
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Алгоритм сортировки выбором. Распределяющая сортировка. Цифровая распределяющая сортировка.Содержание книги
Поиск на нашем сайте
on_load_lecture() Выбор В сортировке посредством выбора основная идея состоит в том, чтобы идти по шагам
Несмотря на неэффективность алгоритма 1, идея выбора может привести и к эффективному алгоритму сортировки. Весь вопрос в том, чтобы найти более эффективный метод определения Идея турнира с выбыванием прослеживается при сортировке весьма отчетливо, если имена образуют пирамиду. Пирамида - это полностью сбалансированное бинарное дерево высоты
Заметим, что в пирамиде наибольшее имя должно находиться в корне и, таким образом, всегда в первой позиции массива, представляющего пирамиду. Обмен местами первого имени с
Это общее описание пирамидальной сортировки.
Процедура RESTORE
Переписывая это итеративным способом и дополняя деталями, мы получим алгоритм 2.
Распределяющая сортировка Обсуждаемый здесь алгоритм сортировки отличается от рассматривавшихся до сих пор тем, что он основан не на сравнениях между именами, а на представлении имен. Мы полагаем, что каждое из имен
и их нужно отсортировать в возрастающем лексикографическом порядке, то есть
тогда и только тогда, если для некоторого
|
|||||
|
|
Последнее изменение этой страницы: 2017-02-07; просмотров: 255; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.139.70.69 (0.006 с.) |

 , находя
, находя  -е наибольшее (наименьшее) имя и помещая его на его место на
-е наибольшее (наименьшее) имя и помещая его на его место на  имен. Число сравнений имен на
имен. Число сравнений имен на  , что приводит к общему числу сравнений имен
, что приводит к общему числу сравнений имен  независимо от входа, поэтому ясно, что это не очень хороший способ сортировки.
независимо от входа, поэтому ясно, что это не очень хороший способ сортировки.
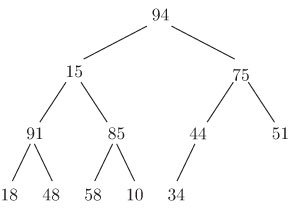
 , затем сравниваются "победители" (то есть большие имена) этих сравнений и т.д.; эта процедура для
, затем сравниваются "победители" (то есть большие имена) этих сравнений и т.д.; эта процедура для  показана на рис. 1. Заметим, что для определения наибольшего имени этот процесс требует
показана на рис. 1. Заметим, что для определения наибольшего имени этот процесс требует  сравнений имен; но, определив наибольшее имя, мы обладаем большим объемом информации о втором по величине (в порядке убывания) имени: оно должно быть одним из тех, которые "потерпели поражение" от наибольшего имени. Таким образом, второе по величине имя теперь можно определить, заменяя наибольшее имя на
сравнений имен; но, определив наибольшее имя, мы обладаем большим объемом информации о втором по величине (в порядке убывания) имени: оно должно быть одним из тех, которые "потерпели поражение" от наибольшего имени. Таким образом, второе по величине имя теперь можно определить, заменяя наибольшее имя на  и вновь осуществляя сравнение вдоль пути от наибольшего имени к корню. На рис. 2 эта процедура показана для дерева из рис. 1.
и вновь осуществляя сравнение вдоль пути от наибольшего имени к корню. На рис. 2 эта процедура показана для дерева из рис. 1. , в котором все листья находятся на расстоянии
, в котором все листья находятся на расстоянии  от корня и все потомки узла меньше его самого; кроме того, в нем все листья уровня максимально смещены влево. На рис. 3 показано множество имен, организованных в виде пирамиды. Чтобы получить удобное линейное представление дерева, пирамиду можно хранить по уровням в одномерном массиве: сыновья имени из
от корня и все потомки узла меньше его самого; кроме того, в нем все листья уровня максимально смещены влево. На рис. 3 показано множество имен, организованных в виде пирамиды. Чтобы получить удобное линейное представление дерева, пирамиду можно хранить по уровням в одномерном массиве: сыновья имени из  и
и  . Таким образом, пирамида, представленная на рисунке 3, принимает вид
. Таким образом, пирамида, представленная на рисунке 3, принимает вид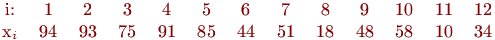
 -м помещает наибольшее имя в его правильную позицию, но нарушает свойство пирамидальности в первых
-м помещает наибольшее имя в его правильную позицию, но нарушает свойство пирамидальности в первых  ,
,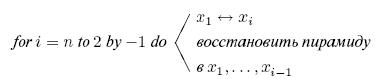

 восстановления пирамиды из последовательности
восстановления пирамиды из последовательности  в предположении, что все поддеревья суть пирамиды, такова:
в предположении, что все поддеревья суть пирамиды, такова:




 имеем
имеем 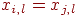 для
для  и
и  . Для простоты будем считать, что
. Для простоты будем считать, что 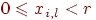 , и поэтому имена можно рассматривать как целые, представленные по основанию
, и поэтому имена можно рассматривать как целые, представленные по основанию  , так что каждое имя имеет
, так что каждое имя имеет 



