Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Data Mining. Определение, назначение и решаемые задачи.Содержание книги
Поиск на нашем сайте
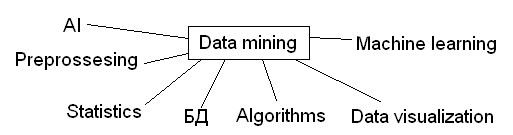
Data mining – добыча данных. Data mining – это процесс выделения их данных неявной объективной и практически полезной информации и представление ее в виде, пригодном для использования. Data mining включает в себя множество концепций:
Цели Data mining- разработка алгоритма анализа данных, начиная от предобработки данных и заканчивая визуализацией. Примерами задач Data mining могут быть: - какие факторы лучше всего предсказывают несчастный случай - как отличается поведение украденной кредитной карточки - какие характеристики отличают клиентов, которые в последующем отказались от услуг организации выделяют 5 стандартных типов закономерностей, которые позволяют выявить методы Data Mining: 1) ассоциация – закономерность, возникающая в том случае, если несколько событий связаны друг с другом. Поиск закономерностей осуществляется не на основе свойств анализируемого объекта, а между несколькими событиями, которые происходят последовательно или параллельно. Наиболее известный алгоритм выявления ассоциаций – Apriori 2) Классификация – с ее помощью выявляются признаки, характеризующие группу, к которой принадлежит тот или иной объект. По этим признакам новый объект можно отнести к той или иной группе. Методы – НС, метод ближайшего соседа, байесовские сети. 3) кластеризация – отличается от классификации тем, что сами группы заранее не заданны. DM самостоятельно выделяет группы на основе набора признаков. результатом кластеризации является разбиение на группы. 4) Последовательность - выделение связанных во времени событий 5) прогнозирование – на основе имеющихся данных оцениваются пропущенные и значащие значения числовых показателей. Data Mining. Классификация. Data mining – это процесс выделения их данных неявной объективной и практически полезной информации и представление ее в виде, пригодном для использования. выделяют 5 стандартных типов закономерностей, которые позволяют выявить методы Data Mining: 1) ассоциация 2) классификация 3) кластеризация 4) Последовательность 5) прогнозирование С помощью классификации выявляются признаки, характеризующие группу, к которой принадлежит тот или иной объект. По этим признакам новый объект можно отнести к той или иной группе. Цель процесса классификации состоит в том, чобы построить модель, которая использует прогнозирующие атрибуты в качестве входных параметров и на выходе получает значение зависимого атрибута. Классификатор – некая сущность, определяющая, какому из предопределенных классов принадлежит объект по вектору признаков. Процесс классификации в общем случае состоит из 2 этапов: 1) Конструирование модели – описание множества предопределенных классов 2) использование модели – классификация новых или неизвестных знаний, оценка правильности и точности модели. Уровень точности – процент правильно классифицированных примеров в тестовом множестве. Тестовое множество не должно зависеть от обучающего множества. Методы, применяемые для решения задач классификации: 1) деревья решений 2) искусственные НС 3) Байесовская классификация 4) метод опорных векторов 5) статистические методы, в частности, линейная регрессия 6) генетические алгоритмы 7) метод ближайшего соседа Точность классификации – оценка уровня ошибок. Оценка точности классификации может производиться при помощи кросс-проверки (процедуры оценки точности классификации на данных из тестового множества и кросс-проверочного множества) Если точность классификации на обучающей выборке примерно равна точности на проверочной, то модель прошла кросс-проверку. Оценивание методов классификации можно проводить из следующих характеристик: 1) скорость создания модели для классификации и скорость ее использования 2) Робастность – устойчивость к данным с помехами 3) Интерпретируемость – возможность понимания модели аналитиком 4) Надежность Data Mining. Кластеризация. Data mining – это процесс выделения их данных неявной объективной и практически полезной информации и представление ее в виде, пригодном для использования. выделяют 5 стандартных типов закономерностей, которые позволяют выявить методы Data Mining: 1) ассоциация 2) классификация 3) кластеризация 4) Последовательность 5) прогнозирование Кластеризация предназначена для разбиения совокупности объектов на отдельные группы. Кластеризация отличается от классификации тем, что сами группы заранее не заданны. DM самостоятельно выделяет группы на основе набора признаков. результатом кластеризации является разбиение на группы. Цель кластеризации – поиск соответствующих структур данных. Кластеризация является описательной процедурой и не делает никаких статистических выводов, но позволяет изучить внутреннюю структуру данных, которые исследуются. Кластером можно считать группу объектов, в которой присутствует: 1) внутренняя однородность 2) Внешняя изолированность Подходы к кластеризации: алгоритмы, основанные на разделении данных (в том числе итеративные): 1) разделение объектов на k-кластеры и итеративное перераспределение объектов для улучшения кластеризации 2) Методы, основанные на концентрации объектов 3) Грит-методы – основаны на квантовании объектов в грит-стуктуры 4)Иерархические алгоритмы, например, агломерация 5) Модельные методы Оценка качества кластеризации: Используются следующие процедуры: 1) ручная провурка 2) Установление контрольных точек и проверка не полученных кластерах 3) Проверка стабильности кластеризации путем добавления новых переменных или объектов 4)Сравнение полученных кластеров с использованием различных методов
|
||||
|
|
Последнее изменение этой страницы: 2016-08-14; просмотров: 285; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.145.80.247 (0.006 с.) |