Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Построение кодового дерева ХаффменаСодержание книги
Поиск на нашем сайте Для иллюстрации алгоритма Хаффмена рассмотрим графический способ построения дерева кодирования. Перед этим введем некоторые определения, принятые для описания алгоритма Хаффмена с использованием этого способа. Граф -- совокупность множества узлов и множества дуг, направленных от одного узла к другому. Дерево -- граф, обладающий следующими свойствами: · ни в один из узлов не входит более одной дуги; · только в один узел не входит ни одной дуги (этот узел называется корнем дерева); · перемещаясь по дугам от корня, можно попасть в любой узел. Лист дерева -- узел, из которого не выходит ни одной дуги. В паре узлов дерева, соединенных между собой дугой, тот, из которого она выходит, называется родителем, другой же -- ребенком. Два узла называются братьями, если имеют одного и того же родителя. Двоичное дерево -- дерево, у которого из всех узлов, кроме листьев, выходит ровно по две дуги. Дерево кодирования Хаффмена -- двоичное дерево, у которого каждый узел имеет вес, и при этом вес родителя равен суммарному весу его детей. Алгоритм построения дерева кодирования Хаффмена таков: 1. Буквы входного алфавита образуют список свободных узлов будущего дерева кодирования. Каждый узел в этом списке имеет вес, равный вероятности появления соответствующей буквы в сообщении. 2. Выбираются два свободных узла дерева с наименьшими весами. Если имеется более двух свободных узлов с наименьшими весами, то можно брать любую пару. 3. Создается их родитель с весом, равным их суммарному весу. 4. Родитель добавляется в список свободных узлов, а двое его детей удаляются из этого списка. 5. Одной дуге, выходящей из узла-родителя, ставится в соответствие бит 1, другой -- 0. 6. Пункты 2, 3, 4, 5 повторяются до тех пор, пока в списке свободных узлов не останется только один узел. Этот узел будет являться корнем дерева. Его вес получается равным единице -- суммарной вероятности всех букв сообщения. Теперь, двигаясь по кодовому дереву сверху вниз и последовательно выписывая двоичные цифры, соответствующие дугам, можно получить коды букв входного алфавита. Для примера рассмотрим построение дерева кодирования Хаффмена для приведенного в таблице 1 алфавита из восьми букв.
Построение дерева начинаем со списка листьев (см. рис. 1) и выполняем по шагам.
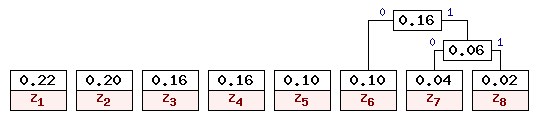
На первом шаге из листьев дерева выбираются два с наименьшими весами z7 и z8. Они присоединяются к узлу-родителю, вес которого устанавливается в 0.04 + 0.02 = 0.06. Затем узлы z7 и z8 удаляются из списка свободных. Узел z7 соответствует ветви 0 родителя, узел z8 -- ветви 1. Дерево кодирования после первого шага приведено на рис. 2.
На втором шаге "наилегчайшей" парой оказывается лист z6 и свободный узел (z7 + z8). Для них создается родитель с весом 0.16. Узел z6 соответствует ветви 0 родителя, узел (z7 + z8) -- ветви 1. На данном шаге дерево кодирования выглядит следующим образом (см. рис. 3).
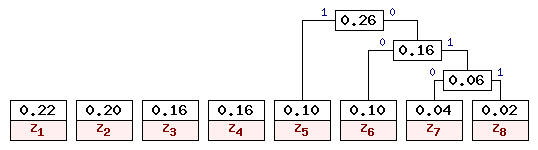
На третьем шаге наименьшие вероятности имеют z5, z4, z3 и свободный узел (z6 + z7 + z8). Таким образом, на данном шаге можно создать родителя для z5 и (z6 + z7 + z8) с весом 0.26, получив при этом дерево кодирования, представленное на рис. 4. Обратите внимание, что в данной ситуации возможны несколько вариантов соединения узлов с наименьшими весами. При этом все такие варианты будут правильными, хотя и могут привести к различным наборам кодов, которые, впрочем, будут обладать одинаковой эффективностью для заданного распределения вероятностей.
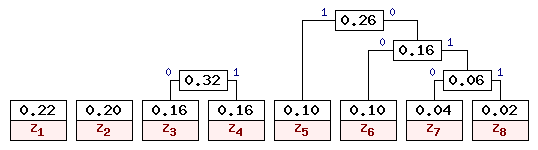
На четвертом шаге "наилегчайшей" парой оказываются листья z3 и z4. Дерево кодирования Хаффмена приведено на рис. 5.
На пятом шаге выбираем узлы с наименьшими весами 0.22 и 0.20. Дерево кодирования Хаффмена после пятого шага приведено на рис. 6.
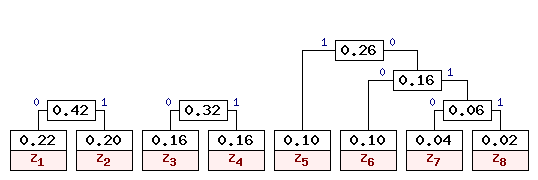
На шестом шаге остается три свободных узла с весами 0.42, 0.32 и 0.26. Выбираем наименьшие веса 0.32 и 0.26. Дерево кодирования Хаффмена после шестого шага приведено на рис. 7.
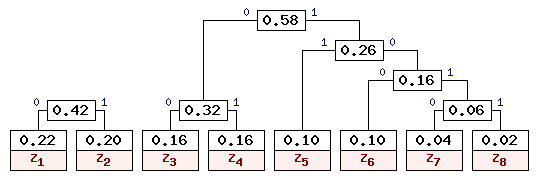
На седьмом шаге остается объединить две оставшиеся свободные вершины, после чего получаем окончательное дерево кодирования Хаффмена, приведенное на рис. 8.
На основании построенного дерева буквы представляются кодами, отражающими путь от корневого узла до листа, соответствующего нужной букве. В рассмотренном примере буквы входного алфавита кодируются так, как показано в таблице 2.
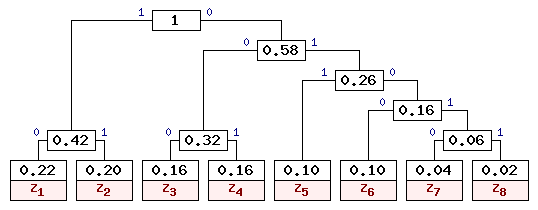
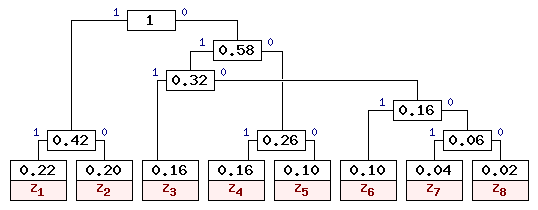
Видно, что наиболее вероятные буквы закодированы самыми короткими кодами, а наиболее редкие -- кодами большей длины. Причем коды построены таким образом, что ни одна кодовая комбинация не совпадает с началом более длинной комбинации. Это позволяет однозначно декодировать сообщения без использования разделительных символов. Для заданных в таблице 1 вероятностей можно построить и другие правильные варианты кодового дерева Хаффмена. Одно из допустимых деревьев приведено на рис. 9. Коды букв входного алфавита для данного кодового дерева приведены в таблице 3.
Из таблицы 3 видно, что коды также получились префиксными, и наиболее вероятным буквам соответствуют наиболее короткие коды. Вопросы практической реализации алгоритма Для повышения эффективности сжатия необходимо, чтобы при построении кодового дерева использовались данные по вероятностям появления букв именно в этом файле, а не усредненные по большому количеству текстов. Исходя из этого, необходима статистика встречаемости букв сжимаемого файла, которая может быть получена предварительным проходом по файлу. Для ускорения работы принято определять не вероятности появления букв pi, а частоту встречаемости (количество появлений) буквы в файле ni. Это позволяет существенно упростить и ускорить алгоритм (не нужно медленных операций с плавающей запятой и операций деления). При таком подходе алгоритм работы не изменяется, так как частоты прямо пропорциональны вероятностям. Стоит заметить, что вес корневого узла дерева кодирования в таком случае будет равен общему количеству букв в обрабатываемом файле.
Лекция №7 Автоматизированная система управления или АСУ — комплекс аппаратных и программных средств, предназначенный для управления различными процессами в рамках технологического процесса, производства, предприятия. АСУ применяются в различных отраслях промышленности, энергетике, транспорте и т. п. Термин автоматизированная, в отличие от термина автоматическая подчеркивает сохранение за человеком-оператором некоторых функций, либо наиболее общего, целеполагающего характера, либо не поддающихся автоматизации. Создателем первых АСУ в СССР является доктор экономических наук, профессор, член-корреспондент Национальной академии наук Беларуси, основоположник научной школы стратегического планирования Николай Иванович Ведута (1913—1998)[1][2][3][4]. В 1962—1967 гг. в должности директора Центрального научно-исследовательского института технического управления (ЦНИИТУ), являясь также членом коллегии Министерства приборостроения СССР, он руководил внедрением первых в стране автоматизированных систем управления производством на машиностроительных предприятиях. Активно боролся против идеологических PR-акций по внедрению дорогостоящих ЭВМ, вместо создания настоящих АСУ для повышения эффективности управления производством. Виды АСУ
Примеры: o Автоматизированная система управления уличным освещением («АСУ УО») — предназначена для организации автоматизации централизованного управления уличным освещением. o Автоматизированная система управления наружного освещения («АСУНО») — предназначена для организации автоматизации централизованного управления наружным освещением. o Автоматизированная система управления дорожным движением или АСУ ДД — предназначена для управления транспортных средств и пешеходных потоков на дорожной сети города или автомагистрали Автоматизированная система управления предприятием или АСУП — Для решения этих задач применяются MRP,MRP II и ERP-системы. В случае, если предприятием является учебное заведение, применяются системы управления обучением. SCADA (аббр. от англ. Supervisory Control And Data Acquisition, Диспетчерское управление и сбор данных) — данное понятие обычно применяется к системе управления в промышленности: система контроля и управления процессом с применением ЭВМ. Процесс может быть технологическим, инфраструктурным или обслуживающим:
Основные компоненты системы SCADA—система обычно содержит следующие подсистемы:
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2021-05-27; просмотров: 193; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.217.39 (0.008 с.) |