
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Передача параметров по значениюСодержание книги
Похожие статьи вашей тематики
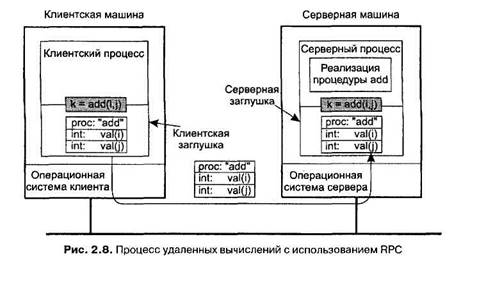
Поиск на нашем сайте Упаковка параметров в сообщение носит название маршалипга параметров {parameter marshaling). В качестве простейшего примера рассмотрим удаленную процедуру, add (i, j), которая использует два целых параметра, i и j, и возвращает в результате их арифметическую сумму. (На практике так не делается, поскольку удаленная реализация столь простой процедуры крайне невыгодна, но для примера сойдет.) Вызов add иллюстрируется левой частью рис. 2.8 (в клиентском процессе). Клиентская заглушка извлекает два ее параметра и, как показано на рисунке, упаковывает их в сообщение. Она также помещает туда имя или номер вызываемой в сообщении процедуры, поскольку сервер может поддерживать несколько разных процедур и ему следует указать, какая из них потребовалась в данном случае.
2.2. Удаленный вызов процедур 99
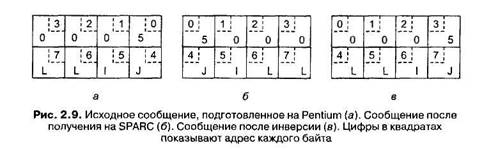
Таким образом, имеет место следующая пошаговая процедура. 1. Клиент вызывает процедуру add. 2. Клиентская заглушка строит сообщение. 3. Сообщение отправляется по сети на сервер. 4. Операционная система сервера передает сообщение серверной заглушке. 5. Серверная заглушка распаковывает сообщение. 6. Серверная заглушка выполняет локальный вызов процедуры add. Когда сервер заканчивает работу, управление вновь передается серверной за-г.тушке. Она получает результат, переданный сервером, и запаковывает его в со-ощение. Это сообщение отправляется назад, к клиентской заглушке, которая распаковывает его и возвращает полученное значение клиентской процедуре. До тех пор пока машины клиента и сервера идентичны, а все параметры и ре-зультаты имеют скалярный тип (то есть целый, символьный или логический), та модель работает абсолютно правильно. Однако в больших распределенных системах обычно присутствуют машины разных типов. Каждая из машин часто имеет собственное представление чисел, символов и других элементов данных. Так, в мэйнфреймах IBM используется кодовая таблица EBCDIC, а в персональных компьютерах той же фирмы — ASCII. Вследствие этого, если передать сим-вольный параметр с клиента на базе IBM PC на мэйнфрейм IBM, используемый в качестве сервера, по простейшей схеме, показанной на рис. 2.8, сервер поймет эти символы неправильно. Сходные проблемы могут обнаружиться при передаче целых чисел (знако-вый или значащий старший бит) и чисел с плавающей точкой. Вдобавок сущест-вует значительно более серьезная проблема, состоящая в том, что в некоторых машинах, таких как Intel Pentium, байты нумеруются справа налево, а в других, например в Sun SPARC, — в обратном направлении. Формат компании Intel называется остроконечным (little endiari), а формат SPARC — тупоконечным (big •:dian), по аналогии с названиями политических партий из книги «Путешествия Гулливера», которые в спорах о том, с какой стороны разбивать яйца, дошли до войны [108]. Для примера рассмотрим процедуру с двумя параметрами, целым истом и строкой из четырех символов. Для размещения каждого из параметров требуется одно 32-битное слово. На рис. 2.9, а показано, как будет выглядеть со-держащий параметры фрагмент сообщения, построенного клиентской заглуш-■й. когда клиент работает на компьютере Intel Pentium. Первое слово содержит целый параметр, в данном случае 5, а второе слово — строку JILL.
100 Глава 2. Связь
Поскольку сообщение передается по сети байт за байтом (на самом деле бит за битом), первый посланный байт будет и первым принятым. На рис. 2.9, б мы видим, как будет выглядеть сообщение с рис. 2.9, а, принятое на компьютере SPARC. Нумерация байтов здесь такова, что нулевым байтом считается левый (верхний байт), а не правый (нижний байт), как в процессорах Intel. После того как серверная заглушка прочитает параметры по адресам 0 и 4, сервер получит, соответственно, целое число, равное 83 886 080 (5х224), и строку JILL. Очевидное, но, к сожалению, неверное решение — просто инвертировать байты каждого слова после того, как оно будет принято (рис. 2.9, в). Теперь целое число стало правильным, а строка превратилась в LLIJ. Проблема состоит в том, что целые нужно приводить к другому порядку следования байтов, а строки — нет. Не имея дополнительной информации о том, где строка, а где целое, мы не в состоянии исправить положение дел. Передача параметров по ссылке Теперь мы подошли к сложной проблеме: как передавать указатели или, в общем случае, ссылки? Общий ответ таков: с величайшим трудом. Мы помним, что указатель имеет смысл только в адресном пространстве того процесса, в котором он используется. Возвращаясь к нашему примеру с процедурой read, который мы обсуждали ранее, второй параметр (адрес буфера) для клиента может быть равен, например, 1000, но нельзя же просто передать на сервер число 1000 и ожидать, что это сработает. На сервере адрес 1000 вполне может прийтись на середину текста программы. Одно из решений состоит в том, чтобы вообще забыть про указатели и ссылки в качестве параметров. Однако важность таких параметров делает такое решение абсолютно неподходящим. На самом деле в нем нет особой необходимости. В примере с процедурой read клиентской заглушке известно, что второй параметр указывает на массив символов. Предположим на минуту, что заглушка также знает и величину этого массива. После этого вырисовывается следующая стратегия: скопировать этот массив в сообщение и передать его на сервер. Серверная заглушка может после этого вызвать сервер, передав ему указатель на этот массив, даже если числовое значение этого указателя будет отличаться от переданного во втором параметре вызова процедуры read. Изменения, которые с помощью указателя сделает сервер (то есть по указанному адресу запишет данные), прямо отразятся на буфере сообщения серверной заглушки. Когда сервер закон-
2.2. Удаленный вызов процедур 101
Небольшая оптимизация позволяет сделать этот механизм вдвое эффективнее. Если обеим заглушкам известно, входящим или исходящим параметром является буфер для сервера, то одну из копий можно удалить. Если массив используется сервером в качестве исходных данных (то есть при вызове write), то копировать его обратно не нужно. Если это результат, то нет необходимости изначально передавать его серверу. В качестве последнего комментария отметим, что нет ничего особенно хорошего в том, что мы можем работать с указателями на простые массивы и структуры, если нам по-прежнему недоступна работа с более общими вариантами указателей — с указателями на произвольные структуры данных, например на сложные графы. В некоторых системах делается попытка решить эту проблему путем передачи серверной заглушке реальных указателей с последующей генерацией специального кода в процедурах сервера для работы с этими указателями. Так, для получения данных, которые соответствуют указателю, сервер может сделать специальный запрос. Спецификация параметров и генерация заглушек После всех этих объяснений становится ясно, что сокрытие механизма удаленного вызова процедур требует, чтобы вызывающая и вызываемая системы договорились о формате сообщений, которыми они обмениваются, и при необходимости пересылки, например, данных сложной структуры, следовали определенному порядку действий. Другими словами, при совершении RPC обе стороны должны следовать одному протоколу. В качестве простого примера рассмотрим процедуру, показанную на рис. 2.10, а. Она имеет три параметра: символ, число с плавающей точкой и массив из пяти целых чисел. Предполагая, что длина слова составляет четыре байта, протокол RPC может предписать передачу символа в крайнем правом байте слова (оставляя последующие три пустыми), числа с плавающей точкой — в целом слове, а массива — в виде последовательности слов с общей длиной, равной длине массива, и предшествующим словом, содержащим длину последовательности (рис. 2.10, б). Если ввести подобные правила, то клиентская заглушка будет знать, что для процедуры foobar необходимо использовать тот формат, который представлен на рис. 2.10, б, а серверная заглушка — что именно такой формат будет иметь входящее сообщение для вызова процедуры foobar. Определение формата сообщения — это только одна сторона протокола RPC. Этого недостаточно. Также нам необходимо, чтобы клиент и сервер пришли к договоренности по вопросу представления простых типов данных, таких как целые числа, символы, логические значения и т. д. Так, протокол может предписать, чтобы целые передавались без знака, символы в 16-битной кодировке Unicode, а числа с плавающей точкой — в формате стандарта IEEE 754, и все это — в остроконечном формате. Только при наличии такой дополнительной информации сообщение может быть однозначно интерпретировано.
102 Глава 2. Связь
После того как все биты до последнего выстроены в ряд по согласованным правилам кодирования, осталось сделать только одно. Вызывающая и вызываемая системы должны договориться между собой об обмене реальными сообщениями. Например, они могут решить использовать транспортный протокол с соединениями, такой как TCP/IP. Альтернативой ему будет ненадежная служба дейтаграмм, в этом случае клиент и сервер должны включить реализацию схемы контроля ошибок в RPC. На практике возможны различные варианты. После завершения определения протокола RPC необходимо реализовать заглушки — клиентскую и серверную. К счастью, заглушки, работающие по одному протоколу, для разных процедур различаются лишь интерфейсом с приложениями. Интерфейс состоит из набора процедур, которые могут быть вызваны клиентом, но реализуются на сервере. Доступ к интерфейсу осуществляется обычно из определенного языка программирования, одного из тех, на которых написан клиент или сервер (хотя, строго говоря, это не обязательно). Для упрощения работы интерфейсы часто описываются с использованием языка определения интерфейсов (Interface Definition Language, IDL). Интерфейс, определенный на чем-то вроде IDL, компилируется затем в заглушки клиента и сервера, а также в соответствующие интерфейсы времени компиляции и времени выполнения. Практика показывает, что использование языка определения интерфейсов делает приложения клиент-сервер, базирующиеся на RPC, существенно проще. Поскольку клиентская и серверная заглушки очень легко сгенерировать полностью автоматически, все системы промежуточного уровня, основанные на RPC, используют IDL для поддержки разработки программного обеспечения. В некоторых случаях применение IDL просто обязательно. Мы рассмотрим подобные случаи в следующих главах.
2.2. Удаленный вызов процедур 103
Удаленные вызовы процедур стали фактическим стандартом для связи в распределенных системах. Популярность этой модели объясняется ее несомненной простотой. В этом пункте мы рассмотрим два расширения базовой модели RPC, созданные для разрешения некоторых ее недостатков. Входы Базовая модель RPC предполагает, что вызывающая и вызываемая системы могут связываться друг с другом для обмена сообщениями по сети. В общем случае это предположение истинно. Однако рассмотрим вариант, когда клиент и сервер установлены на одной машине. В стандартном случае мы должны использовать средства локального межпроцессного взаимодействия (InterProcess Communication, IPC), которые базовая операционная система предоставляет процессам, запущенным на одной машине. Так, например, в UNIX соответствующие средства включают в себя совместно используемую память, каналы и очереди сообщений (детальное обсуждение IPC в UNIX-системах можно найти в [439]). Локальные средства IPC обычно значительно более эффективны, чем сетевые, даже если последние используются для связи между процессами на одной машине. Соответственно, если важна производительность, следует совмещать различные механизмы межпроцессного взаимодействия, руководствуясь тем, находятся ли процессы, в которых мы заинтересованы, на одной машине или нет. В качестве компромисса некоторые операционные системы предоставляют процессам, размещенным на одной машине, эквивалент RPC под названием входов (doors). Вход — это обобщенное имя процедур, существующих в адресном пространстве процессов сервера, которые могут вызываться процессами, размещенными на одной с сервером машине. Входы впервые появились в операционной системе Spring [297] и были хорошо описаны в [193]. Сходный механизм, под названием упрощенный вызов RPC (lightweight RPC), описан в [49]. Вызов входов требует поддержки локальной операционной системы, как показано па рис. 2.11. Так, для того чтобы появилась возможность вызвать вход, процесс сервера должен зарегистрировать его. При регистрации входа возвращается его идентификатор, который впоследствии можно будет использовать в качестве символического имени входа. Регистрация заканчивается вызовом door_ create. Доступ других процессов к зарегистрированному входу может осуществляться просто по тому идентификатору, который мы получили при регистрации входа. Так, например, в Solaris каждый вход имеет файловое имя, которое можно получить через идентификатор простым вызовом fattach. Клиент вызывает вход через системный вызов door_call, в который идентификатор входа передается так же, как и любой другой обязательный параметр. Затем операционная система производит вызов того процесса, который зарегистрировал вход. Результатом этого вызова будет вызов входа сервера. Результаты вызова входа будут возвращены в процесс клиента через системный вызов door_return. Главное преимущество входов состоит в том, что они позволяют использовать для связи в распределенных системах единый механизм — вызовы процедур.
104 Глава 2. Связь
Асинхронный вызов RPC В стандартном варианте вызова клиентом удаленной процедуры его работа приостанавливается до получения ответа. Когда ответ не нужен, этот жесткий алгоритм «запрос-ответ» не является необходимым, приводя только к блокированию клиента с невозможностью производить работу до получения ответа от удаленной процедуры. Примеры действий, при которых обычно нет необходимости в ожидании ответа: перечисление денег с одного банковского счета на другой, добавление записей в базу данных, запуск удаленной службы, пакетная обработка и множество других. Для обработки подобных случаев системы RPC могут предоставлять средства для так называемого асинхронного вызова RPC (asynchronous RPC). При помощи этих средств клиент получает возможность продолжить свою работу сразу после выполнения запроса RPC. При асинхронном вызове RPC сервер немедленно по приходу запроса отсылает клиенту ответ, после чего вызывает запрошенную процедуру. Ответ служит подтверждением того, что сервер приступил к обработке RPC. Клиент продолжает работу, снимая блокировку, сразу после получения
2.2. Удаленный вызов процедур 105
Асинхронные вызовы RPC также могут быть полезны в тех случаях, когда ответ будет послан, но клиент не готов просто ждать его, ничего не делая. Например, клиент может пожелать заранее выбрать сетевые адреса из набора хостов, с которыми вскоре будет связываться. В то время, пока служба именования соберет эти адреса, клиент может заняться другими вещами. В подобных случаях имеет смысл организовать сообщение между клиентом и сервером через два асинхронных вызова RPC, как это показано на рис. 2.13. Сначала клиент вызывает сервер, чтобы передать ему список имен хостов, который следует подготовить, и продолжает свою работу, когда сервер подтверждает получение этого списка. Второй вызов делает сервер, который вызывает клиента, чтобы передать ему найденные адреса. Комбинация из двух асинхронных вызовов RPC иногда называется также отложенным синхронным вызовом RPC (deferred synchronous RPC).
106 Глава 2. Связь
Пример — DCE RPC Механизм удаленных вызовов процедур был тщательно адаптирован для использования в качестве основы систем промежуточного уровня и вообще распределенных систем. В этом пункте мы рассмотрим одну из специальных систем RPC: среду распределенных вычислений {Distributed Computing Environment, DCE), разработанную организацией OSF (Open Software Foundation), которая сейчас переименована в Open Group. Система DCE RPC не настолько популярна, как некоторые другие системы RPC, например Sun RPC. Однако DCE RPC — прекрасный представитель систем RPC. Спецификация DCE RPC адаптирована к системе распределенных вычислений на базе решений Microsoft. Кроме того, как мы увидим в следующем пункте, DCE RPC вдобавок иллюстрирует отношения между системами RPC и распределенными объектами. Мы начнем с краткого введения в DCE, за которым последует обсуждение принципов работы DCE RPC. Знакомство с DCE DCE — настоящая система промежуточного уровня, разработанная, чтобы абстрагировать существующие (сетевые) операционные системы от распределенных приложений. Изначально она была разработана под UNIX, однако в настоящее время существуют версии DCE для всех распространенных операционных систем, включая VMS и Windows NT, а также операционных систем настольных компьютеров. Идея состоит в том, что покупатель может взять набор компьютеров, поставить программное обеспечение DCE и начать запускать распределенные приложения, и все это без каких-либо неполадок в работе существующих (нераспределенных) приложений. Хотя большая часть пакета DCE работает в пространстве пользователя, в некоторых конфигурациях часть (отвечающая за распределенную файловую систему) может быть добавлена и к ядру. Сама по себе организация Open Group только продает исходные тексты, а поставщики встраивают их в свои системы. Модель программирования, лежащая в основе всей системы DCE, — это модель клиент-сервер, широко обсуждавшаяся в предыдущей главе. Процессы пользователей действуют как клиенты, вызывающие удаленные службы, предоставляемые серверными процессами. Некоторые из этих служб являются составными частями DCE, другие же принадлежат к приложениям и написаны прикладными программистами. Вся связь между клиентами и серверами осуществляется посредством RPC.
2.2. Удаленный вызов процедур 107
Задачи DCE RPC Задачи систем DCE RPC вполне традиционны. Они позволяют клиенту получить доступ к удаленной службе простым вызовом локальной процедуры. Этот интерфейс дает возможность писать клиентские (то есть прикладные) программы простым, хорошо знакомым большинству программистов способом. Также он упрощает запуск в распределенной среде больших объемов существующего кода с минимальными изменениями или без них. Самое важное для системы RPC — это скрыть все возможные детали от клиента и до некоторой степени от сервера. Для начала система RPC может автоматически определить необходимый сервер и установить связь между клиентом и сервером. Обычно это называется привязкой {binding). Кроме того, она может управлять транспортировкой сообщений в обе стороны, а также, если в этом есть необходимость, их дроблением и последующей сборкой, например, если один из параметров сообщения является большим массивом. И наконец, система RPC может автоматически отслеживать преобразование типов данных между клиентом и сервером, даже если они работают на системах с разной архитектурой, которые имеют различный порядок следования байт. В заключение скажем несколько слов о способности систем RPC скрывать детали. Клиент и сервер могут быть почти независимыми друг от друга. Клиент может быть написан на Java, а сервер на С или наоборот. Клиент и сервер могут работать на разных платформах и использовать различные операционные системы. Поддерживается также многообразие сетевых протоколов и представлений данных, все это — без какого-либо вмешательства в клиент или сервер. Написание клиента и сервера Система DCE RPC состоит из множества компонентов. В нее входят, в частности, языки, библиотеки, программы-демоны и утилиты. Все это делает возмож-
108 Глава 2. Связь
В системе клиент-сервер клеем, соединяющим все в единую систему, является описание интерфейса, которое создается с помощью языка определения интерфейсов {Interface Definition Language, IDL). Он позволяет описать процедуры в виде, очень похожем на прототипы функций в ANSI С. Файлы IDL могут также содержать определения типов, описания констант и другую информацию, необходимую для правильного маршалинга параметров и демаршалинга результатов. В идеале описание интерфейсов содержит также формальное определение действий, осуществляемых процедурой, но это выходит за рамки современных возможностей программирования, так что определение интерфейса включает в себя только его синтаксис, но не семантику. В лучшем случае программист может лишь добавить комментарии, описывающие, что делает та или иная функция. Важнейшим элементом каждого файла IDL является глобальный уникальный идентификатор описываемого интерфейса. Клиент пересылает этот идентификатор в первом сообщении RPC, а сервер проверяет его правильность. В этом случае если клиент по ошибке пытается выполнить привязку не к тому серверу
2.2. Удаленный вызов процедур 109
Описания интерфейсов и уникальные идентификаторы в DCE в значительной степени взаимозависимы. Как показано на рис. 2.14, первым шагом при написании приложения клиент-сервер является запуск программы Uuidgen, от которой мы хотим создания прототипа файла IDL, содержащего идентификатор интерфейса, гарантированно не использовавшийся ни в одном интерфейсе, созданном при помощи программы Uuidgen. Уникальность обеспечивается путем кодирования идентификатора машины и времени создания. Идентификатор представляет собой 128-битное число, представляемое в файле IDL в шестнадцате-ричном формате в виде строки ASCII. Следующим шагом является редактирование файла IDL, задание в нем имен удаленных процедур и их параметров. Несмотря на то что RPC не является полностью прозрачной системой (например, клиент и сервер не могут совместно использовать глобальные переменные), правила IDL делают описание неподдерживаемых конструкций невозможным. После того как файл IDL будет закончен, для его обработки вызывается компилятор IDL. В результате работы компилятора мы получаем три файла: ♦ заголовочный файл (то есть interface.h, в терминологии С); ♦ файл клиентской заглушки; ♦ файл серверной заглушки. Заголовочный файл содержит уникальный идентификатор, определения типов, констант и описания функций. Он может быть включен (с помощью директивы # include) в код сервера и клиента. Клиентская заглушка клиента содержит те процедуры, которые будет непосредственно вызывать клиентская программа. Эти процедуры отвечают за подбор параметров и упаковку их в исходящие сообщения с последующими обращениями к системе для их отправки. Клиентская заглушка также занимается распаковкой ответов, приходящих от сервера, и передачей значений, содержащихся в этих ответах, клиенту. Серверная заглушка содержит процедуры, вызываемые системой на машине сервера по приходе на нее сообщений. Они, в свою очередь, вызывают процедуры сервера, непосредственно выполняющие необходимую работу. Следующим шагом программиста является написание кода клиента и сервера. После этого они оба, а также обе заглушки, компилируются. Полученные объектные файлы клиента и клиентской заглушки компонуются с библиотеками времени выполнения, что дает в результате исполняемый файл клиента. Таким же точно образом из файлов сервера и серверной заглушки после компиляции и компоновки получается исполняемый файл сервера. Во время исполнения клиент и сервер будут запущены, и приложение начнет свою работу. Привязка клиента к серверу Чтобы позволить клиенту вызывать сервер, необходимо, чтобы сервер был зарегистрирован и готов к приему входящих вызовов. Регистрация сервера дает кли-
110 Глава 2. Связь
1. Обнаружение машины сервера. 2. Обнаружение сервера (то есть нужный процесс) на этой машине. Второй шаг немного непонятен. В общем случае для того, чтобы связаться с сервером, клиенту нужно знать конечную точку (endpoint) машины сервера, которой он может посылать сообщения. Конечная точка (более известная под названием порт) используется операционной системой сервера для получения входящих сообщений от различных внешних процессов. В DCE на каждой из серверных машин процессом, известным под названием DCE-демон (DCE daemon), поддерживается таблица пар сервер — конечная точка. Перед тем как сервер станет доступным для входящих запросов, он должен запросить у операционной системы конечную точку. Далее сервер регистрирует эту конечную точку у DCE-демона. DCE-демон записывает эту информацию (включая и протоколы, по которым может осуществляться обмен информацией с сервером) в таблицу конечных точек для последующего использования. Сервер также регистрирует (с помощью службы каталогов) предоставленные серверной машине сетевой адрес и имя, под которым сервер будет доступен. Затем происходит привязка клиента к серверу, как показано на рис. 2.15.
Как показано на рисунке, привязка выполняется в несколько этапов. 1. Регистрация конечной точки. 2. Регистрация службы. 3. Поиск сервера службы каталогов. 4. Запрос конечной точки. 5. Выполнение вызова RPC. Предположим, клиенту требуется привязка к серверу видеоинформации, локально доступному под именем /local/multimedia/video/movies. Он передает это
2.3. Обращение к удаленным объектам 111
При необходимости система DCE дает клиенту возможность усложненного поиска необходимого сервера. Безопасность RPC также входит в ее задачи. Выполнение вызова RPC Реальный вызов RPC происходит прозрачно и обычным образом. Клиентская заглушка выполняет маршалинг параметров в том порядке, который необходим для библиотечных функций, осуществляющих передачу с использованием выбранного при привязке протокола. Когда сообщение приходит на машину с серверами, оно передается нужному серверу в соответствии с содержащейся в сообщении конечной точкой. Библиотека времени выполнения передает сообщение серверной заглушке, которая выполняет демаршалинг параметров и вызывает сервер. Ответ отправляется назад по тому же маршруту. DCE предоставляет программистам некоторые семантические возможности. По умолчанию поддерживается одноразовая операция (at-most-once operation), в соответствие с которой ни один вызов не может осуществляться более одного раза, даже в случае краха системы. На практике это означает, что если сервер в ходе вызова RPC «рухнул», а затем был быстро восстановлен, клиент не должен повторять операцию, поскольку она, возможно, уже выполнена. С другой стороны, можно пометить (в файле IDL) удаленную процедуру как идемпотентную (idempotent), в этом случае не возбраняются многочисленные повторы запросов. Так, например, чтение некоторого блока из файла можно повторять снова и снова, пока оно не будет успешно закончено. Если выполнение идемпотентного блока из-за сбоя сервера срывается, клиент может подождать перезагрузки сервера и сделать новую попытку. Также имеется и другая (редко используемая) семантика, включающая в себя широковещательные рассылки вызовов RPC всем машинам текущей локальной сети. Мы вернемся к семантике RPC в главе 7 при рассмотрении работы RPC в условиях сбоев.
|
||
|
|
Последнее изменение этой страницы: 2016-09-19; просмотров: 579; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.141 (0.016 с.) |

 Когда сообщение приходит на сервер, заглушка исследует сообщение в поисках указания на то, какую процедуру следует вызвать, а затем делает соответствующий вызов. Если сервер поддерживает и другие удаленные процедуры, серверная заглушка должна содержать инструкцию типа switch для выбора вызываемой процедуры в зависимости от первого поля сообщения. Реальный вызов процеду-гы сервера из серверной заглушки выглядит почти как первоначальный клиеит-cкнй вызов, если не считать того, что параметрами являются переменные, инициализированные значениями, взятыми из сообщения.
Когда сообщение приходит на сервер, заглушка исследует сообщение в поисках указания на то, какую процедуру следует вызвать, а затем делает соответствующий вызов. Если сервер поддерживает и другие удаленные процедуры, серверная заглушка должна содержать инструкцию типа switch для выбора вызываемой процедуры в зависимости от первого поля сообщения. Реальный вызов процеду-гы сервера из серверной заглушки выглядит почти как первоначальный клиеит-cкнй вызов, если не считать того, что параметрами являются переменные, инициализированные значениями, взятыми из сообщения.
 чит работу, оригинальное сообщение будет отослано назад, клиентской заглушке, которая скопирует буфер клиенту. В результате вызов по ссылке будет подменен копированием/восстановлением. Несмотря на то что это не одно и то же, часто такой замены вполне достаточно.
чит работу, оригинальное сообщение будет отослано назад, клиентской заглушке, которая скопирует буфер клиенту. В результате вызов по ссылке будет подменен копированием/восстановлением. Несмотря на то что это не одно и то же, часто такой замены вполне достаточно.

 2.2.3. Расширенные модели RPC
2.2.3. Расширенные модели RPC К сожалению, разработчики приложений часто нуждаются в сведениях о том, выполняется ли данный вызов в текущем процессе, в другом процессе на этой же машине или в удаленном процессе.
К сожалению, разработчики приложений часто нуждаются в сведениях о том, выполняется ли данный вызов в текущем процессе, в другом процессе на этой же машине или в удаленном процессе.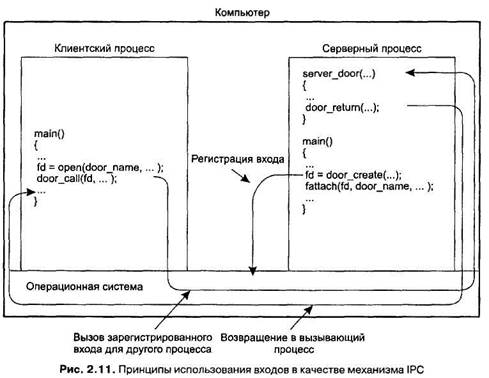
 от сервера этого подтверждения. На рис. 2.12, а приведен стандартный алгоритм взаимодействия «запрос-ответ», а на рис. 2.12, б — алгоритм взаимодействия клиента и сервера в случае асинхронного вызова RPC.
от сервера этого подтверждения. На рис. 2.12, а приведен стандартный алгоритм взаимодействия «запрос-ответ», а на рис. 2.12, б — алгоритм взаимодействия клиента и сервера в случае асинхронного вызова RPC.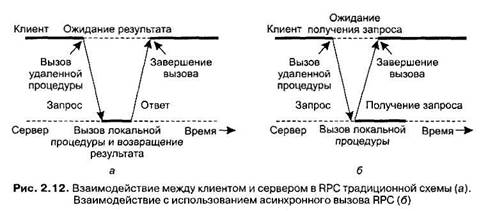
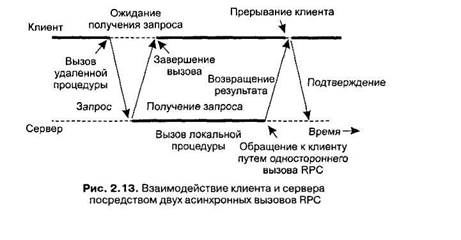
 Следует отдельно отметить вариант асинхронного вызова RPC, реализующегося в тех случаях, когда клиент продолжает работу немедленно после посылки запроса на сервер. Другими словами, клиент не ожидает от сервера подтверждения в получении запроса. Мы будем называть такие вызовы односторонними вызовами RPC (one-way RPC). Проблема такого подхода состоит в том, что при отсутствии гарантий надежности клиент не может быть точно уверен, что его запрос будет выполнен. Мы вернемся к этому вопросу в главе 7.
Следует отдельно отметить вариант асинхронного вызова RPC, реализующегося в тех случаях, когда клиент продолжает работу немедленно после посылки запроса на сервер. Другими словами, клиент не ожидает от сервера подтверждения в получении запроса. Мы будем называть такие вызовы односторонними вызовами RPC (one-way RPC). Проблема такого подхода состоит в том, что при отсутствии гарантий надежности клиент не может быть точно уверен, что его запрос будет выполнен. Мы вернемся к этому вопросу в главе 7.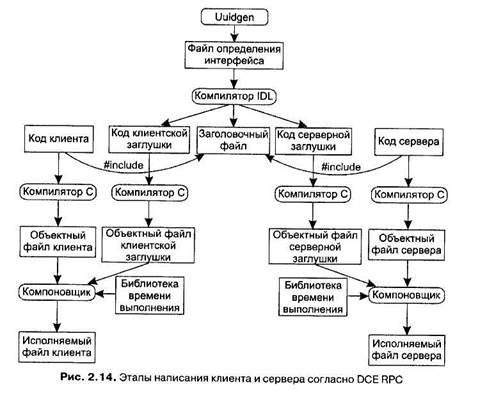
 или к старой версией правильного сервера, сервер обнаружит ошибку и привязки не произойдет.
или к старой версией правильного сервера, сервер обнаружит ошибку и привязки не произойдет.



