Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Відображення фізичних даних за допомогою їх логічного представленняСодержание книги
Поиск на нашем сайте
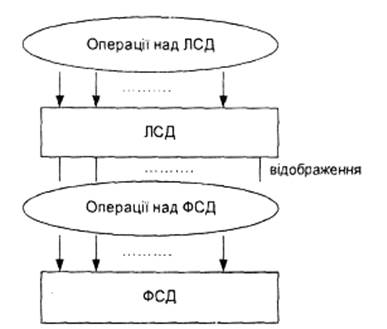
Розрізняють наступні рівні опису даних: • абстрактний (математичний) рівень; • логічний рівень; • фізичний рівень. Логічний рівень (ЛСД) – подання структури даного на тій чи іншій мові програмування. Фізичний рівень (ФСД) — відображення у пам'ять комп'ютера інформаційного об'єкту відповідно до логічного описування. Оскільки пам'ять комп'ютера обмежена, то виникають питання розподілу пам'яті й керування нею. Логічний і фізичний рівні відрізняються один від одного, тому в обчислювальних системах здійснюється відображення фізичного рівня на логічний і навпаки (рис 3.1.).
Рис. 3.1. Зв'язок між логічним та фізичним рівнями подання СД.
Будь-яка структура на абстрактному рівні може бути подана у вигляді двійки <D,R>, де D - скінчена множина елементів, які можуть бути типами даних або структурами даних, a R - множина відношень, властивості якої визначають різні типи структур даних на абстрактному рівні.
Визначення структур даних Структура даних (СД) - загальна властивість інформаційного об'єкта, з яким взаємодіє та або інша програма. Ця загальна властивість характеризується: • множиною допустимих значень цієї структури; • набором допустимих операцій; • характером організованості. Найпростіші структури дацих називаються також типами даних. У програмуванні та комп'ютерних науках структури даних—це способи організації даних у комп'ютерах. Часто разом зі структурою даних пов'язується і специфічний перелік операцій, які можуть бути виконаними над даними, організованими в таку структуру. Правильний підбір структур даних є надзвичайно важливим для ефективного функціонування відповідних алгоритмів їх опрацювання. Добре побудовані структури даних дозволяють оптимізувати використання машинного часу та пам'яті комп'ютера для виконання найбільш критичних операцій. Відома формула ≪Програма = Алгоритми + Структури даних≫ дуже точно виражає необхідність відповідального ставлення до такого підбору. Тому іноді навіть не обраний алгоритм для опрацювання масиву даних визначає вибір тієї чи іншої структури даних для їх збереження, а навпаки. Структури даних поділяються на вбудовані (реалізовані в мовах програмування) та похідні (утворюються користувачами). Класифікація СД у програмах користувача та пам'яті комп'ютера подана на рис. 3.2.
Рис. 3.2. Класифікація СД
Важливою ознакою для класифікації є зміна структур даних під час виконання програми. Наприклад, якщо змінюється кількість елементів і/або відношення між ними, то такі структури даних називаються динамічними, інакше – статичними.
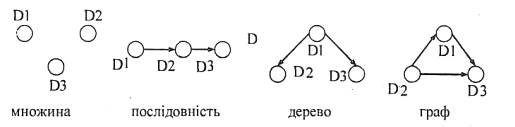
Найпростіші стандартні та складені типи даних. Перелік спискових типів даних, до яких належать: лінійні списки, деревоподібні структури та графи Складеним типом даних назвемо тип даних, що складається із скінченної та наперед заданої множини елементів певного типу, які не обов'язково є атомарними. Перерахуємо складені типи даних та дамо їм коротку характеристику. Множина – скінчена сукупність елементів, в якої R = Ø. Послідовність — абстрактна структура, у якої множина R складається з одного відношення лінійного порядку (тобто для кожного елемента, крім першого і останнього, є попередній і наступний елементи). Матриця – структура, в якої множина R складається із двох відношень лінійного порядку. Дерево – множина R складається з одного відношення ієрархічного порядку. Граф – множина R складається з одного відношення бінарного порядку. Гіперграф – множина R складається із двох і більше відношень різного порядку. Приклади СД подано на рис. 3.3.
Рис. 3.3. Приклади подання структур даних
Прикладом гіперграфа є мережа Петрі - дводольний граф, який складається з двох типів вершин: станів, які мають певну кількість фішок, та переходів, що перерозподіляють фішки у станах залежно від кількості вхідних та вихідних дуг.
Тема 2. Середовище бази даних 1. Архітектура бази даних 2. Моделі даних 3. Програмні і мовні засоби баз даних 4. Архітектура інформаційної системи
Архітектура бази даних Для організації роботи з БД необхідно забезпечити незалежність прикладних програм від даних. Це обумовлено тим, що при зміні системи, а також з метою забезпечення ефективного обслуговування користувачів необхідно виконувати роботи щодо зміни методів зберігання даних в БД, шляхів доступу до даних, змінювати структури і формати даних та зв'язки між ними. Якщо не застосовувати спеціальні підходи і при написанні застосувань вводити програмний опис методів доступу, засобів зберігання даних, формати даних, то при будь-якій зміні в БД для перелічених випадків буде необхідно корегувати текст програми користувача, що потребує значних витрат. Незалежність застосувань від даних забезпечується засобами СУБД. Цей підхід базується на тому, що користувачі застосовуючи БД, не знають внутрішнє представлення даних. На рис. 1.1 показана трирівнева модель архітектури СУБД, що була запропонована Комітетом планування стандартів і норм SPARC (Standarts Planning and Requirements Committee) Американського національного інституту стандартів ANSI (American National Standarts Institute). Опис структури даних на будь-якому рівні називається схемою. Існує три різних типи схем БД, які визначаються згідно з рівнями абстракції архітектури СУБД. На самому верхньому рівні є декілька зовнішніх схем, які відповідають різним представленням даних. Цей рівень визначає точку зору на БД окремих застосувань. Кожне застосування бачить і обробляє тільки ті дані, які необхідні цьому застосуванню.
Рис. 2.1. Трирівнева архітектура СУБД
На концептуальному рівні опис БД називається концептуальною схемою. Тут БД представлена в найбільш загальному вигляді, який об'єднує дані, що використовуються всіма застосуваннями, які працюють з БД. Фактично концептуальний рівень відображає модель предметної області, для якої створювалася БД. На внутрішньому рівні опис БД називається внутрішньою схемою. Тут БД представлена у вигляді безпосередньо даних, що розташовані в файлах, які відповідають фізичній організації БД. Трирівнева архітектура СУБД дозволяє забезпечити незалежність від даних. Це означає, що зміни на нижніх рівнях не впливають на верхні рівні. Розрізняють логічну і фізичну незалежність при роботі з даними. Логічна незалежність від даних означає захищеність зовнішніх схем від змін, що вносяться в концептуальну схему. Зміни концептуальної схеми БД не викликають необхідності в корегуванні існуючих зовнішніх схем для користувачів, і відповідно не викликають змін в застосуваннях, що працюють з цими схемами. Фізична незалежність від даних означає захищеність концептуальної і зовнішніх схем від змін, що вносяться у внутрішню схему. До змін внутрішньої схеми належать використання різних файлових систем або структур даних, різних пристроїв зберігання, модифікація пошукових структур тощо. Крім трьох названих рівнів абстрагування в БД існує ще один рівень, що передує їм. Цей рівень відображає інформацію про предметну область, а модель цього рівня називається інфологічною моделлю предметної області. Таким чином головними рівнями абстрагування в БД є рівні: • інфологічний; • зовнішній; • концептуальний; • внутрішній. Перехід від одного рівня абстрагування до наступного і складає в загальному вигляді процес проектування БД.
Моделі даних Модель даних – це деяка абстракція, в якій знаходять своє відображення найбільш важливі аспекти функціонування визначеної предметної області, адругорядні – ігноруються. Модель даних являє собою деяку цільову модель предметної області. У моделі даних розрізняють три головні складові: • структурна частина, яка визначає правила породження допустимих для даної СУБД видів структур даних; • управляюча частина, яка визначає можливі операції над такими структурами; • класи обмежень цілісності даних, які можуть бути реалізовані засобами цієї системи. Моделювання даних – це процес створення логічного представлення структури бази даних. На рис. 2.2 показана класифікація моделей даних.
Рис. 2.2. Класифікація моделей даних
Кожному рівню представлення інформації відповідає певна модель. Інфологічна модель –відображає інформацію пропредметну область у вигляді незалежному від СУБД, що використовується. Ця модель відображає інформаційно-логічний рівень абстрагування, який пов'язаний з описом об'єктів предметної області, їх властивостей і взаємозв'язків. Часто ці моделі ототожнюють з концептуальними моделями предметної області і називають концептуальними інфологічними моделями (внутрішня і зовнішня концептуальніінфологічні моделі). Даталогічна модель –модель логічного рівня,якавідображає логічні зв'язки між елементами даних безвідносно до їх змісту і середовища збереження. Часто ці моделі ототожнюють з логічними моделями. Фізична модель –описує те,як дані зберігаються вкомп'ютері, представляючи інформацію про структуру записів, їх впорядкованість і про існуючі шляхи доступу до даних. Модель " сутність-зв'язок " (ER-модель) – описує модель предметної області і складається з множини сутностей, множини звязків між сутностями, а також з атрибутів сутностей і зв'язків. В модель входить обмеження цілісності даних, що пов'язано з двома множинами сутностей і називається залежністю по існуванню. ER-моделі дозволяють графічно представляти моделі предметних областей. Вони є складовою частиною багатьох CASE-продуктів. Семантична об'єктна модель–описує модель предметноїобласті і являє собою модель даних. Ця модель складається з семантичних об'єктів, що містять сукупність атрибутів. Атрибути групуються у класи. Модель даних володіє більш розвиненими засобами відображення семантики у порівнянні з теоретико-множинними і теоретико-графовими моделями. Теоретико-графова модель–модель даних,в якійдозволені структури даних можуть бути представлені у вигляді графа загального або спеціального виду, наприклад дерева. Необхідну групу операцій на мові маніпулювання даними, що засновані на цій моделі, представляють навігаційні операції. Операції над даними мають позаописовий характер. Теоретико-множинна модель–модель даних,в якійвикористовується математичний апарат реляційної алгебри, реляційного обчислення, а операції над даними маніпулюють таблицями. Фактографічні моделі–містять відомості,якіпредставлені у вигляді спеціальним чином організованих сукупностей формалізованих записів даних. Документальні моделі–передбачають,що в якостіодиничного елемента інформації виступає неподільний на менші складові частини документ, а інформація про документ, як правило, не структурується, або структурується в обмеженому вигляді. В цих моделях в основному розглядаються тексти на природній мові, формати документів є вільними. Ієрархічна модель–модель даних в основі якоївикористовується ієрархічна, деревоподібна структура даних. Вершинами цієї структури є записи, які складаються з простих елементів даних різних типів. Батьківському запису відповідає довільне число екземплярів підлеглих записів кожного типу. Мережна модель–модель даних,в якій дозволеніструктури даних можуть бути представлені у вигляді графа загального вигляду. Вершинами такого графа можуть бути дані різних типів – від атомарних елементів даних до записів складної структури. На відміну від ієрархічної моделі наступник в цій моделі може мати довільне число батьків. Реляційна модель–модель даних,яка заснована наматематичному понятті відношення і представленні відношень у формі таблиць. Постреляційна модель–розширена реляційна модель,яказнімає обмеження неподільності даних, що зберігаються в записах таблиць. Ця модель допускає багатозначні поля – поля, значення яких складається з підзначень. Набір значень багатозначних полів вважається самостійною таблицею, яка вбудована в основну таблицю. Часто ці моделі ототожнюють з об'єктно-реляційними моделями. Об'єктно-орієнтована модель–модель даних,якабазується на понятті об'єкта, тобто сутності, що володіє станом і поведінкою. Стан об'єкта визначається його атрибутами, а поведінка визначається сукупністю операцій, що визначені для цього об'єкта. Також передбачається можливість підтримки зв'язків між типами об'єктів. Багатомірна модель–модель даних,яка оперуєбагатомірним представленням даних (у вигляді гіперкубу) і орієнтована на підтримку аналіза даних. Передбачається конструювання різноманітних агрегацій даних у межах гіперкубу, побудова різних його проекцій – підмножин гіперкубу, деталізація і обертання даних, а також цілий ряд інших операцій. Дескрипторна модель–описує кожен документ задопомогою дескриптора. Дескриптор має жорстку структуру і являє собою набори деяких лексичних одиниць (слов, словосполучень, термінів), які потрібні для роботи з документами. Дескриптори між собою не зв'язані. Тезаурусна модель–описує кожен документ задопомогою дескрипторів, а також змістовних відношень між лексичними одиницями (ціле-частина, род-вид, клас-підклас і т.ін.). Ці моделі дозволяють підвищити ефективність дескрипторних моделей за рахунок більш ефективного відображення предметної області. Гіпертекстова модель–модель,що заснована на розмітцідокумента за допомогою спеціальних навігаційних конструкцій, які відповідають змістовим зв'язкам між різними документами, або окремими фрагментами одного документа. Такі конструкції утворюють деяку семантичну мережу в базі документів.
|
||||
|
|
Последнее изменение этой страницы: 2016-07-16; просмотров: 935; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.15.141.155 (0.012 с.) |