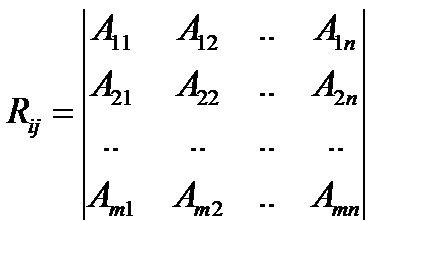Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Директории. Логическая структура файлового архива.
Количество файлов на компьютере может быть большим. Отдельные системы хранят тысячи файлов, занимающие сотни гигабайтом диска. Каждый каталог содержит список каталогов и/или файлов, содержащихся в данном каталоге. Каталоги имеют один и тот же внутренний формат, где каждому файлу соответствует одна запись в файле директории.
Рис. 11.3 Директории. (а) Атрибуты внутри записи в директории. (б) Атрибуты в другой структуре Когда система открывает файл, она ищет имя файла в директории. Затем извлекаются атрибуты и адреса блоков файла на диске или непосредственно из записи в директории или из структуры, на которую запись в директории указывает. Эта информация помещается в системную таблицу в главной памяти. Все последующие ссылки на этот файл используют эту информацию. Число директорий зависит от системы. В ранних ОС имелась только одна корневая директория, затем появились директории для пользователей (по одной директории на пользователя). В современных ОС используется произвольная структура дерева директорий. Таким образом, файлы на диске образуют иерархическую древовидную структуру (см. рис. 11.4).
Рис. 11.4 Древовидная структура файловой системы. Существует несколько эквивалентных способов изображения дерева, структура перевернутого дерева, приведенного на рис.11.4, наиболее популярна. Верхнюю вершину называют корнем. Если элемент дерева не может иметь потомков, он называется терминальной вершиной или листом (в данном случае является файлом). Не листовые вершины – справочники или каталоги, содержат списки листовых и не листовых вершин. Путь от корня к файлу однозначно определяет файл. Внутри одного каталога имена листовых файлов уникальны. Имена файлов, находящихся в разных каталогах могут совпадать. Для того чтобы однозначно определить файл по его имени (избежать коллизии имен) принято именовать файл полным именем (pathname), которое состоит из списка имен вложенных каталогов, по которому можно найти путь от корня к файлу, плюс имя файла в каталоге, непосредственно содержащем данный файл. Таким образом, имя включает цепочку имен - путь к файлу, например /usr/ast/mailbox. Это так называемое абсолютное имя. Такие имена уникальны. Компоненты пути разделяют символами ‘/’ (слеш) в Unix или обратными слешами в MS-DOS (в Multics – ‘>’).
Базы данных Типы баз данных Наиболее широко распространенными являются иерархические, сетевые и реляционные модели данных, каждая из которых имеет свою внутреннюю схему построения. Соответствующим образом называют и СУБД, поддерживающие перечисленные модели. В иерархических БД данные представляются в виде древовидной структуры (см. рис.1). Дерево представляет собой иерархию элементов, называемых узлами. На самом верхнем уровне иерархии имеется только один узел - корень. Каждый узел, кроме корня, связан с одним узлом на более высоком уровне, называемом исходным узлом для данного узла. Ни один элемент не имеет более одного исходного. Каждый элемент может быть связан с одним или несколькими элементами на более низком уровне. Они называются порожденными. Иерархическая база данных, как правило, состоит из совокупности таких «деревьев», которые образуют множество деревьев, или «лес». Иерархические БД обладают высокой скоростью доступа к требуемой информации в направлении от основания дерева к его вершинам, однако, с другой стороны, затрудненным доступом к информации в обратном направлении - от периферии к основанию дерева.
Рис.1. Схематическое изображение иерархической БД Если порожденный элемент в отношении между данными имеет более чем один исходный элемент, то это отношение, очевидно, уже нельзя описать как древовидную структуру. Его описывают в виде сетевой структуры (см. рис. 2).
Рис. 2. Схематическое изображение сетевой БД Каждый элемент в сетевой структуре может быть связан с любым другим элементом. Такие структуры используются для представления данных в сетевых СУБД. В сетевых моделях снимается указанный выше недостаток иерархических БД, однако, с другой стороны, язык манипулирования данными для таких моделей всегда является гораздо более сложным, так как содержит большое число разнотипных команд и слабо формализуется.
В настоящее время на персональных компьютерах наиболее распространены т.н. реляционные модели БД. В основе реляционной модели данных лежит понятие отношения, или реляции (relation – отношение, англ., отсюда и происходит термин реляционные БД). Отношение удобно и наглядно представляется в виде двумерной (плоской) таблицы при соблюдении определенных ограничивающих условий. Данные в таблицах могут быть связанными, а сама реляционная база данных представляет собой набор таких взаимосвязанных таблиц. В реляционных БД (РБД) все объекты разделяются на типы, т.е. каждый объект относится к некоторому типу. Объекты одного и того же типа имеют свой, соответствующий их типу, набор атрибутов. Поэтому объекты одного типа в РБД представляются записями с одинаковым количеством полей, а каждый экземпляр объекта можно представить как вектор с соответствующим количеством измерений. Например, если n – количество атрибутов объекта данного типа, то i-й экземпляр объекта можно представить как вектор Аi=(Ai1,Ai2,…,Ain). Вся совокупность из m экземпляров объектов данного типа может быть представлена в виде матрицы или таблицы размерностью m*n вида
В зависимости от содержания в РБД различают два типа отношений: объектные и связные. Объектное отношение хранит данные об объектах и отражает зависимости между атрибутами объекта, связное отношение отражает зависимости между отдельными таблицами в РБД. В объектном отношении один из атрибутов однозначно идентифицирует объект в таблице, т.е. запись в таблице, а именно каждому конкретному значению такого атрибута будет соответствовать одна и только одна запись (строка) в таблице. Понятно, что значения такого атрибута в столбце таблицы должны быть уникальны и никогда не повторяться. Такой атрибут называется первичным ключом отношения. Для удобства первичный ключ обычно размещают в первом столбце таблицы. Для обеспечения уникальности значения первичного ключа, если в таблице нет одного атрибута с неповторяющимися значениями, такой ключ может состоять из нескольких атрибутов, и тогда он называется составным ключом. В связном отношении атрибуты-признаки разных таблиц используются для организации связей между таблицами. Благодаря наличию таких связей обеспечивается целостность БД и взаимодействие данных, содержащихся в различных таблицах БД. Реляционную модель данных предложил в 1969 году Э.Ф. Кодд – сотрудник фирмы IBM. Основной принцип реляционного подхода заключается в использовании операций над таблицами, а не над отдельными записями, что имеет место в иерархических и сетевых БД. Можно выделить следующие важные преимущества РБД: · отношения (таблицы) не зависят от способа хранения данных в компьютере; · теория отношений является областью математической логики, т.н. реляционной алгебры, и поэтому хорошо формализована; · имеется простой и единообразный способ представления данных в виде таблиц;
· осуществляется надежное обеспечение целостности и защиты данных и некоторые другие. Важным достоинством реляционной модели данных является то, что на основе уже имеющихся схем отношений можно получать новые схемы, которые ранее в файле базы данных не были представлены. Таким способом соответствующая СУБД позволяет получать ответы на незапланированные прикладными программами информационные запросы. Необходимо отметить, что РБД не лишены и определенных недостатков: медленность работы для больших БД, жесткость структуры данных и некоторые другие. Однако для персональных компьютеров и не очень больших БД в настоящее время используются исключительно реляционные модели БД. Итак, перечислим исходные компоненты реляционной модели данных, основанной на совокупности отношений: · все множество объектов (записей) предметной области, которую описывает БД, разделяется на несколько типов, каждый из которых представляется своей таблицей; · каждому типу объектов соответствует определенный набор атрибутов, который определяет содержание соответствующей данному типу объектов таблице; · каждый тип объектов имеет свои признаки или характеристики – атрибуты, значения которых содержатся в полях – в столбцах таблицы; · каждому конкретному объекту данного типа соответствует определенный набор значений этих атрибутов, соответствующий строке в таблице; · атрибут (или набор атрибутов), однозначно определяющий объект в таблице (т.е. строку в таблице), называется первичным ключом объекта; · в таблицах имеются также атрибуты, являющиеся первичными ключами в других таблицах, т.н. внешние ключи, которые обеспечивают связь между таблицами в РБД. 1.2. Нормализация отношений в РБД Самым простым примером РБД является база данных, состоящая всего из одного отношения – одной таблицы. Однако в таком случае, как правило, не будут выполняться основные требования, предъявляемые к структуре БД из-за возникающих проблем избыточности информации, нарушения целостности данных, сложности редактирования данных, низкой скорости обработки информации и т.п. Убедимся в этом на конкретном примере небольшой БД, основанной на одной таблице «Поставки товаров», в которой будем хранить сведения о товарах, их цене, количестве и стоимости, а также о поставщиках, их адресах и расчетных счетах. Предположим, что эти данные будут храниться в следующей таблице (здесь приведены только первые четыре записи и всего 7 полей, хотя в реальной БД их число будет неизмеримо большим):
Анализируя структуру таблицы, необходимо прежде всего отметить, что в ней имеется повторяющаяся информация о поставщике. Кроме того, стоимость товара является избыточной информацией, так как всегда может быть получена на основе цены товара и его количества. Далее, атрибуты «Адрес» и «Счет» характеризуют только поставщика и, вообще говоря, не связаны с поставляемым товаром. Существуют и другие более тонкие недостатки в структуре такой БД. Таким образом, на первом этапе проектирования РБД важнейшим является вопрос, какую выбрать схему отношений для данной БД из множества альтернативных вариантов, т.е. какую систему таблиц и с каким набором столбцов в каждой таблице выбрать для данной БД. Как правило, БД содержат объекты разных типов и для каждого типа объектов создается своя таблица с соответствующим набором столбцов-атрибутов объекта. Процесс создания оптимальной схемы отношений для РБД строго формализован и называется нормализацией БД. Нормализация – это формализованная процедура, в процессе выполнения которой атрибуты данных группируются в таблицы, а таблицы, в свою очередь, в БД. Цели нормализации следующие: · исключить дублирование информации; · исключить избыточность информации; · обеспечить возможность проведения непротиворечивых и корректных изменений данных в таблицах; · упростить и ускорить поиск информации в БД. Процесс нормализации состоит в приведении таблиц РБД к т.н. нормальным формам. Всего существует 5 нормальных форм, которые удовлетворяют соответствующим правилам нормализации. При этом в большинстве случаев оптимальная структура БД достигается при выполнении уже первых 3 правил нормализации, которые были сформулированы для РБД Э.Ф. Коддом в 1972 году. Чтобы таблица, а вместе с ней и БД, соответствовала 1-й нормальной форме, необходимо, чтобы все значения ее полей были атомарными (неделимыми) и невычисляемыми, а все записи – уникальными (не должно быть полностью совпадающих строк). Выполняя это правило, преобразуем первоначальную таблицу к виду
Чтобы таблица соответствовала 2-й нормальной форме, необходимо, чтобы она уже находилась в 1-й нормальной форме и все неключевые поля полностью зависели от ключевого. В данной таблице на роль ключевого поля может претендовать только поле (атрибут-признак) «Товар», значения которого в таблице не повторяются. Из других полей только поле «Поставщик» непосредственно связано с поставляемым товаром – полем «Товар», а поля «Индекс», «Область», «Город» и «Счет» характеризуют только самого поставщика. Поэтому, удовлетворяя 2-му правилу нормализации, необходимо разбить (или разложить) исходную таблицу на две – соответственно «Товары»
и «Поставщики»
Проведенное преобразование называется разложением, или проектированием, БД и является обратимой операцией. Причем проектирование исходной таблицы привело, с одной стороны, к уменьшению записей (строк) во второй таблице, однако, с другой стороны, для организации связей между отдельными таблицами и обеспечения таким образом целостности БД поле «Поставщик» появилось уже в обеих таблицах, привнося этим некоторую неизбежную избыточность информации в БД. Очевидно, что в больших БД, где реально существуют сотни и тысячи записей, эта избыточность во много раз будет перекрыта уменьшением общего размера таблиц, полученных из исходной таблицы при ее разложении. Заметим, что на роль ключевого поля таблицы «Поставщики» подходит поле «Поставщик», значения которого в этой таблице уже не повторяются. Можно отметить, что на эту роль вполне подходит и поле «Счет», значения которого также не будут повторяться, а само поле, хотя и выглядит как набор цифр, все же является не количественной, а качественной характеристикой объекта, т.е. является атрибутом-признаком, что необходимо для ключевого поля (см. выше). Чтобы теперь перейти к 3-й нормальной форме, необходимо прежде всего обеспечить, чтобы все таблицы БД находились во 2-й нормальной форме и все неключевые поля в таблицах зависели только от ключа таблицы и не зависели непосредственно друг от друга. Анализируя таблицу «Поставщики», можно заметить, что поля «Область» и «Город» являются зависимыми от поля «Индекс», и поэтому эта таблица не находится в 3-й нормальной форме. В связи с этим, необходимо разбить таблицу на две: оставить в таблице «Поставщики» только два «Поставщик» и «Счет», а также поле «Индекс» для обеспечения связи между таблицами,
а остальные поля выделить в новую таблицу «Адреса»,
в которой поле «Индекс», естественно, будет ключевым, так как его значения в таблице не повторяются. Приведение БД к 4-й и 5-й нормальным формам является необходимой операцией в специальных случаях, когда между элементами БД существуют связи типа многие-ко-многим (см. ниже) и при этом необходимо обеспечить возможность точного восстановления исходной таблицы из таблиц, на которые она была спроектирована. Как уже говорилось выше, этими правилами нормализации при проектировании БД в большинстве случаев можно пренебречь. Типы связей и ключей в РБД Как уже отмечалось, в БД все таблицы должны быть так или иначе связаны между собой, чтобы обеспечить целостность данных, создающих информационную модель некой предметной области. Если оказалось, что одна из таблиц в создаваемой БД не имеет связей ни с одной другой таблицей, то в этом случае необходимо создавать новую БД либо рассматривать более широкую предметную область, для которой создается БД. Связи между таблицами организуются с помощью различных ключей. Связное отношение хранит ключи двух или более объектных отношений, по этим ключам устанавливаются связи между объектами. Связное отношение кроме связываемых ключей может иметь и другие атрибуты, которые будут функционально зависеть от этой связи. Ключи в связных отношениях называются внешними ключами, поскольку они являются первичными ключами других отношений. Каждому внешнему ключу должна соответствовать строка какого-либо объектного отношения. Невыполнение этого ограничения может привести к нарушению ссылочной целостности данных. Ключ должен ссылаться на объект, который существует. Перечислим условия и ограничения, накладываемые на отношения реляционной моделью данных, которые позволяют таблицы считать отношениями: 1. Не может быть одинаковых значений для первичных ключей, т.е. все строки таблицы должны быть в целом уникальны и определяться значением первичного ключа однозначно. 2. Все строки таблицы должны иметь одну и ту же структуру, т.е. одно и то же количество атрибутов. 3. Имена столбцов таблицы должны быть различны, а значения столбцов должны быть однотипными. 4. Значения атрибутов должны быть простыми, следовательно, отношения не могут иметь в качестве компонент другие отношения. 5. Должна соблюдаться ссылочная целостность для внешних ключей. 6. Порядок следования строк в таблице несущественен - он лишь влияет на скорость доступа к строке. Хорошо организованная база данных обеспечивает удобный доступ к хранящейся в ней информации. При правильном проектировании базы данных будет меньше затрачиваться времени и усилий на ввод данных в базу, внесение изменений и извлечение данных из базы. Этап установки связей между таблицами нужен для того, чтобы указать, какие действия надо предпринимать для объединения содержимого таблиц, составляющих РБД. После того как пользователь установит связи между таблицами, СУБД сможет использовать эти связи для поиска связанной информации в разных таблицах базы данных. В теории РБД существует три типа межтабличных отношений или связей: один-ко-многим, многие-ко-многим и один-к-одному (четвертый возможный тип отношений - многие-к-одному фактически сводится к первому типу, так как является его «зеркальным отражением» и в СУБД Access просто совпадает со связью один-ко-многим). Связь один-ко-многим является наиболее распространенной в реляционных базах данных. При таком типе отношений одной записи в первой таблице могут соответствовать несколько записей во второй таблице, однако каждой записи во второй таблице соответствует не более одной записи в первой таблице, что отражает в полной мере функциональную зависимость второй таблицы от первой. Связь многие-ко-многим означает, что каждой записи в первой таблице могут соответствовать несколько записей во второй таблице, а каждой записи во второй таблице -- несколько записей в первой таблице. В СУБД Access такой тип отношений напрямую не допускается, и во избежание такой ситуации создается еще одна вспомогательная таблица, которая связывается с обеими исходными таблицами связью типа один-ко-многим. При связи один-к-одному каждой записи в первой таблице может соответствовать не более одной записи во второй таблице, а каждой записи во второй таблице -- не более одной записи в первой таблице. Такой тип межтабличных отношений используется тогда, когда для удобства в работе очень широкую таблицу разбивают на две с повторением одного поля в каждой либо когда из таблицы необходимо выделить часть, к которой нужно обеспечить особый режим допуска (например, конфиденциальные сведения о сотрудниках, содержащиеся в одном или нескольких полях таблицы, к которым должны иметь доступ только определенные лица). В любом случае наличие связей (отношений) между таблицами второго и третьего типов означает, что база данных спроектирована не совсем оптимально или же просто содержит ошибки. Хорошо спроектированная база данных обычно не содержит отношений между таблицами двух последних типов. Как уже отмечалось выше, основным достоинством любой БД является способность быстро находить и объединять информацию, хранящуюся в разных таблицах. Для решения первой задачи каждая таблица в БД должна содержать поле или набор полей, значение которого или совокупность значений которых однозначно определяет каждую запись этой таблицы. На языке БД такое поле или совокупность полей называется ключом таблицы, а точнее, первичным ключом таблицы. При этом кандидатами на роль ключа таблицы могут быть любые поля, которые содержат уникальные (неповторяющиеся) значения для каждой записи, т.н. потенциальные ключи таблицы. Если в роли ключа выступают сразу несколько полей, когда в таблице просто нет одного поля с неповторяющимися значениями, то приходится подбирать такую комбинацию полей, значение которой будет уникальным. Такой ключ называется составным ключом. Для решения второй из названных задач -- объединения информации и организации связей между таблицами -- используются поля таблиц, имеющие совпадающие значения. При этом связь один-ко-многим образуется между первичным ключом одной таблицы, которая называется главной, и т.н. внешним, или вторичным, ключом другой таблицы, которая называется подчиненной. Значения внешнего ключа в таблице могут повторяться (отсюда термин ко-многим в названии связи), а сам внешний ключ, например поле «Поставщик» в таблице «Товары» или поле «Индекс» в таблице «Поставщики», получил такое название потому, что при проектировании (разложении) таблицы на составляющие такое поле специально вводится в вычленяемую таблицу именно для организации связей между таблицами и обеспечения целостности данных в БД.
ОРС в свете СОМ. OPC (OLE for Process Control, или OLE для Управления Процессами) – промышленный стандарт, созданный консорциумом производителей оборудования и программного обеспечения. Этот стандарт основан на объектной модели COM/DCOM фирмы Microsoft. Стандарт описывает интерфейсы обмена данными между приложениями систем управления технологическими процессами. Главная цель технологии OPC - предоставить разработчикам систем единый универсальный механизм сбора данных из разнородных источников и передачу этих данных любой клиентской программе вне зависимости от типа используемого оборудования. Архитектура OPC Стандарт обмена данными OPC базируется на распространенной архитектуре Клиент-Сервер. Она позволяет подключить множество клиентов к одному серверу. И наоборот, имеется возможность использования одним клиентом различных ОРС-серверов. На сегодня технология OPC является своего рода стандартом в области построения систем автоматизации. OPC-сервер представляет собой программную среду, обеспечивающую одновременный унифицированный способ доступа к данным для различных программных пакетов. В нашем случае это SCADA-пакеты различных производителей программного обеспечения. Полезность применения OPC с точки зрения интеграции достаточно прозрачна и вытекает из самой сути OPC - это стандарт на интерфейс обмена данными с оборудованием, дающий следующие преимущества: · Независимость в применении систем автоматизации от оборудования, используемого в конкретном проекте. · Стандартный, открытый, независимый от производителя оборудования интерфейс. · Отсутствие необходимости модифицировать программное обеспечение из-за модификации оборудования или выпуска новых изделий. · Свобода выбора между поставщиками оборудования у заказчика, возможность интегрировать это оборудование в информационную систему предприятия, которая может охватывать всю систему производства, управления и логистики. Организация OPC Foundation Разработку стандартов OPC, их описание, поддержку и пропаганду ведет добровольная международная организация OPC Foundation, расположенная в городке Boca Raton, штат Флорида США. Организация насчитывает более 250 членов, в числе которых компании, занимающие лидирующие позиции в области автоматизации: Honeywell, Fisher-Rosemount, Siemens, Wonderware, Intellution и другие. Microsoft, Inc. также является членом OPC Foundation, принимая участие в разработке новых спецификаций. Типы спецификаций OPC Основные текущие спецификации: · OPC DA (Data Access) — основной и наиболее востребованный стандарт. Описывает набор функций обмена данными в реальном времени с ПЛК, РСУ, ЧМИ, ЧПУ и другими устройствами. Примером сервера, поддерживающего OPC DA 2.0, 2.05a является сервер AccelOPC, разработанный нашей компанией. · OPC AE (Alarms & Events) — предоставляет функции уведомления по требованию о различных событиях: аварийные ситуации, действия оператора, информационные сообщения и другие. · OPC Batch — особая спецификация OPC, которая уже широко применяется в автоматике. Ее используют для посылки пропорций дозирования в технологические процессы и отслеживания выполнения этих пропорций (лабораторные системы, дозаторы, весовые системы и т.п., работающие в соответствии со стандартом S88.01). Очень важный момент состоит в том, что каждый OPC Batch сервер (клиент) одновременно является OPC Data Access 2.0 сервером (клиентом). Другими словами, OPC Batch сервер (клиент) включает в себя, кроме спецификации OPC Batch, также и спецификацию OPC Data Access 2.0, включая некоторые дополнительные интерфейсы (например, загрузка переменных). · OPC DX (Data eXchange) — предоставляет функции организации обмена данными между OPC-серверами через сеть Ethernet. Основное назначение — создание шлюзов для обмена данными между устройствами и программами разных производителей. · OPC HDA (Historical Data Access) — в то время как OPC Data Access предоставляет доступ к мгновенным значениям (данным, изменяющимся в реальном времени), OPC Historical Data Access предоставляет доступ к уже сохраненным данным (архивам). · OPC Security — определяет функции организации прав доступа клиентов к данным системы управления через OPC-сервер. · OPC XML-DA (XML-Data Access) — предоставляет гибкий, управляемый правилами формат обмена данными через SOAP и HTTP. Цель данной спецификации – разработать гибкий и удобный интерфейс для обмена данными через OPC, используя XML (Extensible Markup Language) в приложениях Internet/Intranet. Функции XML позволяют очень легко записывать любые структуры данных и, в то же время, передавать данные в виде XML-файлов, удобных для пересылки через Internet. · OPC UA (Unified Architecture) — последняя по времени выпуска спецификация, которая основана не на технологии Microsoft COM, что предоставляет кроссплатформенную совместимость.
Замечания Технология OPC не обеспечивает работы в жестком реальном времени, поскольку в DCOM отсутствуют понятия качества обслуживания, крайних сроков и т.п. Но частота передачи данных порядка 50 миллисекунд достигается без каких либо специальных мер. Для передачи данных по OPC обязательно наличие OPC сервера. Его можно либо получить вместе с устройством, либо купить, либо написать самостоятельно. Один из обязательных компонентов для работы технологии OPC – COM и его сетевая версия DCOM. DCOM – стандартный компонент для операционных систем Windows NT 4.0, Windows 2000, Windows XP, Windows 2003 и Windows 98. Для работы в Windows 95 DCOM нужно установить дополнительно. Все эти операционные системы позволяют передавать данные в рамках одного компьютера или через локальную сеть. В операционной системе Windows CE сетевые возможности появились в версии 3.0. Недавно стандарт OPC был разработан и для операционной системы Linux.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2021-05-27; просмотров: 133; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.217.194.39 (0.067 с.) |
 Эффективное управление этими данными подразумевает наличие в них четкой логической структуры. Все современные файловые системы поддерживают многоуровневое именование файлов за счет поддержания во внешней памяти дополнительных файлов со специальной структурой – каталогов (или директорий).
Эффективное управление этими данными подразумевает наличие в них четкой логической структуры. Все современные файловые системы поддерживают многоуровневое именование файлов за счет поддержания во внешней памяти дополнительных файлов со специальной структурой – каталогов (или директорий).