Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Сравнение возможностей деревьев решений и индукции правилСодержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте
Индукция правил и деревья решений, будучи способами решения одной задачи, значительно отличаются по своим возможностям. Несмотря на широкую распространенность деревьев решений, индукция правил по ряду причин, представляется более предпочтительным подходом. 1. Деревья решений часто довольно сложны и тяжелы для понимания. Quinlan [57] заметил, что даже усеченные деревья решений могут быть чересчур громоздкими, усложненными и запутанными, чтобы обеспечить прямой доступ к знаниям, и поэтому изобретал процедуры упрощения деревьев решений путем приведения их к ограниченным наборам порождающих правил (продукций) [58, 57]. 2. Непременное требование неперекрываемости правил в алгоритмах обучения деревьев решений навязывает жесткое ограничение на возможность выражения существующих закономерностей. Одна из проблем, вытекающих из этого ограничения - проблема дублированного поддерева [51]. Часто случается, что идентичные поддеревья оказываются в процессе обучения в разных местах дерева решений вследствие фрагментации пространства исходных примеров, обязательной по ограничению на неперекрываемость правил. Индукция отделения и захвата не ставит такого ограничения и, следовательно, менее чувствительна к этой проблеме. Например, можно легко проверить, что записанный в виде двух правил концепт: x:- a = 3, b = 3. x:- c = 3, d = 3. имеет минимальное эквивалентное дерево решений, содержащее 10 внутренних узлов и 21 терминальный при предположении, что атрибуты a... d имеют каждый по три возможных значения. Следовательно, из-за того, что порядок проверок значений различных атрибутов при спуске к терминальной вершине по дереву решений строго последователен, многие простые закономерности в них оказываются по существу потерянными, поскольку разделяются на дублированные поддеревья и затем чаще всего удаляются на стадии подрезания, вследствие чего прогностическая точность классификации таким деревом решений значительно ухудшается по сравнению с набором правил. 3. Построение деревьев решений затруднено при большом количестве исходной информации (что чаще всего имеет место при интеллектуальном анализе хранилищ данных). Для решения этой проблемы часто выделяют относительно небольшое подмножество имеющихся обучающих примеров и на его основе сооружают дерево решений. Такой подход во многих случаях приводит к потере информации, скрытой в проигнорированных при индукции примерах.
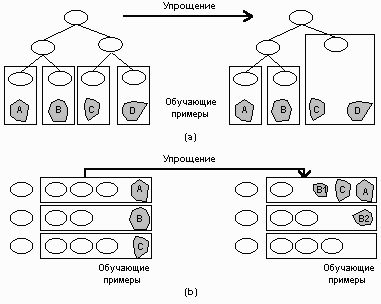
С другой стороны, индукция правил осуществляется значительно более сложными (и медленными) алгоритмами, чем индукция деревьев решений. Особенно большие трудности возникают с поступрощением построенной теории, в отличие от простоты подрезания деревьев решений, на что обратил внимание Furnkranz: отсечение ветвей в дереве решений никогда не затронет соседние ветви, тогда как отсечение условий правила оказывает влияние на все перекрывающиеся с ним правила (рис. 9). Рис. 9. Поступрощение в обучающих алгоритмах (a) разделения и захвата и (b) отделения и захвата.
Рис. 9(a) иллюстрирует работу поступрощения в индукции деревьев решений. Правая половина переусложненного дерева покрывается множествами C и D обучающих примеров. Когда упрощающий алгоритм решает отсечь эти две терминальные вершины, порождающий их узел становится терминальным, который теперь покрывается примерами. Левая ветвь дерева решений не затронута данной операцией. С другой стороны, отсечение условий от правила означает его обобщение, то есть в новом виде оно будет покрывать больше положительных и больше отрицательных примеров. Следовательно, эти дополнительные положительные и отрицательные примеры должны быть исключены из обучающего множества, дабы не воздействовать на индукцию последующих правил. В случае на рис. 9(b) первое из трех правил упрощается и начинает покрывать не только примеры, покрываемые оригинальной версией, но и все примеры, которые покрывает третье правило, а также часть примеров, которые покрывает второе правило. Если третье правило после этого может быть просто удалено алгоритмом поступрощения, то ситуация с оставшимся множеством примеров B2 не такая простая. Второе правило, естественно, покрывает все примеры множества B2, потому что оно было произведено для покрытия примеров включающего его множества B. Однако вполне может статься, что другое правило окажется более подходящим для отделения положительных примеров B2 от оставшихся отрицательных примеров. Корректная обработка таких ситуаций требует тесной интеграции процессов предупрощения и поступрощения, значительно усложняющей алгоритм индукции правил и ухудшающей его производительность.
Следовательно, исходя из проведенного сравнения, можно заключить, что построение деревьев решений оправдано в несложных задачах при небольшом количестве исходной информации благодаря простоте и быстроте их индукции. Однако при анализе больших объемов данных, накопленных в хранилищах, использование методов индукции правил предпочтительнее, несмотря на их относительную сложность.
Таблица 2 Поставщики средств отбора данных
Процесс обнаружения знаний дает возможность извлечь смысл из большего количества информации, чем в состоянии охватить человеческий мозг. Он позволяет человеку и компьютеру делать то, что каждый из них делает лучше всего. Человек определяет тип проблемы, которая требует внимания. Алгоритм отбора данных выявляет шаблоны и тенденции в море информации, слишком обширном для того, чтобы человек мог в нем ориентироваться. А затем человек снова решает, как лучше всего использовать полученную информацию.
В ы в о д ы
1. Наиболее популярные аналитические инструменты Data Mining в ряде случаев оказываются не способны решать даже простейшие задачи. 2. Применяющиеся подходы к обнаружению знаний в базах данных выявляют лишь усеченные фрагменты истинных логических закономерностей. 3. Известные системы для поиска логических правил не поддерживают функцию обобщения найденных правил и функцию поиска оптимальной композиции таких правил. Вместе с тем, указанные функции являются весьма существенными для построения баз знаний, требующих умения вводить понятия, метапонятия и семантические отношения на основе множества фрагментов знаний о предметной области.
Средства data mining предполагают оказание помощи организациям в нахождении скрытых зависимостей в данных. Получаемые модели можно использовать как для предсказания будущих значений, так и для описания текущего состояния. Однако, средства data mining не могут работать без сопровождения пользователей, которые хорошо понимают деловую область, сами данные и общий характер используемых аналитических методов. Результат применения методов нахождения нового знания может проявляться в широком спектре, от увеличения доходов, до уменьшения расходов.
Построение модели, это только один шаг в процессе нахождения нового знания. Для получения корректных результатов необходимо собрать и подготовить данные и проверить модель в реальном мире. Наилучшую модель можно найти после построения моделей различных типов по разным технологиям. Процесс обнаружения знаний дает возможность извлечь смысл из большего количества информации, чем в состоянии охватить человеческий мозг. Он позволяет человеку и компьютеру делать то, что каждый из них делает лучше всего. Человек определяет тип проблемы, которая требует внимания. Алгоритм отбора данных выявляет шаблоны и тенденции в море информации, слишком обширном для того, чтобы человек мог в нем ориентироваться. А затем человек снова решает, как лучше всего использовать полученную информацию. Как видно из сделанного обзора, ни один из рассмотренных методов не способен покрыть все задачи, обеспечивающие поддержку принятия управленческих решений на основе интеллектуального анализа содержимого хранилищ данных. Но большинство существующих на рынке систем интеллектуального анализа реализуют один-три метода (например, Pilot Discovery Server фирмы Pilot Software Inc. и Information Harvester фирмы Information Harvester Corp. - только деревья решений, Idis фирмы Information Discovery Inc. - деревья решений и индукцию правил, Darwin фирмы Thinking Machines - нейронные сети, деревья решений и визуализацию данных, MineSet фирмы Silicon Graphics - деревья решений, индукцию ассоциативных правил и визуализацию данных), поэтому в реальных приложениях для того, чтобы не потерять большое количество значимых закономерностей, приходится, как правило, пользоваться несколькими разнородными инструментами. Кроме того, многие инструменты не позволяют напрямую работать с хранилищами данных, требуя предварительной подготовки исходных данных для анализа в виде плоских файлов фиксированной структуры, что также затрудняет их практическое использование.
ИСПОЛЬЗУЕМАЯ ЛИТЕРАТУРА 1. Дюк В.А., Самойленко А.П. Data Mining: учебный курс – СПб: “Питер”, 2001. – 368 с
2. J. Ross Quinlan. C4.5: Programs for Machine learning. Morgan Kaufmann Publishers 1993 3. S.Murthy. Automatic construction of decision trees from data: A Multi-disciplinary survey 1997 4. W. Buntine. A theory of classification rules. 1992 5. Machine Learning, Neural and Statistical Classification. Editors D. Mitchie et.al. 1994 6. К. Шеннон. Работы по теории информации и кибернетике. М. Иностранная литература, 1963 7. С.А. Айвазян, В.С Мхитарян Прикладная статистика и основы эконометрики, М. Юнити, 1998
8. http://glossary.basegroup.ru/a/id3.htm 9. http://ai-online.narod.ru/documents/doc-msc-006.html 10. http://datadiver.nw.ru/Articles/DevDM.htm 11. http://www.basegroup.ru/trees/description.html
12. h ttp://raai.org/razrabotki.htm.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-08-15; просмотров: 500; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.218.150.72 (0.007 с.) |