
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Ю. В. Калмыков, А. В. ТаракановСтр 1 из 5Следующая ⇒
Ю. В. Калмыков, А. В. Тараканов СИСТЕМНОЕ ПРОГРАММНОЕ ОБЕСПЕЧЕНИЕ
Учебное пособие
Самара 2010 УДК 004.45 Калмыков Юрий Васильевич Тараканов Алексей Валерьевич Системное программное обеспечение: Учеб. пособ./ Самар. гос. техн. ун-т. Сост. Ю.В. Калмыков, А.В. Тараканов. Самара, 2010. 66 с.
Изложены принципы организации параллельных вычислений средствами операционной системы Windows. Рассмотрены вопросы определения временных характеристик приложений, написанных для различных операционных систем. Предназначено для студентов специальности 230101 «Вычислительные машины, комплексы, системы и сети» при выполнении ими курсовых работ. Ил. 29. Табл. 2. Библиогр.: 8 назв.
Печатается по решению редакционно-издательского совета СамГТУ
Рецензенты: канд. техн. наук А. В. Островой, канд. пед. наук Б. М. Маврин
© Ю. В. Калмыков, А. В. Тараканов, 2010 © Самарский государственный технический университет, 2010 ВВЕДЕНИЕ Данное пособие посвящено одному из эффективных приемов повышения производительности в вычислительных системах – параллельному программированию. При необходимости выполнить работу в строго отведенные временные рамки, и если это превышает возможности одного вычислителя, то стремятся распределить эту работу на ряд взаимосвязанных действий между одновременно занятыми исполнителями. Такое распределение является наиболее эффективным при одновременном независимом действии всех исполнителей. Однако идеальное распараллеливание далеко не всегда возможно: в общем случае, работы можно представить лишь частично упорядоченными во времени множествами последовательно-параллельных работ. Кардинально новые способы параллельной обработки представлены в современных операционных системах – мультипрограммирование или мультипроцессорная обработка. При мультипрограммировании параллельная работа приложений осуществляется на самом деле псевдопараллельно, так как несколько задач попеременно выполняются на одном процессоре. В мультипроцессорных системах обработка ведется параллельно на нескольких обрабатывающих устройствах – процессорах. Однако организация мультипроцессирования требует более сложной структуры самой операционной системы (усложнение алгоритмов управления ресурсами).
В качестве альтернативы параллельной обработке можно использовать написание программ на низкоуровневом языке программирования – ассемблере. Для определения эффективности применения того или иного метода в системах реального времени используется временной критерий. Определение временных характеристик программ осуществляется при помощи специального программного средства – профилировщика. Данное пособие адресуется студентам специальности 230101 «Вычислительные машины, комплексы, системы и сети» в качестве методического руководства к выполнению курсовой работы по дисциплине «Системное программное обеспечение». В основу методического руководства положен многолетний опыт преподавания аналогичных дисциплин авторами. Кроме того, данное руководство может заинтересовать всех, кто имеет дело с компьютерами и хочет больше узнать о принципах параллельной обработки. Быстрому появлению данного издания в свет способствовали некоторые студенты, среди которых надо отдельно отметить Дуданова Сергея, написавшего примеры программ, представленных в данном руководстве. Хотелось бы выразить благодарность также всем остальным людям, кто активно или пассивно помогал выходу данного пособия в свет. Содержание и объем курсовой работы Курсовая работа состоит из расчетно-пояснительной записки (РПЗ). Объем РПЗ – 25-30 листов машинописного текста на листах формата А4. В расчетной части необходимо представить: 1) информационный граф; 2) программу коммутации; 3) схему коммутации счета в соответствии с заданием. Согласно схеме коммутации счета написать программу, реализующую вычисление арифметического выражения на языке С/С++. Программа составляется для операционной системы Windows с использованием функций интерфейса прикладного программирования (API). Кроме того, в программе параллельные вычисления должны осуществляться с использованием четырех тредов. Программа на Ассемблере должна реализовывать последовательное вычисление арифметического выражения. При программировании необходимо учесть так называемые исключительные ситуации, например, деление на ноль.
В качестве задания каждому студенту выдается индивидуальное арифметическое выражение (прил. П6). Оформление курсовой работы Расчетно-пояснительная записка оформляется в соответствии с существующими стандартами. Оформление программного кода и других должно соответствовать примерам, приведенным в данном пособии. Первый лист РПЗ является титульным листом, который не нумеруется. Образец оформления титульного листа приведен в приложении П1. На первом (заглавном) листе РПЗ помещают содержание. Слово с о д е р ж а н и е записывают в виде заголовка симметрично к тексту прописными буквами. Далее с абзаца приводят наименования разделов, подразделов и приложений РПЗ и указывают номера листов, с которых они начинаются. На заглавном листе РПЗ делают рамку и помещают штамп в соответствии со стандартом. В основной надписи штампа указывается обозначение курсовой работы. Например: КР …, где за буквами КР ставится шифр специальности и специализации, учебной группы и шифр варианта в виде последовательности цифр. Текст РПЗ набирается на компьютере шрифтом Times New Roman, размер шрифта – 14, поля сверху, снизу и слева – 20 мм, справа – 10 мм. Схемы, рисунки и код также оформляются на компьютере в масштабе, позволяющем ясно различить их элементы. Излагать материал в РПЗ следует от первого лица множественного числа (определяем, выбираем, принимаем и т.д.) или использовать неопределенную форму (определяется, выбирается, принимается и т.п.). В конце РПЗ приводится список использованной литературы, включающий учебники, учебные пособия, справочники, государственные стандарты и др. Литературу в списке нумеруют арабскими цифрами и располагают в порядке появления ссылок на нее в тексте РПЗ. При ссылках проставляется номер литературного источника в квадратных скобках в соответствии со списком, например: [9]. В качестве примеров записи можно использовать список литературы в конце данного методического пособия. РАСПАРАЛЛЕЛИВАНИЕ ОБРАБОТКИ ВЫСОКОЙ ПРОИЗВОДИТЕЛЬНОСТИ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ Когда необходимо выполнить работу за ограниченное время и это превышает возможности одного исполнителя, то стремятся разделить эту работу на ряд взаимосвязанных действий и распределить их между одновременно занятыми исполнителями. Такое распределение более эффективно, если допускает одновременные и независимые действия всех исполнителей. Это и есть распараллеливание. Однако идеальное распараллеливание далеко не всегда возможно: в общем случае работы можно представить лишь частично упорядоченными во времени множествами параллельно-последовательных работ. Сейчас ни одно используемое, разрабатываемое или перспективное вычислительное средство не рассматривается вне проблемы привлечения новых резервов распараллеливания работ. Возникла самостоятельная проблема построения параллельных архитектур вычислительных систем, а также организации и планирования в них параллельных вычислительных процессов для достижения максимальной производительности. При этом параллельный процесс подсказывает целесообразную архитектуру так же, как архитектура диктует параллельный процесс.
Говоря о производительности, отметим, что каждая вычислительная система (ВС) может обладать как собственной характеристикой лишь значением пиковой производительности – суммарным числом выполняемых в единицу времени операций при полной загрузке всех исполнительных устройств. Для конкретных задач с учетом возможностей их распараллеливания, соотношения типов операций, режима вычислений в данной вычислительной системе и накладных расходов на организацию вычислительного процесса определяется значение реальной производительности. Отклонение реальной производительности от пиковой может характеризовать, насколько данная архитектура вычислительной системы действительно приспособлена к решению данной задачи или класса задач. Важными показателями при решении конкретных задач, комплексов взаимосвязанных задач, классов задач могут служить коэффициенты загрузки отдельных исполнительных устройств вычислительной системы или найденный усреднением на их основе коэффициент загрузки вычислительной системы. Указанные коэффициенты загрузки определяются отношением времени занятости соответствующих устройств работами по решению задачи к времени решения этой задачи. Таким образом, коэффициент загрузки вычислительной системы есть отношение реальной производительности к пиковой. Самым простым способом наращивания производительности (пиковой) вычислительных средств является построение многомашинных вычислительных систем на базе нескольких ЭВМ, объединенных каналами передачи информации или устройствами общей памяти. Такие многомашинные вычислительные системы предназначены для совместного решения распараллеленных задач или для выполнения сложных программных комплексов. Построение многопроцессорной вычислительной системы с общей оперативной памятью значительно расширяет возможности распараллеливания решения отдельных задач, так как практически исключает потери времени на передачу данных при выполнении информационно взаимосвязанных программных модулей на разных процессорах вычислительной системы.
Таким образом, можно ввести понятие именованной или потенциально именованной работы, которая рассматривается в качестве неделимой в общей совокупности взаимосвязанных работ, подлежащих распараллеливанию в вычислительной системе. Такие работы могут быть определены (снабжены именем) выражениями вида "процедура решения задачи целочисленного линейного программирования", "расчет значения полинома", "нахождение sinα", "сложение значений а и b ", "умножение двух компонент векторов" и т. д. Другими словами, именованная работа отражается в программе вычислительной системы на алгоритмическом языке или в ее коде в виде программного модуля, отдельной инструкции или операции над данными. Совокупность именованных работ задает пользователь. Во-вторых, выделим два уровня распараллеливания: 1) распределение отдельных задач, взаимодействующих программных модулей, процедур и т. д. (соответствует построению многопроцессорных вычислительных систем или многомашинных вычислительных систем); 2) распределение отдельных инструкций программы между исполнительными устройствами решающего поля (соответствует построению вычислительной системы на решающих полях). Отметим тенденцию совмещения в одной вычислительной системе двух уровней распараллеливания. Вычислительные системы развиваются как многопроцессорные, процессоры в которых располагают сложными АЛУ – решающими полями. Классификация вычислительных систем по реализуемым уровням распараллеливания, возможно, не является столь универсальной, она более близка к предложенной классификации, на основе таких характеристик, как число устройств управления (или процессоров), число АЛУ, связанных с каждым из них, параметры конвейерной реализации устройств и разрядность машинного слова.
В вычислительных системах Программа коммутации
Учтем это, преобразовав выражение с использованием адресов вычислителей, на которых получены результаты счета: А (1,1) (2,1) ´ (3,1) g + ´ (4,1) j ´ - k l (1,2) - ´:: = (4.3) Это бесскобочная запись выражения (4.1) при условии выполнения множества операций назначенными для этого вычислителями на первом шаге. Применим на втором шаге для нее тот же прием планирования использования вычислителей, что и на первом шаге. Отразим его, преобразовав запись (4.3):
Эта запись иллюстрирует формирование команд 6 – 9 программы коммутации вычислителей на втором шаге. С учетом дальнейшего условного выполнения операций вновь сформируем промежуточную бесскобочную запись счета значения исходного выражения, соответствующую выполнению второго яруса (третий ярус вершин) в графе G: А (2,2) (3,2) ´ (4,2) – k (1,3) ´:: = (4.4) Как и выше, планируем использование вычислителей для выполнения первой операции в каждой цепочке
Таким образом, на третьем шаге формируются команды 10 и 11, а запись преобразуется: А (2,3) (4,2) – (3,3):: = (4.5) На основе принятого порядка использования вычислителей на четвертом шаге формируется команда 12, предполагающая выполнение операции вычитания на вычислителе (4,3), и на пятом шаге формируется команда 13 получения окончательного результата А на вычислителе (1,4). На рис. 4.4 показана схема коммутации вычислителей для счета значения выражения (4.1). Таким образом, программа коммутации вычислителей составляется на основе анализа графа G по ярусам. Это способствует более раннему началу работы вычислителей при выполнении работ в порядке предшествования операций. При планировании выполнения операций мы считаем, что вычислитель, вырабатывающий результат, сам организует пересылку его для дальнейшего использования в качестве операнда или в память, т. е. вычислитель не производит опроса других вычислителей в ожидании готовности операндов для себя (в этом отличие от так называемых редукционных ВС). Необходимость такой пересылки и ее направление полностью определяются в процессе выполнения программы коммутации, как только встречается команда, в которой адрес данного вычислителя указан как источник операнда. В зависимости от позиции в выбранной нами трехадресной команде, в которой указан адрес этого вычислителя, формируется информация о том месте, на которое должен быть помещен результат на регистре буфера вычислителя-преемника. Это важно для правильного выполнения некоммутативных операций. Рассмотрев теоретические принципы организации параллельных вычислений, перейдем к практической составляющей. Одним из практических способов организации управления совместной работой исполнительных устройств при выполнении одной программы в ВС является управление потоком данных или организация потоковой обработки информации. Далее рассмотрим организацию параллельных вычислений средствами операционной системы. ОРГАНИЗАЦИЯ ПАРАЛЛЕЛЬНЫХ ВЫЧИСЛЕНИЙ СРЕДСТВАМИ ОПЕРАЦИОННОЙ СИСТЕМЫ Основными средствами выполнения параллельных вычислений в операционной системе является организация мультипрограммирования или мультипроцессорной обработки. Мультипрограммирование – это способ организации вычислительного процесса, при котором на одном процессоре попеременно выполняются сразу несколько программ. Эти программы совместно используют не только процессор, но и другие ресурсы компьютера: оперативную и внешнюю память, устройства ввода-вывода, данные. [4] Мультипроцессорная обработка – это способ организации вычислительного процесса в системах с несколькими процессорами, при котором несколько задач (процессов, потоков) могут одновременно выполняться на разных процессорах системы. [4] При мультипрограммировании параллельная работа приложений осуществляется на самом деле псевдопараллельно, так как несколько задач попеременно выполняются на одном процессоре. А в мультипроцессорных системах обработка ведется параллельно на нескольких обрабатывающих устройствах – процессорах. Однако организация мультипроцессирования требует более сложной структуры самой операционной системы (усложнение алгоритмов управления ресурсами). В настоящее время большинство операционных систем (ОС) поддерживают режим мультипрограммирования. Однако только современные ОС реализуют мультипроцессорную обработку (Sun Solaris 2.x, Santa Crus Operations Open Server 3.x, IBM OS/2, Microsoft Windows NT и Novell Net Ware, начиная с 4.1). Для организации мультипрограммирования в ОС различают следующие виды элементарных работ: процесс и поток. Процесс – это выполняющееся приложение, которое состоит из личного виртуального адресного пространства, кода, данных и других ресурсов операционной системы, таких, как файлы, пайпы и синхронизационные объекты, видимые для процесса. Процесс обладает несколькими объектами: адресное пространство, выполняемый модуль (модули) и все, что эти модули создают или открывают. Как минимум, процесс должен состоять из выполняющегося модуля, личного адресного пространства и ветви. У каждого процесса, по крайней мере, одна ветвь. Фактически, ветвь – это выполняющаяся очередь. Например, когда ОС Windows впервые создает процесс, она создает только одну ветвь на процесс. Эта ветвь обычно начинает выполнение с первой инструкции в модуле. Если в дальнейшем понадобится больше ветвей, то ОС может сама создать их. Эти ветви называются потоками или тредами. Тред – это цепь инструкций. Программист также может создавать дополнительные треды в программе. Таким образом, мультитрединг можно считать как многозадачность внутри одной программы. Если говорить в терминах непосредственной реализации, тред – это функция, которая выполняется параллельно с основной программой. Можно запустить несколько экземпляров одной и той же функции или несколько функций одновременно, в зависимости от требований. Мультитрединг свойственен Win32, под Win16 аналогов не существует. Треды выполняются в одном процессе, поэтому они имеют доступ ко всем ресурсам процесса: глобальным переменным, хэндлам и т.д. Тем не менее, каждый тред имеет свой собственный стек, так что локальные переменные в каждом треде приватны. Каждый тред также имеет свой собственный набор регистров, поэтому, когда ОС Windows переключается на другой тред, предыдущий "запоминает" свое состояние и может "восстановить" его, когда он снова получает контроль. Это обеспечивается внутренними средствами ОС Windows. Создание тредов при программировании осуществляется при помощи интерфейса прикладного программирования API (Application Programming Interface). Наибольший эффект от введения многопоточной обработки достигается в мультипроцессорных системах, в которых потоки, в том числе и принадлежащие одному процессу, могут выполняться на разных процессорах действительно параллельно (а не псевдопараллельно). [4] ПРИМЕР СОЗДАНИЯ МУЛЬТИПОТОЧНОГО ПРИЛОЖЕНИЯ Основой данного примера является арифметическое выражение 4.1, которое было рассмотрено в п. 4.2. В соответствии с информационным графом (см. рис. 4.2) и схемой коммутации счета (см. рис. 4.3) была написана программа, реализующая мультипоточное вычисление арифметического выражения (4.1) с использованием четырех тредов. В качестве среды разработки использовался пакет Microsoft Visual C++ 6.0. Первоначально создается проект File->New.
Рис. 6.1
На закладке Projects выбираем проект Win32Application. В поле Project Name указываем имя проекта, а в поле Location – его размещение. После нажатия кнопки OK переходим к следующему шагу создания проекта (рис. 6.2).
Рис. 6.2
В окне (рис. 6.2) выбираем An empty project, что соответствует созданию пустого проекта. После нажатия кнопки Finish создается пустой проект с заданным именем. Далее переходим на поле Workspace, где отражена структура созданного проекта, первоначально состоящая из трех пустых папок: Source Files (файлы источники с расширением "cpp"), Header Files (заголовочные файлы с расширением "h"), Resource File (файлы ресурсов с расширением "rc"). Так как новый проект пустой, то нужно создать необходимые файлы. Для этого "щелчком" правой кнопки мыши по одной из трех папок вызываем контекстное меню и выбираем в нем пункт Add Files to Folder (Добавить файлы в папку) (рис. 6.3).
Рис. 6.3
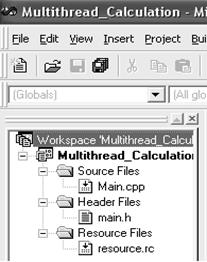
Далее в следующем окне (рис. 6.4) необходимо указать имя создаваемого файла и его расширение. Таким образом, создаем проект, который будет состоять из следующих файлов: Main.cpp (основной модуль), Main.h, Resource.rc (рис. 6.5). После того как были созданы пустые файлы необходимо наполнить их содержанием.
Рис. 6.4
Рис. 6.5
Для этого откроем его двойным "щелчком" левой кнопки мыши. Далее на появившейся в центральном окне папке Resource "щелчком" правой кнопки мыши вызываем в контекстном меню пункт Insert (рис. 6.6).
Рис. 6.6
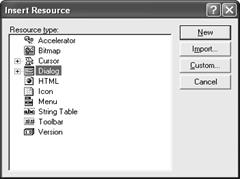
В появившемся окне выбираем Dialog и нажимаем кнопку New (рис. 6.7).
Рис. 6.7
Таким образом, создается новый диалог, на основе которого строится приложение (рис. 6.8). После создания диалога среда программирования автоматически создает заголовочный файл Resource.h, который необходимо поместить в папку Header File. Далее с использованием редактора ресурсов создаем интерфейс приложения, который будет иметь следующий вид (рис. 6.9).
Рис. 6.8
Рис. 6.9 В создаваемом приложении имеются: поля для ввода переменных (a, b, c, … m), поле View thread steps, предназначенное для вывода информации о состоянии тредов, а также кнопки Start и Terminate, соответственно для запуска и прерывания процесса вычисления. Далее с помощью интегрированного текстового редактора пишем исходный код программы, реализующей вычисление арифметического выражения при помощи четырех тредов, согласно созданному интерфейсу приложения. Исходный текст программы поместим в файлы Main.cpp и Main.h (рис. 6.10).
Рис. 6.10
Рассмотрим принцип функционирования приложения. Листинги текста программы приведены в прил. П3, П4, а описание используемых функций и их параметров – в прил. П2. Первоначально директивой препроцессора #include подключаем необходимые заголовочные файлы. Далее объявляем глобальные переменные и массивы переменных, так как в качестве общих данных несколько тредов могут использовать только глобальные переменные. После этого необходимо организовать точку входа. В Windows-приложениях для этого существует функция WinMain(). В теле этой функции организуем цикл по созданию объектов события – эти объекты необходимы для синхронизации тредов. Далее используем функцию, создающую диалоговое окно DialogBoxParam(). В качестве одного из параметров этой функции используется указатель на функцию обработки диалогового окна DlgProc(). В этой функции осуществляется обработка сообщений. Так при нажатии на кнопку Start проверяем введенные значения, если какая-либо переменная отсутствует, то выводим сообщение с помощью функции MessageBox(). Получение значений входных переменных осуществляется функцией GetOurVariables(). Если переменные введены, то очищаем ListBox при помощи функции SendDlgItemMessage(). Далее организуем цикл по созданию тредов, создание которых осуществляется функцией CreateThread(). В этом же цикле осуществляется установка уровня приоритета тредов – функция SetThreadPriority(), а также, выполнение тредов - функции Thread1, Thread2, Thread3, Thread4. Рассмотрим более детально функции тредов на примере функции Thread1. В этой функции используется макроподстановка, позволяющая осуществить вывод состояний тредов в ListBox – функция addstr(). Согласно схеме коммутации каждый тред выполняет определенные действия (вычисления), а также с помощью функций SetEvent(), WaitForMultipleObjects() и WaitForSingleObject() осуществляется синхронизация тредов. При нажатии кнопки Terminate запускается цикл, в котором осуществляется грубое прерывание тредов функцией TerminateThread(). Далее при помощи функции EnableWindow() кнопка Start становится активной, а кнопка Terminate деактивированной. Одним из параметров этой функции является функция GetDlgItem() – функция, возвращающая хендл элемента управления диалогового окна. При создании диалога обрабатывается сообщение WM_INITDIALOG, при этом используется функция SendMessage(). Обработка сообщения WM_CLOSE осуществляется функцией, корректно закрывающей диалоговое окно EndDlg(). После того, как текст программы написан, необходимо скомпилировать проект, а затем получить исполняемый модуль. Для этого выбираем из меню Build пункт Rebuild All (рис. 6.11).
Рис. 6.11
Если не возникает ошибок, то в итоге получаем исполняемый модуль, реализующий вычисление арифметического выражения (4.1) с использованием четырех тредов. При возникновении каких-либо ошибок их необходимо устранить. Для устранения ошибок можно использовать встроенный отладчик. При инициализации полученного исполняемого файла запускается приложение (рис. 6.12).
Рис. 6.12
Далее необходимо ввести значения переменных, например, используемых в п. 4.2, тогда в результате вычислений получаем рис. 6.13.
Рис. 6.13
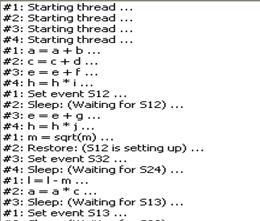
В поле View threads steps отражается состояние тредов и этапы вычислений (рис. 6.14)
Рис. 6.14 ОПРЕДЕЛЕНИЕ ВРЕМЕННЫХ ХАРАКТЕРИСТИК ПРИЛОЖЕНИЯ Используя профилировщик, оценим скорость работы приложения, написанного на С/С++ с организацией параллельных вычислений. При профилировании программного модуля, написанного на С/С++, для операционной системы Windows используем профилировщик AQtime 3.16. Demo. Первоначально необходимо установить настройки среды программирования, как показано на рис. 7.1 – 7.3.
Р и с. 7.1. Меню Build / Set Active Configuration
Р и с. 7.2. Меню Project / Settings
Рис. 7.3
После настройки среды программирования необходимо перекомпилировать проект Build / Rebuild Project, а затем запустить профилировщик.
Рис. 7.4
В профилировщике необходимо открыть из папки Debug файл MultithreadProject (рис. 7.5).
Рис. 7.5
Далее, в поле Areas с помощью контекстного меню, вызванного правой кнопкой мыши, выбираем опцию Add-Area…, в появившемся окне указываем имя AllThreads (рис. 7.6).
Рис. 7.6
В итоге в поле Areas появляется папка с именем AllThreads. Затем правой кнопкой мыши вызываем контекстное меню и выбираем пункт AddRoutines. В появившемся окне в левой его части выбираем файл main.obj, а в правой части окна выбираем функции тредов (рис. 7.7).
Рис. 7.7
Далее необходимо запустить программу выбором пункта Run из меню Project. После этого запускается приложение (рис. 6.12). В этом приложении необходимо ввести операнды арифметического выражения и произвести расчет. По результатам работы программы определяется время работы каждого треда, а также строится гистограмма, отражающая процентное соотношение времени выполнения каждого треда к общему времени вычислений (рис. 7.8). Для определения временных характеристик приложения, написанного на ассемблере, используем профилировщик Turbo Profiler, который является составной частью интегрированной среды разработки Borland C++ 5.02. Первоначально необходимо открыть профилируемый файл File -> Open (рис. 7.9). В открывшемся окне в поле Program name необходимо указать полный путь, по которому находится профилируемый файл (рис. 7.10). После загрузки окно профилировщика приобретет следующий вид (рис. 7.11). Далее необходимо запустить профилировщик Run -> Run. В результате работы которого в поле Execution Profile будет показано время вычисления арифметического выражения.
Рис. 7.8
Рис. 7.9
Рис. 7.10
Рис. 7.11
Таким образом, зная время работы приложения, написанного на С++ и на ассемблере, можно произвести их сравнение по временному критерию. Программа, написанная на ассемблере, выполняется на несколько порядков быстрее, чем программа, написанная на языке С++. Это связано с несколькими аспектами, одним из которых является то, что в последней программе необходимо было организовать синхронизацию, что потребовало дополнительных временных затрат. Таким образом, для достижения быстродействия, в каких-либо критичных ко времени выполнения участках программного кода, необходимо использовать ассемблер. Однако организация параллельных вычислений, являясь одним из средств повышения производительности вычислительных систем, наиболее эффективна в больших программах, выполнение которых будет осуществляться на многопроцессорных или многомашинных платформах. ПОРЯДОК ВЫПОЛНЕНИЯ РАБОТЫ 1. На основе полученного арифметического выражения построить информационный граф G, как показано в примере (п. 4.2). 2. Используя полученный информационный граф и арифметическое выражение, составить программу коммутации и построить схему коммутации счета (см. п. 4.2). 3. Используя API функции операционной системы Windows, организовать параллельные вычисления заданного арифметического выражения. Вычисления осуществляются в четырех тредах, между которыми необходимо осуществлять синхронизацию. В качестве операндов арифметического выражения используются целые неотрицательные числа от 0 до 99. 4. Определить время выполнения вычислений в каждом треде и общее время работы программы, используя профилировщик AQtime 3.16. Demo. 5. Написать программу вычисления арифметического выражения 4.1 на языке Ассемблера без организации параллельных вычислений. В качестве операндов арифметического выражения используются целые неотрицательные числа от 0 до 99. 6. Используя профилировщик Turbo Profiler определить время выполнения вычислений арифметического выражения в программе написанной на ассемблере. СОДЕРЖАНИЕ РАСЧЕТНО-ПОЯСНИТЕЛЬНОЙ ЗАПИСКИ В расчетно-пояснительной записке должны присутствовать: 1. Краткое описание теории, способы достижения высокой производительности вычислительных систем, необходимость организации параллельных вычислений, организация параллельных вычислений средствами операционных систем. 2. Информационный граф, схема коммутации счета, программа коммутации, в соответствии с индивидуальным заданием. 3. Листинг программы на языке С/С++, организующей параллельное вычисление индивидуального арифметического выражения, с комментариями и описанием, интерфейс программы и результаты ее работы. 4. Листинг программы на языке ассемблера, организующей последовательное вычисление индивидуального арифметического выражения, с комментариями и описанием, интерфейс программы и результаты ее работы. 5. Результаты профилирования программы, написанной на языке С/С++ (время работы каждого треда и общее время вычислений, гистограмма, отражающая процентное соотношение времени выполнения каждого треда к общему времени вычислений). 6. Результаты профилирования программы, написанной на языке ассемблера. 7. Сравнительный анализ программ, написанных на С++ и на ассемблере, по временному критерию.
ПРИЛОЖЕНИЯ Приложение П1
Министерство образования и науки Российской Федерации Филиал государственного образовательного учреждения высшего профессионального образования «Самарский государственный технический университет» В г. Сызрани
Процессов и производств» К курсовой работе «Системное программное обеспечение» Вариант __________
Исполнитель: Студент группы _______ _________ И.И. Иванов (шифр группы) (подпись) Руководитель КР: ________________ П.П. Петров (подпись) _______________________ (ученая степень, ученое звание)
_____________________________ (оценка работы)
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2017-02-05; просмотров: 550; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.17.128.129 (0.197 с.) |
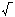

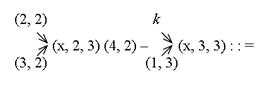





















 Кафедра «Автоматизация технологических
Кафедра «Автоматизация технологических


