Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Гипотеза — модель — решение.Содержание книги
Поиск на нашем сайте
Хранилища данных (курс лекций)
СОДЕРЖАНИЕ Введение. 2 Эволюция корпоративных информационных систем.. 3 Общие свойства хранилищ.. 8 Ориентированность на предметную область. 8 Интегрированность. 8 Зависимость от времени. 9 Постоянство. 9 Данные хранилища. 10 Источники данных. 10 Хранилище данных (в узком смысле) 11 Оперативный склад данных (Operational Data Store - ODS) 11 Витрины данных (Data mart) 11 Метаданные. 12 Компоненты хранилища. 12 Подсистема загрузки данных. 13 Подсистема обработки запросов и представления данных. 13 Подсистема администрирования хранилища. 13 Методика (методология) построения хранилищ данных. 14 Постановка задачи. 15 Системно-аналитическое обследование. 15 Техническое задание. 15 Проектирование. 15 Автоматизируемые процессы и функции. 16 Информационное обеспечение. 16 Компонентная архитектура. 18 Техническая архитектура. 19 Реализация. 19 Внедрение. 19 Выбор метода реализации Хранилищ данных. 19 Продукция Microsoft 21 Продукция Sybase. 23 Продукция Oracle. 26 Выбор продукта. 29 Что такое OLAP. 5 Многомерные кубы.. 35 Некоторые термины и понятия. 39 Типичная структура хранилищ данных. 40 Таблица фактов. 41 Таблицы измерений. 43 OLAP на клиенте и на сервере. 47 Технические аспекты многомерного хранения данных. 48 Условные сокращения и обозначения. 55 Словарь. 55 Список использованных источников. 57
Введение Эффективное управление крупным и средним бизнесом сегодня немыслимо без применения передовых информационных технологий — систем поддержки принятия решений (СППР). Процесс управления сводится к решению 3 задач: · Где мы находимся? · Куда мы хотим прийти? · Как мы туда попадем? Процесс управления — итерационный характер (принятие решения — применение управляющего воздействия — оценка состояния системы — оценка правильности выбранного решения — при наличии отклонений снова принятие решения). Современные информационные технологии позволяют аналитику формулировать и решать следующие классы: · Аналитические (вычисление заданных показателей и статистических характеристик). · Визуализация данных · Добыча знаний (data mining —проверка статистических гипотез, кластеризация, нахождение ассоциаций и временных шаблонов и т.п.)
· Имитационные (проведение на ЭВМ экспериментов на моделях, описывающих поведение сложных систем, например, в интервалы времени для анализа возможных последствий принятия того или иного решения) · Синтез управления (для определения допустимых управляющих воздействий, обеспечивающих достижение заданной цели, оценка достижимости цели, определение множества возможных управляющих воздействий) · Оптимизационные (интеграция имитационных, управленческих, оптимизационных и статистических методов моделирования и прогнозирования, выбор наиболее эффективного решения). Однако в настоящее время нет информационных средств для решения всех задач в комплексе. Бизнес — это сложный объект, который состоит из множества различных по свойствам подсистем, между которыми действует большое число разнородных связей. В кибернетике такие объекты получили название сложных систем, а методы их изучения — системным анализом (эта наука развивается с начала 40-х гг. в период 2-й мировой войны). Общая с точки зрения теории познания триада имеет вид: Что такое OLAP Системы поддержки принятия решений обычно обладают средствами предоставления пользователю агрегатных данных для различных выборок из исходного набора в удобном для восприятия и анализа виде. Как правило, такие агрегатные функции образуют многомерный (и, следовательно, нереляционный) набор данных (нередко называемый гиперкубом или метакубом), оси которого содержат параметры, а ячейки — зависящие от них агрегатные данные1. Вдоль каждой оси данные могут быть организованы в виде иерархии, представляющей различные уровни их детализации. Благодаря такой модели данных пользователи могут формулировать сложные запросы, генерировать отчеты, получать подмножества данных. Технология комплексного многомерного анализа данных получила название OLAP (On-Line Analytical Processing). OLAP — это ключевой компонент организации хранилищ данных. Концепция OLAP была описана в 1993 году Эдгаром Коддом, известным исследователем баз данных и автором реляционной модели данных (см. E.F. Codd, S.B. Codd, and C.T.Salley, Providing OLAP (on-line analytical processing) to user-analysts: An IT mandate. Technical report, 1993). В 1995 году на основе требований, изложенных Коддом, был сформулирован так называемый тест FASMI (Fast Analysis of Shared Multidimensional Information — быстрый анализ разделяемой многомерной информации), включающий следующие требования к приложениям для многомерного анализа:
· предоставление пользователю результатов анализа за приемлемое время (обычно не более 5 с), пусть даже ценой менее детального анализа; · возможность осуществления любого логического и статистического анализа, характерного для данного приложения, и его сохранения в доступном для конечного пользователя виде; · многопользовательский доступ к данным с поддержкой соответствующих механизмов блокировок и средств авторизованного доступа; · многомерное концептуальное представление данных, включая полную поддержку для иерархий и множественных иерархий (это — ключевое требование OLAP); · возможность обращаться к любой нужной информации независимо от ее объема и места хранения. Следует отметить, что OLAP-функциональность может быть реализована различными способами, начиная с простейших средств анализа данных в офисных приложениях и заканчивая распределенными аналитическими системами, основанными на серверных продуктах
Общие свойства хранилищ Хранилище данных играет в первую очередь роль интегратора и аккумулятора исторических данных. Структура организации хранилища ориентированна на предметные области. Предметно-ориентированное хранилище содержит данные, поступающие из различных оперативных БД и внешних источников. Хранилище представляет собой совокупность данных, отвечающую следующим характеристикам:
Интегрированность Наиболее важный аспект хранилища данных состоит в том, что данные, находящиеся в хранилище, интегрированы. Интегрированность проявляется во многих аспектах:
Контраст между интеграцией данных в хранилище данных и в прикладном окружении иллюстрируется следующим образом. Первая причина возможного рассогласования приложений заключается в наличии множества средств разработки. Каждое средство разработки диктует определенные правила, часть из которых индивидуальна для данного средства. Не секрет, что каждый разработчик предпочитает одни средства разработки другим. Если два разработчика используют различные средства разработки, они, как правило, применяют индивидуальные особенности средств, а значит, возникает вероятность несогласованности между создаваемыми системами. Вторая причина возможного рассогласования приложений заключается в существовании множества способов построения приложения. Способ построения конкретного приложения зависит от стиля разработчика, от времени, когда это приложение разрабатывалось, а также от ряда факторов, характеризующих конкретные условия разработки приложения. Все это отражается на используемых способах задания ключевых структур, способах кодирования, обозначения данных, физических характеристиках данных и т.д. Таким образом, если два разработчика создают различные способы построения приложений, имеется высокая вероятность того, что полной согласованности между системами не будет.
Интеграция данных по единицам измерения атрибутов состоит в следующем. Разработчики приложений к вопросу о способе задания размеров продукции могут подходить несколькими путями. Размеры могут задаваться в сантиметрах, дюймах, ядрах и т.д. Каков бы ни был источник данных, если информация поступит в хранилище, она должна быть приведена к одним и тем же единицам измерения, принятым в качестве стандарта в хранилище. Зависимость от времени Все данные в хранилище в определенный момент времени совместны (непротиворечивы). Для оперативных систем эта базовая характеристика данных соответствует совместности данных в момент доступа. Когда в оперативной среде осуществляется доступ к данным, ожидается, что данные имеют совместные значения только в момент доступа к ним. Зависимость от времени хранилища данных проявляется в следующем. Данные в хранилище представлены за временной промежуток от года до 10 лет. В оперативной среде представление данных осуществляется в промежутке от текущего значения до нескольких десятков дней. Приложения с высокой производительностью для обеспечения эффективного процесса транзакций должны работать с минимальным количеством данных. Следовательно, оперативные приложения ориентированны на короткий временной промежуток. Другое проявление зависимости хранилища данных от времени заключается в его структуре. Каждая структура хранилища включает – явно или неявно – элемент времени. Третье проявление зависимости хранилища данных от времени состоит в неукоснительном выполнении правила, что данные, однажды корректно в хранилище записанные, не могут быть обновлены. Хранилище данных с точки зрения практического использования представляет собой большую серию моментальных снимков. Естественно, если моментальный снимок данных был сделан некорректно, он может быть изменен. Но если был получен корректный моментальный снимок, то, однажды сделанный, он в последующем изменению не подлежит. Оперативные данные, будучи корректны в момент доступа к ним, могут обновляться по мере необходимости. Постоянство Четвертая определяющая характеристика хранилища данных – это постоянство. В оперативной среде операции обновления, добавления, удаления и изменения производятся над записями регулярно. Базовые манипуляции с данными хранилища ограничены начальной загрузкой данных и доступом к ним. В хранилище данных обновление данных не производится. Исходные (исторические) данные, после того как они были согласованны, верифицированы и внесены в хранилище данных, остаются неизменными и используются исключительно в режиме чтения.
Существуют важные последствия различия обработки данных в оперативной среде и обработки в хранилище данных. На уровне проектирования хранилища данных необходимость в поддержке механизмов, обеспечивающих корректность обновлений, отпадает – обновления в хранилище данных не производятся. Это означает, что на физическом уровне проектирования при решении проблемы нормализации и физической денормализации доступ к данным может оптимизироваться без каких-либо ограничений. Другое последствие простоты работы с данными хранилища касается технологии работы с данными. Технология работы с данными в оперативной среде отличается большей сложностью. Она поддерживает функции оперативного резервного копирования и восстановления, обеспечивает целостность данных, включает механизмы разрешения конфликтов и тупиковых ситуаций. Для обработки информации в хранилище данных указанные функции не столь критичны. Характеристики хранилища данных – ориентированность на предметную область при проектировании, интегрированность данных, зависимость от времени и простота управления данными – определяют среду, которая существенно отличается от классической транзакционной среды. Источником почти всех данных среды хранилища данных являются оперативные среды. Может возникнуть ощущение, что существует огромная избыточность данных в обеих средах. Однако на практике избыточность данных в средах минимальна, поскольку:
Данные хранилища В общем случае модель данных современных Систем Поддержки Принятия Решений (СППР) строится на основе пяти классов данных: · источники данных, · хранилища данных (в узком смысле), · оперативный склад данных, · витрины данных, · метаданные. Источники данных Источниками данных хранилища служат оперативные транзакционные системы, которые обслуживают повседневную учетную деятельность компании. Необходимость включения той или иной транзакционной системы в качестве источника определяется бизнес-требованиями к СППР. Исходя из этих же требований, в качестве источников данных, могут быть рассмотрены внешние системы, в том числе и Интернет. Детальные данные из источников могут либо напрямую поступать в хранилище, либо предварительно агрегироваться до требуемого уровня обобщения.
Витрины данных (Data mart) Функционально ориентированные витрины данных представляют собой структуры данных, обеспечивающие решение аналитических задач в конкретной функциональной области или подразделении компании, например управление прибыльностью, анализ рынков, анализ ресурсов и проч. Иногда эти структуры хранения данных называют также киосками данных. Витрины данных можно рассматривать как маленькие хранилища, которые создаются с целью информационного обеспечения аналитических задач конкретных управленческих подразделений компании. Как правило, витрина содержит значительно меньше данных, охватывает всего несколько предметных областей и имеет более короткую историю. Витрины данных можно представить в виде логически или физически разделенных подмножеств хранилищ данных. Обычно они строятся для обслуживания нужд определенной группы пользователей. Источником данных для витрин служат данные хранилища, которые, как правило, агрегируются и консолидируются по различным уровням иерархии. Детальные данные могут также помещаться в витрину или присутствовать в ней в виде ссылок на данные хранилища. Различные витрины данных содержат разные комбинации и выборки одних и тех же детализированных данных хранилища. Важно, что данные витрины поступают из центрального хранилища данных — единого "источника истины". Метаданные Метаданные — это любые данные о данных. Метаданные играют важную роль в построении Систем Поддержки Принятия Решений (СППР). Одновременно это один из наиболее сложных и недостаточно практически проработанных объектов. В общем случае можно выделить по крайней мере три аспекта метаданных, которые должны присутствовать в системе.
· метаданные для бизнес-аналитиков, · метаданные для администраторов, · метаданные для разработчиков.
· структуры данных хранилища, · модели бизнес-процессов, · описания пользователей, · технологические и пр.
· метаданные о процессах трансформации, · метаданные по администрированию системы, · метаданные о приложениях, метаданные о представлении данных · пользователям. Присутствие трех перечисленных аспектов метаданных подразумевает, что, например, прикладные пользователи и разработчики системы будут иметь различное видение технологических аспектов трансформации данных из источников: прикладные пользователи - семантику, состав и периодичность пополнения хранилища данными из источника, разработчики - ER-диаграммы, правила трансформации и интерфейс доступа к данным источника. В настоящее время отсутствует единая промышленная технология проектирования, создания и сопровождения метаданных. Поэтому вопросы, связанные с управлением метаданными, рассматриваются отдельно, применительно к каждому конкретному проекту построения СППР. Компоненты хранилища Хранилище на самом верхнем уровне состоит, как правило, из трех подсистем: · подсистемы загрузки данных, · подсистемы обработки запросов и представления данных, · подсистемы администрирования хранилища. Подсистема загрузки данных Данная подсистема представляет собой ПО, которое в соответствии с определенным регламентом извлекает данные из источников и приводит их к единому формату, определенному для хранилища. Данная подсистема отвечает за формализованную логическую согласованность, качество и интеграцию данных, которые загружаются из источников в оперативный склад данных. Каждый источник данных требует разработки собственного загрузочного модуля. Каждый модуль должен решать два класса задач: · Начальной загрузки ретроспективных данных, · Регламентного пополнения хранилища данными из источников. Данная подсистема также по регламенту извлекает детальные данные из оперативного склада, производит их агрегирование, консолидацию, трансформацию и помещает данные в хранилище и витрины данных. Именно в данной подсистеме должны быть определены все бизнес-модели консолидации данных по иерархическим измерениям и вычисления зависимых бизнес-показателей по независимым исходным данным. Постановка задачи Проектирование На данной стадии проектных работ, на основе анализа требований к системе, сформулированных в ТЗ, разрабатываются основные архитектурные решения. Архитектура информационной системы рассматривается в четырех аспектах: · Логическая архитектура. Представляет архитектуру системы с точки зрения пакетов базовых классов и их взаимосвязей. Определяются автоматизируемые процессы и функции, необходимые для достижения поставленных целей, которые затем разделяются на задачи, подлежащие реализации на стадии разработки. · Архитектура процессов. Применительно к СППР, определяет информационное обеспечение системы – состав и содержание процессов преобразования и передачи данных. · Компонентная архитектура. Представляет архитектуру ПО системы, ее декомпозицию на подсистемы и компоненты. · Техническая архитектура. Описывает физические узлы системы и связи между ними. Информационное обеспечение В общем случае информационное обеспечение системы состоит из пяти классов данных:
Проектирование информационного обеспечения системы осуществляется сверху вниз. На основе анализа прецедентов использования системы, выявленных на этапе системно-аналитического обследования, определяются представления данных конечным прикладным пользователям системы: состав показателей и их разрезы. Осуществляется сегментация представлений данных в соответствии с их проблемной ориентацией. На основе групп представлений витрин должны быть определены: · Измерения, их иерархии и уровень детализации. Например, для временного измерения должен быть определен минимальный интервал времени (день, неделя, месяц), по которому будут индексироваться показатели в витрине. · Базовые показатели, измерения, их индексирующие, и правила агрегирования каждого показателя по иерархиям. Правила агрегирования по иерархическому измерению зависят от показателя. Например, если для дохода от продаж агрегирование по времени осуществляется простым суммированием, то при исследовании цены продукции агрегирование по времени может быть реализовано в виде среднего, максимального или минимального значения за период агрегации. · Производные показатели и формулы их вычисления на основе базовых показателей. Выбор конкретного способа представления витрин (ROLAP, MOLAP или HOLAP — см. далее) выполняется, как правило, на стадии реализации системы. Выявленные измерения и показатели служат исходными данными для проектирования хранилища. В первую очередь обобщаются все выявленные разрезы и их иерархии. На их основе проектируется бизнес-пространство хранилища. Измерения, как правило, тесно связаны со структурированной нормативно-справочной информацией компании. Например, измерениями хранилища часто служат организационная структура компании, справочник административно-территориального деления, план финансовых статей компании и пр. На пространстве, которое задается бизнес-измерениями, проектируются базовые и производные показатели, которые должны находиться в хранилище. Для больших систем целесообразно проводить сегментацию хранилища по предметным областям. На следующем этапе выполняется анализ результатов обследования источников данных. При выборе подходящего источника во внимание принимаются следующие вопросы: · Если имеется более одного источника, следует ли определить, какой из них лучше? · Какие преобразования необходимо выполнить, чтобы приготовить источник к загрузке в хранилище? · Согласуются ли структура источника и структура хранилища? · Насколько согласуются данные источника с нормативно-справочной информацией? · Что будет происходить, если источник имеет несколько месторасположений? · Насколько аккуратны данные источника? · Как источник обновляется? · Каковы возраст и перспективность источника? · Насколько полны данные? · Что потребуется для интеграции данных источника в поток загрузки? · Какова технология хранения данных в источнике? · Насколько эффективно может осуществляться доступ к источнику?
На основе выполненного анализа принимаются следующие архитектурные решения: · Определяются состав, содержание и источники потоков данных, которые будут поступать из источников в хранилище. · Определяются преобразования, которые должны быть выполнены над данными при загрузке, а также периодичность загрузки данных в хранилище. · При необходимости проектируются структуры оперативного склада данных и транзитных файлов. · Выявляются данные, которые отсутствуют в источниках информационного хранилища. Для таких данных, как правило, проектируются процедуры и регламенты ручного ввода. Общая структура репозитария хранилища является своего рода отражением главной цели его построения, а именно максимально полно и быстро удовлетворить потребности пользователей в той или иной информации. В зависимости от потребностей пользователей в информации можно выделить следующие ее основные типы:
Компонентная архитектура Система на самом верхнем уровне состоит, как правило, из двух видов ПО: общего и специального. К общему ПО относятся:
o Серверы реляционных БД, o Серверы МБД, o Серверы приложений (поисковые, аналитической обработки, добычи знаний и др.). · Специальное ПО представляет собой совокупность программ, разрабатываемых при создании Систем Поддержки Принятия Решений (СППР). Они объединяются в следующие подсистемы: o Подсистему загрузки данных, o Подсистему обработки запросов и представления данных, o Подсистему администрирования. В этой части должны быть спроектированы модули, составляющие подсистему, и алгоритмы отдельных процедур, входящих в их состав. Техническая архитектура Серверное ПО работает под управлением серверов приложений и серверов БД на UNIX- или NT-платформах или мэйнфреймах. Клиентское ПО, устанавливается на ПК конечных пользователей. В последние годы наметилось стремительное внедрение технологии «тонкого» клиента, при которой на ПК пользователя находится лишь Web-броузер, а вся функциональность клиентского ПО загружается с сервера приложений в виде JavaScript- программ или апплетов. Техническая архитектура во многом зависит от масштабови требований, предъявляемых к ее производительности и надежности. В зависимости от этого серверные компоненты системы могут располагаться на одном компьютере или на нескольких. Сегменты хранилища и витрины данных в больших системах могут располагаться на нескольких компьютерах. Реализация Данная стадия проекта непосредственно связана с разработкой и тестированиемкомпонентов информационного и специального ПО системы в соответствии с разработанной на этапе проектирования архитектурой. К основным результатам работы на этом этапе следует отнести: · Непосредственно саму систему в виде общего и специального ПО, баз данных. · План внедрения системы, который должен определять все работы по внедрению системы у заказчика, включая упаковку системы, доставку ее заказчику, инсталляцию системы на технических средствах заказчика, тестирование и доработку. · Набор тестов, которые должны быть выполнены после установки системы у заказчика. · Пользовательскую документацию и учебные материалы для пользователей системы. Внедрение Данная фаза состоит в выполнении работ, предусмотренных планом внедрения, который был разработан на предыдущей фазе. На стадии развертывания осуществляются монтаж и установка системы и отдельных ее компонентов у заказчика. Осуществляется первоначальная загрузка хранилища необходимыми данными, выполняется опытная эксплуатация системы. Кроме того, на стадии развертывания осуществляется обучение пользователей и сотрудников службы технической поддержки. Окончанием данного этапа считается момент перехода к производственной эксплуатации хранилища.
Рынок BI
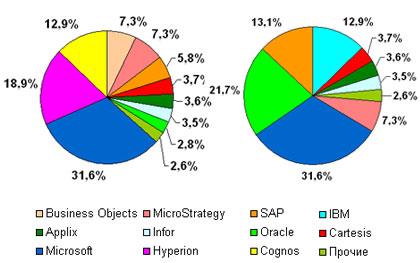
Согласно исследованиям, проведенным компанией The OLAP Report, безусловным лидером мирового рынка BI в 2006 году стала компания Microsoft - доля ее систем на рынке составляла 31,6%. За ней следовала Hyperion (18,9%) и Cognos (12,9%.) Замыкали пятерку лидеров Business Objects и MicroStrategy (по 7,3% у каждого). SAP в 2006 году сумел завоевать только 5,8% рынка.
Следует отметить, что в 2006 году на мировом олимпе BI корпорации Oracle принадлежало всего 2,8%. Однако этот показатель получен без учета прикладных партнерских продуктов, построенных на базе решений Oracle. Кроме того, сама компания за прошедший год сделала ряд громких приобретений: под ее марку перешли знаменитые продукты Siebel и Hyperion. Siebel Analytics стал основой для новой платформы Oracle Business Intelligence Enterprise Edition, а Hyperion вошел в состав Oracle BI Suite EE Plus. Немного спустя компанию Sunopsis с ее ETL-решением постигла та же участь - теперь это новый продукт Oracle Data Integrator. Таким образом, четко прослеживается стратегия Oracle, направленная на развитие этого направления не только за счет собственных разработок, но и за счет поглощений конкурентов.
Прямой конкурент Oracle - компания IBM - тоже не заставила себя долго ждать и объявила о громком приобретении Cognos, известной своим мощным аналитическим комплексом. Несколько лет назад IBM уже поглотила компанию Ascential и представила ее ETL-продукт под новым названием Data Stage. Принимая также во внимание тот факт, что IBM является еще вендором серверных платформ и СУБД DB2, можно предположить, что ее предложение составит серьезную конкуренцию другим участникам рынка.
Однако и другие игроки тоже не остались в стороне: крупнейший производитель ERP систем SAP объявил о приобретении французско-германской компании Business Objects, широко известной своими инструментами репортинга.
Таким образом, прошедший год ознаменовался укреплением позиций лидеров за счет слияний и поглощений, в результате чего расстановка сил на международном рынке BI несколько изменилась.
Распределение позиций игроков рынка BI на мировом рынке, 2006 г*.
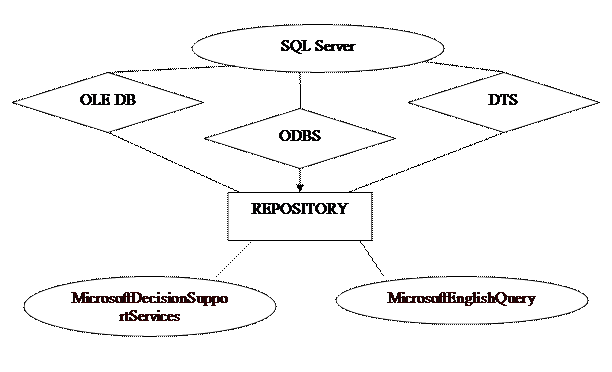
Так, по-прежнему на первом месте осталась компания Microsoft. На втором месте оказался Oracle, которому теперь принадлежит 21,7%. SAP занял третье место, набрав 13,1%. Четвертое и пятое места принадлежат соответственно компаниям IBM (12,9%) и MicroStrategy (7,3%). Продукция Microsoft Фирма Microsoft твердо убеждена, что ее продукты позволяют значительно усовершенствовать процесс создания хранилища данных. Она разработала продукт DataWarehousing Framework, в котором объединены различные технологии (доступ к данным, метаданные, преобразования, запрос конечного пользователя и т.д.) во всех ЭШлах построения и использования хранилища данных, а также управления им. Фирма Microsoft, кроме того, обеспечила поддержку каждого компонента Warehousing Network в продуктах Microsoft Office, BackOffice и Visual Studio. Microsoft тесно сотрудничает и с другими фирмами – производителями продуктов разработки хранилища данных с целью создания Data Warehousing Alliance. Все эти фирмы работают на основе общих технологий и протоколов, которые были установлены для Warehousing Framework. Это позволяет повысить совместимость и возможность взаимодействия различных продуктов на рынке технологий создания хранилищ данных [8]. В СУБД MicrosoftSQLServer 7.0 предусмотрено много средств, которые могут помочь в построении хранилища данных. Поддержка больших баз данных, оптимизация запросов и репликация — все эти функции делают SQLServer мощным инструментом для создания хранилища или витрины данных (рис. 5). Гетерогенные запросы позволяют объединить результирующие наборы из нескольких источников данных OLEDB или ODBC. Кроме того, к вашим услугам службы преобразования данных (DTS), склад (Repository) для хранения метаданных, OLAP-средства для принятия решений (DecisionSupportServices) и MicrosoftEnglishQuery (выполнение запросов на английском языке) [10].
Рис. 5. Схема работы с хранилищем данных при помощи продукции Microsoft
Службы преобразования данных (DataTransformationServices – DTS) – это универсальный набор инструментов, встроенный в SQLServer 7.0. Он позволяет легко импортировать, экспортировать и преобразовывать данные, перемещая их между любыми двумя источниками, которые поддерживают OLEDB. В каком-то смысле DTS — это своего рода насос данных, с помощью которого можно перемещать исходные записи с одного места на другое с помощью простого интерфейса мастера. В DTS предусмотрены службы импорта и экспорта данных из различных источников: · источников данных, поддерживающих OLEDB: Oracle, SQLServer 4.2, 6.5 и др.; · источников данных, поддерживающих ODBC: DB2 на MVS, данных AS400, Informix, MicrosoftAccess, MicrosoftExcel и др.; · текстовых ASCII-файлов, содержащих поля фиксированной длины или разделенных символами-ограничителями. Приложение MicrosoftRepository — это инфраструктура для хранения и совместного использования метаданных. Оно позволяет простым способом описывать данные, находящиеся в хранилище. С помощью склада информационные структуры данных можно хранить отдельно от самих данных; к этим структурам также можно обращаться из других компонентов архитектуры хранилища данных. Склад хранилища данных обладает следующими возможностями: · сохраняет модели данных со звездообразной структурой; · заносит в каталог связи между элементами данных и исходными СУБД; · регистрирует преобразования данных и родословные данных: · сохраняет правила выборки данных и репликации; · поддерживает работу команды разработчиков. Службы поддержки принятия решений фирмы Microsoft (MicrosoftDecisionSupportServices) — это инструменты, позволяющие сделать общедоступными возможности OLAP и информацию, находящуюся в хранилище. С их помощью можно представить информацию из хранилища в виде многомерных кубов, что способствует проведению анализа данных. Главные особенности и преимущества MicrosoftDSS: · доступ к любому поддерживающему OLEDB источнику данных; · поддержка MOLAP (многомерной интерактивной аналитической обработки), ROLAP (реляционной OLAP) и HOLAP(гибрида первых двух); · объединение возможностей хранения данных SQLServer и анализа данных Excel путем поддержки средств создания свободных таблиц; · возможность проведения анализа данных в автономном режиме, например во время передвижения в автомобиле, самолете и т.д. · возможность перехода от настольной системы к общей модели для всего предприятия. Продукция Sybase Adaptive Server IQ – это СУБД, оптимизированная для анализа данных на уровне физического дизайна. Уникальная архитектура IQ позволяет обрабатывать незапланированные аналитические запросы в десятки-сотни раз быстрее, чем традиционные СУБД. При этом вместо разбухания данных в хранилище происходит их сжатие [7]. СУБД Sybase Adaptive Server IQ специально разработана для высокоскоро
|
|||||||||
|
|
Последнее изменение этой страницы: 2016-12-16; просмотров: 308; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.134.115.120 (0.021 с.) |