
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Устранение гетероскедастичностиСодержание книги Поиск на нашем сайте
В случае, когда присутствие гетероскедастичности установлено, возникает необходимость преобразования регрессионной модели с целью устранения данного нежелательного явления. Вид преобразования зависит от того, известны или нет дисперсии случайных отклонений Предположим, что рассматриваемая модель гетероскедастична, и нам известны значения дисперсий остатков Для простоты изложения опишем ВМНК на примере парной регрессии [11]: yi = b 0 + b 1 xi + e i. (5.7) Разделим каждый член модели (5.7) на известное σ i:
Введем обозначения
Полученное уравнение представляет собой регрессию без свободного члена, но с дополнительной объясняющей переменной U и с преобразованным случайным отклонением e*. Для преобразованной модели (5.9) дисперсия остатков Таким образом, ковариационная матрица W в выражении (5.1) становится единичной, а сама преобразованная модель (5.9) – классической, к которой применим «обычный» МНК. Другими словами, в данном случае обобщенным методом наименьших квадратов для модели с гетероскедастичностью является взвешенный метод наименьших квадратов (ВМНК). «Взвешивая» каждый остаток Рассмотренная выше процедура применения ВМНК предполагает, что фактические значения дисперсий
Несложно показать, что для отклонений Рассматривая проведенные выше преобразования и их результаты, следует отметить, что применение обобщенного метода наименьших квадратов для моделей с гетероскедастичностью остатков заключается в минимизации суммы взвешенных квадратов отклонений выборочных данных от их оценок.
Автокорреляция
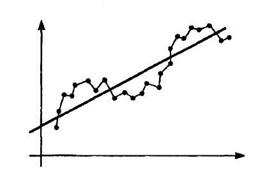
При анализе временных рядов часто приходится учитывать статистическую зависимость (коррелированность) наблюдений в разные моменты времени. Следовательно, в данном случае для регрессионных моделей Cov (e i, e j) ¹ 0, i ¹ j, т. е. третья предпосылка Гаусса-Маркова о некоррелированности остатков не выполняется. Такие регрессионные зависимости называются моделями с автокорреляцией (сериальной корреляцией) остатков [1,28]. Для обобщенной линейной регрессионной модели с автокорреляцией ковариационная матрица случайных отклонений W не может быть диагональной. Последствия автокорреляции остатков во многом сходны с последствиями гетероскедастичности (см. раздел 5.2). Среди них особенно следует выделить ухудшение прогнозных качеств моделей временных рядов. Поскольку автокорреляция рассматривается в регрессионном анализе при использовании данных временных рядов, в дальнейших выкладках вместо символа i порядкового номера наблюдения будем использовать символ t отражающий момент наблюдения во времени (t = 1, 2, …, n). В экономических задачах более часто встречается так называемая положительная автокорреляция (Cov (e t - 1, e t) > 0 для соседних отклонений), нежели отрицательная автокорреляция (Cov (e t - 1, e t) < 0). В большинстве случаев причиной положительной автокорреляции является направленное постоянное воздействие на исследуемый показатель некоторых неучтенных в модели факторов, что отражается на поведении случайного отклонения e t. Пусть, например, исследуется спрос Y (yt) на прохладительные напитки в зависимости от дохода потребителей X по ежемесячным данным. Трендовая зависимость (основная тенденция), отражающая увеличение спроса с ростом дохода, может быть представлена линейной моделью
Рис. 5.2.
Если рассматривать в качестве примера временной ряд yt значений курса некоторой ценной бумаги, наблюдаемых в последовательные моменты времени, то естественно предположить, что результаты предыдущих торгов оказывают влияние на результаты последующих: завышенный (заниженный) в какой то момент времени курс скорее всего окажется завышенным (заниженным) по сравнению с реальным и на следующих торгах, т. е. здесь также может иметь место положительная автокорреляция. Графически положительная автокорреляция выражается в чередовании зон, где наблюдаемые значения оказываются выше модельных (предсказанных), и зон, где наблюдаемые значения ниже (рис. 5.2). Отрицательная автокорреляция характеризуется тем, что за положительным отклонением следует отрицательное и наоборот (принцип «маятника»). Примерная схема рассеивания точек относительно линии модели в случае отрицательной автокорреляции представлена на рис. 5.3.
Рис. 5.3.
Следует заметить, что автокорреляция чаще всего может быть вызвана неправильной спецификацией модели. Поэтому для ее возможного устранения следует скорректировать саму модель: включить в уравнение регрессии дополнительный фактор-аргумент или изменить формулу зависимости. Однако это далеко не всегда приводит к положительным результатам, что вызвано сложностью экономических процессов, влияющих на поведение случайных отклонений e t. Если возможные процедуры изменения спецификации модели оказываются неэффективными, то необходимо воспользоваться так называемыми авторегрессионными преобразованиями над случайными отклонениями, среди которых наиболее простым и результативным является авторегрессионный процесс (авторегрессия) первого порядка. Авторегрессия первого порядка состоит в достаточно реалистичном предположении, что корреляция во времени наиболее сильно проявляется между двумя соседними отклонениями. В целом для построения качественных моделей (особенно моделей временных рядов), наряду с проверкой общего качества уравнений регрессии, необходимо проводить их проверку на наличие автокорреляции остатков, и, в случае обнаружения, применять специальные методы по ее устранению.
Обнаружение автокорреляции
Большинство тестов на наличие автокорреляции основаны на достаточно простой идее: если корреляция во времени присутствует между случайными отклонениями e t, то она должна проявляться и в их оценках et, получаемых при использовании обычного МНК. Наиболее распространенным примером реализации данного подхода является тест (критерий) Дарбина-Уотсона, который определяет наличие автокорреляции между соседними отклонениями [1,22,28]. Этот критерий основан на применении статистики Дарбина-Уотсона (DW), определяемой соотношением:
Покажем, что статистика Дарбина-Уотсона связана с выборочным коэффициентом корреляции между соседними отклонениями r следующим образом: DW» 2(1 - r). (5.11) Преобразуем соотношение (5.10)
При достаточно больших выборках сумма
Учитывая, что математическое ожидание M (et) = 0, запишем формулу для вычисления выборочного коэффициента корреляции:
При большом числе наблюдений n суммы
Из сравнения выражений (5.13) и (5.14) следует приближенное равенство (5.11). Согласно формуле (5.11) значения статистики Дарбина-Уотсона могут находиться в пределах 0 £ DW £ 4 и указывают на наличие либо отсутствие автокорреляции. Действительно, если автокорреляция отсутствует, то выборочный коэффициент корреляции между соседними отклонениями r» 0 и значение статистики DW будет близко к двум, что соответствует независимости случайных отклонений. Близость наблюдаемого значения статистики к нулю указывает на наличие положительной автокорреляции, к четырем – отрицательной автокорреляции. Следует заметить, что непосредственное использование статистики DW в схеме проверки статистических гипотез (H 0: r = 0, H 1: r > 0, r < 0) не представляется возможным. Проблема состоит в том, что распределение статистики DW зависит не только от числа наблюдений n и количества регрессоров m, но и от значений объясняющих переменных. В этом случае пороговые (критические) значения статистики указать невозможно. Однако Дарбин и Уотсон доказали, что для статистики существуют две границы (du - верхняя, dl - нижняя), которые зависят только от n, m и выбираемого уровня значимости a. Значения этих границ статистики DW затабулированы (см. Приложение 6) и могут быть использованы для проверки нулевой гипотезы H 0 об отсутствии автокорреляции. Приведем общую схему применения теста (критерия) Дарбина-Уотсона [11,28,29]. 1. По построенному с помощью МНК эмпирическому уравнению регрессии:
определяются значения отклонений (остатков) 2. По формуле (5.10) на основе полученных данных рассчитывается наблюдаемое значение статистики DW. 3. По таблице критических значений статистики DW определяются два числа dl и du и делаются выводы о наличии автокорреляции по правилу, отраженному следующей таблицей.
Таблица 5.1
Статистика Дарбина-Уотсона приводится во всех компьютерных эконометрических пакетах как важная характеристика качества регрессионной модели. Несмотря на то, что тест Дарбина-Уотсона наиболее распространен в регрессионном анализе, он обладает рядом ограничений и недостатков. Его основными недостатками являются наличие зоны неопределенности для значений статистики, когда нет оснований ни принимать, ни отвергать гипотезу H 0 об отсутствии автокорреляции, а также неприменимость для так называемых авторегрессионных моделей*, содержащих в составе объясняющих переменных зависимую переменную с временным лагом в один период.
|
||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-06-28; просмотров: 856; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.118.137.13 (0.012 с.) |

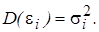
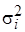 для каждого t -го наблюдения. При отсутствии автокорреляции это означает, что ковариационная матрица случайных отклонений V (e) = W - диагональная. В данном случае можно устранить гетероскедастичность, разделив каждое значение зависимой и объясняющих переменных на соответствующее стандартное отклонение
для каждого t -го наблюдения. При отсутствии автокорреляции это означает, что ковариационная матрица случайных отклонений V (e) = W - диагональная. В данном случае можно устранить гетероскедастичность, разделив каждое значение зависимой и объясняющих переменных на соответствующее стандартное отклонение 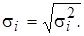 Нормируя («взвешивая») переменные по σ i, мы стремимся получить более точные оценки. В этом заключается суть так называемого взвешенного метода наименьших квадратов (ВМНК).
Нормируя («взвешивая») переменные по σ i, мы стремимся получить более точные оценки. В этом заключается суть так называемого взвешенного метода наименьших квадратов (ВМНК).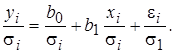 (5.8)
(5.8)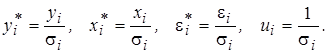 Тогда уравнение модели (5.7) примет вид:
Тогда уравнение модели (5.7) примет вид: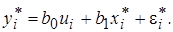 (5.9)
(5.9)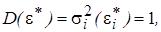 т. е. имеет место гомоскедастичность. Действительно, можно записать
т. е. имеет место гомоскедастичность. Действительно, можно записать 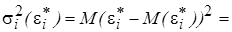
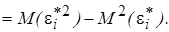 Так как, согласно первой предпосылке МНК, математическое ожидание М (e i) = 0, то
Так как, согласно первой предпосылке МНК, математическое ожидание М (e i) = 0, то 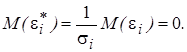 Следовательно,
Следовательно, 
 с помощью коэффициента 1/σ i, мы добиваемся равномерного вклада остатков в общую дисперсию и, в конечном счете, получения эффективных оценок параметров модели.
с помощью коэффициента 1/σ i, мы добиваемся равномерного вклада остатков в общую дисперсию и, в конечном счете, получения эффективных оценок параметров модели.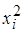 (стандартное отклонение остатков пропорционально независимой переменной) или значениям хi. Тогда необходимым преобразованием будет деление уравнения регрессии (5.7) на хi или
(стандартное отклонение остатков пропорционально независимой переменной) или значениям хi. Тогда необходимым преобразованием будет деление уравнения регрессии (5.7) на хi или 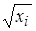 соответственно, что позволит нам получить «преобразованные» случайные отклонения
соответственно, что позволит нам получить «преобразованные» случайные отклонения 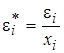 и
и 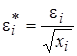 , для которых выполняется условие гомоскедастичности. Например, определим дисперсию случайного члена для случая пропорциональности стандартного отклонения значениям независимой переменной (σ i = σ(e i) = l хi, где l - коэффициент пропорциональности). В силу выполнимости предпосылки МНК имеем:
, для которых выполняется условие гомоскедастичности. Например, определим дисперсию случайного члена для случая пропорциональности стандартного отклонения значениям независимой переменной (σ i = σ(e i) = l хi, где l - коэффициент пропорциональности). В силу выполнимости предпосылки МНК имеем:
 (рис. 5.2). Однако фактические точки наблюдений вследствие влияния фактора сезонности будут превышать трендовую линию в летние периоды и находиться ниже ее в зимние.
(рис. 5.2). Однако фактические точки наблюдений вследствие влияния фактора сезонности будут превышать трендовую линию в летние периоды и находиться ниже ее в зимние.


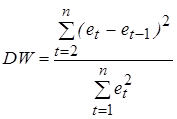 . (5.10)
. (5.10)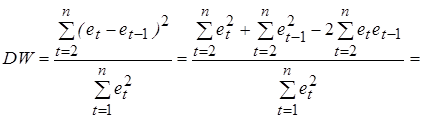
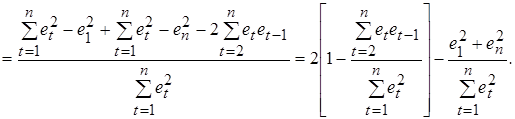 (5.12)
(5.12)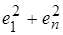 значительно меньше
значительно меньше 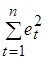 , поэтому последним членом в формуле (5.12) можно пренебречь. Тогда получим:
, поэтому последним членом в формуле (5.12) можно пренебречь. Тогда получим: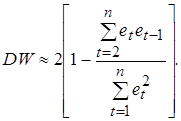 (5.13)
(5.13)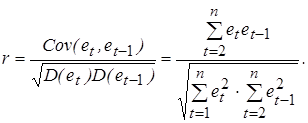
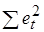 и
и 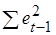 будут практически одинаковы. Поэтому выборочный коэффициент корреляции r можно приближенно представить в виде:
будут практически одинаковы. Поэтому выборочный коэффициент корреляции r можно приближенно представить в виде: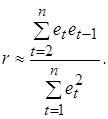 (5.14)
(5.14)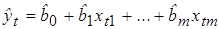
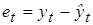 для каждого конкретного наблюдения t, t = 1, 2, …, n.
для каждого конкретного наблюдения t, t = 1, 2, …, n.


