
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Метод сигнального обучения ХэббаСодержание книги
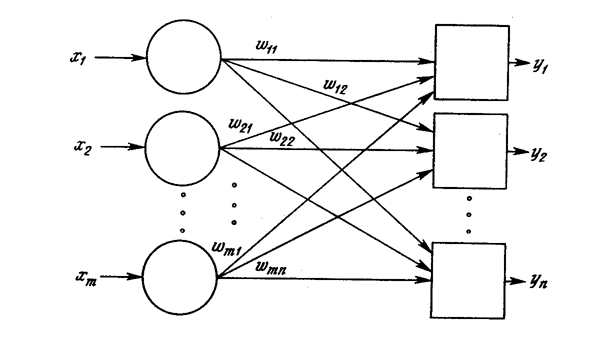
Поиск на нашем сайте Как мы видели, выход NET простого искусственного нейрона является взвешенной суммой его входов. Это может быть выражено следующим образом:
где NETj – выход NET нейрона j; OUTi – выход нейрона i;w ij – вес связи нейрона i с нейроном j. Можно показать, что в этом случае линейная многослойная сеть не является более мощной, чем однослойная сеть; рассматриваемые возможности сети могут быть улучшены только введением нелинейности в передаточную функцию нейрона. Говорят, что сеть, использующая сигмоидальную функцию активации и метод обучения Хэбба, обучается по сигнальному методу Хэбба. В этом случае уравнение Хэбба модифицируется следующим образом:
w ij(t +1) = w ij(t) + OUTi OUTj где w ij(t) – сила синапса от нейрона i к нейрону j в момент времени t; OUTi – выходной уровень пресинаптического нейрона равный F (NETi); OUTj – выходной уровень постсинаптического нейрона равный F (NET). Метод дифференциального обучения Хэбба Метод сигнального обучения Хэбба предполагает вычисление свертки предыдущих изменений выходов для определения изменения весов. Настоящий метод, называемый методом дифференциального обучения Хэбба, использует следующее равенство: w ij(t +1) = w ij(t) + [OUTi(t) – OUTi(t –1)][ OUTj(t) – OUTj(t –1)], где w ij(t) – сила синапса от нейрона i к нейрону j в момент времени t; OUTi(t) – выходной уровень пресинаптического нейрона в момент времени t; OUTj(t) – выходной уровень постсинаптического нейрона в момент времени t.
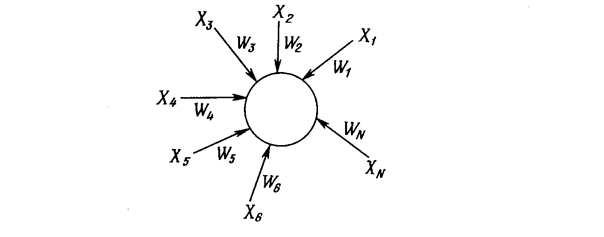
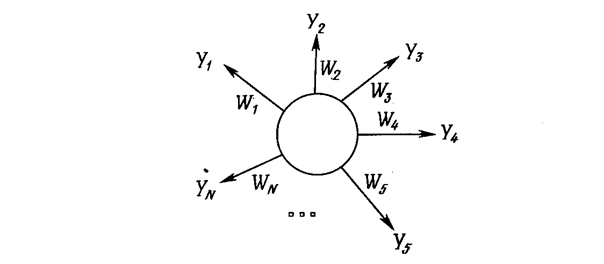
Рис. Б.1. Сеть «Инстар» Гроссберга ВХОДНЫЕ И ВЫХОДНЫЕ ЗВЕЗДЫ Много общих идей, используемых в искусственных нейронных сетях, прослеживаются в работах Гроссберга; в качестве примера можно указать конфигурации входных и выходных звезд [I], используемые во многих сетевых парадигмах. Входная звезда, как показано на рис. Б.1, состоит из нейрона, на который подается группа входов через синапсические веса. Выходная звезда, показанная на рис. Б.2, является нейроном, управляющим группой весов. Входные и выходные звезды могут быть взаимно соединены в сети любой сложности; Гроссберг рассматривает их как модель определенных биологических функций. Вид звезды определяет ее название, однако звезды обычно изображаются в сети иначе.
Рис. Б.2. Сеть «Аутстар» Гроссберга Обучение входной звезды Входная звезда выполняет распознавание образов, т. е. она обучается реагировать на определенный входной вектор Х и ни на какой другой. Это обучение реализуется путем настройки весов таким образом, чтобы они соответствовали входному вектору. Выход входной звезды определяется как взвешенная сумма ее входов, как это описано в предыдущих разделах. С другой точки зрения, выход можно рассматривать как свертку входного вектора с весовым вектором, меру сходства нормализованных векторов. Следовательно, нейрон должен реагировать наиболее сильно на входной образ, которому был обучен. Процесс обучения выражается следующим образом: w i(t +1) = w i(t) + a[ x i – w i(t)], где w i – вес входа х i; х i – i –й вход; a – нормирующий коэффициент обучения, который имеет начальное значение 0,1 и постепенно уменьшается в процессе обучения. После завершения обучения предъявление входного вектора Х будет активизировать обученный входной нейрон. Это можно рассматривать как единый обучающий цикл, если a установлен в 1, однако в этом случае исключается способность входной звезды к обобщению. Хорошо обученная входная звезда будет реагировать не только на определенный единичный вектор, но также и на незначительные изменения этого вектора. Это достигается постепенной настройкой нейронных весов при предъявлении в процессе обучения векторов, представляющих нормальные вариации входного вектора. Веса настраиваются таким образом, чтобы усреднить величины обучающих векторов, и нейроны получают способность реагировать на любой вектор этого класса. Обучение выходной звезды В то время как входная звезда возбуждается всякий раз при появлении определенного входного вектора, выходная звезда имеет дополнительную функцию; она вырабатывает требуемый возбуждающий сигнал для других нейронов всякий раз, когда возбуждается. Для того чтобы обучить нейрон выходной звезды, его веса настраиваются в соответствии с требуемым целевым вектором. Алгоритм обучения может быть представлен символически следующим образом: w i(t +1) = w i(t) + b[ y i – w i(t)], где b представляет собой нормирующий коэффициент обучения, который в начале приблизительно равен единице и постепенно уменьшается до нуля в процессе обучения. Как и в случае входной звезды, веса выходной звезды, постепенно настраиваются над множеством векторов, представляющих собой обычные вариации идеального вектора. В этом случае выходной сигнал нейронов представляет собой статистическую характеристику обучающего набора и может в действительности сходиться в процессе обучения к идеальному вектору при предъявлении только искаженных версий вектора. ОБУЧЕНИЕ ПЕРСЕПТРОНА В 1957 г. Розенблатт [4] разработал модель, которая вызвала большой интерес у исследователей. Несмотря на некоторые ограничения ее исходной формы, она стала основой для многих современных, наиболее сложных алгоритмов обучения с учителем. Персептрон является настолько важным, что вся гл. 2 посвящена его описанию; однако это описание является кратким и приводится в формате, несколько отличном от используемого в [4]. Персептрон является двухуровневой, нерекуррентной сетью, вид которой показан на рис. Б.3. Она использует алгоритм обучения с учителем; другими словами, обучающая выборка состоит из множества входных векторов, для каждого из которых указан свой требуемый вектор цели. Компоненты входного вектора представлены непрерывным диапазоном значений; компоненты вектора цели являются двоичными величинами (0 или 1). После обучения сеть получает на входе набор непрерывных входов и вырабатывает требуемый выход в виде вектора с бинарными компонентами.
Рис. Б.3. Однослоиная нейронная сеть Обучение осуществляется следующим образом: 1. Рандомизируются все веса сети в малые величины. 2. На вход сети подается входной обучающий вектор Х и вычисляется сигнал NET от каждого нейрона, используя стандартное выражение
3. Вычисляется значение пороговой функции активации для сигнала NET от каждого нейрона следующим образом: OUTj = 1, если NETj больше чем порог θ j, OUTj = 0 в противном случае. Здесь θ j представляет собой порог, соответствующий нейрону j (в простейшем случае, все нейроны имеют один и тот же порог). 4. Вычисляется ошибка для каждого нейрона посредством вычитания полученного выхода из требуемого выхода: errorj = targetj – OUTj. 5. Каждый вес модифицируется следующим образом: W ij(t +1) = w ij(t) +a x ierrorj. 6. Повторяются шаги со второго по пятый до тех пор, пока ошибка не станет достаточно малой. МЕТОД ОБУЧЕНИЯ УИДРОУ-ХОФФА Как мы видели, персептрон ограничивается бинарными выходами. Уидроу вместе со студентом университета Хоффом расширили алгоритм обучения персептрона на случай непрерывных выходов, используя сигмоидальную функцию [5,6]. Кроме того, они разработали математическое доказательство того, что сеть при определенных условиях будет сходиться к любой функции, которую она может представить. Их первая модель – Адалин – имеет один выходной нейрон, более поздняя модель – Мадалин – расширяет ее на случай с многими выходными нейронами. Выражения, описывающие процесс обучения Адалина, очень схожи с персептронными. Существенные отличия имеются в четвертом шаге, где используются непрерывные сигналы NET вместо бинарных OUT. Модифицированный шаг 4 в этом случае реализуется следующим образом: 4. Вычисляется ошибка для каждого нейрона посредством вычитания полученного выхода из требуемого выхода: errorj = targetj – NETj.
|
||
|
|
Последнее изменение этой страницы: 2016-12-16; просмотров: 452; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.141 (0.006 с.) |

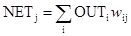
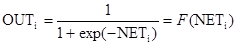
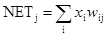 .
.


