
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Корреляционно-регрессионный анализ взаимосвязей социально-экономических явленийСтр 1 из 8Следующая ⇒
КОРРЕЛЯЦИОННО-РЕГРЕССИОННЫЙ АНАЛИЗ ВЗАИМОСВЯЗЕЙ СОЦИАЛЬНО-ЭКОНОМИЧЕСКИХ ЯВЛЕНИЙ План 1. Понятие, виды и формы факторных связей. 1.1. Понятие о функциональных и стохастических связях. Корреляционная связь. 1.2.Графическое представлениекорреляционной связи 1.3.Виды и формы выражения корреляционной связи 1.4. Свойства корреляционной связи 2. Этапы корреляционно-регрессионного анализа, требования к исходному статистическому материалу 3. Корреляционный анализ взаимосвязи признаков 3.1. Основные статистические методы выявления наличия и направления корреляционной связи 3.2. Измерение тесноты корреляционной связи 4. Регрессионный анализ взаимосвязи признаков. 4.1. Выбор аналитической формы связи. 4. 2. Расчет числовые значения параметров математической функции связи. 4. 3. Анализ качества построенной модели. 5. Непараметические методы обнаружения взаимосвязей социально- экономических явлений. Пример 1. Пусть первичные данные статистического наблюдения представлены в табл. 1, где каждому значению xi фактора X соответствуют несколько значений результативного признака Y. Таблица 1 Первичные данные статистического наблюдения
Зависимость Y от X можно представить в виде соответствий: для x1=8: для x2=9: и т.д.
Средние арифметические значения Для рассмотренного примера зависимость между значениями xi и условными средними Таблица 2 Корреляционный анализ взаимосвязи признаков Основные статистические методы выявления наличия Пример.
Обращаясь к исходным данным примера, можно говорить о наличии прямой корреляционной связи между признаками Х,Y, обратной связи - между признаками Х, Z и отсутствии связи между Х,W.
Метод параллельных рядов обычно используется для установления характера связи при относительно небольшом объёме исходных данных. 2. Метод аналитической группировки
В статистической практике изучение взаимосвязей явлений проводится, как правило, по достаточно большому числу наблюдений, а значения наблюдаемых признаков X и Y представляются в сгруппированном виде Наиболее удобной формой представления корреляционных зависимостей при большом числе наблюдений являются групповые аналитические таблицы, отражающие результаты аналитической группировки статистической совокупности по факторному признаку.
При построении аналитической таблицы для каждой выделенной j -ой группы подсчитывается численность составляющих её факторных значений x, а также суммарное и среднее
Пример. Зависимость суммы прибыли банков от объема кредитных вложений.
.Если при переходе от одной группы к другой средние значения
3. Метод корреляционной таблицы
При построении корреляционной таблицы значения признаков X и Y ранжируются в порядке возрастания, факторные значения xi располагаются, как правило, в строках таблицы, результативные – в столбцах (графах), а на пересечении строк и столбцов проставляются числа, указывающие частоту появления различных результативных значений yj при фиксированном факторном значении xi. При таком построении таблицы каждая i -ая строка представляет распределение признака Y при условии X= xi. В итоговой строке таблицы проставляются частоты
Пример. Зависимость суммы прибыли банков от объема кредитных вложений.
По корреляционной таблице прослеживают визуально, как именно расположена в таблице основная масса частот повторения в эмпирических данных сочетаний (xi, yj): - концентрация частот вдоль диагонали от левого верхнего угла таблицы к правому нижнему (т.е. большему значению X соответствует большее значение Y) означает наличие прямой корреляционной связи между признаками (как в таблице данного примера). - концентрация частот вдоль диагонали от левого нижнего угла к правому верхнему (когда большему значению Х соответствует меньшее значение Y) означает наличие обратной корреляционной связи между признаками Интенсивная концентрация частот около диагонали таблицы указывает на факт тесной корреляционной связи. Так, в корреляционной таблице данного примера наблюдается тесная связь между рассматриваемыми признаками. Корреляционная таблица дает более правильную характеристику тесноты связи в случае, если число выделенных групп одинаково для обоих изучаемым признаков X и Y (как в приведенной таблице). ПРИМЕР ПОСТРОЕНИЯ ЛИНЕЙНОГО УРАВНЕНИЯ РЕГРЕСИИ
Имеются следующие условные данные о размере страховой суммы и страховых выплат на автотранспортные средства одной из страховых компаний Таблица 7 Расчётная таблица для определения параметровуравнения регрессии
Решение. Система нормальных уравнений (22)
для данных таблицы принимает вид:
Решение системы методом исключений или по формулам (23), (24) дает:
Тогда модель связи в виде линейного уравнения регрессий имеет вид:
Расчётные значения страховых выплат Наблюдаются отклонения между фактическими и теоретическими значениями yi. Однако суммарные значения совпадают (26,65=25,650). Это свидетельствует, что из всех возможных линейных моделей построенная модель является наилучшей. Это объясняется тем, что она получена методом наименьших квадратов (МНК) путём решения задачи на экстремум.
Коэффициент a1 при факторе Х называется коэффициентом регрессии. Величина коэффициента регрессии a1 показывает, на сколько в среднем изменяется значения результативного признака Y при изменении фактора Х на единицу его измерения. Знак при a1 показывает направление этого изменения. В примере единицей измерения X и Y является 1000 $. Следовательно, коэффициент регрессии
При изучении многофакторных корреляционных связей методология их моделирования уравнениями регрессии аналогична рассмотренной.
Уравнения многофакторной регрессии имеют вид:
и позволяют приближенно оценить меру влияния на результативный признак Y каждого из включенных в модель факторов X. Наиболее простыми для построения и анализа являются многофакторные линейные модели, которые содержат независимые переменные только первой степени:
Методом наименьших квадратов для нее получна систему нормальных уравнений:
Параметры уравнения множественной регрессии С изменением факторного признака ak, на единицу его измерения (при неизменном значении других факторов) результативный признак Y изменяется в среднем на величину параметра ak.
Необходимо отметить, что параметры связи ak, в силу их расчета по МНК, являются усредненными по всей совокупности наблюдений (xi, yi). Они отражают взаимосвязь признаков X и Y только в общем итоге, по всей совокупности в целом (для каждой индивидуальной пары (xi, yi) значения ak остаются неизвестными.
3. Анализ качества построенной модели Этот этап заключается в анализе адекватности и практической пригодности построенной регрессионной модели. Анализ качества регрессионной модели ставит задачу – определить, насколько построенная теоретическая модель взаимосвязи признаков отражает фактическую зависимость между этими признаками. Анализ выполняется в 3 этапа:
1) измерение тесноты связи признаков в уравнении регрессии; 2) определение по величине показателей тесноты связи практической пригодности построенной модели связи; 3) проверка статистической значимости показателей тесноты связи.
Этап 1. Для построенной регрессионной модели измерение тесноты связи признаков X и Y осуществляется на основе следующих показателей: R2 - коэффициент (или индекс) детерминации, показывающий, какая часть общей вариации расчетных (теоретических) значений признака Y объясняется вариацией фактора X;
R – индекс корреляции (называемый также теоретическим корреляционным отношением и обозначаемый r – линейный коэффициент корреляции, используемый для измерения тесноты связи признаков в регрессионной модели в случае линейной функции связи f(x). Расчет этих показателей определяется следующими формулами:
где a1 – коэффициент регрессии в регрессионной модели связи. Используя соотношения для вычисления соответствующих дисперсий, а также известное из математической статистики правило сложения дисперсий
для расчета показателей R2 и R применяют формулы:
В многофакторном корреляционном анализе для характеристики тесноты связи между изучаемым показателем и влияющими на него факторами, используются парные, частные и множественные коэффициенты корреляции, множественный коэффициент детерминации.
Этап 2. Практическая пригодность синтезированной регрессионной модели связи оценивается по величине показателей r (в случае линейности модели), R или R2. Значения всех трех показателей R2, R и r зависят от того, какая типовая форма (8) уравнения регрессии была выбрана, поэтому эти показатели можно рассматривать как измерители степени близостивыбранной теоретической линии регрессии к фактическим данным. Качественный характер такой близости может оцениваться в соответствии со шкалой Чэддока. Индекс корреляции R принимает значения в пределах · близость R к единице означает, что связь между признаками достаточно хорошо описывается избранным уравнением корреляционной зависимости (8); · если R равен или близок к нулю, это означает, что между фактором X и теоретическими значениями признака Y либо нет связи, либо если она и существует, то не может быть охарактеризована выбранным для моделирования типовым аналитическим выражением связи (8). Аналогичные утверждения имеют место и для линейного коэффициента корреляции r, принимающего значения в пределах -1 · близость · близость Пригодность построенной регрессионной модели для практического использования можно оценить и по величине коэффициента детерминации R2 : · неравенство R2 >0,5 позволяет считать, что построенная модель пригодна для практического применения, т.к. в ней достигается высокая степень тесноты связи признаков X и Y, при которой более 50% вариации признака Y объясняется влиянием фактора Х; · неравенство
В тех случаях, когда синтезированы различные (альтернативные) регрессионные модели, коэффициент детерминации R2 используется в качестве критерия предпочтительности того или иного уравнения регрессии: наилучшей считается модель с наибольшим значением R2.
Этап 3. Так как показатели тесноты связи R или r рассчитываются на основе ограниченной совокупности наблюдаемых эмпирических данных (xi, yi), значения которых могли быть искажены влиянием случайных факторов, то найденные по уравнению регрессии показатели тесноты связи r, R проверяются на их неслучайность (значимость).
В начале проверки задается уровень значимости (чаще всего обозначаемый буквой греческого алфавита «альфа» —
Для оценки значимости линейного коэффициента корреляции r применяется t-критерий Стьюдента, фактическое значение которого рассчитывается по формуле:
Расчетное значение критерия tr сравнивается с критическим tтабл, определяемым по таблице значений t-критерия Стьюдента с учетом заданного уровня значимости
Для оценки значимости индекса корреляции R применяется F-критерий ФишераFR, фактическое значение которого определяется по формуле
где m – число параметров уравнения регрессии. Расчетная величина FR сравнивается с критическим табличным значением Fтабл ( Если Fрасч>Fтабл, то величина найденного индекса корреляции R признается значимой. Значимость показателя тесноты связи R или r означает, что зависимость между признаками Х и Y регрессионной модели является статистически существенной, т.е. построенная регрессионная модель в целом адекватна исследуемому процессу. Следовательно, выводы, сделанные на основе регрессионной модели, построенной по данным ограниченной выборки, можно с достаточной вероятностью распространить на всю генеральную совокупность. В качестве критериев адекватности регрессионной модели в практике экономико-статистического анализа, помимо показателя тесноты связи r, R и R2, используются также показатели, оценивающие погрешность модели: · средняя квадратическая ошибка уравнения регрессии
· средняя ошибка аппроксимации
В адекватных моделях ошибки Показатели
5. Экономическая интерпретация построенной регрессионной модели Взаимосвязи признаков Экономическая интерпретация построенной регрессионной модели взаимосвязи признаков – это, по существу, перевод модели с языка статистики и математики на язык экономики. Интерпретация уравнения регрессии используется для целей анализа и прогноза взаимосвязей признаков.
1. В процессе анализа прежде всего выясняются, как факторный признак влияет на величину результативного признака. Чем больше величина коэффициентов регрессии ak при k-ой степени фактора Х, тем значительнее влияние данного признака на результативный. В случае линейного уравнения регрессии Если в соответствии с экономической теорией факторный признак должен иметь положительное значение, а коэффициент ak имеет знак «-», то необходимо проверить расчёты параметров связи, а также возможность ошибок при сборе и обработке информации.
2. С целью расширения возможностей экономического анализа используется коэффициент эластичности 3. Анализируя остатки 4. Уравнение регрессии Прогнозные значения результативного признака Y получают путем подстановки в уравнение регрессии Уравнение позволяет определять в рассматриваемом временном периоде возможные значения признака Y при значениях Х из интервала [ xmin - xmax ].
При прогнозировании значений Y за рассмотренными пределами изменения фактора X необходимо соблюдать следующее ограничение: нельзя подставлять в уравнение регрессии факторные значения xi, существенно отличающиеся от тех, на основе которых это уравнение было получено. Для выполнения этого требования при выборе факторных производных значений х рекомендуется не выходить за пределы 1/3 размаха вариации фактора x (xmax-xmin) как сверх минимального (xmin), так и сверх максимального (xmax)значений, которые имеются в исходных эмпирических данных.
Пример (анализ взаимосвязей с проверкой возможности применения метода КРА).
Имеются следующие данные по отрасли:
Провести на основе приведенных данных исследование взаимосвязи балансовой прибыли и ежегодной суммы амортизации; проверить аналитическое выражение связи на достоверность.
Результативный признак – балансовая прибыль (y); Факторный признак – ежегодная сумма амортизации (х).
Результаты расчетов среднего квадратического отклонения приведены в табл. 1:
Таблица 1.
Среднее квадратическое отклонение:
Коэффициент вариации:
Следовательно, совокупность можно считать однородной.
Для этого определим интервалы для значений признака-фактора:
т.е. (37-4,1)¸(37+4,1); (37-2*4,1)¸(37+2*4,1) и (37-3*4,1)¸(37+3*4,1).
Первичная информация по признаку-фактору не подчиняется закону нормального распределения, однако это не является основанием для отказа использования корреляционно-регрессионного анализа (табл. 2). Таблица 2.
По данным таблицы, резко выделяющихся единиц в первичной информации нет.
Таблица 3. Пример. По имеющимся данным о группе рабочих предприятия определите тесноту связи между признаками Среднемесячная производительность труда и Премия по итогам года с помощью: 1) коэффициента Фехнера; 2) коэффициента ранговой корреляции Спирмена; 3) коэффициента линейной корреляции. Решение. Построим вспомогательную таблицу для определения необходимых значений, где х – Среднемесячная производительность труда (факторный признак), у – Премия по итогам года (результативный признак). Таблица Таблица для расчетов показателей тесноты связи
1)
2)
3)
3.Ранговый коэффициент корреляции Кендэла, как и ранговый коэффициент Спирмена, применяют с целью выявления взаимосвязей, как к количественным, так и к качественным признакам, если последние можно проранжировать. Формула для расчёта коэффициентов корреляции рангов Кендэла имеет вид:
где S=P+Q; P – число следующих наблюдений для переменной Y с большими значениями рангов; Q – число следующих наблюдений для переменной Y с меньшими значениями рангов.
Значения рангового коэффициента корреляции Кендэла изменяются в пределах от –1 до +1. При
4.Коэффициент конкордации (множественный коэффициент ранговой корреляции) применяется для измерения связи между двумя и более признаками при условии, что их можно проранжировать; определяется по формуле:
где m – количество признаков, между которыми устанавливается связь; n – число наблюдений; S – разность между суммой квадратов рангов и средним квадратом рангов. Значения коэффициента конкордации изменяются в пределах от 0 до +1; при значении больше 0,5 можно говорить о тесной связи между признаками. 5.Коэффициенты ассоциации и контингенции применяются для измерения связи между двумя качественными альтернативными признаками.
С этой целью строится четырёхклеточная таблица, которая показывает связь между двумя явлениями, каждое из которых обладает альтернативными признаками.
Например, обследуют группу населения одного из регионов России в отчётном периоде. I вопрос – о месте проживания (следует выбрать правильный ответ): 1. Проживаю в городе. 2. Проживаю в сельской местности. II вопрос – о принадлежности к полу (следует выбрать правильный ответ): 1. Мужчина. 2. Женщина.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2017-01-18; просмотров: 434; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.131.110.169 (0.221 с.) |
 ;
;
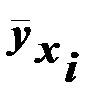 распределений признака Y, вычисленные при условии, что фактор X принимает некоторое определённое значение xi, называют условными средними. С изменением значения xi меняется и средняя
распределений признака Y, вычисленные при условии, что фактор X принимает некоторое определённое значение xi, называют условными средними. С изменением значения xi меняется и средняя 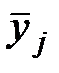 групповые значения результативного признака
групповые значения результативного признака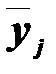
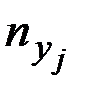 повторения в эмпирических данных результативного значения yj, а в итоговом столбце – частоты
повторения в эмпирических данных результативного значения yj, а в итоговом столбце – частоты 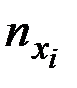 повторения значений xi.
повторения значений xi.




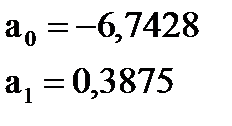


 в построенной модели показывает, что при увеличении стоимости автомобиля на 1000 долларов объём страховых выплат в среднем вырастает на 0,3875 тыс. долларов.
в построенной модели показывает, что при увеличении стоимости автомобиля на 1000 долларов объём страховых выплат в среднем вырастает на 0,3875 тыс. долларов. = f(x1, x2, …, xm)
= f(x1, x2, …, xm) .
. .
. показывают степень влияния каждого фактора на анализируемый показатель при фиксированном (среднем) значении всех других факторов.
показывают степень влияния каждого фактора на анализируемый показатель при фиксированном (среднем) значении всех других факторов. ), оценивающий степень тесноты связи между факторными значениями xi и расчетными результативными значениями
), оценивающий степень тесноты связи между факторными значениями xi и расчетными результативными значениями  ;
; ,
,  ,
,  ,
, ,
, , (25)
, (25) . При этом:
. При этом: r
r  1:
1: к единице свидетельствует о хорошей аппроксимации фактических данных полученной линейной связи
к единице свидетельствует о хорошей аппроксимации фактических данных полученной линейной связи  = a0 + a1x;
= a0 + a1x; означает, что построенная модель связи практического значения не имеет ввиду недостаточной тесноты связи между признаками X и Y, при которой менее 50% вариации признака Y объясняется влиянием фактора Х, и, следовательно, фактор Х влияет на вариацию Y в значительно меньшей степени, чем другие (неучтенные в модели) факторы.
означает, что построенная модель связи практического значения не имеет ввиду недостаточной тесноты связи между признаками X и Y, при которой менее 50% вариации признака Y объясняется влиянием фактора Х, и, следовательно, фактор Х влияет на вариацию Y в значительно меньшей степени, чем другие (неучтенные в модели) факторы. ), который показывает вероятность принятия ошибочного решения. Возможность ошибки вытекает из того факта, что для определения взаимосвязи используются данные не всей совокупности, а лишь ее части. Обычно
), который показывает вероятность принятия ошибочного решения. Возможность ошибки вытекает из того факта, что для определения взаимосвязи используются данные не всей совокупности, а лишь ее части. Обычно  .
. , (26)
, (26) ), которое определяется по таблице F- критерия с учетом принятого уровня значимости
), которое определяется по таблице F- критерия с учетом принятого уровня значимости  , представляющая собой среднее квадратическое отклонение эмпирических значений признака Y от теоретических:
, представляющая собой среднее квадратическое отклонение эмпирических значений признака Y от теоретических: (27)
(27) , выраженная в процентах:
, выраженная в процентах: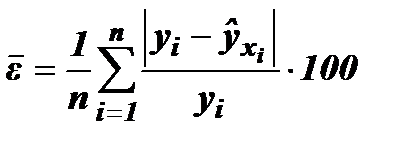 (28)
(28) и
и 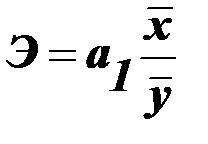 , который показывает, на сколько процентов изменяется в среднем результативный признак при изменении факторного признака на 1%.
, который показывает, на сколько процентов изменяется в среднем результативный признак при изменении факторного признака на 1%. , характеризующие отклонения i -ых наблюдений от значений
, характеризующие отклонения i -ых наблюдений от значений  , которые следует ожидать в среднем, можно сделать ряд практических выводов об эффективности экономической деятельности рассматриваемых хозяйствующих субъектов и выявить скрытые резервы их развития и повышения деловой активности. При этом наиболее значительный экономический интерес представляют наибольшие и наименьшие положительные и отрицательные отклонения
, которые следует ожидать в среднем, можно сделать ряд практических выводов об эффективности экономической деятельности рассматриваемых хозяйствующих субъектов и выявить скрытые резервы их развития и повышения деловой активности. При этом наиболее значительный экономический интерес представляют наибольшие и наименьшие положительные и отрицательные отклонения  .
. может использоваться для краткосрочного прогнозирования ожидаемых значений результативного признака Y в зависимости от тех или иных значений фактора Х.
может использоваться для краткосрочного прогнозирования ожидаемых значений результативного признака Y в зависимости от тех или иных значений фактора Х.

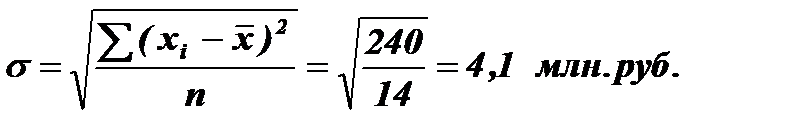

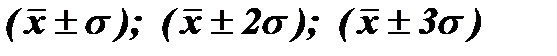 ,
, .
.

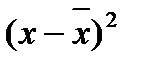
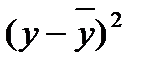
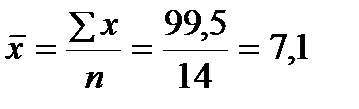 ;
; 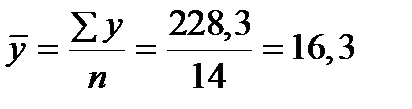 ;
; =
= 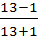 = 0,857 Þ связь тесная, прямая.
= 0,857 Þ связь тесная, прямая.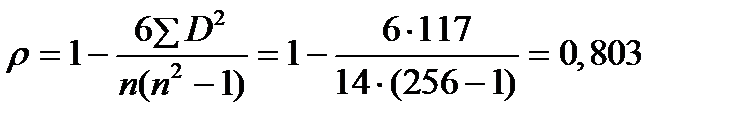 Þ связь тесная, прямая.
Þ связь тесная, прямая.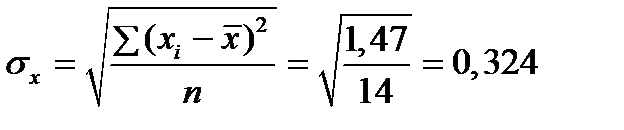 ;
; 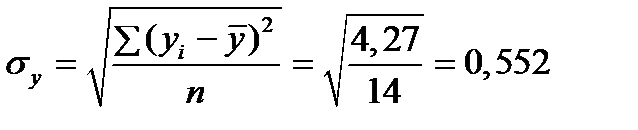 ;
; Þ связь заметная, прямая.
Þ связь заметная, прямая. , (31)
, (31)  >0,5 – связь существенная.
>0,5 – связь существенная.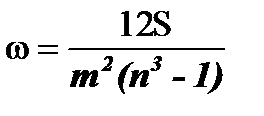 , (32)
, (32) 


