
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
По необходимости поддержания постоянного соединенияСодержание книги
Поиск на нашем сайте
· Пакетная сеть, например, Фидонет и UUCP · Онлайновая сеть, например, Интернет и GSM 56. Архитектура ВС. Архитектура ВС — совокупность характеристик и параметров, определяющих функционально-логическую и структурную организацию системы. Понятие архитектуры охватывает общие принципы построения и функционирования, наиболее существенные для пользователей, которых больше интересуют возможности систем, а не детали их технического исполнения. Поскольку ВС появились как параллельные системы, то и рассмотрим классификацию архитектур под этой точкой зрения. Эта классификация архитектур была предложена М. Флинном (М. Flynn) в начале 60-х гг. В ее основу заложено два возможных вида параллелизма: независимость потоков заданий (команд), существующих в системе, и независимость (несвязанность) данных, обрабатываемых в каждом потоке. Классификация до настоящего времени еще не потеряла своего значения. Однако подчеркнем, что, как и любая классификация, она носит временный и условный характер. Своим долголетием она обязана тому, что оказалась справедливой для ВС, в которых ЭВМ и процессоры реализуют программные последовательные методы вычислений. С появлением систем, ориентированных на потоки данных и использование ассоциативной обработки, данная классификация может быть некорректной. Согласно этой классификации существует четыре основных архитектуры ВС, представленных на рис. 11.3: • одиночный поток команд — одиночный поток данных (ОКОД), в английском варианте — SingleInstructionSingleData(SISD) — одиночный поток инструкций — одиночный поток данных; • одиночный поток команд — множественный поток данных (ОКМД), или SingleInstructionMultipleData(SIMD) — одиночный поток инструкций — одиночный поток данных; • множественный поток команд — одиночный поток данных (МКОД), или MultipleInstructionSingleData(MISD) — множественный поток инструкций — одиночный поток данных; • множественный поток команд — множественный поток данных (МКМД), или MultipleInstructionMultipleData(MIMD) — множественный поток инструкций — множественный поток данных (MIMD). Коротко рассмотрим отличительные особенности каждой из архитектур. Архитектура ОКОД охватывает все однопроцессорные и одномашинные варианты систем, т.е. с одним вычислителем. Все ЭВМ классической структуры попадают в этот класс. Здесь параллелизм вычислений обеспечивается путем совмещения выполнения операций отдельными блоками АЛУ, а также параллельной работы устройств ввода-вывода информации и процессора. Закономерности организации вычислительного процесса в этих структурах достаточно хорошо изучены. Архитектура ОКМД предполагает создание структур векторной или матричной обработки. Системы этого типа обычно строятся как однородные, т.е. процессорные, элементы, входящие в систему, идентичны, и все они управляются одной и той же последовательностью команд. Однако каждый процессор обрабатывает свой поток данных. Под эту схему хорошо подходят задачи обработки матриц или векторов (массивов), задачи решения систем линейных и нелинейных, алгебраических и дифференциальных уравнений, задачи теории поля и др. В структурах данной архитектуры желательно обеспечивать соединения между процессорами, соответствующие реализуемым математическим зависимостям. Как правило, эти связи напоминают матрицу, в которой каждый процессорный элемент связан с соседними. По этой схеме строились системы: первая суперЭВМ — ILLIAC-IV, отечественные параллельные системы — ПС-2000, ПС-3000. Идея векторной обработки широко использовалась в таких известных суперЭВМ, какCyber-205 иGray-I,II,III. Узким местом подобных систем является необходимость изменения коммутации между процессорами, когда связь между ними отличается от матричной. Кроме того, задачи, допускающие широкий матричный параллелизм, составляют достаточно узкий класс задач. Структуры ВС этого типа, по существу, являются структурами специализированных суперЭВМ. Третий тип архитектуры МКОД предполагает построение своеобразного процессорного конвейера, в котором результаты обработки передаются от одного процессора к другому по цепочке. Выгоды такого вида обработки понятны. Прототипом таких вычислений может служить схема любого производственного конвейера. В современных ЭВМ по этому принципу реализована схема совмещения операций, в которой параллельно работают различные функциональные блоки, и каждый из них делает свою часть в общем цикле обработки команды. В ВС этого типа конвейер должны образовывать группы процессоров. Однако при переходе на системный уровень очень трудно выявить подобный регулярный характер в универсальных вычислениях. Кроме того, на практике нельзя обеспечить и «большую длину» такого конвейера, при которой достигается наивысший эффект. Вместе с тем конвейерная схема нашла применение в так называемых скалярных процессорах суперЭВМ, в которых они применяются как специальные процессоры для поддержки векторной обработки. Архитектура МКМД предполагает, что все процессоры системы работают по своим программам с собственным потоком команд. В простейшем случае они могут быть автономны и независимы. Такая схема использования ВС часто применяется на многих крупных вычислительных центрах для увеличения пропускной способности центра. Больший интерес представляет возможность согласованной работы ЭВМ (процессоров), когда каждый элемент делает часть общей задачи. Общая теоретическая база такого вида работ практически отсутствует. Но можно привести примеры большой эффективности этой модели вычислений. Подобные системы могут быть многомашинными и многопроцессорными. Например, отечественный проект машины динамической архитектуры (МДА) — ЕС-2704, ЕС-2127 — позволял одновременно использовать сотни процессоров.
57. Типовые структуры ВС. Универсальной структуры вычислительной системы, одинаково хорошо обрабатывающей задачи любого типа, не существует. Интересные результаты исследований по этим вопросам даны в работах [14, 19, 20]. В них приведены сопоставления различных видов программного параллелизма и соответствующих им структур вычислительных систем. Классификация уровней программного параллелизма включает шесть позиций: независимые задания, отдельные части заданий, программы и подпрограммы, циклы и итерации, операторы и команды, фазы отдельных команд. Для каждой из них имеются специфические свойства параллельной обработки, апробированные в различных структурах вычислительных систем. Заметим, что данный перечень совершенно не затрагивает этапы выбора алгоритмов решения, на которых могут анализироваться альтернативные алгоритмы (а значит, и программы), дающие различные результаты. Для каждого вида параллельных работ имеются структуры вычислительных средств, используемые в различных вычислительных системах. Верхние три уровня, включающие независимые задания, шаги или части заданий и отдельные программы, имеют единое средство параллельной обработки — мультипроцессирование, т.е. многопроцессорные вычислительные системы, относящиеся к архитектуре МКМД. Программные циклы и итерации требуют использования векторной обработки (архитектура ОКМД). Операторы и команды, выполняемые ЭВМ, ориентированы на многофункциональную обработку. Параллельная обработка фаз последовательно выполняемых команд приводит к организации конвейера команд. Рассмотрим возможные структуры вычислительных систем, которые обеспечивают перечисленные виды программного параллелизма. ОКОД-структуры. Два нижних вида параллелизма реализуются в любых современных ЭВМ, включая и персональные ЭВМ. Данный тип архитектуры объединяет любые системы в однопроцессорном (одномашинном) варианте. За 50 лет развития электронной вычислительной техники классическая структура ЭВМ претерпела значительные усовершенствования, однако основной принцип программного управления не был нарушен. Данная структура оказалась сосредоточенной вокруг оперативной памяти, так как именно цепь «процессор — оперативная память» во многом определяет эффективную работу компьютера. При выполнении каждой команды необходимо неоднократное обращение к оперативной памяти: выбор команды, операндов, отсылка результатов и т.д. Можно перечислить большое число приведенных улучшений классической структуры ЭВМ, ставших в настоящее время определенными стандартами при построении новых ЭВМ: иерархическое построение памяти ЭВМ, появление сверхоперативной памяти и кэш-памяти, относительная и косвенная адресация памяти, разделение процессоров ввода-вывода и обработки задач, появление систем прерывания и приоритетов и т.д. В этом ряду следует рассматривать и организацию конвейера последовательно выполняемых команд: формирование адреса команды, выбор команды, формирование адресов и выбор операндов, выполнение команды, запись результата. Однако примитивная организация памяти (память линейна и одномерна) не позволяет организовать длинный и эффективный конвейер. Линейные участки современных программ редко превышают десяток, полтора последовательно выполняемых команд. Поэтому конвейер часто перезапускается, что снижает производительность ЭВМ в целом. Многофункциональная обработка также нашла свое место при построении ЭВМ. Например, даже в персональных ЭВМ, построенных на микропроцессорах i486 и Pentium, в состав ЭВМ могут включаться и другие специализированные средства обработки: умножители, делители, сопроцессоры или блоки десятичной арифметики, сопроцессоры обработки графической информации и др. Все они совместно с центральным процессором ЭВМ позволяют создавать своеобразные микроконвейеры, целью которых является повышение скорости вычислений. В последние годы широко используются еще несколько модификаций классической структуры. В связи с успехами микроэлектроники появилась возможность построения RISC-компьютеров (ReducedInstructionSetComputing), т.е. ЭВМ с сокращенным набором команд. Большие ЭВМ предыдущих поколений не имели большой сверхоперативной памяти, поэтому они имели достаточно сложную систему CISC-команд (CompleteInstructionSetComputing— вычисления с полной системой команд). В этих машинах большую долю команд составляли команды типа «Память-память», в которых операнды и результаты операций находились в оперативной памяти. Время обращения к памяти и время вычислений соотносились примерно, как 5:1. ВRISC-машинах с большой сверхоперативной памятью большой удельный вес составляют операции «регистр-регистр» и отношение времени обращения к памяти и времени вычислений составляет 2:1 [27]. Поэтому в RISC-ЭВМ основу системы команд составляют наиболее употребительные, «короткие» операции типа алгебраического сложения. Сложные операции выполняются как подпрограммы, состоящие из простых операций. Это позволяет значительно упростить внутреннюю структуру процессора, уменьшить фазы дробления конвейерной обработки и увеличить частоту работы конвейера. Но здесь необходимо отметить, что за эффект приходится расплачиваться усложнением процедур обмена данными между регистрами сверхоперативной памяти и кэш-памяти с оперативной памятью. Другой модификацией классической структуры ЭВМ является VLIW(VeryLargeInstuctionWord) — ЭВМ с «очень длинным командным словом». ЭВМ этого типа выбирает из памяти суперкоманду, включающую несколько команд. Здесь возможны варианты. В самом простом случае это приводит к появлению буфера команд (кэш-команд) с целью ускорения конвейера операций. В более сложных случаях в состав суперкоманд стараются включать параллельные команды, не связанные общими данными. Если процессор ЭВМ при этом построен из функционально независимых устройств (устройства алгебраического сложения, умножения, сопроцессоры), то в этом случае обеспечивается максимальный эффект работы ЭВМ. Но это направление связано с кардинальной перестройкой процессов трансляции и исполнения программ. Здесь значительно усложняются средства автоматизации программирования. VLIW-компьютеры могут выполнять суперскалярную обработку, т.е. одновременно выполнять две или более команды. В целом ряде структур суперЭВМ использовалась эта идея. Отметим, что и в ПЭВМ последних выпусков имеется возможность выполнения двух команд одновременно. Эта реализация имеет две цели: • уменьшение отрицательного влияния команд ветвления вычислительного процесса путем выполнения независимых команд двух различных ветвей программы. При этом в какой-то степени исключаются срывы конвейера в обработке команд программы; • одновременное выполнение двух команд (независимых по данным и регистрам их хранения), например команды пересылки и арифметические операции. ОКМД-структуры. Для реализации программного параллелизма, включающего циклы и итерации, используются матричные или векторные структуры. В них эффективно решаются задачи матричного исчисления, задачи решения систем алгебраических и дифференциальных уравнений, задачи теории поля, геодезические задачи, задачи аэродинамики. Теоретические проработки подобных структур относятся к концу 50-х — 60-м гг. Данные структуры очень хорошо зарекомендовали себя при решении перечисленных задач, но они получились очень дорогими по стоимости и эксплуатации. Кроме того, в тех случаях, когда структура параллелизма отличалась от матричной, возникает необходимость передачи данных между процессорами через коммутаторы. При этом эффективность вычислений резко снижается. Подобные структуры могут использоваться как сопроцессоры в системах будущих поколений. МКОД-структуры большой практической реализации не получили. Задачи, в которых несколько процессоров могли бы эффективно обрабатывать один поток данных, в науке и технике неизвестны. С некоторой натяжкой к этому классу можно отнести фрагменты многофункциональной обработки, например обработку на разных процессорах команд с фиксированной и плавающей точкой. Так же как фрагмент такой структуры, можно рассматривать локальную сеть персональных компьютеров, работающих с единой базой данных, но скорее всего это — частный случай использования МКМД-структуры. МКМД-структуры являются наиболее интересным классом структур вычислительных систем. После разочарований в структурах суперЭВМ, основанных на различном сочетании векторной и конвейерной обработки, усилия теоретиков и практиков сосредоточены в этом направлении. Уже из названия МКМД-структур видно, что в данных системах можно найти все перечисленные виды параллелизма. Этот класс дает большое разнообразие структур, сильно отличающихся друг от друга своими характеристиками (рис. 11.5). Важную роль здесь играют способы взаимодействия ЭВМ или процессоров в системе. В сильносвязанных системах достигается высокая оперативность взаимодействия процессоров посредством общей оперативной памяти. При этом пользователь имеет дело с многопроцессорными вычислительными системами. Наиболее простыми по строению и организации функционирования являются одно-родные, симметричные структуры. Они обеспечивают простоту подключения процессоров и не требуют очень сложных централизованных операционных систем, размещаемых на одном из процессоров. Рис. 11.5. Типовые структуры ВС в МКМД (МIMD)-классе Однако при построении таких систем возникает много проблем с использованием общей оперативной памяти. Число комплексируемых процессоров не должно превышать 16. Для уменьшения числа обращений к памяти и конфликтных ситуаций может использоваться многоблочное построение ОП, функциональное закрепление отдельных блоков за процессорами, снабжение комплексируемых процессоров собственной памятью типа кэш. Но все эти методы не решают проблемы повышения производительности ВС в целом. Аппаратные затраты при этом существенно возрастают, а производительность систем увеличивается незначительно. Появление мощных микропроцессоров типа Pentiumпривело к экспериментам по созданию многопроцессорных систем на их основе. Так, для включения мощных серверов в локальные сети персональных компьютеров была предложена несколько измененная структура использования ООП — мультипроцессирование с разделением памяти (SharedMemorymultiprocessing,SMP). На общей шине оперативной памяти можно комплексировать до четырех микропроцессоров. Слабосвязанные МКМД-системы могут строиться как многомашинные комплексы или использовать в качестве средств передачи информации общее поле внешней памяти на дисковых накопителях большой емкости. Невысокая оперативность взаимодействия заранее предопределяет ситуации, в которых число межпроцессорных конфликтов при обращении к общим данным и друг к другу было бы минимальным. Для этого необходимо, чтобы ЭВМ комплекса обменивались друг с другом с небольшой частотой, обеспечивая автономность процессов (программы и данные к ним) и параллелизм их выполнения. Только в этом случае обеспечивается надлежащий эффект. Эти проблемы решаются в сетях ЭВМ. Успехи микроинтегральной технологии и появление БИС и СБИС позволяют расширить границы и этого направления. Возможно построение систем с десятками, сотнями и даже тысячами процессорных элементов, с размещением их в непосредственной близости друг от друга. Если каждый процессор системы имеет собственную память, то он также будет сохранять известную автономию в вычислениях. Считается, что именно такие системы займут доминирующее положение в мире компьютеров в ближайшие десять — пятнадцать лет. Подобные ВС получили название систем с массовым параллелизмом (Mass-ParallelProcessing,MPP). Все процессорные элементы в таких системах должны быть связаны единой коммутационной средой. Нетрудно видеть, что здесь возникают проблемы, аналогичные ОКМД-системам, но на новой технологической основе. Передача данных в МРР-системах предполагает обмен не отдельными данными под централизованным управлением, а подготовленными процессами (программами вместе с данными). Этот принцип построения вычислений уже не соответствует принципам программного управления классической ЭВМ. Передача данных процесса по его готовности больше соответствует принципам построения «потоковых машин» (машин, управляемых потоками данных). Подобный подход позволяет строить системы с громадной производительностью и реализовывать проекты с любыми видами параллелизма, например перейти к «систолическим вычислениям» с произвольным параллелизмом. Однако для этого необходимо решить целый ряд проблем, связанных с описанием и программированием коммутаций процессов и управления ими. Математическая база этой науки в настоящее время практически отсутствует.
58. Комплексирование в ВС. См вопр 14 59. Системы счисления. Информационно-логические основы ЭВМ. Система счисления(далее СС) - совокупность приемов и правил для записи чисел цифровыми знаками. возможность представления любого числа в рассматриваемом диапазоне величин; единственность представления (каждой комбинации символов должна соответствовать одна и только одна величина); простоту оперирования числами; В зависимости от способов изображения чисел цифрами, системы счисления делятся на непозиционные и позиционные. Непозиционной системой называется такая, в которой количественное значение каждой цифры не зависит от занимаемой ей позиции в изображении числа (римская система счисления). Позиционной системой счисления называется такая, в которой количественное значение каждой цифры зависит от её позиции в числе (арабская система счисления). Количество знаков или символов, используемых для изображения числа, называется основанием системы счисления. Позиционные системы счисления имеют ряд преимуществ перед непозиционными: удобство выполнения арифметических и логических операций, а также представление больших чисел, поэтому в цифровой технике применяются позиционные системы счисления.
По этому принципу построены непозиционные СС. В общем же случае системы счисления: A(B)=a1B1+a2B2 +...+anBn. Если положить, что Bi=q*Bi-1, а B1=1, то получим позиционную СС. При q=10 мы имеем дело с привычной нам десятичной СС. Каждая СС имеет свои правила арифметики (таблица умножения, сложения). Поэтому, производя какие-либо операции над числами, надо помнить о СС, в которой они представлены. Если основание системы q превышает 10, то цифры, начиная с 10, при записи обозначают прописными буквами латинского: A,B,...,Z. При этом цифре 10 соответствуею знак 'A', цифре 11 - знак 'B' и т.д. В таблице ниже приводятся десятичные числа от 0 до 15 и их эквивалент в различных СС: В позиционной СС число можно представить через его цифры с помощью следующего многочлена относительно q: A=a1*q0+a2*q1+...+an*qn (1) Выражение (1) формулирует правило для вычисления числа по его цифрам в q-ичной СС. Для уменьшения количества вычислений пользуются т.н. схемой Горнера. Она получается поочередным выносом q за скобки: A=(...((an*q+an-1)*q+an-2)*q+...)*q+a1 результат вычисления многочлена будет всегда получен в той системе счисления, в которой будут представлены цифры и основание и по правилам которой будут выполнены операции.
Результатом является целое число. 1. Из десятичной системы счисления - в двоичную и шестнадцатеричную: исходное целое число делится на основание системы счисления, в которую переводится (2 или 16); получается частное и остаток; если полученное частное не делится на основание системы счисления так, чтобы образовалась целая часть, отличная от нуля, процесс умножения прекращается, переходят к шагу в). Иначе над частным выполняют действия, описанные в шаге а); все полученные остатки и последнее частное преобразуются в соответствии с таблицей в цифры той системы счисления, в которую выполняется перевод; формируется результирующее число: его старший разряд - полученное последнее частное, каждый последующий младший разряд образуется из полученных остатков от деления, начиная с последнего и кончая первым. Таким образом, младший разряд полученного числа - первый остаток от деления, а старший - последнее частное. 2. Из двоичной и шестнадцатеричной систем счисления - в десятичную. В этом случае рассчитывается полное значение числа по формуле. 3. Из двоичной системы счисления в шестнадцатеричную: исходное число разбивается на тетрады (т.е. 4 цифры), начиная с младших разрядов. Если количество цифр исходного двоичного числа не кратно 4, оно дополняется слева незначащими нулями до достижения кратности 4; каждая тетрада заменятся соответствующей шестнадцатеричной цифрой в соответствии с таблицей 4. Из шестнадцатеричной системы счисления в двоичную: каждая цифра исходного числа заменяется тетрадой двоичных цифр в соответствии с таблицей. Если в таблице двоичное число имеет менее 4 цифр, оно дополняется слева незначащими нулями до тетрады; незначащие нули в результирующем числе отбрасываются.
60. Современные чипсеты. Охладители. Модинг.
|
||||
|
|
Последнее изменение этой страницы: 2017-02-05; просмотров: 257; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.225.56.181 (0.028 с.) |

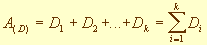 ,
, 


