
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Обнаружение гетероскедастичностиСодержание книги Поиск на нашем сайте
В случае парной регрессии о проявлении гетероскедастичности можно судить по характеру расположения экспериментальных точек на корреляционном поле (рис. 5.1). На рис. 5.1 можно заметить, что дисперсии случайных отклонений неодинаковы и увеличиваются с возрастанием значений объясняющей переменной. Однако даже для парной регрессии выводы по определению гетероскедастичности могут являться неоднозначными при наличии локальных «выбросов» точек (пиков на диаграмме рассеивания). Естественно, что для множественной регрессии обнаружение гетероскедастичности является значительно более сложной задачей, чем для моделей с одним регрессором.
Рис. 5.1.
В настоящее время существует достаточно большое количество тестов для поверки на гетероскедастичность, базирующихся на дисперсионном анализе случайных отклонений. Рассмотрим наиболее распространенные из них. Тест ранговой корреляции Спирмена [11,28]. Идея данного теста заключается в том, что в случае гетероскедастичности дисперсия случайного отклонения будет либо увеличиваться, либо уменьшаться с увеличением значений регрессоров Х. Поэтому для регрессионной модели, построенной по МНК, абсолютные значения оценок отклонений ei и значения xi будут коррелированны. Значения ei и xi ранжируются (упорядочиваются по величинам). Номеру i значения xi в упорядоченном ряду будет соответствовать ранг rxi. Аналогично упорядочим данные по абсолютным значениям остатков и каждому | ei | припишем ранг rei. Тогда разность между рангами (di) запишем как di = rxi - rei. Например, если x 20 является 30-м по величие среди всех значений X, а e 20 является 40-м, то di = 30 - 40 = -10. Коэффициент ранговой корреляции Спирмена вычисляется по формуле
где n - число наблюдений. Доказано, что при n > 10 статистика
имеет t -распределение Стьюдента с числом степеней свободы v = n - 2. Следовательно, в соответствии со схемой проверки статистических гипотез, если наблюдаемое значение t -статистики, рассчитанное по формуле (5.3), превышает tкр = t a, n - 2 (табличное), то необходимо отклонить гипотезу Н 0 об отсутствии гетероскедастичности. В противном случае гипотеза Н 0 принимается, что соответствует гомоскедастичности. Если анализируется модель множественной регрессии, то проверка гипотезы осуществляется с помощью t -статистики для каждой объясняющей переменной отдельно. Следует заметить, что коэффициент ранговой корреляции Спирмена (r) может иметь самостоятельное значение в эконометрических исследованиях. Он используется при установлении тесноты связи между порядковыми переменными. В этом случае анализируемые объекты упорядочивают по степени влияния (проявления) признака. Если объекты ранжированы по двум признакам Х и Y, то имеется возможность оценить тесноту связи между этими переменными, основываясь на рангах. В том случае, если ранги всех объектов равны, то r = 1 (полная прямая связь). При полной обратной связи ранги объектов по двум переменным расположены в обратном порядке и r = -1. Во всех остальных случаях | r | < 1. Применение коэффициента ранговой корреляции не требует нормального распределения переменных и линейной связи между ними. Однако необходимо учитывать, что в случае количественных переменных переход от их первоначальных значений и размерностей к рангам сопровождается определенной потерей информации. Тест Голдфелда-Квандта. Этот тест использует предположения о нормальности распределения случайных отклонений и о пропорциональности средних квадратических (стандартных) отклонений σ i = σ(e i) значениям соответствующей объясняющей переменной X. В рамках этих предположений Голдфелд и Квандт предложили следующую процедуру проверки на гетероскедастичность: 1. Все n наблюдений упорядочиваются в порядке возрастания значений регрессора X, и выборка после этого разбивается на три подвыборки размерностей k, n - 2 k, k соответственно. 2. Оцениваются отдельные регрессии для первой и третьей подвыборок (рассматриваем k первых значений и k последних; средние n - 2 k наблюдений отбрасываем). 3. Если, в соответствии с нашим предположением, дисперсия случайных отклонений увеличивается с ростом X, то дисперсия регрессии по первой подвыборке (сумма квадратов остатков 4. Для сравнения соответствующих дисперсий определяется следующая F -статистика:
Здесь (k - m - 1) – числа степеней свободы соответствующих выборочных дисперсий (m - одинаковое количество объясняющих переменных в уравнениях регрессии). При выполнении начальных предположений относительно остатков построенная F -статистика имеет распределение Фишера с числами степеней свободы v 1 = v 2 = k - m - 1. 5. Если наблюдаемое значение F -статистики (Fнабл), рассчитанное по формуле (5.4), превосходит ее критическое значение Мощность теста Голдфелда-Квандта, т. е. вероятность отвергнуть гипотезу об отсутствии гетероскедастичности в случае, когда ее действительно нет, оказывается максимальной, если выбирать k» n /3. Для множественной регрессии данный тест может осуществляться для каждой из объясняющих переменных или для одного выбранного регрессора, который в наибольшей степени связан с σ i. Аналогичный тест может быть использован при условии обратной пропорциональности между стандартными отклонениями остатков σ i и значениями объясняющей переменной. При этом статистика Фишера примет вид: F = S 1/ S 3. Тест Уайта [25]. Сущность данного теста заключается в том, что если в модели присутствует гетероскедастичность, то дисперсии случайных отклонений некоторым образом зависят от регрессоров; т. е. гетероскедастичность должна как-то проявляться в поведении остатков исходной регрессионной модели. Исходя из этого при использовании теста Уайта предполагается, что дисперсии остатков представляют собой некоторую функцию от наблюдаемых значений объясняющих переменных
Для получения соответствующих выводов осуществляется оценка функции (5.5) с помощью уравнения регрессии для квадратов остатков:
где vi - случайный член. На практике чаще всего функция f выбирается квадратичной, а регрессоры в уравнении (5.6) – это регрессоры исходной модели, их квадраты и, возможно, попарные произведения. Для данного теста гипотеза об отсутствии гетероскедастичности, что соответствует условию f = const, принимается в случае незначимости регрессии (5.6) в целом. Следует заметить, что во всех рассматриваемых тестах (критериях) осуществляется проверка нулевой гипотезы Н 0 об отсутствии гетероскедастичности.
|
||||
|
|
Последнее изменение этой страницы: 2016-06-28; просмотров: 438; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.189.170.65 (0.009 с.) |




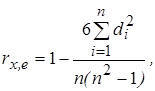 (5.2)
(5.2) (5.3)
(5.3) ) будет существенно меньше дисперсии регрессии по третьей подвыборке (суммы квадратов остатков
) будет существенно меньше дисперсии регрессии по третьей подвыборке (суммы квадратов остатков  ).
). . (5.4)
. (5.4)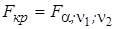 , то гипотеза об отсутствии гетероскедастичности (о равенстве дисперсий) отклоняется на выбранном уровне значимости a.
, то гипотеза об отсутствии гетероскедастичности (о равенстве дисперсий) отклоняется на выбранном уровне значимости a. . (5.5)
. (5.5)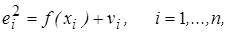 , (5.6)
, (5.6)


