
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Инициализация весовых векторов ТСодержание книги
Поиск на нашем сайте
Из ранее рассмотренного примера обучения сети можно было видеть, что правило двух третей приводит к вычислению вектора С как функции И между входным вектором Х и выигравшим соревнование запомненным вектором Т j. Следовательно, любая компонента вектора С будет равна единице в том случае, если соответствующие компоненты обоих векторов равны единице. После обучения эти компоненты вектора Т j остаются единичными; все остальные устанавливаются в нуль. Это объясняет, почему веса t ij должны инициализироваться единичными значениями. Если бы они были проинициализированы нулевыми значениями, все компоненты вектора С были бы нулевыми независимо от значений компонент входного вектора, и обучающий алгоритм предохранял бы веса от изменения их нулевых значений. Обучение может рассматриваться как процесс «сокращения» компонент запомненных векторов, которые не соответствуют входным векторам. Этот процесс необратим, если вес однажды установлен в нуль, обучающий алгоритм никогда не восстановит его единичное значение. Это свойство имеет важное отношение к процессу обучения. Предположим, что группа точно соответствующих векторов должна быть классифицирована к одной категории, определяемой возбуждением одного нейрона в слое распознавания. Если эти вектора последовательно предъявляются сети, при предъявлении первого будет распределяться нейрон распознающего слоя, его веса будут обучены с целью соответствия входному вектору. Обучение при предъявлении остальных векторов будет приводить к обнулению весов в тех позициях, которые имеют нулевые значения в любом из входных векторов. Таким образом, запомненный вектор представляет собой логическое пересечение всех обучающих векторов и может включать существенные характеристики данной категории весов. Новый вектор, включающий только существенные характеристики, будет соответствовать этой категории. Таким образом, сеть корректно распознает образ, никогда не виденный ранее, т. е. реализуется возможность, напоминающая процесс восприятия человека. Настройка весовых векторов Вj Выражение, описывающее процесс настройки весов (выражение (8.6) повторено здесь для справки) является центральным для описания процесса функционирования сетей APT.
Сумма в знаменателе представляет собой количество единиц на выходе слоя сравнения. Эта величина может быть рассмотрена как «размер» этого вектора. В такой интерпретации «большие» векторы С производят более маленькие величины весов b ij, чем «маленькие» вектора С. Это свойство самомасштабирования делает возможным разделение двух векторов в случае, когда один вектор является поднабором другого; т. е. когда набор единичных компонент одного вектора составляет подмножество единичных компонент другого. Чтобы продемонстрировать проблему, возникающую при отсутствии масштабирования, используемого в выражении (8.6), предположим, что сеть обучена двум приведенным ниже входным векторам, при этом каждому распределен нейрон в слое распознавания. Заметим, что Х 1 является поднабором Х 2. В отсутствие свойства масштабирования веса b ij и t ij получат значения, идентичные значениям входных векторов. Если начальные значения выбраны равными 1,0, веса образов будут иметь следующие значения: Если Х прикладывается повторно, оба нейрона в слое распознавания получают одинаковые активации; следовательно, нейрон 2, ошибочный нейрон, выиграет конкуренцию. Кроме выполнения некорректной классификации, может быть нарушен процесс обучения. Так как Т 2 равно 1 1 1 0 0, только первая единица соответствует единице входного вектора, и С устанавливается в 1 0 0 0 0, критерий сходства удовлетворяется и алгоритм обучения устанавливает вторую и третью единицы векторов Т 2 и В 2 в нуль, разрушая запомненный образ. Масштабирование весов b ij предотвращает это нежелательное поведение. Предположим, что в выражении (8.2) используется значение L =2, тем самым определяя следующую формулу:
Значения векторов будут тогда стремиться к величинам Подавая на вход сети вектор Х 1, получим возбуждающее воздействие 1,0 для нейрона 1 в слое распознавания и ½ для нейрона 2; таким образом, нейрон 1 (правильный) выиграет соревнование. Аналогично предъявление вектора Х 2 вызовет уровень возбуждения 1,0 для нейрона 1 и 3/2 для нейрона 2, тем самым снова правильно выбирая победителя. Инициализация весов b ij Инициализация весов b ij малыми значениями является существенной для корректного функционирования систем APT. Если они слишком большие, входной вектора который ранее был запомнен, будет скорее активизировать несвязанный нейрон, чем ранее обученный. Выражение (8.1), определяющее начальные значения весов, повторяется здесь для справки
Установка этих весов в малые величины гарантирует, что несвязанные нейроны не будут получать возбуждения большего, чем обученные нейроны в слое распознавания. Используя предыдущий пример с L =2, т =5 и b ij<1/3, произвольно установим b ij=1/6. С такими весами предъявление вектора, которому сеть была ранее обучена, приведет к более высокому уровню активации для правильно обученного нейрона в слое распознавания, чем для несвязанного нейрона. Например, для несвязанного нейрона Х 1 будет производить возбуждение 1/6, в то время как Х 2 будет производить возбуждение ½; и то и другое ниже возбуждения для обученных нейронов. Поиск. Может показаться, что в описанных алгоритмах отсутствует необходимость наличия фазы поиска за исключением случая, когда для входного вектора должен быть распределен новый несвязанный нейрон. Это не совсем так; предъявление входного вектора, сходного, но не абсолютно идентичного одному из запомненных образов, может при первом испытании не обеспечить выбор нейрона слоя распознавания с уровнем сходства большим р, хотя такой нейрон будет существовать. Как и в предыдущем примере, предположим, что сеть обучается следующим двум векторам: X 1 = 1 0 0 0 0 X 2 = 1 1 1 0 0 с векторами весов В i, обученными следующим образом B 1 = 1 0 0 0 0 B 2 = ½ ½ ½ 0 0 Теперь приложим входной вектор X 3 = 1 1 0 0 0. В этом случае возбуждение нейрона 1 в слое распознавания будет 1,0, а нейрона 2 только 2/3. Нейрон 1 выйдет победителем (хотя он не лучшим образом соответствует входному вектору), вектор С получит значение 1 1 0 0 0, S будет равно ½. Если уровень сходства установлен в 3/4, нейрон 1 будет заторможен и нейрон 2 выиграет состязание. С станет равным 1 1 0 0 0, S станет равным 1, критерий сходства будет удовлетворен и поиск закончится. Теоремы APT В работе [2] доказаны некоторые теоремы, показывающие характеристики сетей APT. Четыре результата, приведенные ниже, являются одними из наиболее важных: 1. После стабилизации процесса обучения предъявление одного из обучающих векторов (или вектора с существенными характеристиками категории) будет активизировать требуемый нейрон слоя распознавания без поиска. Эта характеристика «прямого доступа» определяет быстрый доступ к предварительно изученным образам. 2. Процесс поиска является устойчивым. После определения выигравшего нейрона в сети не будет возбуждений других нейронов в результате изменения векторов выхода слоя сравнения С; только сигнал сброса может вызвать такие изменения. 3. Процесс обучения является устойчивым. Обучение не будет вызывать переключения с одного возбужденного нейрона слоя распознавания на другой. 4. Процесс обучения конечен. Любая последовательность произвольных входных векторов будет производить стабильный набор весов после конечного количества обучающих серий; повторяющиеся последовательности обучающих векторов не будут приводить к циклическому изменению весов. ЗАКЛЮЧЕНИЕ Сети APT являются интересным и важным видом систем. Они способны решить дилемму стабильности-пластичности и хорошо работают с других точек зрения. Архитектура APT сконструирована по принципу биологического подобия; это означает, что ее механизмы во многом соответствуют механизмам мозга (как мы их понимаем). Однако они могут оказаться не в состоянии моделировать распределенную память, которую многие рассматривают как важную характеристику функций мозга. Экземпляры APT представляют собой «бабушкины узелки»; потеря одного узла разрушает всю память. Память мозга, напротив, распределена по веществу мозга, запомненные образы могут часто пережить значительные физические повреждения мозга без полной их потери.
Кажется логичным изучение архитектур, соответствующих нашему пониманию организации и функций мозга. Человеческий мозг представляет существующее доказательство того факта, что решение проблемы распознавания образов возможно. Кажется разумным эмулировать работу мозга, если мы хотим повторить его работу. Однако контраргументом является история полетов; человек не смог оторваться от земли до тех пор, пока не перестал имитировать движения крыльев и полет птиц. Литература 1. Carpenter G., Grossberg S. 1986. Neural dynamics of category learning and recognition: Attention; memory consolidation and amnesia. In Brain Structure, Learning and Memory (AAAS Symposium Series), eds. J. Davis., R. Newburgh and E. Wegman. 2. Carpenter G., Grossberg S. 1987. A massively parallel architecture for a self-organizing neural pattern recognition machine. Computing Vision. Graphics, and Image Processing 37:54-115. 3. Carpenter G., Grossberg S. 1987 ART-2: Self-organization of stable category recognition codes for analog input patterns. Applied Optics 26(23):4919-30. 4. Crossberg S. 1987. Competitive learning: From interactive activation to adaptive resonanse. Cognitive Science 11:23-63. 5. Lippman R. P. 1987. An introduction to computing with neurals nets. IEEE Transactions on Acosufics, Speech and Signal Processing, April, pp. 4-22. Глава 9. Использование и обучение нейронных сетей требует в основном двух типов операций над данными: вычислений и передачи данных. Вычислительные функции легко и просто выполняются электронными системами. Элементы интегральных цепей работают в наносекундных интервалах. Кроме того, они имеют размеры, измеряемые в микронах, и могут иметь стоимость менее сотой цента за вентиль. Задачи передачи данных решаются не просто. Электронные сигналы в интегральных сетях требуют наличия конденсаторов для передачи сигналов от вентиля к вентилю. Хотя конденсаторы имеют микронные размеры, занимаемое пространство (с учетом пространства, необходимого для изоляции одного конденсатора от другого) может стать настолько большим, что на пластине кремния не останется места для размещения вычислительных цепей. Несмотря на то, что существует технология реализации обыкновенных цифровых компьютеров в виде больших функциональных блоков с относительно небольшим количеством конденсаторов, эта технология не годится в случае массового параллелизма. Аналогичное решение для искусственных нейронных сетей в настоящее время неизвестно. Мощность нейронных сетей определяется большим количеством связей; взятые отдельно элементы имеют относительно малые вычислительные возможности.
Серьезную проблему представляет достижение требуемой связанности в электронных цепях. В [10] предполагается, что плотность конденсаторов в двумерной системе должна уменьшаться обратно пропорционально квадрату расстояния от нейрона-источника; в противном случае отсутствует возможность реализации системы в виде интегральных цепей. Это ограничение имеет особое значение при реализации сетей с полными взаимными связями. Реализация нейронных сетей в виде оптических систем позволяет решить эту проблему. Взаимное соединение нейронов с помощью световых лучей не требует изоляции между сигнальными путями, световые потоки могут проходить один через другой без взаимного влияния. Более того, сигнальные пути могут быть расположены в трех измерениях. (Интегральные цепи являются существенно планарными с некоторой рельефностью, обусловленной множеством слоев.) Плотность путей передачи ограничена только размерами источников света, их дивергенцией и размерами детектора. Потенциально эти размеры могут иметь величину в несколько микрон. Наконец, все сигнальные пути могут работать одновременно, тем самым обеспечивая огромный темп передачи данных. В результате система способна обеспечить полный набор связей, работающих со скоростью света. Оптические нейронные сети могут также обеспечить важные преимущества при проведении вычислений. Величина синаптических связей может запоминаться в голограммах с высокой степенью плотности; некоторые оценки дают теоретический предел в 1012 бит на кубический сантиметр. Хотя такие значения на практике не достигнуты, существующий уровень плотности памяти очень высок. Кроме того, веса могут модифицироваться в процессе работы сети, образуя полностью адаптивную систему. Учитывая эти преимущества, можно задать вопрос, почему наряду с оптическими нейронными сетями вообще рассматриваются другие способы реализации. К сожалению, возникает множество практических проблем при попытках оптической реализации нейронных сетей. Оптические устройства имеют собственные физические характеристики, часто не соответствующие требованиям искусственных нейронных сетей. Хотя они в действительности пригодны для обработки изображений, изображения от оптических нейронных сетей, полученные до настоящего времени, были разочаровывающе плохими. Однако достаточно взглянуть на первые пробы телевизионных изображений, чтобы понять, какой огромный прогресс возможен в повышении качества изображения. Несмотря на эти трудности, а также на такие проблемы, как стоимость, размеры и критичность к ориентации, потенциальные возможности оптических систем побуждали (и побуждают) попытки проведения интенсивных и широких исследований. В этой области происходят стремительные изменения и в ближайшее время ожидаются важные улучшения.
Многие изучаемые конфигурации оптических нейронных сетей можно разделить на две категории, рассмотренные в данной главе: векторно-матричные умножители и голографические корреляторы. Заметим, что детальное описание вопросов оптической физики выходит за рамки данной работы. Вместо этого приведено качественное описание работы систем и взгляд автора на достижения в этой области.
|
|||||||||
|
|
Последнее изменение этой страницы: 2016-12-16; просмотров: 223; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.144.15.34 (0.013 с.) |

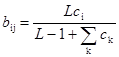 (8.6)
(8.6)
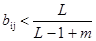 для всех i, j, (8.1)
для всех i, j, (8.1)


