Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Между программным и аппаратным обеспечениемСодержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте
Вопрос 1. Операцио́нная систе́ма — комплекс взаимосвязанных программ, предназначенных для управления ресурсами компьютера и организации взаимодействия с пользователем.
Основная функция всех ОС - посредническая. Она заключается в обеспечении интерфейсов: 1. пользователя (между пользователем и программно-аппаратными средствами По реализации интерфейса пользователя ОС подразделяются на графические и неграфические. Неграфические используют интерфейс командной строки, основным устройством управления которого является клавиатура. Управляющие команды вводятся в поле командной строки. Графические ОС реализуют более сложный тип интерфейса. Работа в графическом интерфейсе основана на взаимодействии активных и пассивных экранных элементов управления. В качестве активного элемента выступает указатель мыши, а в качестве пассивных выступают графические элементы управления приложением: кнопки, значки, переключатели, флажки, меню и т.д. Между программным и аппаратным обеспечением Между разными видами программного обеспечения Обеспечение автоматического запуска Все ОС обеспечивают свой автоматический запуск. Для дисковых ОС в специальной(системной) области диска создаётся запись программного кода. Обращение к этому коду происходит из BIOS. Завершая свою работу программы BIOS дают команду на загрузку и исполнение системной области диска. Диск с системной областью называется системным. На компьютере должен быть как минимум один системный диск.
Организация файловой системы Обслуживание файловой структуры. 1. Создание файлов 2. Создание каталогов 3. Навигация по файловой структуре
Управление приложениями. Обслуживание компьютера - одна из важных функций ОС. Средства проверки диска бывают двух типов - проверка целостности файловой структуры и проверка физической поверхности диска. Ошибки файловой структуры устраняются средствами ОС. Физические дефекты ОС локализует и исключает их из активной работы. Возможность ошибок файловой системы зависит от её типа. Например, схема организации работы в NTFS вообще исключает возможность появления ошибок в файловой структуре. В системе FAT часто появляются ошибки типа "потерянных кластеров" или "общих кластеров".
Вопрос 2. Монолитное ядро По сути дела, операционная система – это обычная программа, поэтому было бы логично и ее организовать так же, как устроено большинство программ, то есть составить из процедур и функций. В этом случае компоненты операционной системы являются не самостоятельными модулями, а составными частями одной большой программы. Такая структура операционной системы называется монолитным ядром (monolithic kernel) Монолитное ядро представляет собой набор процедур, каждая из которых может вызвать каждую. Все процедуры работают в привилегированном режиме. Таким образом, монолитное ядро – это такая схема операционной системы, при которой все ее компоненты являются составными частями одной программы, используют общие структуры данных и взаимодействуют друг с другом путем непосредственного вызова процедур. Для монолитной операционной системы ядро совпадает со всей системой. Во многих операционных системах с монолитным ядром сборка ядра, то есть его компиляция, осуществляется отдельно для каждого компьютера, на который устанавливается операционная система. При этом можно выбрать список оборудования и программных протоколов, поддержка которых будет включена в ядро. Так как ядро является единой программой, перекомпиляция – это единственный способ добавить в него новые компоненты или исключить неиспользуемые. Следует отметить, что присутствие в ядре лишних компонентов крайне нежелательно, так как ядро всегда полностью располагается в оперативной памяти. Кроме того, исключение ненужных компонентов повышает надежность операционной системы в целом. Монолитное ядро – старейший способ организации операционных систем. Примером систем с монолитным ядром является большинство Unix-систем. Даже в монолитных системах можно выделить некоторую структуру. Как в бетонной глыбе можно различить вкрапления щебенки, так и в монолитном ядре выделяются вкрапления сервисных процедур, соответствующих системным вызовам. Сервисные процедуры выполняются в привилегированном режиме, тогда как пользовательские программы – в непривилегированном. Для перехода с одного уровня привилегий на другой иногда может использоваться главная сервисная программа, определяющая, какой именно системный вызов был сделан, корректность входных данных для этого вызова и передающая управление соответствующей сервисной процедуре с переходом в привилегированный режим работы. Иногда выделяют также набор программных утили, которые помогают выполнять сервисные процедуры. Многоуровневые системы (Layered systems) Продолжая структуризацию, можно разбить всю вычислительную систему на ряд более мелких уровней с хорошо определенными связями между ними, так чтобы объекты уровня N могли вызывать только объекты уровня N-1. Нижним уровнем в таких системах обычно является hardware, верхним уровнем – интерфейс пользователя. Чем ниже уровень, тем более привилегированные команды и действия может выполнять модуль, находящийся на этом уровне. Впервые такой подход был применен при создании системы THE(Technishe Hogeschool Eindhoven) Дейкстрой (Dijkstra) и его студентами в 1968 г. Эта система имела следующие уровни:
Слоеные системы хорошо реализуются. При использовании операций нижнего слоя не нужно знать, как они реализованы – нужно лишь понимать, что они делают. Слоеные системы хорошо тестируются. Отладка начинается с нижнего слоя и проводится послойно. При возникновении ошибки мы можем быть уверены, что она находится в тестируемом слое. Слоеные системы хорошо модифицируются. При необходимости можно заменить лишь один слой, не трогая остальные. Но слоеные системы сложны для разработки: тяжело правильно определить порядок слоев и что к какому слою относится. Слоеные системы менее эффективны, чем монолитные. Так, например, для выполнения операций ввода-вывода программе пользователя придется последовательно проходить все слои от верхнего до нижнего. Виртуальные машины В начале мы говорили о взгляде на операционную систему как на виртуальную машину, когда пользователю не необходимости знать детали внутреннего устройства компьютера. Он работает с файлами, а не с магнитными головками и двигателем; он работает с огромной виртуальной, а не ограниченной реальной оперативной памятью; его мало волнует, единственный он на машине пользователь или нет. Рассмотрим несколько иной подход. Пусть операционная система реализует виртуальную машину для каждого пользователя, но не упрощая ему жизнь, а наоборот, усложняя. Каждая такая виртуальная машина предстает перед пользователем как голое железо – копия всего hardware в вычислительной системе, включая процессор, привилегированные и непривилегированные команды, устройства ввода-вывода, прерывания и т.д. И он остается с этим железом один на один. При попытке обратиться к такому виртуальному железу на уровне привилегированных команд в действительности, происходит системный вызов реальной операционной системы, которая и производит все необходимые действия. Такой подход позволяет каждому пользователю загрузить свою операционную систему на виртуальную машину и делать с ней все, что душа пожелает.
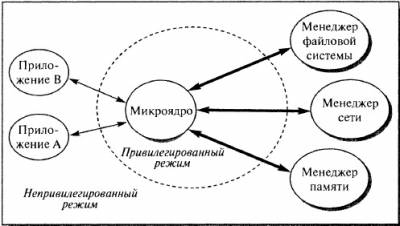
Вариант виртуальной машины Первой реальной системой такого рода была система CP/CMS, или VM/370, как ее называют сейчас, для семейства машин IBM/370. Недостатком таких операционных систем является снижение эффективности виртуальных машин по сравнению с реальным компьютером, и, как правило, они очень громоздки. Преимущество же заключается в использовании на одной вычислительной системе программ, написанных для разных операционных систем. Микроядерная архитектура Современная тенденция в разработке операционных систем состоит в перенесении значительной части системного кода на уровень пользователя и одновременной минимизации ядра. Речь идет о подходе к построению ядра, называемом микроядерной архитектурой (microkernel architecture) операционной системы, когда большинство ее составляющих являются самостоятельными программами. В этом случае взаимодействие между ними обеспечивает специальный модуль ядра, называемый микроядром. Микроядро работает в привилегированном режиме и обеспечивает взаимодействие между программами, планирование использования процессора, первичную обработку прерываний, операции ввода-вывода и базовое управление памятью.
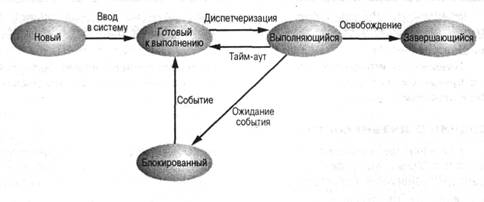
Рис. Микроядерная архитекту3ра операционной системы Остальные компоненты системы взаимодействуют друг с другом путем передачи сообщений через микроядро. Основное достоинство микроядерной архитектуры – высокая степень модульности ядра операционной системы. Это существенно упрощает добавление в него новых компонентов. В микроядерной операционной системе можно, не прерывая ее работы, загружать и выгружать новые драйверы, файловые системы и т.д. Существенно упрощается процесс отладки компонентов ядра, так как новая версия драйвера может загружаться без перезапуска всей операционной системы. Компоненты ядра операционной системы ничем принципиально не отличаются от пользовательских программ, поэтому для их отладки можно применять обычные средства. Микроядерная архитектура повышает надежность системы, поскольку ошибка на уровне непривилегированной программы менее опасна, чем отказ на уровне режима ядра. В то же время микроядерная архитектура операционной системы вносит дополнительные накладные расходы, связанные с передачей сообщений, что существенно влияет на производительность. Для того чтобы микроядерная операционная система по скорости не уступала операционным системам на базе монолитного ядра, требуется очень аккуратно проектировать разбиение системы на компоненты, стараясь минимизировать взаимодействие между ними. Таким образом, основная сложность при создании микроядерных операционных систем – необходимость очень аккуратного проектирования. Смешанные системы Рассмотренные подходы к построению операционных систем имеют свои достоинства и недостатки. В большинстве случаев современные операционные системы используют различные комбинации этих подходов. Так, например, ядро операционной системы Linux представляет собой монолитную систему с элементами микроядерной архитектуры. При компиляции ядра можно разрешить динамическую загрузку и выгрузку очень многих компонентов ядра – так называемых модулей. В момент загрузки модуля его код загружается на уровне системы и связывается с остальной частью ядра. Внутри модуля могут использоваться любые экспортируемые ядром функции. Другим примером смешанного подхода может служить возможность запуска операционной системы с монолитным ядром под управлением микроядра. Так устроены 4.4BSD и MkLinux, основанные на микроядреMach. Микроядро обеспечивает управление виртуальной памятью и работу низкоуровневых драйверов. Все остальные функции, в том числе взаимодействие с прикладными программами, осуществляются монолитным ядром. Данный подход сформировался в результате попыток использования преимущества микроядерной архитектуры, сохраняя по возможности хорошо отлаженный код монолитного ядра. Наиболее тесно элементы микроядерной архитектуры и элементы монолитного ядра переплетены в ядреWindows NT. Хотя Windows NT часто называют микроядерной операционной системой, это не совсем так. Микроядро NT слишком велико (более 1 Мбайт), чтобы носить приставку «микро». Компоненты ядра WindowsNT располагаются в вытесняемой памяти и взаимодействуют друг с другом путем передачи сообщений, как и положено в микроядерных операционных системах. В то же время все компоненты ядра работают в одном адресном пространстве и активно используют общие структуры данных, что свойственно операционным системам с монолитным ядром. По мнению специалистов Microsoft, причина проста: чисто микроядерный дизайн коммерчески невыгоден, поскольку неэффективен. Таким образом, Windows NT можно с полным правом назвать гибридной операционной системой. Вопрос 3. Классификация ОС Операционные системы могут различаться особенностями реализации внутренних алгоритмов управления основными ресурсами компьютера (процессорами, памятью, устройствами), особенностями использованных методов проектирования, типами аппаратных платформ, областями использования и многими другими свойствами. Ниже приведена классификация ОС по нескольким наиболее основным признакам. Вопрос 4. Состояния процессов: Выполняющийся. Процесс, который выполняется в текущий момент времени. В настоящей главе предполагается, что на компьютере установлен только один процессор, поэтому в этом состоянии может находиться только один процесс. Готовый к выполнению. Процесс, который может быть запущен, как только для этого представится возможность. Блокированный. Процесс, который не может выполняться до тех пор, пока не произойдет некоторое событие, например завершение операции ввода-вывода. Новый. Только что созданный процесс, который еще не помещен операционной системой в пул выполнимых процессов. Обычно это новый процесс, который еще не загружен в основную память. Завершающийся. Процесс, удаленный операционной системой из пула выполнимых процессов.
Вопрос 7. Этапы создания процесса Чтобы создать процесс надо:
В Unix Процессы создаются через две функции Fork() и exec() В Windows В ОС Windows процессы создаются через системный вызов NtCreatProcess() – данный вызов имеет множество параметров, многие из которых «по умолчанию». Процесс порождается непосредственно по желанию, он не должен быть обязательной копией текущего, поэтому не соблюдается родство.
Вопрос 8. Управляющий блок процесса – это набор атрибутов для управления процессом:
Идентификаторы процессов (родительского процесса, текущего процесса и процесса пользователя) Регистры пользователя: доступные для программ пользователя регистры процессора (от 8 до 32) управляющие регистры: счетчик команд, флаги условия, флаги состояния Указатели на стек: с каждым процессом связан свой стек, на который нужна ссылка управляющая информация процесса: состояние, приоритет, событие ожидания, флаги взаимодействия процессов, привилегии в выполнении каких-то действий, указатели на таблицы памяти... Вопрос 9. Для каждого уровня планирования процессов можно предложить много различных алгоритмов. Выбор конкретного алгоритма определяется классом задач, решаемых вычислительной системой, и целями, которых мы хотим достичь, используя планирование. К числу таких целей можно отнести следующие: · Справедливость – гарантировать каждому заданию или процессу определенную часть времени использования процессора в компьютерной системе, стараясь не допустить возникновения ситуации, когда процесс одного пользователя постоянно занимает процессор, в то время как процесс другого пользователя фактически не начинал выполняться. · Эффективность – постараться занять процессор на все 100% рабочего времени, не позволяя ему простаивать в ожидании процессов, готовых к исполнению. В реальных вычислительных системах загрузка процессора колеблется от 40 до 90%. · Сокращение полного времени выполнения (turnaround time) – обеспечить минимальное время между стартом процесса или постановкой задания в очередь для загрузки и его завершением. · Сокращение времени ожидания (waiting time) – сократить время, которое проводят процессы в состоянии готовность и задания в очереди для загрузки. · Сокращение времени отклика (response time) – минимизировать время, которое требуется процессу в интерактивных системах для ответа на запрос пользователя. Независимо от поставленных целей планирования желательно также, чтобы алгоритмы обладали следующими свойствами. · Были предсказуемыми. Одно и то же задание должно выполняться приблизительно за одно и то же время. Применение алгоритма планирования не должно приводить, к примеру, к извлечению квадратного корня из 4 за сотые доли секунды при одном запуске и за несколько суток – при втором запуске. · Были связаны с минимальными накладными расходами. Если на каждые 100 миллисекунд, выделенные процессу для использования процессора, будет приходиться 200 миллисекунд на определение того, какой именно процесс получит процессор в свое распоряжение, и на переключение контекста, то такой алгоритм, очевидно, применять не стоит. · Равномерно загружали ресурсы вычислительной системы, отдавая предпочтение тем процессам, которые будут занимать малоиспользуемые ресурсы. · Обладали масштабируемостью, т. е. не сразу теряли работоспособность при увеличении нагрузки. Например, рост количества процессов в системе в два раза не должен приводить к увеличению полного времени выполнения процессов на порядок. Многие из приведенных выше целей и свойств являются противоречивыми. Улучшая работу алгоритма с точки зрения одного критерия, мы ухудшаем ее с точки зрения другого. Приспосабливая алгоритм под один класс задач, мы тем самым дискриминируем задачи другого класса. "В одну телегу впрячь не можно коня и трепетную лань". Ничего не поделаешь. Такова жизнь.
Вопрос 10. Невытесняющее планирование используется, например, в MS Windows 3.1 и ОС Apple Macintosh. При таком режиме планирования процесс занимает столько процессорного времени, сколько ему необходимо. При этом переключение процессов возникает только при желании самого исполняющегося процесса передать управление (для ожидания завершения операции ввода-вывода или по окончании работы). Этот метод планирования относительно просто реализуем и достаточно эффективен, так как позволяет выделить большую часть процессорного времени для работы самих процессов и до минимума сократить затраты на переключение контекста. Однако при невытесняющем планировании возникает проблема возможности полного захвата процессора одним процессом, который вследствие каких-либо причин (например, из-за ошибки в программе) зацикливается и не может передать управление другому процессу. В такой ситуации спасает только перезагрузка всей вычислительной системы. Вытесняющее планирование обычно используется в системах разделения времени. В этом режиме планирования процесс может быть приостановлен в любой момент исполнения. Операционная система устанавливает специальный таймер для генерации сигнала прерывания по истечении некоторого интервала времени – кванта. После прерывания процессор передается в распоряжение следующего процесса. Временные прерывания помогают гарантировать приемлемое время отклика процессов для пользователей, работающих в диалоговом режиме, и предотвращают "зависание" компьютерной системы из-за зацикливания какой-либо программы. Вопрос 11. Вопрос 11. Round Robin (RR) Модификацией алгоритма FCFS является алгоритм, получивший название Round Robin (Round Robin – это вид детской карусели в США) или сокращенно RR. По сути дела, это тот же самый алгоритм, только реализованный в режиме вытесняющего планирования. Можно представить себе все множество готовых процессов организованным циклически – процессы сидят на карусели. Карусель вращается так, что каждый процесс находится около процессора небольшой фиксированный квант времени, обычно 10 – 100 миллисекунд (см. рис. 3.4.). Пока процесс находится рядом с процессором, он получает процессор в свое распоряжение и может исполняться.
Реализуется такой алгоритм так же, как и предыдущий, с помощью организации процессов, находящихся в состоянии готовность, в очередь FIFO. Планировщик выбирает для очередного исполнения процесс, расположенный в начале очереди, и устанавливает таймер для генерации прерывания по истечении определенного кванта времени. При выполнении процесса возможны два варианта. Вопрос 11. Shortest-Job-First (SJF) При рассмотрении алгоритмов FCFS и RR мы видели, насколько существенным для них является порядок расположения процессов в очереди процессов, готовых к исполнению. Если короткие задачи расположены в очереди ближе к ее началу, то общая производительность этих алгоритмов значительно возрастает. Если бы мы знали время следующих CPU burst для процессов, находящихся в состоянии готовность, то могли бы выбрать для исполнения не процесс из начала очереди, а процесс с минимальной длительностью CPU burst. Если же таких процессов два или больше, то для выбора одного из них можно использовать уже известный нам алгоритм FCFS. Квантование времени при этом не применяется. Описанный алгоритм получил название "кратчайшая работа первой" или Shortest Job First (SJF). SJF-алгоритм краткосрочного планирования может быть как вытесняющим, так и невытесняющим. При невытесняющем SJF - планировании процессор предоставляется избранному процессу на все необходимое ему время, независимо от событий, происходящих в вычислительной системе. При вытесняющемSJF - планировании учитывается появление новых процессов в очереди готовых к исполнению (из числа вновь родившихся или разблокированных) во время работы выбранного процесса. Если CPU burst нового процесса меньше, чем остаток CPU burst у исполняющегося, то исполняющийся процесс вытесняется новым.
Вопрос 12. Многоуровневые очереди в планировании процессов (без обратной связи и с обратной связью) (Multilevel Queue)
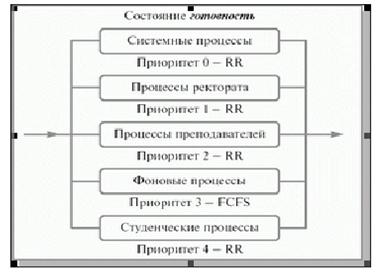
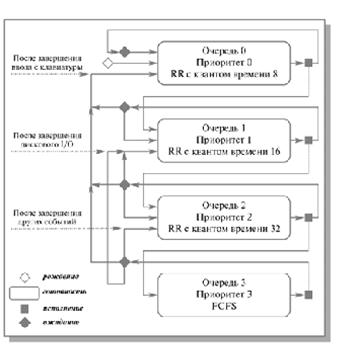
Для систем, в которых процессы могут быть легко рассортированы по разным группам, был разработан другой класс алгоритмов планирования. Для каждой группы процессов создается своя очередь процессов, находящихся в состоянии готовность Этим очередям приписываются фиксированные приоритеты. Например, приоритет очереди системных процессов устанавливается выше, чем приоритет очередей пользовательских процессов. А приоритет очереди процессов, запущенных студентами, ниже, чем для очереди процессов, запущенных преподавателями. Это значит, что ни один пользовательский процесс не будет выбран для исполнения, пока есть хоть один готовый системный процесс, и ни один студенческий процесс не получит в свое распоряжение процессор, если есть процессы преподавателей, готовые к исполнению Внутри этих очередей для планирования могут применяться самые разные алгоритмы. Так, например, для больших счетных процессов, не требующих взаимодействия с пользователем (фоновых процессов), может использоваться алгоритм FCFS, а для интерактивных процессов – алгоритм RR. Подобный подход, получивший название многоуровневых очередей, повышает гибкость планирования: для процессов с различными характеристиками применяется наиболее подходящий им алгоритм Многоуровневые очереди с обратной связью (Multilevel Feedback Queue) Дальнейшим развитием алгоритма многоуровневых очередей является добавление к нему механизма обратной связи. Здесь процесс не постоянно приписан к определенной очереди, а может мигрировать из одной очереди в другую в зависимости от своего поведения. Для простоты рассмотрим ситуацию, когда процессы в состоянии готовность организованы в 4 очереди, как на рисунке
Рис. Схема миграции процессов в многоуровневых очередях планирования с обратной связью. Вытеснение процессов более приоритетными процессами и завершение процессов на схеме не показано Планирование процессов между очередями осуществляется на основе вытесняющего приоритетного механизма. Чем выше на рисунке располагается очередь, тем выше ее приоритет. Процессы в очереди 1 не могут исполняться, если в очереди 0 есть хотя бы один процесс. Процессы в очереди 2 не будут выбраны для выполнения, пока есть хоть один процесс в очередях 0 и 1. И наконец, процесс в очереди 3 может получить процессор в свое распоряжение только тогда, когда очереди 0, 1 и 2 пусты. Если при работе процесса появляется другой процесс в какой-либо более приоритетной очереди, исполняющийся процесс вытесняется новым. Планирование процессов внутри очередей 0–2 осуществляется с использованием алгоритма RR, планирование процессов в очереди 3 основывается на алгоритме FCFS. Родившийся процесс поступает в очередь 0. При выборе на исполнение он получает в свое распоряжение квант времени размером 8 единиц. Если продолжительность его CPU burst меньше этого кванта времени, процесс остается в очереди 0. В противном случае он переходит в очередь 1. Для процессов из очереди 1 квант времени имеет величину 16. Если процесс не укладывается в это время, он переходит в очередь 2. Если укладывается – остается в очереди 1. В очереди 2 величина кванта времени составляет 32 единицы. Если для непрерывной работы процесса и этого мало, процесс поступает в очередь 3, для которой квантование времени не применяется и, при отсутствии готовых процессов в других очередях, может исполняться до окончания своего CPU burst. Чем больше значение продолжительности CPU burst, тем в менее приоритетную очередь попадает процесс, но тем на большее процессорное время он может рассчитывать. Таким образом, через некоторое время все процессы, требующие малого времени работы процессора, окажутся размещенными в высокоприоритетных очередях, а все процессы, требующие большого счета и с низкими запросами к времени отклика, – в низкоприоритетных Миграция процессов в обратном направлении может осуществляться по различным принципам. Например, после завершения ожидания ввода с клавиатуры процессы из очередей 1, 2 и 3 могут помещаться в очередь 0, после завершения дисковых операций ввода-вывода процессы из очередей 2 и 3 могут помещаться в очередь 1, а после завершения ожидания всех других событий – из очереди 3 в очередь 2. Перемещение процессов из очередей с низкими приоритетами в очереди с высокими приоритетами позволяет более полно учитывать изменение поведения процессов с течением времени. Многоуровневые очереди с обратной связью представляют собой наиболее общий подход к планированию процессов из числа подходов, рассмотренных нами. Они наиболее трудны в реализации, но в то же время обладают наибольшей гибкостью. Понятно, что существует много других разновидностей такого способа планирования, помимо варианта, приведенного выше. Для полного описания их конкретного воплощения необходимо указать: · Количество очередей для процессов, находящихся в состоянии готовность. · Алгоритм планирования, действующий между очередями. · Алгоритмы планирования, действующие внутри очередей. · Правила помещения родившегося процесса в одну из очередей. · Правила перевода процессов из одной очереди в другую. Изменяя какой-либо из перечисленных пунктов, мы можем существенно менять поведение вычислительной системы. Вопрос 12. Взаимодействие между процессами (англ. Inter-Process Communication, сокращенно англ. IPC) - набор средств обмена сообщениями процессами. Средства IPC могут использоваться для взаимодействия процессов: · которые выполняются на одном компьютере (для многомашинных систем - под управлением одной операционной системы), также известные как собственно IPC; · которые выполняются на разных компьютерах (для многомашинных систем - под управлением отдельных операционных систем), также известные как средства межмашинного взаимодействия; · для обеспечения взаимодействия процесса с самим собой - например, для синхронизации или обмена данными между различными нитями одного процесса.
Взаимодействие процессов внутри одной машины Для взаимодействия процессов, выполняемых на одном компьютере (под управлением одной операционной системы) используют (механизмы взаимодействия обеспечиваются ядром операционной системы, в которой выполняются процессы): · сигналы - асинхронные (неожиданные) сообщения, не передают данные между процессами, а извещают о событии (чрезвычайной ситуации), на которую процесс должен отреагировать выполнением предустановленной действия (функции или команды в зависимости от использованных средств программирования); · неименованные и именованные каналы (англ. pipes) передачи данных как синхронных (ожидаемых) сообщений; отправки сообщения происходит подобно операции записи в файл, получения - подобно чтения данных из файла, если канал пуст - процесс, который ожидает данные приостанавливается до поступления данных в канал. · очереди сообщений - пакеты данных, передаваемые между процессами с увидомленням получателя о поступлении пакета; · сегменты делимой памяти - средство, позволяющее нескольким процессам совместно использовать (разделять) фрагмент оперативной памяти с целью обмена данными; отправка данных происходит путем записи в память, получения - чтением из памяти.
Взаимодействие процессов, выполняемых на разных машинах Взаимодействие процессов, выполняемых на разных компьютерах - в управлении отдельных операционных систем, межмашинной взаимодействие - обеспечивается через специальную абстракцию - сокет. В зависимости от уровня использования сокетов существуют следующие средства межмашинного взаимодействия процессов (механизмы взаимодействия согласовано обеспечиваются ядрами операционных систем, в которых выполняются процессы): · прямое использование сокетов - технология, требующая программирования на низком уровне и реализации протокола передачи данных; · RPC (Remote Procedure Call), удаленный вызов процедур - технология, обеспечивающая взаимодействие между процессами подобно вызова функций, данные в одну сторону передаются как аргументы функций (удаленных процедур), в другом - как результаты выполнения функций (удаленных процедур). · CORBA - технология, предусматривающая возможность взаимодействия между процессами как между объектами CORBA, является дальнейшим развитием технологии RPC. Также существуют и другие технологии, которые в основном являются модификациями существующих: XML-RPC, SOAP и т.п.. Кроме того, сокеты могут использоваться также для взаимодействия процессов в пределах одной машины, так например работает x.Org.
Вопрос 12. ПОТОКИ (нити) Потоки в операционных системах нужны для двух вещей – для параллелизма и одновременности. Параллелизм – это физически одновременное выполнение для достижения наибольшей производительности(например, между двумя ядрами). Одновременность – логическое и/или физическое одновременное выполнение (есть один ЦП, на нем одновременно выполняется несколько программ – многозадачная ОС). Потоки нужны для того и другого понятия для эффективного использования. В самом простом варианте, чтобы достичь параллелизма – использование множества процессов – программы изолированы друг от друга в разных процессах, поэтому параллелизм есть. Потоки – другой способ достичь параллелизма. Потоки работают внутри одного процесса. Все потоки процесса имеют одно адресное пространство и те же ресурсы ОС. У потоков есть свой стек и свое состояние ЦП.
Многопоточность полезна для: · обработки одновременных событий · построение параллельных программ. Поддержка многопоточности – разделение понятие процесса от минимального потока управления. · Для параллельного потока выполнения не нужно создавать новые процессы. · Работает быстрее, меньше требования к памяти. Раньше: «Процесс»= адресное пространство + ресурсы ОС+ подразумевался единственный поток Раньше: «Процесс»= адресное пространство + ресурсы ОС+ все потоки принадлежат процессу Какие бывают потоки?
Вопрос 13.
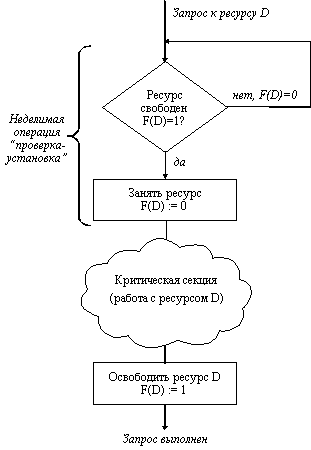
Тупики Гонки Вопрос 18. Критическая секция - это часть программы, в которой осуществляется доступ к разделяемым данным. Чтобы исключить эффект гонок по отношению к некоторому ресурсу, необходимо обеспечить, чтобы в каждый момент в критической секции, связанной с этим ресурсом, находился максимум один процесс. Этот прием называют взаимным исключением. Простейший способ обеспечить взаимное исключение - позволить процессу, находящемуся в критической секции, запрещать все прерывания. Однако этот способ непригоден, так как опасно доверять управление системой пользовательскому процессу; он может надолго занять процессор, а при крахе процесса в критической области крах потерпит вся система, потому что прерывания никогда не будут разрешены.
Вопрос 20. Алгоритм Петерсона Первое решение проблемы, удовлетворяющее всем требованиям и использующее идеи ранее рассмотренных алгоритмов, было предложено датским математиком Деккером (Dekker). В 1981 году Петерсон (Peterson) предложил более изящное решение. Пусть оба процесса имеют доступ к массиву флагов готовности и к переменной очередности. shared int ready[2] = {0, 0}; shared int turn; while (some condition) { ready[i] = 1; turn =1-i; while(ready[1-i] && turn == 1-i); critical section ready[i] = 0; remainder section } При исполнении пролога критической секции процесс Pi заявляет о своей готовности выполнить критический участок и одновременно предлагает другому процессу приступить к его выполнению. Если оба процесса подошли к прологу практически одновременно, то они оба объявят о своей готовности и предложат выполняться друг другу. При этом одно из предложений всегда следует после другого. Тем самым работу в критическом участке продолжит процесс, которому было сделано последнее предложение. Давайте докажем, что все пять наших требований к алгоритму действительно удовлетворяются. Удовлетворение требований 1 и 2 очевидно. Докажем выполнение условия взаимоисключения методом от противного. Пусть оба процесса одновременно оказ
|
|||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-08-01; просмотров: 476; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.225.156.91 (0.012 с.) |