
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Сеть встречного распространения полностьюСодержание книги
Поиск на нашем сайте
На рис. 4.4 показана сеть встречного распространения целиком. В режиме нормального функционирования предъявляются входные векторы Х и Y, и обученная сеть дает на выходе векторы X’ и Y’, являющиеся аппроксимациями соответственно для Х и Y. Векторы Х и Y предполагаются здесь нормализованными единичными векторами, следовательно, порождаемые на выходе векторы также будут иметь тенденцию быть нормализованными. В процессе обучения векторы Х и Y подаются одновременно и как входные векторы сети, и как желаемые выходные сигналы. Вектор Х используется для обучения выходов X’, а вектор Y – для обучения выходов Y’ слоя Гроссберга. Сеть встречного распространения целиком обучается с использованием того же самого метода, который описывался для сети прямого действия. Нейроны Кохонена принимают входные сигналы как от векторов X, так и от векторов Y. Но это неотличимо от ситуации, когда имеется один большой вектор, составленный из векторов Х и Y, и не влияет на алгоритм обучения.
Рис. 4.4. Полная сеть встречного распространения В качестве результирующего получается единичное отображение, при котором предъявление пары входных векторов порождает их копии на выходе. Это не представляется особенно интересным, если не заметить, что предъявление только вектора Х (с вектором Y, равным нулю) порождает как выходы X’, так и выходы Y’. Если F – функция, отображающая Х в Y’, то сеть аппроксимирует ее. Также, если F обратима, то предъявление только вектора Y (приравнивая Х нулю) порождает X’. Уникальная способность порождать функцию и обратную к ней делает сеть встречного распространения полезной в ряде приложений. Рис. 4.4 в отличие от первоначальной конфигурации [5] не демонстрирует противоток в сети, по которому она получила свое название. Такая форма выбрана потому, что она также иллюстрирует сеть без обратных связей и позволяет обобщить понятия, развитые в предыдущих главах. ПРИЛОЖЕНИЕ: СЖАТИЕ ДАННЫХ В дополнение к обычным функциям отображения векторов встречное распространение оказывается полезным и в некоторых менее очевидных прикладных областях. Одним из наиболее интересных примеров является сжатие данных. Сеть встречного распространения может быть использована для сжатия данных перед их передачей, уменьшая тем самым число битов, которые должны быть переданы. Допустим, что требуется передать некоторое изображение. Оно может быть разбито на подизображения S, как показано на рис. 4.5. Каждое подизображение разбито на пиксели (мельчайшие элементы изображения). Тогда каждое подизображение является вектором, элементами которого являются пиксели, из которых состоит подизображение. Допустим для простоты, что каждый пиксель – это единица (свет) или нуль (чернота). Если в подизображении имеется п пикселей, то для его передачи потребуется п бит. Если допустимы некоторые искажения, то для передачи типичного изображения требуется существенно меньшее число битов, что позволяет передавать изображения быстрее. Это возможно из-за статистического распределения векторов подизображений. Некоторые из них встречаются часто, тогда как другие встречаются так редко, что могут быть грубо аппроксимированы. Метод, называемый векторным квантованием, находит более короткие последовательности битов, наилучшим образом представляющие эти подизображения.
Рис. 4.5. Система сжатия изображений. Сеть встречного распространения может быть использована для выполнения векторного квантования. Множество векторов подизображений используется в качестве входа для обучения слоя Кохонена по методу аккредитации, когда лишь выход одного нейрона равен 1. Веса слоя Гроссберга обучаются выдавать бинарный код номера того нейрона Кохонена, выход которого равен 1. Например, если выходной сигнал нейрона 7 равен 1 (а все остальные равны 0), то слой Гроссберга будет обучаться выдавать 00...000111 (двоичный код числа 7). Это и будет являться более короткой битовой последовательностью передаваемых символов. На приемном конце идентичным образом обученная сеть встречного распространения принимает двоичный код и реализует обратную функцию, аппроксимирующую первоначальное подизображение. Этот метод применялся как к речи, так и к изображениям, с коэффициентом сжатия данных от 10:1 до 100:1. Качество было ' приемлемым, хотя некоторые искажения данных на приемном конце неизбежны. ОБСУЖДЕНИЕ Роберт Хехт-Нильсон, создатель сети встречного распространения (СВР), осознавал ее ограничения: «СВР, конечно, уступает обратному распространению в большинстве приложений, связанных с сетевыми отображениями. Ее преимущества в том, что она проста и дает хорошую статистическую модель для своей среды входных векторов» ([5],с. 27).
К этому можно добавить, что сеть встречного распространения быстро обучается, и при правильном использовании она может сэкономить значительное количество машинного времени. Она полезна также для быстрого моделирования систем, где большая точность обратного распространения вынуждает отдать ему предпочтение в окончательном варианте, но важна быстрая начальная аппроксимация. Возможность порождать функцию и обратную к ней также нашло применение в ряде систем. Литература 13. DeSieno D. 1988. Adding a conscience to competitive learning Proceedings of the IEEE International Conference on Neural Networks, pp. 117-24. San Diego, CA: SOS Printing. 14. Qrossberg S. 1969. Some networks that can learn, remember and reproduce any number of complicated space-time patterns. Journal of Mathematics and Mechanics, 19:53-91. 15. Grossberg S. 1971. Embedding fields: Underlying philosophy, mathematics, and applications of psyho-logy, phisiology, and anatomy. Journal of Cybernetics, 1:28-50. 16. Grossberg S. 1982. Studies of mind and brain. Boston: Reidel. 17. Hecht-Nielsen R. 1987a. Counterpropagation networks. In Proceedings of the IEEE First International Conference on Newral Networks, eds. M. Caudill and C. Butler, vol. 2, pp. 19-32. San Diego, CA: SOS Printing. 18. Hecht-Nielsen R. 1987b. Counterpropagation networks. Applied Optics 26(23): 4979-84. 19. Hecht-Nielsen R. 1988. Applications of Counterpropagation networks. Newral Networks 1: 131-39. 20. Kohonen Т. 1988. Self-organization and associative memory. 2d ed. New-York, Springer-Verlag. Глава 5. Стохастические методы полезны как для обучения искусственных нейронных сетей, так и для получения выхода от уже обученной сети. Стохастические методы обучения приносят большую пользу, позволяя исключать локальные минимумы в процессе обучения. Но с ними также связан ряд проблем. Использование стохастических методов для получения выхода от уже обученной сети рассматривалось в работе [2] и обсуждается нами в гл. 6. Данная глава посвящена методам обучения сети. ИСПОЛЬЗОВАНИЕ ОБУЧЕНИЯ Искусственная нейронная сеть обучается посредством некоторого процесса, модифицирующего ее веса. Если обучение успешно, то предъявление сети множества входных сигналов приводит к появлению желаемого множества выходных сигналов. Имеется два класса обучающих методов: детерминистский и стохастический. Детерминистский метод обучения шаг за шагом осуществляет процедуру коррекции весов сети, основанную на использовании их текущих значений, а также величин входов, фактических выходов и желаемых выходов. Обучение персептрона является примером подобного детерминистского подхода (см. гл. 2). Стохастические методы обучения выполняют псевдослучайные изменения величин весов, сохраняя те изменения, которые ведут к улучшениям. Чтобы увидеть, как это может быть сделано, рассмотрим рис. 5.1, на котором изображена типичная сеть, в которой нейроны соединены с помощью весов. Выход нейрона является здесь взвешенной суммой его входов, которая, преобразована с помощью нелинейной функции (подробности см. гл. 2). Для обучения сети может быть использована следующая процедура: 1. Выбрать вес случайным образом и подкорректировать его на небольшое случайное Предъявить множество входов и вычислить получающиеся выходы. 2. Сравнить эти выходы с желаемыми выходами и вычислить величину разности между ними. Общепринятый метод состоит в нахождении разности между фактическим и желаемым выходами для каждого элемента обучаемой пары, возведение разностей в квадрат и нахождение суммы этих квадратов. Целью обучения является минимизация этой разности, часто называемой целевой функцией.
3. Выбрать вес случайным образом и подкорректировать его на небольшое случайное значение. Если коррекция помогает (уменьшает целевую функцию), то сохранить ее, в противном случае вернуться к первоначальному значению веса. 4. Повторять шаги с 1 до 3 до тех пор, пока сеть не будет обучена в достаточной степени.
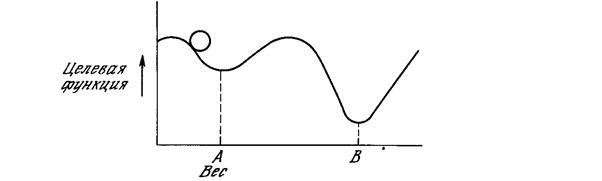
Рис. 5.1. Двухслойная сеть без обратных связей Этот процесс стремится минимизировать целевую функцию, но может попасть, как в ловушку, в неудачное решение. На рис. 5.2 показано, как это может иметь место в системе с единственным весом. Допустим, что первоначально вес взят равным значению в точке А. Если случайные шаги по весу малы, то любые отклонения от точки А увеличивают целевую функцию и будут отвергнуты. Лучшее значение веса, принимаемое в точке В, никогда не будет найдено, и система будет поймана в ловушку локальным минимумом, вместо глобального минимума в точке В. Если же случайные коррекции веса очень велики, то как точка А, так и точка В будут часто посещаться, но то же самое будет иметь место и для каждой другой точки. Вес будет меняться так резко, что он никогда не установится в желаемом минимуме.
Рис.5.2. Проблема локальных минимумов. Полезная стратегия для избежания подобных проблем состоит в больших начальных шагах и постепенном уменьшении размера среднего случайного шага. Это позволяет сети вырываться из локальных минимумов и в то же время гарантирует окончательную стабилизацию сети. Ловушки локальных минимумов досаждают всем алгоритмам обучения, основанным на поиске минимума, включая персептрон и сети обратного распространения, и представляют серьезную и широко распространенную трудность, которой часто не замечают. Стохастические методы позволяют решить эту проблему. Стратегия коррекции весов, вынуждающая веса принимать значение глобального оптимума в точке В, возможна. В качестве объясняющей аналогии предположим, что на рис. 5.2 изображен шарик на поверхности в коробке. Если коробку сильно потрясти в горизонтальном направлении, то шарик будет быстро перекатываться от одного края к другому. Нигде не задерживаясь, в каждый момент шарик будет с равной вероятностью находиться в любой точке поверхности. Если постепенно уменьшать силу встряхивания, то будет достигнуто условие, при котором шарик будет на короткое время «застревать» в точке В. При еще более слабом встряхивании шарик будет на короткое время останавливаться как в точке А, так и в точке В. При непрерывном уменьшении силы встряхивания будет достигнута критическая точка, когда сила встряхивания достаточна для перемещения шарика из точки А в точку В, но недостаточна для того, чтобы шарик мог вскарабкаться из В в А. Таким образом, окончательно шарик остановится в точке глобального минимума, когда амплитуда встряхивания уменьшится до нуля.
Искусственные нейронные сети могут обучаться по существу тем же самым образом посредством случайной коррекции весов. Вначале делаются большие случайные коррекции с сохранением только тех изменений весов, которые уменьшают целевую функцию. Затем средний размер шага постепенно уменьшается, и глобальный минимум в конце концов достигается. Это сильно напоминает отжиг металла, поэтому для ее описания часто используют термин «имитация отжига». В металле, нагретом до температуры, превышающей его точку плавления, атомы находятся в сильном беспорядочном движении. Как и во всех физических системах, атомы стремятся к состоянию минимума энергии (единому кристаллу в данном случае), но при высоких температурах энергия атомных движений препятствует этому. В процессе постепенного охлаждения металла возникают все более низкоэнергетические состояния, пока в конце концов не будет достигнуто наинизшее из возможных состояний, глобальный минимум. В процессе отжига распределение энергетических уровней описывается следующим соотношением: P (e) = exp(– e / kT) (5.1) где Р (е) – вероятность того, что система находится в состоянии с энергией е; k – постоянная Больцмана; Т – температура по шкале Кельвина. При высоких температурах Р(е) приближается к единице для всех энергетических состояний. Таким образом, высокоэнергетическое состояние почти столь же вероятно, как и низкоэнергетическое. По мере уменьшения температуры вероятность высокоэнергетических состояний уменьшается по сравнению с низкоэнергетическими. При приближении температуры к нулю становится весьма маловероятным, чтобы система находилась в высокоэнергетическом состоянии. Больцмановское обучение Этот стохастический метод непосредственно применим к обучению искусственных нейронных сетей: 1. Определить переменную Т, представляющую искусственную температуру. Придать Т большое начальное значение. 2. Предъявить сети множество входов и вычислить выходы и целевую функцию. 3. Дать случайное изменение весу и пересчитать выход сети и изменение целевой функции в соответствии со сделанным изменением веса. 4. Если целевая функция уменьшилась (улучшилась), то сохранить изменение веса. Если изменение веса приводит к увеличению целевой функции, то вероятность сохранения этого изменения вычисляется с помощью распределения Больцмана: P (c) = exp(– c / kT) (5.2) где Р (с) – вероятность изменения с в целевой функции; k – константа, аналогичная константе Больцмана, выбираемая в зависимости от задачи; Т – искусственная температура. Выбирается случайное число r из равномерного распределения от нуля до единицы. Если Р(с) больше, чем r, то изменение сохраняется, в противном случае величина веса возвращается к предыдущему значению.
Это позволяет системе делать случайный шаг в направлении, портящем целевую функцию, позволяя ей тем самым вырываться из локальных минимумов, где любой малый шаг увеличивает целевую функцию. Для завершения больцмановского обучения повторяют шаги 3 и 4 для каждого из весов сети, постепенно уменьшая температуру Т, пока не будет достигнуто допустимо низкое значение целевой функции. В этот момент предъявляется другой входной вектор и процесс обучения повторяется. Сеть обучается на всех векторах обучающего множества, с возможным повторением, пока целевая функция не станет допустимой для всех них. Величина случайного изменения веса на шаге 3 может определяться различными способами. Например, подобно тепловой системе весовое изменение w может выбираться в соответствии с гауссовским распределением: P (w) = exp(– w 2/ T 2) (5.2)
где P(w) – вероятность изменения веса на величину w, Т – искусственная температура. Такой выбор изменения веса приводит к системе, аналогичной [З]. Так как нужна величина изменения веса Δ w, а не вероятность изменения веса, имеющего величину w, то метод Монте-Карло может быть использован следующим образом: 1. Найти кумулятивную вероятность, соответствующую P (w). Это есть интеграл от P(w) в пределах от 0 до w. Так как в данном случае P (w) не может быть проинтегрирована аналитически, она должна интегрироваться численно, а результат необходимо затабулировать. 2. Выбрать случайное число из равномерного распределения на интервале (0,1). Используя эту величину в качестве значения P(w}, найти в таблице соответствующее значение для величины изменения веса. Свойства машины Больцмана широко изучались. В работе [1] показано, что скорость уменьшения температуры должна быть обратно пропорциональна логарифму времени, чтобы была достигнута сходимость к глобальному минимуму. Скорость охлаждения в такой системе выражается следующим образом:
где T (t) – искусственная температура как функция времени; Т 0 – начальная искусственная температура; t – искусственное время. Этот разочаровывающий результат предсказывает очень медленную скорость охлаждения (и данные вычисления). Этот вывод подтвердился экспериментально. Машины Больцмана часто требуют для обучения очень большого ресурса времени. Обучение Коши В работе [6] развит метод быстрого обучения подобных систем. В этом методе при вычислении величины шага распределение Больцмана заменяется на распределение Коши. Распределение Коши имеет, как показано на рис. 5.3, более длинные «хвосты», увеличивая тем самым вероятность больших шагов. В действительности распределение Коши имеет бесконечную (неопределенную) дисперсию. С помощью такого простого изменения максимальная скорость уменьшения температуры становится обратно пропорциональной линейной величине, а не логарифму, как для алгоритма обучения Больцмана. Это резко уменьшает время обучения. Эта связь может быть выражена следующим образом:
Распределение Коши имеет вид
где Р (х) есть вероятность шага величины х.
Рис. 5.3. Распределение Коши и распределение Больцмана В уравнении (5.6) Р (х) может быть проинтегрирована стандартными методами. Решая относительно х, получаем x c = r T (t) tg(P (x)), (5.7) где r – коэффициент скорости обучения; х c – изменение веса. Теперь применение метода Монте Карло становится очень простым. Для нахождения х в этом случае выбирается случайное число из равномерного распределения на открытом интервале (–p/2, p/2) (необходимо ограничить функцию тангенса). Оно подставляется в формулу (5.7) в качестве Р (х), и с помощью текущей температуры вычисляется величина шага.
|
|||||||||
|
|
Последнее изменение этой страницы: 2016-12-16; просмотров: 392; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.117.254.202 (0.014 с.) |




 (5.4)
(5.4) (5.5)
(5.5) (5.6)
(5.6)



