
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Оптимальные деревья бинарного поиска
Бинарный поиск в последовательно распределенной таблице (алгоритм 13.4.) обеспечивает очень быстрое нахождение имен, которые являются средними точками на раннем этапе процесса деления пополам, именно имен, близких к вершине дерева
На практике в большинстве таблиц встречаются имена, к которым обращаются гораздо чаще, чем к другим, и "привилегированные" места в таблице разумно постараться использовать для наиболее часто вызываемых имен, а не для имен, выбранных для этих мест в результате бинарного поиска. Это невозможно осуществить для последовательно распределенных таблиц, поскольку место имени определяется его положением относительно естественного порядка имен в таблице. Введем структуру данных, легко приспосабливаемую как к месту бинарного поиска, так и к возможности выделять точки, в которых таблица делится на две части. Деревом бинарного поиска над именами Поиск имени
Пусть бинарное дерево имеет вид, в котором каждый узел представляет собой тройку (LEFT, NAME, RIGHT), где LEFT и RIGHTсодержат указатели левого и правого сыновей соответственно, и NAME содержит имя, хранящееся в узле. Указатели могут иметь значение
Эта процедура нахождения имени
Логарифмический поиск в динамических таблицах Здесь мы рассмотрим организацию в виде деревьев для таблиц, в которых часто встречаются включения и исключения. Что происходит с временем поиска в дереве, которое модифицировалось путем включения и исключения? Если включенные и исключенные имена выбраны случайно, то оказывается, что в среднем время поиска мало изменяется; но в худшем случае поведение плохое - деревья могут вырождаться в линейные списки, поиск в которых нужно осуществлять последовательно. Проблема вырождения дерева в линейный список, приводящая к времени поиска Случайные деревья бинарного поиска. Как ведут себя деревья бинарного поиска без ограничений в качестве динамических деревьев? Другими словами, предположим, что дерево бинарного поиска меняется при случайных включениях и исключениях. Для включения
Исключение гораздо сложнее включения, и мы изложим здесь только основную идею. Если подлежащее удалению имя Лекция № 5
|
||||||
|
|
Последнее изменение этой страницы: 2017-02-07; просмотров: 182; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.118.200.136 (0.005 с.) |
 . Таким образом, любое имя в таблице можно выбрать примерно за
. Таким образом, любое имя в таблице можно выбрать примерно за 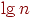 сравнений.
сравнений.
 называется расширенное бинарное дерево, все внутренние узлы которого помечены различными именами из списка
называется расширенное бинарное дерево, все внутренние узлы которого помечены различными именами из списка  внешних узлов соответствует промежутку в таблице. На рис.1 показаны четыре различных дерева бинарного поиска на множестве имен
внешних узлов соответствует промежутку в таблице. На рис.1 показаны четыре различных дерева бинарного поиска на множестве имен  . Деревья (а) и (b) - вырожденные, поскольку они по существу являются линейными списками, которые должны просматриваться последовательно.
. Деревья (а) и (b) - вырожденные, поскольку они по существу являются линейными списками, которые должны просматриваться последовательно. в дереве бинарного поиска осуществляется путем сравнения
в дереве бинарного поиска осуществляется путем сравнения  , означающее, что поддерево, на которое они указывают пусто. Если указатель корня дерева есть
, означающее, что поддерево, на которое они указывают пусто. Если указатель корня дерева есть  , показана в алгоритме 5. Отметим его сходство с алгоритмом 4 (бинарный поиск).
, показана в алгоритме 5. Отметим его сходство с алгоритмом 4 (бинарный поиск).
 вместо
вместо  в практических применениях выражена более резко, чем это указывается теоретическим анализом. Такой анализ обычно предполагает, что включения и исключения появляются случайным образом, но на практике часто это не так.
в практических применениях выражена более резко, чем это указывается теоретическим анализом. Такой анализ обычно предполагает, что включения и исключения появляются случайным образом, но на практике часто это не так. указатель
указатель  не указывает больше на последний пройденный узел, а вместо этого имеет значение
не указывает больше на последний пройденный узел, а вместо этого имеет значение  или
или  ; мы можем осуществить это, сделав процедуру включения рекурсивной. Процедура
; мы можем осуществить это, сделав процедуру включения рекурсивной. Процедура  выдает в качестве значения указатель на дерево, в которое добавлено
выдает в качестве значения указатель на дерево, в которое добавлено  используется для включения
используется для включения 
 , которое непосредственно предшествует
, которое непосредственно предшествует  , которое непосредственно следует за
, которое непосредственно следует за 


