · Оптимальні параметри мікроклімату. · Належні ергономічні показники. · Враховувати наявність шуму і вібрації, рентгенівського випромінювання, електромагнітного випромінювання, електростатичного поля, наявність пилу, озону і оксидів азоту. Внутрішні поверхні приміщення повинні виготовлятися з матеріалів дозволених для обробки приміщень. Розміщення робочих місць ВДТ ЭВМ в підвальних і цокольних поверхах забороняється. Приміщення з ВДТ повинні мати природне і штучне освітлення. Природне освітлення повинне здійснюватися через світлові отвори, орієнтовані переважно на північ, північний захід. На робочих місцях з ВДТ КЕО (коефіцієнт природного освітлення) має бути не менше 1.5%. Приміщення з ВДТ мають бути обладнані системами опалювання, вентиляції і кондиціонуванням повітря. Віконні отвори мають бути обладнані регульованими пристосуваннями: це жалюзі, фіранки і зовнішні козирки. Для обробки приміщень забороняється використовувати матеріали, що виділяють в повітря шкідливі речовини (ДСП, шпалери, що миються, паперовий пластик). В цілях створення комфортних умов праці, для кожного працюючого підбирають висоту і кут нахилу клавіатури, екрану і сидіння. Робоче місце зазвичай розташовуються на висоті 74 см від підлоги. Відстань між бічними поверхнями комп'ютерів має бути не менше 1,2 м, відстань від тильної поверхні одного комп'ютера до екрану іншого повинно бути не менше 2,5 м; клавіатура повинна мати матове покриття з коефіцієнтом віддзеркалення 0,4. Встановлюються 15 - хвилинні перерви через кожні 1 - 2 години. Згідно з заданим варіантом розміри приміщення становлять: ширина – а = 10 м; довжина – b = 18 м; h = 3 м, тому площа приміщення становить 180 м2, а обсяг – 540 м3. Отже максимальна кількість робочих місць складає 27, що не суперечить нормам: не менше 6 м2 або 20 м3 на 1 людину. Електробезпечність - це система організаційних і технічних заходів і засобів, що забезпечують захист людей від шкідливого й небезпечного впливу електричного струму, електричної дуги, електромагнітного поля й статичної електрики. Основними заходами захисту від ураження електричним струмом є: забезпечення неприступності струмоведучих частин, що перебувають під напругою, для випадкового дотику; електричний поділ мережі; усунення небезпеки поразки з появою напруги на корпусах, кожухах і інших частинах електроустаткування, що досягається застосуванням малих напруг, використанням подвійної ізоляції, вирівнюванням потенціалу, захисним заземленням, звірофермою, відключенням та ін.; застосування спеціальних електрозахисних засобів - переносних приладів і пристосувань; організація безпечної експлуатації електроустановок. За ступенем небезпеки ураження електричним струмом всі приміщення поділяються на три категорії: · приміщення без підвищеної небезпеки; · приміщення з підвищеною небезпекою; · особливо небезпечні приміщення. Приміщення без підвищеної небезпеки характеризуються відсутністю умов, що створюють особливу або підвищену небезпеку, до цього типу і відноситься наше приміщення. Це – сухе приміщення, без пилу, з нормальною температурою повітря і з ізолюючими (наприклад, дерев'яними) підлогами. Головним заходом запобігання пожеж і вибухів від електрообладнання є правильний вибір і експлуатація обладнання у вибухо-пожежонебезпечних приміщеннях. Одним з засобів захисту від ураження електрострумом є захисне заземлення. Заземленням називається навмисне електричне з'єднання металевих не струмонесучих частин, які можуть виявитися під напругою, із заземлюючим пристроєм. Призначення захисного заземлення — знизити напругу, обумовлена «замиканням на корпус» до безпечного рівня й попередити поразку людини електричним струмом. Захисне заземлення використовують у трифазних три провідних мережах напругою до 1000 В з ізольованою нейтраллю й вище 1000В з будь-яким режимом нейтралі. Захисне заземлення в електричних колах із заземленою нейтраллю не завжди може забезпечити безпеку їх експлуатації, тому що аварійний струм, який перейшов на корпус у випадку пробою ізоляції може не викликати миттєвого спрацьовування плавких запобіжників через опір (хоч і незначного) заземлювача. Таким чином, за деякий час корпус буде перебувати під напругою, достатнім для поразки струмом людини, яка торкнеться доти, поки його не відключать вручну. Тому в таких випадках застосовують інший вид захисту - занулення. Зануленням називають приєднання корпусів і інших металевих частин електроустаткування, що звичайно не перебувають під напругою, до неодноразово заземленого нульового проводу живильної мережі. При введенні в схему нульового проводу збільшується струм, що протікає через захисне обладнання, завдяки чому забезпечується його спрацьовування. Призначення заземлення нейтрали - зниження до безпечного значення напруги щодо землі нульового проводу й усіх приєднаних до нього корпусів при випадковому замиканні фази на землю. Призначення повторного заземлення нульового захисного провідника зменшення небезпеки поразки людини струмом, що виникає при обриві цього провідника й замиканні фази на корпус за місцем обриву. Проведемо розрахунок штучного захисного заземлення згідно заданого завдання. d – діаметр одного заземлювача, d = 0,03м; y - кліматичний коефіцієнт, враховуючий сезонні коливання опору ґрунту, y = 1,1; ρгр = 100 Ом*м – питомий опір ґрунту (вапняк); L – довжина одного заземлювача, L = 2 м; L' – відстань між заземлювачами, L'/L = 3 м; t0 – глибина траншеї, t0 = 0,5 м. Визначаємо розрахункове значення питомого опору ґрунту:
Визначаємо опір одного вертикального заземлювача:
Задаємося довжиною вертикального заземлювача:
Визначаємо кількість вертикальних заземлювачів:
Округляємо отриману кількість заземлювачів до найближчого стандартного значення (2,4,6,10,20,40,60,100): Визначаємо опір системи вертикальних заземлювачів:
де Вибираємо систему розподілу вертикальних заземлювачів в ряд. При розміщенні в ряд довжина полоси дорівнює:
Опір з’єднувальної смуги(шини):
Визначаємо опір системи заземлення:
Висновок: 1,6<4, Rcист<Rтр, тобто ми отримали заземлення, яке задовольняє умовам. Усі підприємства поділяють за вибуховою, вибухопожежною і пожежною небезпекою на категорії: - Категорія А: вибухонебезпечні; - Категорія Б: вибухопожежонебезпечні; - Категорія В: пожежонебезпечні; - Категорія Г: виробництва, що використовують матеріали в гарячому, розпеченому або розплавленому стані. - Категорія Д: виробництва, що використовують негорючі речовини й матеріали в холодному стані. Категорія виробництва по пожежній небезпеці визначає вимоги до конструкцій і плануванню будинку, організації пожежної охорони і її технічної оснащеності, до режиму й експлуатації. Розглянуте в даній роботі приміщення належить до категорії Д. На проектованому підприємстві в якості пожежних звідників застосовуються а
|
|||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2017-02-05; просмотров: 578; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.214 (0.021 с.) |











 ,Ом∙м.
,Ом∙м.  , Ом∙м
, Ом∙м ,Ом
,Ом ,Ом
,Ом , м
, м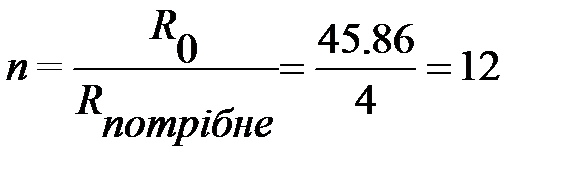 , шт.
, шт. , шт.
, шт. , Ом
, Ом - коефіцієнт використання вертикального заземлювача,
- коефіцієнт використання вертикального заземлювача, 
 ,м
,м
 , Ом
, Ом , Ом
, Ом


