
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Базирование способом суммированияСодержание книги
Поиск на нашем сайте
В команде адресный код АКразделяется на две составляющие: АБ– адрес регистра в регистровой памяти, в котором хранится база Б (базовый адрес); C – код смещения относительно базового адреса (рис. 2.7).
Для определения максимальной емкости ОП, адресуемой с помощью базирования, способом суммирования, определим длину кода исполнительного адреса
Так как nБ = mРП и обычно больше, чем nC, то справедливо следующее выражение: MОП= т. е. максимальная адресуемая емкость ОП определяется разрядностью РП. Длина ³log2MРП. Таким образом, можно определить количество
Приведенные выражения позволяют определить числовые значения параметров относительной адресации (базирование способов суммирования). Для того, чтобы увеличить МОП, необходимо выполнить условие: С помощью метода относительной адресации удается получить так называемый перемещаемый программный модуль, который одинаково выполняется процессором независимо от адресов, в которых он расположен. Начальный адрес программного модуля (база) загружается, при входе в модуль, в базовый регистр. Все остальные адреса программного модуля формируются через смещение относительно начального адреса (базы) модуля. Таким образом, одна и та же программа может работать с данными, расположенными в любой области памяти, без перемещения данных и без изменения текста программы только за счет изменения содержания всего одного базового регистра. Однако время выполнения каждой операции при этом возрастает. Относительная адресация с совмещением составляющих АИ Для увеличения емкости адресной ОП (МОП) без увеличения длины адресного поля команды можно использовать для формирования исполнительного адреса совмещение (конкатенацию) кодов базы и смещения (рис. 2.8). При совмещении кодов базы и смещения
Таким образом, MОП= Следует отметить, что емкость ОП (МОП) может быть увеличена в
Индексная адресация Для работы программ с массивами, требующими однотипных операций над элементами массива, удобно использовать индексную адресацию. Схема индексной адресации аналогична базированию путем суммирования (см. рис. 2.7). В этом случае адрес i-го операнда в массиве определяется как сумма начального адреса массива (задаваемого полем смещения С) и индекса И, записанного в одном из регистров РП, называемом теперь индексным регистром. Адрес индексного регистра задается в команде полем адреса индекса — АИН(аналогично АБ). В каждом i-м цикле содержимое индексного регистра изменяется на величину постоянную (часто равную 1). Использование индексной адресации значительно упрощает программирование циклических алгоритмов. Для эффективной работы при относительной адресации применяется комбинированная индексация с базированием, при которой адрес операнда вычисляется как сумма трех величин (рис. 2.9): АИОП = Б + И + С.
Стековая адресация Стековая память (стек) является эффективным элементом современных ЭВМ, реализует неявное задание адреса операнда. Хотя адрес обращения в стек отсутствует в команде, он формируется схемой управления автоматически по специальному правилу. Твердотéльный накопи́тель (англ. solid-state drive, SSD) — компьютерное немеханическое запоминающее устройство на основе микросхем памяти. Кроме них, SSD содержит управляющий контроллер. Наиболее распространенный вид твердотельных накопителей использует для хранения информации флеш-памяти типа NAND, однако существуют варианты, в которых накопитель создается на базе DRAM-памяти, снабженной дополнительным источником питания — аккумулятором[1]. По сравнению с традиционными жёсткими дисками (HDD), твердотельные накопители имеют меньший размер и вес, но в несколько раз (6—7) большую стоимость за гигабайт и значительно меньшую износостойкость (ресурс записи). Небольшие твердотельные накопители могут встраиваться в один корпус с магнитными жёсткими дисками, образуя гибридные жёсткие диски (англ. SSHD, solid-state hybrid drive)[2][3][4]. Флеш-память в них может использоваться либо в качестве буфера (кэша) небольшого объёма (4—8 ГБ), либо, реже, быть доступной как отдельный накопитель (англ. dual-drive hybrid systems). Подобное объединение позволяет воспользоваться частью преимуществ флеш-памяти (быстрый произвольный доступ) при сохранении небольшой стоимости хранения больших объёмов данных. В начале 2010-х годов на рынке были представлены SSD-накопители с объёмами 64, 80, 120, 256, 512 гигабайт, отдельные модели имеют ёмкость 0,7, 0,8, 1, 1,6 терабайт или более. Основными интерфейсами подключения стали SATA III (до 600 МБ/с Архитектура и функционирование [] NAND SSD Накопители, построенные на использовании энергонезависимой памяти (NAND SSD), появились, во второй половине 90 годов прошлого века,. До середины 2000-х годов уступали традиционным накопителям — жёстким дискам — в скорости записи, но компенсировали это высокой скоростью доступа к произвольным блокам информации С 2012 года уже выпускаются твердотельные накопители со скоростью чтения и записи, во много раз превосходящие возможности жёстких дисков[8]. Характеризуются относительно небольшими размерами и низким энергопотреблением. RAM SSD ] Эти накопители построены на использовании энергозависимой памяти (такой же, какая используется в ОЗУ персонального компьютера) наподобие RAM drive, и характеризуются сверхбыстрыми чтением, записью и поиском информации. Основным их недостатком является чрезвычайно высокая стоимость за единицу объёма. Используются, в основном, для ускорения работы крупных систем управления базами данных и мощных графических станций. Такие накопители, как правило, оснащены аккумуляторами для сохранения данных при потере питания, а более дорогие модели — системами резервного и/или оперативного копирования. Преимущества ]
· Практически полное отсутствие шума; · Высокая механическая стойкость);
Недостатки[ ]
· Низкая реальная помехозащищенность операций чтения из ячеек памяти и наличие сбойных ячеек, особенно при изготовлении по самым современным («тонким») техпроцессам, приводит к необходимости использования в контроллерах современных моделей все более сложных внутренних кодов исправления ошибок
69. Коды коррекции и восстановления информации. Существует три наиболее распространенных орудия борьбы с ошибками в процессе передачи данных: · коды обнаружения ошибок; · коды с коррекцией ошибок, называемые также схемами прямой коррекции ошибок (Forward Error Correction - FEC); · протоколы с автоматическим запросом повторной передачи (Automatic Repeat Request - ARQ). Код обнаружения ошибок позволяет довольно легко установить наличие ошибки. Как правило, подобные коды используются совместно с определенными протоколами канального или транспортного уровней, имеющими схему ARQ. В схеме ARQ приемник попросту отклоняет блок данных, в котором была обнаружена ошибка, после чего передатчик передает этот блок повторно. Коды с прямой коррекцией ошибок позволяют не только обнаружить ошибки, но и исправить их, не прибегая к повторной передаче. Схемы FEC часто используются в беспроводной передаче, где повторная передача крайне неэффективна, а уровень ошибок довольно высок. Методы обнаружения ошибок Методы обнаружения ошибок основаны на передаче в составе блока данных избыточной служебной информации, по которой можно судить с некоторой степенью вероятности о достоверности принятых данных. Избыточную служебную информацию принято называть контрольной суммой, или контрольной последовательностью кадра (Frame Check Sequence, FCS). Контрольная сумма вычисляется как функция от основной информации, причем не обязательно путем суммирования. Принимающая сторона повторно вычисляет контрольную сумму кадра по известному алгоритму и в случае ее совпадения с контрольной суммой, вычисленной передающей стороной, делает вывод о том, что данные были переданы через сеть корректно. Рассмотрим несколько распространенных алгоритмов вычисления контрольной суммы, отличающихся вычислительной сложностью и способностью обнаруживать ошибки в данных. Контроль по паритету представляет собой наиболее простой метод контроля данных. В то же время это наименее мощный алгоритм контроля, так как с его помощью можно обнаружить только одиночные ошибки в проверяемых данных. Метод заключается в суммировании по модулю 2 всех битов контролируемой информации. Нетрудно заметить, что для информации, состоящей из нечетного числа единиц, контрольная сумма всегда равна 1, а при четном числе единиц - 0. Например, для данных 100101011 результатом контрольного суммирования будет значение 1. Результат суммирования также представляет собой один дополнительный бит данных, который пересылается вместе с контролируемой информацией. При искажении в процессе пересылки любого бита исходных данных (или контрольного разряда) результат суммирования будет отличаться от принятого контрольного разряда, что говорит об ошибке. Однако двойная ошибка, например 110101010, будет неверно принята за корректные данные. Поэтому контроль по паритету применяется к небольшим порциям данных, как правило, к каждому байту, что дает коэффициент избыточности для этого метода 1/8. Метод редко применяется в компьютерных сетях из-за значительной избыточности и невысоких диагностических способностей. Вертикальный и горизонтальный контроль по паритету представляет собой модификацию описанного выше метода. Его отличие состоит в том, что исходные данные рассматриваются в виде матрицы, строки которой составляют байты данных. Контрольный разряд подсчитывается отдельно для каждой строки и для каждого столбца матрицы. Этот метод обнаруживает значительную часть двойных ошибок, однако обладает еще большей избыточностью. Он сейчас также почти не применяется при передаче информации по сети. Циклический избыточный контроль (Cyclic Redundancy Check - CRC) является в настоящее время наиболее популярным методом контроля в вычислительных сетях (и не только в сетях; в частности, этот метод широко применяется при записи данных на гибкие и жесткие диски). Метод основан на рассмотрении исходных данных в виде одного многоразрядного двоичного числа. Например, кадр стандарта Ethernet, состоящий из 1024 байт, будет рассматриваться как одно число, состоящее из 8192 бит. Контрольной информацией считается остаток от деления этого числа на известный делитель R. Обычно в качестве делителя выбирается семнадцати- или тридцатитрехразрядное число, чтобы остаток от деления имел длину 16 разрядов (2 байт) или 32 разряда (4 байт). При получении кадра данных снова вычисляется остаток от деления на тот же делитель R, но при этом к данным кадра добавляется и содержащаяся в нем контрольная сумма. Если остаток от деления на R равен нулю, то делается вывод об отсутствии ошибок в полученном кадре, в противном случае кадр считается искаженным. Этот метод обладает более высокой вычислительной сложностью, но его диагностические возможности гораздо шире, чем у методов контроля по паритету. Метод CRC обнаруживает все одиночные ошибки, двойные ошибки и ошибки в нечетном числе битов. Метод также обладает невысокой степенью избыточности. Например, для кадра Ethernet размером 1024 байта контрольная информация длиной 4 байта составляет только 0,4 %. Методы коррекции ошибок Техника кодирования, которая позволяет приемнику не только понять, что присланные данные содержат ошибки, но и исправить их, называется прямой коррекцией ошибок (Forward Error Correction - FEC). Коды, обеспечивающие прямую коррекцию ошибок, требуют введения большей избыточности в передаваемые данные, чем коды, которые только обнаруживают ошибки. При применении любого избыточного кода не все комбинации кодов являются разрешенными. Например, контроль по паритету делает разрешенными только половину кодов. Если мы контролируем три информационных бита, то разрешенными 4-битными кодами с дополнением до нечетного количества единиц будут: 000 1, 001 0, 010 0, 011 1, 100 0, 101 1, 110 1, 111 0, то есть всего 8 кодов из 16 возможных. Для того чтобы оценить количество дополнительных битов, необходимых для исправления ошибок, нужно знать так называемое расстояние Хемминга между разрешенными комбинациями кода. Расстоянием Хемминга называется минимальное число битовых разрядов, в которых отличается любая пара разрешенных кодов. Для схем контроля по паритету расстояние Хемминга равно 2. Можно доказать, что если мы сконструировали избыточный код с расстоянием Хемминга, равным n, такой код будет в состоянии распознавать (n-1) -кратные ошибки и исправлять (n-1)/2 -кратные ошибки. Так как коды с контролем по паритету имеют расстояние Хемминга, равное 2, они могут только обнаруживать однократные ошибки и не могут исправлять ошибки. Коды Хемминга эффективно обнаруживают и исправляют изолированные ошибки, то есть отдельные искаженные биты, которые разделены большим количеством корректных битов. Однако при появлении длинной последовательности искаженных битов (пульсации ошибок) коды Хемминга не работают. Наиболее часто в современных системах связи применяется тип кодирования, реализуемый сверхточным кодирующим устройством (Сonvolutional coder), потому что такое кодирование несложно реализовать аппаратно с использованием линий задержки (delay) и сумматоров. В отличие от рассмотренного выше кода, который относится к блочным кодам без памяти, сверточный код относится к кодам с конечной памятью (Finite memory code); это означает, что выходная последовательность кодера является функцией не только текущего входного сигнала, но также нескольких из числа последних предшествующих битов. Длина кодового ограничения (Constraint length of a code) показывает, как много выходных элементов выходит из системы в пересчете на один входной. Коды часто характеризуются их эффективной степенью (или коэффициентом) кодирования (Code rate). Вам может встретиться сверточный код с коэффициентом кодирования 1/2. Этот коэффициент указывает, что на каждый входной бит приходится два выходных. При сравнении кодов обращайте внимание на то, что, хотя коды с более высокой эффективной степенью кодирования позволяют передавать данные с более высокой скоростью, они, соответственно, более чувствительны к шуму. В беспроводных системах с блочными кодами широко используется метод чередования блоков. Преимущество чередования состоит в том, что приемник распределяет пакет ошибок, исказивший некоторую последовательность битов, по большому числу блоков, благодаря чему становится возможным исправление ошибок. Чередование выполняется с помощью чтения и записи данных в различном порядке. Если во время передачи пакет помех воздействует на некоторую последовательность битов, то все эти биты оказываются разнесенными по различным блокам. Следовательно, от любой контрольной последовательности требуется возможность исправить лишь небольшую часть от общего количества инвертированных битов.
|
||||
|
|
Последнее изменение этой страницы: 2017-02-05; просмотров: 275; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 52.15.191.241 (0.011 с.) |


 max{ nБ; nC}.
max{ nБ; nC}.
 =
=  ,
,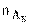 поля кода команды, задающего адрес регистра базы АБ, определяется через емкость РП MРПпо формуле
поля кода команды, задающего адрес регистра базы АБ, определяется через емкость РП MРПпо формуле двоичных разрядов в адресном поле команды, необходимое для формирования АИс размещением базы в РП:
двоичных разрядов в адресном поле команды, необходимое для формирования АИс размещением базы в РП: log2МРП+ nС.
log2МРП+ nС. ³, т.е mРП³log2MРП+ nС.
³, т.е mРП³log2MРП+ nС. .
. =
= 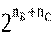 .
. раз за счет использования способа совмещения. Однако в данном случае начальные адреса массивов не могут быть реализованы произвольно, а должны иметь в младших разрядах nCнулей.
раз за счет использования способа совмещения. Однако в данном случае начальные адреса массивов не могут быть реализованы произвольно, а должны иметь в младших разрядах nCнулей.




