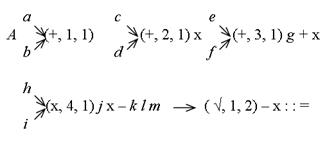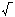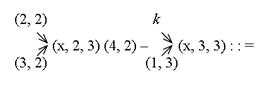Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Организация потоковой обработки информацииСодержание книги Похожие статьи вашей тематики
Поиск на нашем сайте
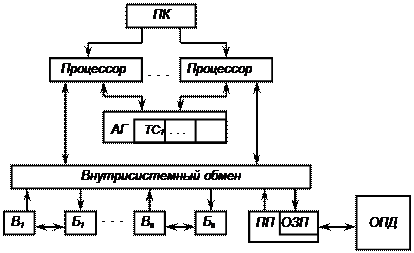
Одним из практических способов организации управления совместной работой исполнительных устройств при выполнении одной программы в ВС является управление потоком данных или организация потоковой обработки информации. При этом способе поступление необходимых данных непосредственно в текст команды – единственное условие, определяющее возможность ее выполнения одним из исполнительных устройств системы. Таким образом, достигается предельно простая синхронизация взаимосвязанных работ и параллельное выполнение независимых работ, определенных программой. В идеальном случае параллельное выполнение алгоритма в ВС обусловлено его информационно-логическим графом. В различных вариантах построения ВС, управляемой потоком данных, по одной команде может выполняться как элементарная операция, так и некоторая программно реализованная процедура. Известны два способа реализации метода управления потоком данных. Первый способ предполагает размещение всей программы или ее частей в активной памяти, состоящей из ячеек команд. В каждую ячейку предусмотрена запись кода операции (идентификатора процедуры), всех необходимых операндов и адреса ячейки, в которую надлежит отправить результат. Готовые к выполнению команды, т. е. те, в тексте которых имеются все операнды, выбираются исполнительными устройствами – вычислителями решающего поля для выполнения. Предполагается возможность одновременной выборки вычислителями достаточно большого числа готовых к выполнению команд. После выборки команды вычислителем операнды в ее тексте уничтожаются, что обеспечивает повторное выполнение команды в цикле. Результаты направляются по указанным в командах адресам в качестве операндов для последующего выполнения других команд. Данный способ требует разработки специальной многовходовой активной памяти большого объема, развитой переключающей сети, нуждается в решении ряда вопросов хранения и подкачки исходной информации, организации процесса в случае, когда память команд не вмещает программу полностью, и т. д. Второй способ предполагает динамическую коммутацию исполнительных устройств при одновременном выполнении ими предписанных операций таким образом, чтобы результаты выполнения одних команд служили аргументами для выполнения других команд, назначенных к выполнению на том же или другом исполнительном устройстве. Данный способ требует разработки специальных коммутирующих устройств, распределяющих команды между ограниченным числом исполнительных устройств и устанавливающих связи между ними. Способ получил распространение при построении модульных арифметическо-логических устройств. При выборе модели потоковой обработки информации необходимо учитывать невозможность полного отказа от последовательной обработки программного кода: ввода, трансляции и перемещения программы, подкачки информации, динамической коммутации устройств, выбора исполнительных устройств на основе текущего использования ресурсов, учета последовательности событий, возникающих при выполнении программы, и т.д. Важно также сохранить для универсальной потоковой системы традиционную форму программ, отражающую отработанные способы параллельно-последовательного представления алгоритмов. Для иллюстрации решения проблем, связанных с организацией потоковой обработки информации, выберем модель асинхронной модульной ВС, в которой применение указанных способов управления потоком данных сочетается с последовательной обработкой команд программы коммутации ВС состоит (рис. 4.1) из m процессоров коммутации (которые будем называть просто процессорами), памяти команд (ПК), адресного генератора (АГ) с таблицами соответствия TC j, j=1,..., m, исполнительных устройств решающего поля, буферов исполнительных устройств, оперативной памяти данных (ОПД). В состав исполнительных устройств входят вычислители Вi (с буферами Б i,), i=l,..., n, и процессор памяти (ПП), осуществляющий обмен информацией с ОПД и связанный со своим буфером – очередью заявок к памяти (ОЗП). Вычислители могут быть построены на основе микро- и миниЭВМ, что способствует унификации устройств, реализации большого набора операций с учетом модификации и расширяемости, возможности переменной комплектации, повышению надежности. Рассмотрим кратко принципы работы такой ВС. Каждый процессор выполняет свою программу коммутации (так как такая программа является единственным представителем вычислительного процесса в ВС, будем называть ее просто программой), соответствующую задаче, программному модулю, процессу и так далее на основе реализации первого уровня распараллеливания.
Р и с. 4.1. Схема ВС, управляемой потоком данных
Программа, записанная в ПК, имеет традиционный вид, но может содержать математические адреса вычислителей, интерпретируемые как адреса особой области памяти, не допускающей повторного использования данных. Процессоры и решающее поле работают независимо друг от друга, за исключением выполнения условных переходов, определяемых результатами счета. Процессоры производят модификацию команд и полностью выполняют команды индексации, цикла, переходов, организации векторных операций. Как средство частичного выполнения команд они выступают как исполнительные устройства, в связи с чем, наряду со специальным, предусматривается их стандартное подключение к решающему полю. С помощью базирования программ и данных реализуется стековый принцип обработки. При обработке основной группы команд из системы команд ВС процессор по дисциплине, реализуемой адресным генератором, занимает или использует ячейки команд буферов исполнительных устройств, организованных по первому способу управления потоком данных. Он записывает в эти ячейки коды операций и физические адреса ячеек команд буферов, в которые необходимо передать результаты. Подобные же команды формируются в ОЗП. Команда на считывание располагает адресом ячейки команды в некотором буфере, куда должна направляться информация. При формировании команды записи ее адрес как адрес результата сообщается той команде, по которой он вырабатывается. Таким образом, процессор выполняет функции динамической коммутации исполнительных устройств для реализации второго уровня распараллеливания. Предусмотрены команды вычисления условных выражений, исключающие необходимость условных переходов при счете значений арифметических операторов. Это минимизирует задержки коммутации для определения направлений ветвления. Асинхронно работающие исполнительные устройства (вычислители и ПП) выполняют команды из своих буферов, располагающие всеми операндами. Результаты направляются по указанным адресам, что реализует второй способ управления потоком данных. При выполнении процессором памяти заявок соблюдается не только алгоритмический порядок преобразования данных по одним и тем же адресам, но и очередность бесконфликтного обращения к модулям памяти. При этом поддерживается соответствие между потоками поступающих и обслуженных заявок, обусловленными тем, что каждая команда исходной программы может порождать несколько заявок к памяти данных, выдаваемых за один машинный такт. Таким образом, в выбранной модели потоковая обработка информации основана на динамическом преобразовании схемы обработки информации в схему коммутации исполнительных устройств решающего поля. Программа коммутации представляет в ВС вычислительный процесс и является объектом программирования или трансляции. Ее выполнение и работа исполнительных устройств происходят асинхронно, т. е. процесс коммутации отделен от процесса выполнения исполнительными устройствами предписанных им операций. Простыми средствами достигается виртуализация вычислительного ресурса. По мере того как частичная коммутация позволяет начать выполнение операций, исполнительные устройства выполняют предписанные им операции асинхронно после поступления на их вход необходимых операндов. Они передают результаты на входы других (или, в частности, этого же) исполнительных устройств в соответствии с необходимостью дальнейшей обработки информации, определенной данным алгоритмом и учтенной на этапе коммутации связей. При этом становится принципиально возможным абсолютное распараллеливание участков выполняемого алгоритма, так как каждое исполнительное устройство получает возможность выполнения операции сразу же, как только будут получены от других исполнительных устройств необходимые операнды. От скорости процесса коммутации зависит возможность распараллеливания вычислений на уровне исполнительных устройств. Вместе с тем очевидно, что практически разница скоростей коммутации и выполнения не может быть столь значительной, что возможна и целесообразна коммутация связей исполнительных устройств для выполнения всего алгоритма сразу. Да и ограниченный вычислительный ресурс этого не позволит. Поэтому по программе коммутации происходит постепенное «развертывание» графа, отражающего вычислительный процесс. Рассмотрим выражение
и соответствующую ему бесскобочную запись
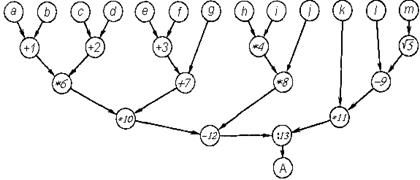
Информационный граф G, соответствующий счету значения выражения (4.2), приведен на рис. 4.2. Его вершины, обозначенные символом операции, соответствуют элементарным операциям, к которым отнесем и счет значения квадратного корня. В соответствии с индивидуальным заданием необходимо построить информационный граф. В качестве примера рассмотрим выражение (4.1), где a = 6, b = 8, c = 26, d = 7, e = 32, f = 90, g = 5, h =283, i = 1, j = 22, k = 298, l = 52, m = 64, тогда информационный граф G будет иметь вид (рис 4.3). Рядом с вершинами графа указаны промежуточные значения вычислений.
Р и с. 4.2. Информационный граф G
Предположим, что без учета ПП ВС обладает однородным решающим полем, т. е. все вычислители ВС способны выполнять все операции.
Рис. 4.3
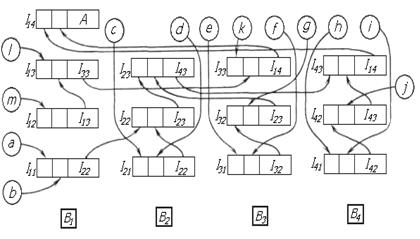
Пусть при неограниченном вычислительном ресурсе каждая вершина графа G закреплена за некоторым вычислителем (на рисунке указаны номера вычислителей). Выходы каждого вычислителя в соответствии с дугами в графе G соединены с входами других вычислителей.Величины, входящие в выражение, считываются из ОПД по их именам или адресам на входы вычислителей, которые первыми начинают их обработку. Пусть в процессе или после установления такой коммутации все вычислители получают возможность однократного выполнения операции тотчас же по появлении необходимых операндов на входе. Очевидно, в процессе счета значения данного выражения полностью будет использован принцип распараллеливания, и счет будет выполнен за минимальное время. При этом минимизации времени счета послужит и отсутствие задержки времени между получением промежуточных результатов и их дальнейшим использованием. Оно обеспечивается непосредственной передачей результатов на вычислители для дальнейшей обработки. Пусть n – количество вычислителей в системе. Тогда неизбежно многократное использование одного вычислителя при счете значения сложного выражения. Если не организовать очередь на входе каждого вычислителя и не задать информацию, какому вычислителю и в какую очередь направлять результат после каждого выполнения операции, то коммутация вычислителей в соответствии с графом G станет невозможной. Пусть каждый вычислитель В i обладает буфером Б i, i=l,..., n, состоящим из S адресуемых регистров для хранения назначаемых на вычислитель команд. Адреса регистров будем отождествлять с номерами очереди использования данного вычислителя. Каждый регистр буфера вмещает полное количество операндов, которые с учетом некоммутативных операций (например, деления) располагаются в определенном порядке. В каждом регистре указывается также адрес результата, включающий номер вычислителя-преемника, номер очереди (адрес регистра в буфере), а также номер позиции этого результата в регистре в соответствии с типом той операции, в которой он будет использован. Вычислитель В i и очередь его использования s обозначим парой (i, s), которую в процессе формирования программы коммутации будем называть адресом вычислителя. Условимся о следующем порядке использования вычислителей. Первоначально до коммутации вычислителей для счета значения данного выражения считаем все регистры буферов свободными, т. е. очереди незанятыми. Просматривая выражение, используем для коммутации вычислителей первую очередь каждого вычислителя в порядке увеличения их номеров. Если однократного использования вычислителей оказывается недостаточно, приступаем к их использованию во вторую очередь и т. д. Одновременно с дальнейшим рассмотрением примера продемонстрируем принцип трансляции записи исходного выражения (4.2) в программу коммутации вычислителей решающего поля. Пусть решающее поле содержит четыре вычислителя (рис. 4.4), где Imn – регистры буферов, m – номер вычислителя, n – номер очереди). Учитывая обусловленный выше порядок использования вычислителей, а также то, что в каждой цепочке операций первая производится над одной или двумя величинами, имена которых указаны в предшествующей цепочке имен, наметим первый шаг их использования. Он соответствует выполнению первого яруса операций (второй ярус вершин в графе G). Отразим это условной записью:
В скобках указаны: выполняемая операция, номер вычислителя, номер регистра-очереди. Конструкции, связанные стрелками, определяют команды программы коммутации в соответствии с использованием регистров буферов, отображенных на рис. 4.4. Даная схема отражает порядок выполнения вычислений и на ее основе строится логика работы программы. Вместо четырех вычислителей обработка данных производится четырьмя тредами (прил. П3). На основе схемы коммутации счета (см. рис. 4.4) и листинга программы (см. прил. П3) рассмотрим порядок вычисления выражения. Первый тред – функция Thread1(): 1. Запуск треда. 2. Сложение (a+b). 3. Установка объекта события s 12 в состояние "включено". Этого события ожидает второй тред для продолжения вычислений. Таким образом, осуществляется синхронизация работы тредов. 4. Вычисление значения квадратного корня. 5. Вычитание (l - m). 6. Установка объекта события s 13 в состояние "включено", так как результат вычислений первого треда ожидает третий тред.
Р и с. 4.4. Схема коммутации счета
7. Ожидание результатов вычислений третьего и четвертого тредов. 8. Вывод результата. Переход с одного этапа вычислений на другой сопровождается выводом сообщения в ListBox. Аналогично работе первого треда осуществляется работа и остальных тредов. Составлению схемы коммутации счета способствует написание программы коммутации. Пусть программа коммутации (табл. 4.1) состоит из трехадресных командных слов, в которых указывается код операции q, адреса А 1 и А 2 операндов, адрес результата А 3. Каждый адрес может быть адресом ОПД или вычислителя (на что указывает тег). Тогда на основе анализа возможности выполнения первой операции из каждой цепочки операций можно записать первые пять команд программы. При выполнении этих команд решающим полем организуется вызов величин а и b на первый регистр I 11 (см. рис. 4.4) вычислителя 1, величин с и d на регистр I 21 и т. д. Величина m поступает на второй регистр I 12 вычислителя 1, так как все вычислители один раз использованы. Расположение операндов в регистрах соответствует порядку, в котором указаны их имена или адреса вырабатывающих их вычислителей в команде. Для продолжения процесса составления программы коммутации предположим, что произошло выполнение первого яруса операций в графе G. Таблица 4.1 Программа коммутации
Учтем это, преобразовав выражение с использованием адресов вычислителей, на которых получены результаты счета: А (1,1) (2,1) ´ (3,1) g + ´ (4,1) j ´ - k l (1,2) - ´:: = (4.3) Это бесскобочная запись выражения (4.1) при условии выполнения множества операций назначенными для этого вычислителями на первом шаге. Применим на втором шаге для нее тот же прием планирования использования вычислителей, что и на первом шаге. Отразим его, преобразовав запись (4.3):
Эта запись иллюстрирует формирование команд 6 – 9 программы коммутации вычислителей на втором шаге. С учетом дальнейшего условного выполнения операций вновь сформируем промежуточную бесскобочную запись счета значения исходного выражения, соответствующую выполнению второго яруса (третий ярус вершин) в графе G: А (2,2) (3,2) ´ (4,2) – k (1,3) ´:: = (4.4) Как и выше, планируем использование вычислителей для выполнения первой операции в каждой цепочке
Таким образом, на третьем шаге формируются команды 10 и 11, а запись преобразуется: А (2,3) (4,2) – (3,3):: = (4.5) На основе принятого порядка использования вычислителей на четвертом шаге формируется команда 12, предполагающая выполнение операции вычитания на вычислителе (4,3), и на пятом шаге формируется команда 13 получения окончательного результата А на вычислителе (1,4). На рис. 4.4 показана схема коммутации вычислителей для счета значения выражения (4.1). Таким образом, программа коммутации вычислителей составляется на основе анализа графа G по ярусам. Это способствует более раннему началу работы вычислителей при выполнении работ в порядке предшествования операций. При планировании выполнения операций мы считаем, что вычислитель, вырабатывающий результат, сам организует пересылку его для дальнейшего использования в качестве операнда или в память, т. е. вычислитель не производит опроса других вычислителей в ожидании готовности операндов для себя (в этом отличие от так называемых редукционных ВС). Необходимость такой пересылки и ее направление полностью определяются в процессе выполнения программы коммутации, как только встречается команда, в которой адрес данного вычислителя указан как источник операнда. В зависимости от позиции в выбранной нами трехадресной команде, в которой указан адрес этого вычислителя, формируется информация о том месте, на которое должен быть помещен результат на регистре буфера вычислителя-преемника. Это важно для правильного выполнения некоммутативных операций. Рассмотрев теоретические принципы организации параллельных вычислений, перейдем к практической составляющей. Одним из практических способов организации управления совместной работой исполнительных устройств при выполнении одной программы в ВС является управление потоком данных или организация потоковой обработки информации. Далее рассмотрим организацию параллельных вычислений средствами операционной системы. ОРГАНИЗАЦИЯ ПАРАЛЛЕЛЬНЫХ ВЫЧИСЛЕНИЙ СРЕДСТВАМИ ОПЕРАЦИОННОЙ СИСТЕМЫ Основными средствами выполнения параллельных вычислений в операционной системе является организация мультипрограммирования или мультипроцессорной обработки. Мультипрограммирование – это способ организации вычислительного процесса, при котором на одном процессоре попеременно выполняются сразу несколько программ. Эти программы совместно используют не только процессор, но и другие ресурсы компьютера: оперативную и внешнюю память, устройства ввода-вывода, данные. [4] Мультипроцессорная обработка – это способ организации вычислительного процесса в системах с несколькими процессорами, при котором несколько задач (процессов, потоков) могут одновременно выполняться на разных процессорах системы. [4] При мультипрограммировании параллельная работа приложений осуществляется на самом деле псевдопараллельно, так как несколько задач попеременно выполняются на одном процессоре. А в мультипроцессорных системах обработка ведется параллельно на нескольких обрабатывающих устройствах – процессорах. Однако организация мультипроцессирования требует более сложной структуры самой операционной системы (усложнение алгоритмов управления ресурсами). В настоящее время большинство операционных систем (ОС) поддерживают режим мультипрограммирования. Однако только современные ОС реализуют мультипроцессорную обработку (Sun Solaris 2.x, Santa Crus Operations Open Server 3.x, IBM OS/2, Microsoft Windows NT и Novell Net Ware, начиная с 4.1). Для организации мультипрограммирования в ОС различают следующие виды элементарных работ: процесс и поток. Процесс – это выполняющееся приложение, которое состоит из личного виртуального адресного пространства, кода, данных и других ресурсов операционной системы, таких, как файлы, пайпы и синхронизационные объекты, видимые для процесса. Процесс обладает несколькими объектами: адресное пространство, выполняемый модуль (модули) и все, что эти модули создают или открывают. Как минимум, процесс должен состоять из выполняющегося модуля, личного адресного пространства и ветви. У каждого процесса, по крайней мере, одна ветвь. Фактически, ветвь – это выполняющаяся очередь. Например, когда ОС Windows впервые создает процесс, она создает только одну ветвь на процесс. Эта ветвь обычно начинает выполнение с первой инструкции в модуле. Если в дальнейшем понадобится больше ветвей, то ОС может сама создать их. Эти ветви называются потоками или тредами. Тред – это цепь инструкций. Программист также может создавать дополнительные треды в программе. Таким образом, мультитрединг можно считать как многозадачность внутри одной программы. Если говорить в терминах непосредственной реализации, тред – это функция, которая выполняется параллельно с основной программой. Можно запустить несколько экземпляров одной и той же функции или несколько функций одновременно, в зависимости от требований. Мультитрединг свойственен Win32, под Win16 аналогов не существует. Треды выполняются в одном процессе, поэтому они имеют доступ ко всем ресурсам процесса: глобальным переменным, хэндлам и т.д. Тем не менее, каждый тред имеет свой собственный стек, так что локальные переменные в каждом треде приватны. Каждый тред также имеет свой собственный набор регистров, поэтому, когда ОС Windows переключается на другой тред, предыдущий "запоминает" свое состояние и может "восстановить" его, когда он снова получает контроль. Это обеспечивается внутренними средствами ОС Windows. Создание тредов при программировании осуществляется при помощи интерфейса прикладного программирования API (Application Programming Interface). Наибольший эффект от введения многопоточной обработки достигается в мультипроцессорных системах, в которых потоки, в том числе и принадлежащие одному процессу, могут выполняться на разных процессорах действительно параллельно (а не псевдопараллельно). [4] ПРИМЕР СОЗДАНИЯ МУЛЬТИПОТОЧНОГО ПРИЛОЖЕНИЯ Основой данного примера является арифметическое выражение 4.1, которое было рассмотрено в п. 4.2. В соответствии с информационным графом (см. рис. 4.2) и схемой коммутации счета (см. рис. 4.3) была написана программа, реализующая мультипоточное вычисление арифметического выражения (4.1) с использованием четырех тредов. В качестве среды разработки использовался пакет Microsoft Visual C++ 6.0. Первоначально создается проект File->New.
Рис. 6.1
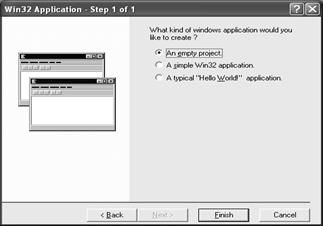
На закладке Projects выбираем проект Win32Application. В поле Project Name указываем имя проекта, а в поле Location – его размещение. После нажатия кнопки OK переходим к следующему шагу создания проекта (рис. 6.2).
Рис. 6.2
В окне (рис. 6.2) выбираем An empty project, что соответствует созданию пустого проекта. После нажатия кнопки Finish создается пустой проект с заданным именем. Далее переходим на поле Workspace, где отражена структура созданного проекта, первоначально состоящая из трех пустых папок: Source Files (файлы источники с расширением "cpp"), Header Files (заголовочные файлы с расширением "h"), Resource File (файлы ресурсов с расширением "rc"). Так как новый проект пустой, то нужно создать необходимые файлы. Для этого "щелчком" правой кнопки мыши по одной из трех папок вызываем контекстное меню и выбираем в нем пункт Add Files to Folder (Добавить файлы в папку) (рис. 6.3).
Рис. 6.3
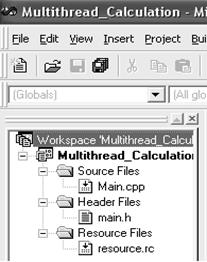
Далее в следующем окне (рис. 6.4) необходимо указать имя создаваемого файла и его расширение. Таким образом, создаем проект, который будет состоять из следующих файлов: Main.cpp (основной модуль), Main.h, Resource.rc (рис. 6.5). После того как были созданы пустые файлы необходимо наполнить их содержанием.
Рис. 6.4
Рис. 6.5
Для этого откроем его двойным "щелчком" левой кнопки мыши. Далее на появившейся в центральном окне папке Resource "щелчком" правой кнопки мыши вызываем в контекстном меню пункт Insert (рис. 6.6).
Рис. 6.6
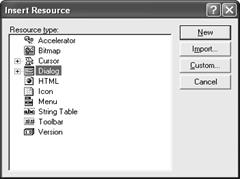
В появившемся окне выбираем Dialog и нажимаем кнопку New (рис. 6.7).
Рис. 6.7
Таким образом, создается новый диалог, на основе которого строится приложение (рис. 6.8). После создания диалога среда программирования автоматически создает заголовочный файл Resource.h, который необходимо поместить в папку Header File. Далее с использованием редактора ресурсов создаем интерфейс приложения, который будет иметь следующий вид (рис. 6.9).
Рис. 6.8
Рис. 6.9 В создаваемом приложении имеются: поля для ввода переменных (a, b, c, … m), поле View thread steps, предназначенное для вывода информации о состоянии тредов, а также кнопки Start и Terminate, соответственно для запуска и прерывания процесса вычисления. Далее с помощью интегрированного текстового редактора пишем исходный код программы, реализующей вычисление арифметического выражения при помощи четырех тредов, согласно созданному интерфейсу приложения. Исходный текст программы поместим в файлы Main.cpp и Main.h (рис. 6.10).
Рис. 6.10
Рассмотрим принцип функционирования приложения. Листинги текста программы приведены в прил. П3, П4, а описание используемых функций и их параметров – в прил. П2. Первоначально директивой препроцессора #include подключаем необходимые заголовочные файлы. Далее объявляем глобальные переменные и массивы переменных, так как в качестве общих данных несколько тредов могут использовать только глобальные переменные. После этого необходимо организовать точку входа. В Windows-приложениях для этого существует функция WinMain(). В теле этой функции организуем цикл по созданию объектов события – эти объекты необходимы для синхронизации тредов. Далее используем функцию, создающую диалоговое окно DialogBoxParam(). В качестве одного из параметров этой функции используется указатель на функцию обработки диалогового окна DlgProc(). В этой функции осуществляется обработка сообщений. Так при нажатии на кнопку Start проверяем введенные значения, если какая-либо переменная отсутствует, то выводим сообщение с помощью функции MessageBox(). Получение значений входных переменных осуществляется функцией GetOurVariables(). Если переменные введены, то очищаем ListBox при помощи функции SendDlgItemMessage(). Далее организуем цикл по созданию тредов, создание которых осуществляется функцией CreateThread(). В этом же цикле осуществляется установка уровня приоритета тредов – функция SetThreadPriority(), а также, выполнение тредов - функции Thread1, Thread2, Thread3, Thread4. Рассмотрим более детально функции тредов на примере функции Thread1. В этой функции используется макроподстановка, позволяющая осуществить вывод состояний тредов в ListBox – функция addstr(). Согласно схеме коммутации каждый тред выполняет определенные действия (вычисления), а также с помощью функций SetEvent(), WaitForMultipleObjects() и WaitForSingleObject() осуществляется синхронизация тредов. При нажатии кнопки Terminate запускается цикл, в котором осуществляется грубое прерывание тредов функцией TerminateThread(). Далее при помощи функции EnableWindow() кнопка Start становится активной, а кнопка Terminate деактивированной. Одним из параметров этой функции является функция GetDlgItem() – функция, возвращающая хендл элемента управления диалогового окна. При создании диалога обрабатывается сообщение WM_INITDIALOG, при этом используется функция SendMessage(). Обработка сообщения WM_CLOSE осуществляется функцией, корректно закрывающей диалоговое окно EndDlg(). После того, как текст программы написан, необходимо скомпилировать проект, а затем получить исполняемый модуль. Для этого выбираем из меню Build пункт Rebuild All (рис. 6.11).
Рис. 6.11
Если не возникает ошибок, то в итоге получаем исполняемый модуль, реализующий вычисление арифметического выражения (4.1) с использованием четырех тредов. При возникновении каких-либо ошибок их необходимо устранить. Для устранения ошибок можно использовать встроенный отладчик. При инициализации полученного исполняемого файла запускается приложение (рис. 6.12).
Рис. 6.12
Далее необходимо ввести значения переменных, например, используемых в п. 4.2, тогда в результате вычислений получаем рис. 6.13.
Рис. 6.13
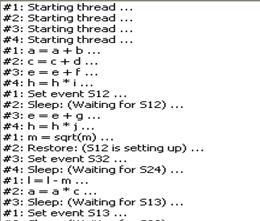
В поле View threads steps отражается состояние тредов и этапы вычислений (рис. 6.14)
Рис. 6.14
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2017-02-05; просмотров: 676; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.227.183.161 (0.012 с.) |

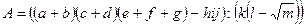 (4.1)
(4.1) (4.2)
(4.2)