Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Сохранение и считывание файловСодержание книги
Поиск на нашем сайте
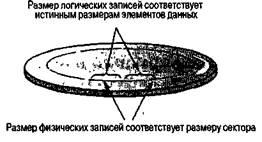
Информация в массовой памяти хранится в виде больших блоков, которые принято называть файлами. Типичный файл может содержать некоторый текстовый документ, фотографию, программу или совокупность данных о персонале какой-либо компании. Физические особенности устройств массовой памяти требуют, чтобы файлы сохранялись и считывались отдельными блоками из большого количества байтов. Например, каждый сектор на магнитном диске должен обрабатываться как одна непрерывная строка битов. Блок данных, соответствующий физическим характеристикам запоминающего устройства, называется физической записью. Поэтому файл, записанный в массовую память, обычно состоит из множества физических записей. Помимо разделения на физические записи, любой файл обычно подразумевает некоторое естественное разграничение представленной в нем информации. Например, файл с информацией о персонале компании будет состоять из множества элементов, каждый из которых содержит сведения об отдельном человеке. Такие блоки данных, естественным образом образующиеся при создании файла, называют логическими записями. Размер логической записи редко совпадает с размером физической записи, который определяется типом устройства массовой памяти. Поэтому несколько логических записей могут помещаться в одну физическую запись, и наоборот, логическая запись при необходимости может разделяться на несколько физических (рис. 1.11). В результате считывание данных файла с устройства массовой памяти обычно связано с восстановлением его логических записей из физических. Типичный способ решения этой проблемы состоит в выделении некоторой области основной памяти, достаточно большой для размещения нескольких физических записей файла, и использовании ее в качестве промежуточного хранилища для перегруппировки информации. В результате обмен данными между этой промежуточной областью и устройством массовой памяти может осуществляться блоками данных, соответствующими физическим записям, тогда как для программ находящаяся в основной памяти информация может быть представлена в виде логических записей. Используемая подобным образом область основной памяти называется буфером. Использование буфера поясняет относительную роль основной и массовой памяти в системе. Основная память используется для хранения данных в целях их обработки, тогда как массовая память является постоянным хранилищем информации. Таким образом, обновление сохраняемой в массовой памяти информации предполагает передачу информации в основную память, изменение ее, а затем возврат обновленной информации в массовую память.
Рис 1.11 Представление логических и физических записей на диске
Можно сделать заключение, что основная память, магнитные диски, компакт-диски и магнитная лента представляют различные уровни возможности прямого доступа к данным в порядке ее уменьшения. Используемая в основной памяти система адресации допускает быстрый произвольный доступ к отдельным байтам данных. Магнитные диски обеспечивают прямой доступ только к целым секторам данных. Кроме того, время, затрачиваемое на считывание сектора, включает также время установки и время ожидания. Компакт-диски тоже поддерживают произвольный доступ к отдельным секторам, однако величина задержки для компакт-дисков значительно больше по сравнению с магнитными дисками. Это обусловлено тем, что в этом случае требуется дополнительное время для того, чтобы найти спиральную дорожку и настроить скорость вращения диска. Наконец, устройства с магнитной лентой не позволяют получать прямой доступ к информации. Современные лентопротяжные системы маркируют фрагменты ленты, что позволяет ссылаться на различные сегменты по отдельности, однако сама физическая организация данных обуславливает то, что поиск сегмента потребует достаточно много времени.
Представление информации в виде комбинации двоичных разрядов
В этом разделе мы рассмотрим, как информация в машине представляется в виде комбинации двоичных разрядов (битов). В частности, мы обсудим популярные методы кодирования текста, представления цифровых данных и изображений. Каждый из указанных методов имеет специфические особенности, с которыми часто сталкивается типичный пользователь компьютера. Наша задача — всецело ознакомиться с этими технологиями, чтобы потом можно было оценить все их последствия.
Представление текста
Информация в форме текста обычно представляется с помощью кода, причем каждому отличному от других символу (например, букве алфавита или знаку пунктуации) присваивается уникальная комбинация двоичных разрядов. В этом случае текст будет представлен как длинный ряд битов, в котором следующие друг за другом комбинации битов отражают последовательность символов в исходном тексте. В ранний период развития компьютерной технологии было разработано много подобных кодов, причем каждый из них использовался в различных элементах оборудования. Это привело к появлению ряда проблем, связанных с передачей информации. Во избежание этих проблем Американский национальный институт стандартов (American National Standards Institute, ANSI) принял американский стандартный код для обмена информацией (American Standard Code for Information Interchange, ASCII), который приобрел очень большую популярность. В этом коде комбинации двоичных разрядов длиной семь бит используются для представления строчных и прописных букв английского алфавита, знаков пунктуации, цифр от 0 до 9, а также кодов управления передачей информации (перевод строки, возврат каретки и табуляция). В наше время код ASCII часто употребляется в расширенном восьмиразрядном формате, который получается посредством добавления нуля в старший конец каждого семиразрядного кода. Благодаря этому можно получить не только коды, размер которых соответствует типичной однобайтовой ячейке памяти, но и 128 новых дополнительных комбинаций двоичных разрядов (которые получаются в результате добавления в старший конец бита со значением 1). Это позволяет представлять символы, не поддерживаемые исходной версией кода ASCII. К сожалению, из-за того, что фирмы-разработчики широко использовали собственные варианты толкования этих дополнительных кодов, данные, представленные в этих кодах, оказалось не так-то просто переносить с одной программы в другую, особенно если эти программы были разработаны разными фирмами. Несмотря на то, что ASCII — это один из наиболее широко используемых кодов, сегодня растет популярность кодов с более широкими возможностями, которые способны представлять документы на разных языках. Одним из них является Unicode, который был разработан в результате объединенных усилий нескольких ведущих фирм-производителей программного и аппаратного обеспечения. В этом коде для представления каждого символа используется уникальная комбинация из 16 двоичных разрядов. В результате кодировка Unicode включает 65 536 различных двоичных кодов, что вполне достаточно даже для представления всех широко употребляемых китайских и японских символов. Международная организация по стандартизации (International Organization for Standardization, часто именуемая ISO, от греческого isos — одинаковый) разработала код, способный соперничать даже с кодировкой Unicode. Здесь для выражения символов используются комбинации из 32 бит, в результате чего этот код позволяет представить более 17 миллионов символов. Будущее покажет, какой из двух кодов приобретет большую популярность.
|
||
|
|
Последнее изменение этой страницы: 2016-04-21; просмотров: 257; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.102 (0.007 с.) |