
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Алгоритм Least Recently Used (LRU)Содержание книги Похожие статьи вашей тематики
Поиск на нашем сайте
Данный алгоритм замещения страниц основан на следующем принципе: Замещается та страница, которая раньше всего использовалась. Для примера со строкой запросов: 1, 2, 3, 4, 1, 2, 5, 1, 2, 3, 4, 5 число отказов страниц равно всего 4. Однако следует иметь в виду, что использование системой информации о времени последнего обращения к странице требует хранения в каждом элементе таблицы страниц значения времени последнего обращения (time stamp). Каждый элемент таблицы страниц содержит счетчик. Каждый раз при обращении к странице через некоторый элемент таблицы страниц содержимое системных часов (clock) копируется в его поле счетчика. Если требуется изменение в конфигурации страниц, необходимо проанализировать поля счетчиков всех элементов таблицы страниц, чтобы определить, какую именно страницу следует заместить. Для определения элемента таблицы страниц с минимальным счетчиком требуется применить алгоритм поиска минимального элемента в массиве, сложность которого O(n),где n – длина таблицы страниц. Пример использования алгоритма замещения страниц LRU с той же строкой запроса, что и на рис. 9 и рис. 11 для других алгоритмов, приведен на рис. 12.
Рис. 12. Пример использования алгоритма замещения страниц LRU.
Для оптимизации данного алгоритма, чтобы избежать поиска минимального элемента таблицы страниц при каждом замещении страниц, используется стековая реализация – стек номеров страниц хранится в форме двухсвязного списка. При обращении к странице она перемещается в начало списка (для этого требуется изменить 6 указателей). Преимущества данной модификации алгоритма в том, что при замещении страниц не требуется поиска. На рис. 13 приведен пример использования стека в алгоритме LRU для хранения самых недавних обращений к страницам.
Рис. 13. Использование стека в алгоритме LRU для хранения самых недавних обращений к страницам. Алгоритмы, близкие к LRU Имеется несколько алгоритмов, близких к алгоритму LRU, в которых реализованы различные идеи улучшений или упрощений, направленные на то, чтобы уменьшить недостатки LRU. 1. Бит ссылки (reference bit). В данном алгоритме с каждой страницей связывается бит, первоначально равный 0. При обращении к странице бит устанавливается в 1. Далее, при необходимости замещения страниц, заменяется та страница, у которой бит равен 0 (если такая существует), т.е. страница, к которой не было обращений. Данная версия алгоритма позволяет избежать поиска по таблице страниц. Однако она, очевидно, менее оптимальна, чем LRU. 2. Второй шанс (second chance). В данной версии алгоритма используются ссылочный бит и показания часов, которые хранятся в каждом элементе таблицы страниц. Замещение страниц основано на показаниях часов. Если страница, которую следует заместить (по показаниям часов), имеет ссылочный бит, равный 1, то выполняются следующие действия: o Установить ссылочный бит в 0; o Оставить страницу в памяти; o Заместить следующую страницу (по показаниям часов), по тем же самым правилам. Данный алгоритм имеет следующее эвристическое обоснование. Странице, которая дольше всего не использовалась, как бы дается второй шанс на то, что она будет использована, т. е. делается эвристическое предположение, что, по мере возрастания времени, вероятность обращения к странице, к которой давно не было обращений, возрастает. Схема алгоритма второго шанса изображена на рис. 14.
Рис. 14. Алгоритм второго шанса. Алгоритмы со счетчиком Идея, родственная идее алгоритма LRU, - хранить счетчики числа обращений к каждой странице. На основе этой идеи существуют два алгоритма: · - Алгоритм Least Frequently Used (LFU):замещать страницы с минимальным значением счетчика (к которым было меньше всего обращений); · - Алгоритм Most Frequently Used (MFU):замещать страницы с максимальным значением счетчика. Данный алгоритм основан на соображении, что страница с минимальным счетчиком – возможно, лишь недавно загружена, и, видимо, в дальнейшем будет активно использоваться, поэтому она оставляется в памяти. Выделение фреймов До сих пор мы рассматривали алгоритмы замещения страниц при определенном числе фреймов, выделенных каждому процессу. Рассмотрим теперь стратегии выделения фреймов. При их выделении ОС исходит из того, чтобы каждому процессу выделить минимально необходимое число страниц. Однако различные аппаратные платформы имеют свои особенности, что тоже приходится учитывать. Например, в системе IBM 370 требуется 6 (!) страниц, чтобы обработать команду MOVE (пересылки) формата SS (Storage-Storage). В самом деле, длина команды - 6 байтов, так что она может размещается на двух соседних страницах. Кроме того, максимум две страницы требуются для обработки источника и максимум две страницы – для обработки получателя. Разумеется, подобный казус не может произойти в RISC -системах. В операционных системах используются две основных схемы выделения фреймов - фиксированное выделение и выделение по приоритетам. Фиксированное выделение фреймов. Наиболее простой вариант - равномерное распределение фреймов процессам. Например, если имеется 100 фреймов и 5 процессов, каждому выделяется по 20 страниц. Используется также пропорциональное распределение – выделять фреймы в соответствии со следующим принципом: если общее число фреймов m, размер процесса – s, а общий размер всех процессов – S, то общее число фреймов, выделенных процессу, равно: a = m * (s / S). Выделение по приоритетам. Принцип данного распределения фреймов следующий: применять схему пропорционального распределения, но используя приоритеты, а не размер. Если процесс генерирует отказ страницы, то для замещения выделяется фрейм из процесса с более низким приоритетом. Глобальное и локальное распределение. Глобальное замещение фреймов означает, что процесс выбирает фрейм для замещения среди всех существующих фреймов всех процессов, т.е. один процесс может взять фрейм у другого. Локальное замещение фреймов, наоборот, гарантирует, что каждый процесс выбирает фрейм для замещения только из числа выделенных ему фреймов. Thrashing Данный термин буквально означает метание, тряска. Если процессу не выделено достаточное число страниц, коэффициент отказов страниц очень высок. Это приводит к тому, что процесс занят в основном откачкой и подкачкой страниц. При этом ОС может сделать неверное заключение о низкой производительности использования процессора и, следовательно... принять решение об увеличении степени мультипрограммирования, т.е. о добавлении нового процесса к системе. Неформально, thrashing означает катастрофическую нехватку фреймов в основной памяти. На практике для пользователя это выглядит следующим образом (автор сам неоднократно испытывал подобные ощущения, вынужденный работать на SPARC -станции с очень малым объемом памяти): жесткий диск буквально "надрывается" от непрерывных обращений, а процесс исполняется крайне медленно. Интересно отметить, что SPARC -станция с 32 мегабайтами памяти и ОС Solaris успешно выдерживали эти экстремальные нагрузки (причем на данной конфигурации пропускалась достаточно большая Java- программа). Это говорит о высокой надежности системы Solaris. Другой реальный пример – использование ОС Windows XP (Service Pack 3) на компьютере с 512 мегабайтами памяти. При этом возникает почти такое же ощущение - сначала кажется, что неисправен жесткий диск, но затем сразу осознаешь, что все дело в нехватке памяти: самые простые программы, такие как Internet Explorer, Windows Explorer и др., будучи вызванными одновременно (что является обычной практикой) переполняют основную память и вынуждают операционную систему при любом дополнительном действии пользователя (даже при простом передвижении полосы прокрутки по именам файлов в Windows Explorer) непрерывной откачкой и подкачкой. На рис.15 приведен график зависимости использования процессора от коэффициента мультипрограммирования. При очень большом числе обрабатываемых процессов полезность использования процессора резко падает из-за постоянных откачек и подкачек. Это и есть thrashing.
Рис. 15. График зависимости использования процессора от коэффициента мультипрограммирования Модель рабочего множества Если более глубоко проанализировать ситуацию с thrashing, то возникает вопрос, с какой целью используется страничная организация. При использовании локальной модели распределения фреймов, процесс мигрирует от одной локальной модели к другой. Однако локальные модели различных процессов могут пересекаться. Выражаясь более простым языком, thrashing происходит, если сумма размеров локальных потребностей процессов в основной памяти больше общего размера памяти. Для борьбы с подобными явлениями в операционных системах для распределения фреймов используется модель рабочего множества. Обозначим через Рассмотрим WSSi (рабочее множество процесса Pi) - общее число обращений к страницам в самой недавней Если Если Если Вычислим величину Если D > m то Thrashing (m - общий размер памяти). Политика ОС по борьбе с thrashing ’ом заключается в том, чтобы, если D > m, приостановить один из процессов. Пример использования рабочего множества и вычисления WSSi приведен на рис. 16.
Рис.16. Пример использования рабочего множества. Страничная организация по требованию в Windows NT ОС Windows NT использует страничную организацию " по требованию" и кластеризацию, т.е. подкачку страниц, смежных с затребованной. Процессам выделяются минимальное и максимальное рабочие множества. Минимальное рабочее множество – это набор страниц, которые процесс гарантированно имеет в памяти. Процесс может иметь в памяти число страниц до максимума рабочего множества. Если объем свободной памяти в системе становится меньше некоторого порогового значения (threshold), то ОС выполняет сокращение рабочих множеств процессов (working set trimming). Сокращение рабочих множеств – это изъятие у процессов "лишних" страниц в оперативной памяти, которые превышают минимальный размер их рабочих множеств.
|
||||
|
|
Последнее изменение этой страницы: 2016-12-30; просмотров: 659; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 13.59.5.179 (0.011 с.) |





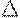 (рабочее множество) фиксированное число обращений к страницам.
(рабочее множество) фиксированное число обращений к страницам. , рассматриваем всю программу.
, рассматриваем всю программу.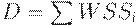 - общий объем требований фреймов всех процессов. Пусть m – размер основной памяти.
- общий объем требований фреймов всех процессов. Пусть m – размер основной памяти.



