
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Внешняя сортировка. Частичная сортировка. Частичная сортировка (выбор). Частичная сортировка (слияние).Содержание книги
Поиск на нашем сайте
on_load_lecture() Внешняя сортировка В методах сортировки, обсуждавшихся в предыдущем разделе, мы полагали, что таблица умещается в быстродействующей внутренней памяти. Хотя для большинства реальных задач обработки данных это предположение слишком сильно, оно, как правило, выполняется для комбинаторных алгоритмов. Сортировка обычно используется только для некоторого сокращения времени работы алгоритмов, в которых сортировка применяется только для некоторого сокращения времени работы алгоритмов, когда оно недопустимо велико даже для задач "умеренных" размеров. Например, часто бывает необходимо сортировать отдельные предметы во времени исчерпывающего поиска, но поскольку такой поиск обычно требует экспоненциального времени, маловероятно, что подлежащая сортировке таблица будет настолько большой, чтобы потребовалось использование запоминающих устройств. Однако задача сортировки таблицы, которая слишком велика для основной памяти, служит хорошей иллюстрацией работы с данными большого объема, и поэтому в этом разделе мы обсудим важные идеи внешней сортировки. Более того, будем рассматривать только сортировку таблицы путем использования вспомогательной памяти с последовательным доступом. Условимся называть эту память лентой. Общей стратегией в такой внешней сортировке является использование внутренней памяти для сортировки имен из ленты по частям так, чтобы производить исходные отрезки (известные также как цепочки) имен в возрастающем порядке. По мере порождения эти отрезки распределяются по Самый очевидный метод для получения исходных отрезков состоит в том, что можно просто считывать Порождение исходных отрезков продолжается следующим образом. Из входной ленты считываются первые Разумный путь реализации этой процедуры состоит в том, чтобы рассматривать каждое имя Порождает ли этот выбор с замещением длинные отрезки? Ясно, что он делает это, по крайней мере, не хуже, чем очевидный метод, так как все отрезки (кроме, возможно, последнего) содержат не меньше После того, как порождены исходные отрезки, возникает задача повторного распределения их по рабочим лентам и слияния их вместе до тех пор, пока в конце концов мы не получим окончательную отсортированную таблицу. Простейший метод состоит в том, чтобы распределить отрезки по лентам Частичная сортировка Ранее мы изучали проблему полного упорядочения множества имен, не имея a priori информации об абстрактном порядке имен. Имеется два очевидных уточнения этой проблемы. Вместо полного упорядочения требуется только определить
|
||||
|
|
Последнее изменение этой страницы: 2017-02-07; просмотров: 199; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.147.126.199 (0.011 с.) |

 рабочим лентам, и затем производится их слияние по
рабочим лентам, и затем производится их слияние по  -ю ленту так, что она будет содержать меньшее число более длинных отрезков. Затем отрезки снова распределяются по остальным
-ю ленту так, что она будет содержать меньшее число более длинных отрезков. Затем отрезки снова распределяются по остальным  имен, рассортировывать их во внутренней памяти и записывать их на ленту в виде отрезка, продолжая процесс до тех пор, пока не будут исчерпаны все имена. Все полученные таким образом исходные отрезки содержат
имен, рассортировывать их во внутренней памяти и записывать их на ленту в виде отрезка, продолжая процесс до тех пор, пока не будут исчерпаны все имена. Все полученные таким образом исходные отрезки содержат  как пару
как пару  , где
, где  есть номер отрезка, в котором находится
есть номер отрезка, в котором находится  ; сравнения между парами осуществляются лексикографически. Когда считывается имя, меньшее последнего имени в текущем отрезке, оно должно быть в следующем отрезке, и благодаря наличию номера отрезка это имя будет ниже всех имен пирамиды, которые входят в текущий отрезок.
; сравнения между парами осуществляются лексикографически. Когда считывается имя, меньшее последнего имени в текущем отрезке, оно должно быть в следующем отрезке, и благодаря наличию номера отрезка это имя будет ниже всех имен пирамиды, которые входят в текущий отрезок. , и это вполне можно считать улучшением по сравнению с очевидным методом, в котором средняя длина отрезков равна
, и это вполне можно считать улучшением по сравнению с очевидным методом, в котором средняя длина отрезков равна 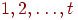 равномерно и произвести их слияние на ленту
равномерно и произвести их слияние на ленту  . Получаемые в результате отрезки снова равномерно распределить по лентам
. Получаемые в результате отрезки снова равномерно распределить по лентам  -е наибольшее имя (то есть
-е наибольшее имя (то есть 


