
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Сегментная организация памяти.Содержание книги Похожие статьи вашей тематики
Поиск на нашем сайте
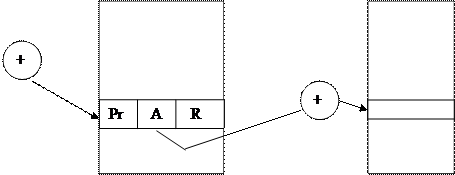
Сегментная организация памяти – это один из способов организации виртуальной памяти. Транслятор подготавливает задачу в виде совокупности сегментов, в общем случае разного размера. Эти сегменты хранятся во внешней памяти. Адресация внутри сегментов носит непрерывный характер. Виртуальные адреса, после трансляции, имеют вид – (s,d), где s – виртуальный номер сегмента, а d – смещение относительно начала сегмента. Предполагается, что в общем случае, при первоначальной загрузке сегментов задачи в оперативную память, не все из них могут попасть в неё, и часть сегментов задачи может остаться во внешней памяти. Отображение виртуальных адресов в физические происходит на этапе выполнения задачи и имеет вид (см. рис.):
Рг. начального адреса
Таблица дескрипторов сегментов Сегмент
При загрузке задачи в оперативную память, ОС, совместно с аппаратурой, создаёт в памяти таблицу дескрипторов сегментов задачи. Первоначально дескрипторы сегментов задачи создаются на этапе её трансляции. Каждый дескриптор имеет поля, содержимое которых может изменяться во время выполнения задачи. На рис. показаны некоторые из них: - Pr – битовый признак присутствия/отсутствия сегментов в оперативной памяти (0 – сегмент отсутствует в памяти, 1 – сегмент присутствует в памяти); - A – начальный адрес сегмента; - R – размер сегмента. В специальном регистре процессора хранится значение начального адреса таблицы дескрипторов сегментов выполняемой задачи. При переключении на выполнение новой задачи ОС меняет содержимое этого регистра. Отображение виртуальных адресов в физические адреса производится в два этапа. На первом этапе определяется адрес конкретного дескриптора в таблице путем сложения начального адреса таблицы, хранящегося в регистре, и значения S. Если сегмент отсутствует в памяти (pr=0), то генерируется соответствующее прерывание и вызывается программа подкачки сегмента (своппинг). На втором этапе определяется значение физического адреса путём сложения значений A и I. Перед выполнением этой операции выполняется проверка условия I<=R. Если это условие выполняется (физический адрес определяется корректно и не выходит за адресуемый сегмент), то определение физического адреса внутри страницы разрешается. В противном случае генерируется соответствующее прерывание, и адресация к странице откладывается.
Рассмотрим свойства сегментной организации памяти. Во первых необходимо отметить, что загружаемым в память объектом является сегмент некоторой задачи а не её код целиком. Кроме того, при данной организации памяти обеспечивается автоматическое перекрытие сегментов в памяти (на место в памяти, где хранился некоторый сегмент, возможна загрузка нового необходимого сегмента). Уровень фрагментации памяти может быть достаточно высоким. Это связано с тем, что при перекрытии сегментов в памяти могут образовываться значительные по размеру незаполненные области памяти из за разных размеров сегментов. 14. Страничная организация памяти. Страничная организация памяти – это ещё один из способов организации виртуальной памяти. Транслятор подготавливает задачу в виде совокупности виртуальных страниц одинакового размера. Эти страницы хранятся во внешней памяти. Адресация внутри страниц носит непрерывный характер. Виртуальные адреса, после трансляции, имеют вид – (p,i), где i – виртуальный номер страницы, а i – смещение относительно начала страницы. Предполагается, что в общем случае, при первоначальной загрузке страниц задачи в оперативную память, не все из них могут попасть в неё, и часть страниц задачи может остаться во внешней памяти. Физическая память рассматривается как совокупность физических страниц того же размера как и виртуальные страницы. Отображение виртуальных адресов в физические происходит на этапе выполнения задачи и имеет вид (см. рис.):
Таблица дескрипторов Страница Страниц
При загрузке задачи в оперативную память, ОС, совместно с аппаратурой, создаёт в памяти таблицу дескрипторов страниц задачи. Первоначально дескрипторы страниц задачи создаются на этапе её трансляции. Каждый дескриптор имеет поля, содержимое которых может изменяться во время выполнения задачи. На рис. показаны некоторые из них:
- Pr – битовый признак присутствия/отсутствия страниц в оперативной памяти (0 – сегмент отсутствует в памяти, 1 – сегмент присутствует в памяти); - F – физический номер страницы. В специальном регистре процессора хранится значение начального адреса таблицы дескрипторов страниц выполняемой задачи. При переключении на выполнение новой задачи ОС меняет содержимое этого регистра. Отображение виртуальных адресов в физические адреса производится в два этапа. На первом этапе определяется адрес конкретного дескриптора в таблице путем сложения начального адреса таблицы, хранящегося в регистре, и значения P. Если страница отсутствует в памяти (pr=0), то генерируется соответствующее прерывание и вызывается программа подкачки страницы (своппинг). На втором этапе определяется значение физического адреса внутри страницы путём реализации операции приписывания (//). Данная операция может быть представлена в виде F*L+I, где L – размер страницы. Так как умножение выполняется медленно, значение L выбирается кратным степени двойки. В этом случае умножение заменяется на быструю операцию сдвига влево на число разрядов равное степени двойки. Рассмотрим свойства страничной организации памяти. Во первых, необходимо отметить, что загружаемым в память объектом является страница некоторой задачи а не её код целиком. Кроме того, при данной организации памяти обеспечивается автоматическое перекрытие страниц в памяти (на место в памяти, где находилась некоторая страница, возможна загрузка новой необходимой страницы). Уровень фрагментации памяти при страничной организации значительно ниже, чем при сегментной. Но для страничной организации памяти характерна внутренняя фрагментация. Внутренняя фрагментация памяти образуется из-за незаполненности последней страницы кода задачи. В среднем, последняя страница задачи незаполнена полезным кодом на 50%. Поэтому важным вопросом является выбор значения размера страниц. Выбор размера страниц основывается на двух противоречивых соображениях. Чем больше размер страницы, тем выше уровень внутренней фрагментации. С другой стороны, если размер страницы делать небольшим, увеличивается интенсивность своппинга, что может значительно увеличить время выполнения отдельных задач и понизить эффективность работы вычислительной системы в целом. Поэтому размеры страниц выбираются в пределах 8 12 2 <= L<=2 байт.
15. Свопинг. Его стратегии. Своппинг (swaping) - это необходимый механизм при организации виртуальной памяти, так как с его помощью реализуется автоматическое перекрытие страниц или сегментов в оперативной памяти. Своппинг состоит из двух процедур – процедуры подкачки страниц (сегментов) из внешней памяти в оперативную, и процедуры откачки страниц (сегментов) из оперативной памяти во внешнюю. Для этого ОС выделяет специальную область внешней памяти, где могут храниться временно откачанные страницы или сегменты задач. Существуют различные стратегии (дисциплины) подкачки и откачки, которые требуют специального рассмотрения.
Стратегии подкачки. Принципиально могут рассматриваться только два метода подкачки необходимых страниц (сегментов) – это опережающая подкачка и подкачка по требованию. Опережающая подкачка основывается на том, что поведение программ при их выполнении можно предсказать. Следовательно, можно заранее определить – какие страницы или сегменты задачи необходимо сразу загрузить в оперативную память. В действительности, поведение программ, в подавляющем большинстве случаев, непредсказуемо. Поэтому идея опережающей подкачки не нашла практического воплощения. Подкачка по требованию состоит в загрузке необходимой страницы (сегмента), когда к данной странице произошло фактическое обращение. Данная стратегия реализуется относительно просто, но при этом она способствует увеличению интенсивности свопинга, что является недостатком стратегии. Стратегии откачки (вытеснения). Откачка страниц необходима, когда в оперативной памяти отсутствуют свободные физические страницы. В этом случае необходимо выбрать занятую физическую страницу для её откачки во внешнюю память. Существует доказанное положение о том, что прежде всего необходимо откачивать такую страницу, следующее обращение к которой будет нескоро. На основе данного положения были реализованы различные стратегии откачки, отличающиеся друг от друга сложностью реализации и показателями качества. Случайная откачка предполагает случайный выбор страницы для откачки. Данная стратегия проста в реализации, но плохо согласуется с вышеуказанным положением. При случайной откачке слишком часто будут откачиваться нужные страницы. FIFO – “первым подкачан – первым откачан”. При данной стратегии, прежде всего откачивается та страница, которая дольше остальных находится в оперативной памяти. Если обращения к памяти носят последовательный характер, то откачиваемая страница становится ненужной на достаточно длительный период времени. Тем не менее, при такой стратегии часто удаляются нужные страницы. Основным достоинством FIFO является простота реализации, так как планировщику памяти достаточно следить за очередью физических страниц, упорядоченных по времени подкачки. LRU (least recently used) – определяет факт давности использования страниц, т. е. прежде всего, откачивается та страница, к которой не было обращений в течение некоторого интервала времени. Данная стратегия даёт хорошие результаты, но сложна в реализации. Сложность реализации объясняется тем, что ОС, совместно с аппаратурой, должна создавать и оперативно изменять список страниц, которым не было обращений в течение некоторого заданного интервала времени.
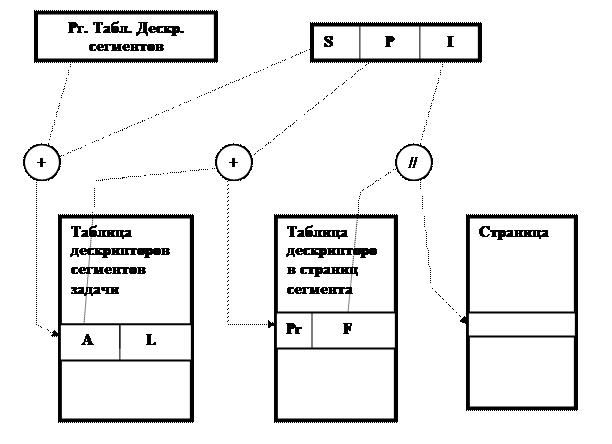
LFU (least frequently used) – определяет факт частоты использования страниц, т. е. прежде всего, откачивается та страница, к которой было меньше всего обращений за заданный интервал времени. Планировщик, однако, не должен учитывать страницы, которые были подкачаны в память только что. Иначе такие страницы станут первыми кандидатами на откачку. Данная стратегия также достаточно сложна в реализации, но даёт хорошее качество. Механизм своппинга необходим при организации виртуальной памяти, но так как при своей реализации он требует значительного времени (обмен с внешней памятью) желательно минимизировать его использование. 16. Сегментно-страничная организация памяти. Компилятор подготавливает задачу в виде совокупности виртуальных сегментов, в общем случае, различной длины. Каждый сегмент состоит из целого числа виртуальных страниц. Виртуальные страницы имеют одинаковую фиксированную длину. Адресация внутри виртуальных страниц носит непрерывный характер. Виртуальные адреса представляются в виде троек (S,P,I), где S – виртуальный номер сегмента, P – виртуальный номер страницы, I – смещение относительно начала страницы. Физическая память представляет собой множество физических страниц того же размера, что и виртуальные страницы. Отображение виртуальных адресов в физические адреса показано на рис.
При загрузке задачи в оперативную память ОС, совместно с аппаратурой, создаёт в памяти таблицу дескрипторов сегментов задачи, а для каждого сегмента – соответствующую таблицу дескрипторов страниц. Загружаемым объектом в память является страница. Каждый дескриптор сегмента содержит начальный адрес соответствующей таблицы дескрипторов страниц (поле А) и размер сегмента в страницах (поле L). Каждый дескриптор страницы содержит признак присутствия/отсутствия страницы в оперативной памяти (поле Pr) и физический номер страницы в памяти (поле F). Перед выполнением задачи, в специальный регистр процессора заносится начальный адрес таблицы дескрипторов сегментов текущей выполняемой задачи. Отображение виртуальных адресов в физические производится во время выполнения задачи и требует трёх обращений к памяти (к таблице дескрипторов сегментов, к таблице дескрипторов страниц, к самой странице), что видно на рис. Такая схема отображения имеет существенный недостаток – низкое быстродействие из-за большого числа обращений к памяти. Для устранения данного недостатка используется дополнительный аппаратно-программный механизм кэш памяти, функционирующей на основе ассоциативного принципа. Каждая ячейка кэш памяти состоит из двух полей (см. рис.) – поля аргумента (X) и поля функции (Y). При использовании кэш памяти на все её ячейки параллельно подаётся значение ключа (Key). Если значение ключа совпадает со значением аргумента, то на выходные шины кэш памяти выдаётся значение функции.
Y X
Использовать кэш память для ускорения отображения виртуальных адресов в физические адреса можно следующим образом. Выберем в качестве аргумента пару (S,P), а в качестве функции – F. Предположим, что произошло первое обращение к новой странице. Тогда физический адрес определится по основной схеме, но параллельно в ячейку кэш памяти занесутся значения S,P – в поле аргумента, и F – в поле функции. Вероятность того, что следующее обращение будет к той же самой странице очень велика. Поэтому, при следующем обращении, скорее всего, сработает быстрый механизм кэш памяти и выдастся значение F, после чего, быстро выполнится операция приписывания и физический адрес будет определён. Механизм кэш памяти для определения физического адреса будет срабатывать до тех пор, пока не произойдёт обращение к следующей странице. Так как кэш память имеет относительно небольшой объём, для неё актуальна проблема вытеснения ненужных заполненных ячеек. Решать эту проблему необходимо, когда кэш память заполнена полностью и происходит обращение к новой странице. Наиболее оптимальной стратегией вытеснения является LFU. Вытеснение ненужных ячеек может производиться также и в случае, когда кэш память заполнена лишь частично. 17. Проблемы синхронизации параллельных процессов. Функционирование мультипрограммной вычислительной системы характерно тем, что в её среде одновременно развиваются несколько параллельных процессов. В своём развитии параллельные процессы часто используют одни и те же ресурсы системы, т. е. разделяют их. Часть таких разделяемых ресурсов требуют только последовательного использования со стороны процессов, т. е. в каждый момент времени только один процесс может использовать разделяемый ресурс. Такие ресурсы называются критическими. Для того чтобы обеспечить последовательное использование критических ресурсов необходимо синхронизировать доступ к ним. Задача синхронизации, в общем случае, состоит в следующем. Если несколько процессов хотят пользоваться критическим ресурсом в режиме разделения, им следует синхронизировать свои действия таким образом, чтобы такой ресурс всегда находился в распоряжении не более чем одного из них. Если один процесс пользуется в данный момент критическим ресурсом, то все остальные процессы, которым нужен этот ресурс, должны получить отказ в доступе и ждать, пока он не освободится. Если в системе не предусмотрена защита от одновременного доступа процессов к критическим ресурсам, в ней могут возникать ошибки, которые трудно обнаружить и исправить. Основной причиной возникновения таких ошибок является то, что процессы развиваются с разными скоростями, причём эти скорости самим процессам неподвластны и неизвестны друг другу. Рассмотрим несколько примеров, как отсутствие синхронизации при доступе к критическим ресурсам влияет на результаты выполнения процессов. Пусть два конкурирующих процесса Р1 и Р2 асинхронно увеличивают значение общей переменной Х, предварительно считывая её значение в свои локальные области памяти R1 и R2. Р1: (1) R1:=X; (2) R1:=R1+1; (3) X:=R1; P2: (4) R2:=X; (5) R2:=R2+1; (6) X:=R2; Поскольку процессы Р1 и Р2 могут иметь различные скорости выполнения, то может иметь место любая последовательность выполнения операций во времени. Например, если в промежуток времени между выполнением операций 1 и 3 будет выполнена хотя бы одна из операций 4-6, то значение переменной Х будет не (Х+2), а (Х+1). Если предположить, что процессы Р1 и Р2 осуществляли продажу билетов, и переменная Х фиксировала количество уже проданных билетов, то в результате некорректного взаимодействия было бы продано несколько билетов на одно и то же место. В качестве второго примера приведём пару процессов, которые изменяют различные поля записей служащих какого либо предприятия. Процесс АДРЕС изменяет домашний адрес служащего, а процесс СТАТУС – его должность и зарплату. Каждый процесс копирует всю запись в свою рабочую область памяти. Пусть каждый процесс должен обработать запись ИВАНОВ. Предположим, что после того как процесс АДРЕС скопировал запись ИВАНОВ в свою рабочую область, но до того как он записал скорректированную запись обратно, процесс СТАТУС скорректировал первоначальную запись ИВАНОВ в свою рабочую область. Изменения, выполненные тем из процессов, который первым запишет скорректированную запись назад в файл СЛУЖАЩИЕ, будут потеряны и, возможно, никто не будет знать об этом. Чтобы предотвратить некорректное исполнение конкурирующих процессов вследствие нерегламентированного доступа к разделяемым переменным, необходимо ввести такое понятие как взаимное исключение, которое не позволит двум или более процессам параллельно обращаться к разделяемым переменным. Кроме реализации в ОС средств, организующих взаимное исключение, в ней должны быть средства, синхронизирующие работу взаимодействующих процессов. Использование таких средств позволит взаимодействующим процессам корректно обмениваться данными, чтобы правильно выполнялась их общая работа. Типичным примером взаимодействующих процессов, использующих разделяемые ресурсы, является задача ПОСТАВЩИК-ПОТРЕБИТЕЛЬ. Решение данной задачи будет рассмотрено в следующих лекциях. Таким образом, при организации различного рода взаимодействующих процессов необходимо решать проблему корректного доступа к общим переменным, которые идентифицируют критические ресурсы с программной точки зрения. Те места в программах, в которых происходит обращение к критическим ресурсам, называются критическими интервалами или критическими секциями (critical section). Решение этой проблемы заключается в организации такого доступа к критическому ресурсу, когда только одному процессу разрешается входить в свою критическую секцию. Когда какой-либо процесс находится в своём критическом интервале, другие процессы могут продолжать своё выполнение, но без входа в свои критические секции. Взаимное исключение необходимо только в том случае, когда процессы обращаются к разделяемым, общим данным. Если же процессы выполняют операции, которые не приводят к конфликтным ситуациям, они должны иметь возможность выполняться параллельно. Когда процесс выходит из своего критического интервала, то одному из остальных процессов, ожидающих входа в свои критические секции, должно быть разрешено продолжить выполнение, т. е. разрешено войти в свой критический интервал. Задача взаимного исключения может быть сформулирована следующим образом: - в любой момент временитолько один процесс должен находиться в своей критической секции; - ни один процесс не должен находиться в своей критической секции бесконечно долго; - ни один процесс не должен бесконечно долго ждать входа в свою критическую секцию. Процесс, находящийся вне своей критической секции, не должен блокировать выполнение других процессов, ожидающих входа в свои критические интервалы. Если два процесса одновременно хотят войти в свои критические интервалы, то принятие решения о том, кто из них должен это сделать, не должно бесконечно откладываться. Если процесс, находящийся в своём критическом интервале, завершается естественным или аварийным путём, режим взаимоисключения должен временно отменяться для того, чтобы один из других процессов смог войти в свою критическую секцию. Для решения проблемы синхронизации параллельных процессов было предложено множество различных подходов, которые стали основой для программно-аппаратных средств из состава современных ОС. 18. Семафорные примитивы Дейкстры. Задача взаимного исключения. Семафор – это переменная специального типа, над которой определены две операции – закрытие семафора (P) и открытие семафора (V). Обобщённый смысл операции Р состоит в декрементации числового поля семафора и в проверке значения этого поля семафора. Если это значение оказывается меньше некоторой величины (чаще всего нуля), процесс, вызвавший данную операцию блокируется и помещается в очередь к семафору.. В противном случае процесс продолжает своё выполнение. Операция V связана с инкрементацией числового поля семафора. При этом, если выполняется некоторое условие, один из ранее заблокированных процессов деблокируется, т. е. покидает очередь к семафору и переходит в состояние готовности. Обычно семафор логически связывается с некоторым критическим ресурсом. Поэтому заблокированные процессы, находящиеся в очереди к семафору, косвенно ожидают доступа к критическому ресурсу. Операции P и V являются неделимыми операциями, т. е. их выполнение не может прерываться. Действия по блокированию и деблокированию процессов реализуют модули из состава ядра ОС. Допустимыми значениями числовых полей семафоров являются целые числа. Различают два вида семафоров – числовые и двоичные. Числовые семафоры – это семафоры, числовые поля которых могут принимать любые целые значения в некотором заданном диапазоне. Двоичные семафоры – это семафоры, числовые поля которых могут принимать только два значения: единица и ноль. Существуют различные реализации семафорных примитивов. Они отличаются друг от друга по различным параметрам (тип семафоров, диапазон изменения значений числовых полей семафоров, логика операций, дисциплина выбора процесса при его деблокировании и т. д.). Рассмотрим некоторые алгоритмы работы семафорных примитивов. Сначала представим вариант алгоритма реализации операций P и V для числовых семафоров: P(S): S:=S-1; If S<0 then <заблокировать процесс, и поместить его в очередь к семафору> V(S): S:=S+1; If S<=0 then <деблокировать один из ранее заблокированных процессов> Алгоритм работы семафорных примитивов P и V для двоичных семаров может выглядеть следующим образом: P(S): if S=1 then S:=0 Else Begin L:=L+1; <заблокировать процесс>; End;
V(S): if (S=0) and (L>0) then Begin <деблокировать один из процессов>; L:=L-1; If L=0 then S:=1; End; Здесь L – длина очереди заблокированных процессов. Решение задачи взаимного исключения с помощью семафорных примитивов для двух параллельных процессов можно представить следующим образом:
Var s: semaphor; Begin s:=1; Parbegin P1: while true do begin … P(s); CS1; V(s); … end; and P2: while true do begin … P(s); CS2; V(s); … end; parend end. Предположим, что первым начнёт выполняться процесс Р1. Прежде чем войти в свой критический интервал (CS1), он вызовет операцию P(s). После её выполнения значение числового поля семафора станет равным нулю, но Р1 войдёт в свой критический интервал. Если в этот момент процесс Р2 получит управление и захочет войти в свой критический интервал (CS2), он сначала вызовет выполнение операции P(s) и заблокируется по семафору s. Если через некоторое время процесс Р1 опять получит управление и выполнит свой критический интервал до конца, а также вызовет операцию V(s), процесс Р2 деблокируется и сможет войти в свой критический интервал. Задача взаимного исключения будет решена, так как только один из двух процессов будет находиться в своём критическом интервале. Использование семафорных примитивов для решения задач синхронизации имеет значительное достоинство: в случае блокировки процессы попадают в состояние пассивного ожидания не требуя использования процессорного времени. 19. Почтовые ящики. Почтовые ящики относятся к высокоуровневым средствам организации взаимодействий между параллельными процессами. Почтовые ящики предназначены для хранения и передачи сообщений между взаимодействующими процессами. Для хранения посланного, но ещё не полученного сообщения необходимо выделить некоторый буфер в памяти, он будет исполнять роль почтового ящика. Если процесс Р1 хочет общаться с процессом Р2, то Р1 просит ОС образовать почтовый ящик, который свяжет эти два процесса так, чтобы они могли передавать друг другу сообщения. Для того чтобы послать процессу Р2 какое-то сообщение, процесс Р1 просто помещает это сообщение в почтовый ящик, откуда процесс Р2 может его взять в любое время. При использовании почтового ящика процесс Р2 в конце концов обязательно получит сообщение, когда обратится за ним. Если объем передаваемых данных велик, то эффективнее не передавать их непосредственно, а отправлять в почтовый ящик сообщение, информирующее процесс получатель о том, где их можно найти (адресная ссылка). Почтовый ящик может быть связан только с парой процессов (отправитель и получатель), а может быть связан и с большим числом процессов. Почтовый ящик, связанный только с процессом получателем, облегчает посылку сообщений от нескольких процессов в фиксированный пункт назначения. Если почтовый ящик не связан с конкретными процессами, то сообщение должно содержать идентификаторы отправителя и получателя. Почтовый ящик – это информационная структура, поддерживаемая ОС. Она состоит из головного элемента (заголовка), в котором находится информация о характеристиках почтового ящика, и из нескольких буферов (гнёзд), в которые помещаются сообщения. Размер каждого гнезда и количество гнёзд обычно задаются при образовании почтового ящика. Правила работы почтовых ящиков могут разные в зависимости от их сложности. В простейшем случае сообщения передаются только в одном направлении. Процесс Р1 может посылать сообщения до тех пор, пока имеются свободные гнёзда. Если все гнёзда заполнены, то процесс Р1 вынужден ждать когда хотя бы одно из гнёзд освободится. Аналогично, процесс Р2 может получать сообщения до тех пор, пока имеются заполненные гнёзда. Если сообщений нет в почтовом ящике, Р2 будет ждать их появлений. Такие почтовые ящики называются однонаправленными. Реализацией однонаправленного почтового ящика является решение задачи “Поставщик-Потребитель”. Двунаправленный почтовый ящик, связанный с парой процессов, используется для подтверждения сообщений. Если используется множество гнёзд, то каждое из них может хранить либо сообщение, либо подтверждение (ответ). Чтобы гарантировать передачу подтверждений, когда все гнёзда заняты, подтверждение на сообщение помещается в то же гнездо, которое использовалось для хранения сообщения, и оно уже не используется для хранения другого сообщения до тех пор, пока подтверждение не будет получено. Из-за того, что некоторые процессы не забрали свои сообщения, связь может быть приостановлена. Если каждое сообщение снабдить пометкой времени появления в почтовом ящике, то системная управляющая процедура может уничтожать старые сообщения и освобождать гнёзда. Процессы могут быть также остановлены в связи с тем, что другие процессы не смогли послать им сообщения или подтверждения. Если время поступления сообщений в почтовый ящик регистрируется, то управляющая процедура может им периодически посылать процессам пустые сообщения или подтверждения, чтобы они не ждали слишком долго. При реализации почтовых ящиков используются низкоуровневые средства, например - семафорные примитивы и т. п. Рассмотрим интерфейс операций с двунаправленным почтовым ящиком, которые могут использовать процессы при своём взаимодействии: 1. Send_message (receiver, message, buffer) – посылка сообщения (message) получателю (receiver) через почтовый ящик (buffer). Процесс, выдавший данную операцию, продолжает своё выполнение. 2. Wait_message (sender, message, buffer) – процесс, выдавший данную операцию ждёт до тех пор, пока в почтовом ящике не появится сообщение от отправителя (sender) и не перепишется в собственную память получателя (message). 3. Send_answer (result, answer, buffer) – записывает ответ (answer) в тот буфер, в который было записано сообщение. 4. Wait_answer (result, answer, buffer) – блокирует процесс, выдавший данную операцию до тех пор, пока в почтовом ящике не появится ответ и не перепишется в собственную память процесса (answer). Значение переменной result определяет, каков ответ: от процесса получателя или пустой от ОС. Совокупность представленных операций с двунаправленным почтовым ящиком позволяет организовать различные варианты взаимодействия двух или более процессов. Почтовые ящики удобны для обмена сообщениями, но их затруднительно использовать для решения задачи взаимоисключения при доступе к критическим ресурсам. 20. Мониторы Хоара. Монитор – это пассивный набор разделяемых переменных и повторно входимых процедур доступа к ним, которым процессы пользуются в режиме разделения, причём в каждый момент времени им может пользоваться только один процесс. Монитор можно представить как комнату, от которой есть только один ключ. Если какой-то процесс намеревается воспользоваться этой комнатой и ключ находится снаружи, то этот процесс может отпереть комнату, войти в неё и воспользоваться одной из процедур монитора. Если ключа снаружи нет, то процессу придется ждать, пока тот, кто пользуется комнатой в данный момент, не выйдет из неё и не отдаст ключ. Кроме того, никому не разрешается в комнате оставаться навсегда. Рассмотрим, например, некоторый ресурс, который выделяет соответствующий планировщик. Каждый раз, когда процесс желает получить этот ресурс, он должен обратиться к планировщику. Процедуру планировщик разделяют все процессы, и каждый из них может обратиться к планировщику в любой момент. Но планировщик не в состоянии обслуживать более одного процесса одновременно. Такая процедура планировщик представляет собой пример монитора. Таким образом, монитор – это механизм организации параллелизма, который содержит как данные, так и процедуры, необходимые для динамического распределения конкретного общего ресурса или группы общих ресурсов. Процесс, желающий получить доступ к разделяемым переменным, должен обратиться к монитору, который либо предоставит доступ, либо откажет в нём. Вход в монитор находится под жёстким контролем – здесь осуществляется взаимоисключение процессов, так как в каждый момент времени только один процесс может пользоваться монитором. Процессам, которые хотят войти в монитор, когда он уже занят, приходится ждать, причём режимом ожидания управляет сам монитор. При отказе в доступе монитор блокирует обратившийся к нему процесс и определяет условие, по которому процесс ждёт. Проверка условия выполняется самим монитором, который и деблокирует ожидающий процесс. Внутренние переменные монитора могут быть либо глобальными (используемыми всеми процедурами монитора), либо локальными (используемыми только в своих процедурах). Обращение к этим переменным возможно только изнутри монитора. При первом обращении к монитору инициализируются начальные значения переменных. При последующих обращениях используются те значения переменных, которые остались от предыдущего обращения. Если процесс обращается к некоторой процедуре монитора и обнаруживается, что соответствующий ресурс уже занят, эта процедура монитора выдаёт команду WAIT с указанием условия ожидания. В этом случае, процесс, переводящийся в режим ожидания, будет ждать момента, когда необходимый ресурс освободится. Со временем процесс, который занимал данный ресурс, обратится к монитору, чтобы возвратить ресурс системе. В этом случае монитор выдаёт команду извещения (сигнализации) SIGNAL, чтобы один из ожидающих процессов мог получить данный ресурс и войти в монитор. Если монитор сигнализирует о возвращении ресурса, и в это время нет процессов, ожидающих такого ресурса, то он вносится в список свободных ресурсов. Чтобы гарантировать, что процесс, находящийся в ожидании некоторого ресурса, со временем его получит, считается, что ожидающий процесс имеет более высокий приоритет, чем новый процесс, пытающийся войти в монитор. Рассмотрим пример монитора для выделения одного ресурса.
Monitor resourse; Condition free; (* условие - свободный *) Var busy: Boolean; Procedure Request; (* запрос *) Begin If busy then WAIT (free); Busy:= true; Выдать ресурс; End; Procedure Release; (* освобождение *) Begin Взять ресурс; Busy:= false; SIGNAL (free); End; Begin Busy:= false; End. Единственный ресурс динамически запрашивается и освобождается процессами, которые обращаются к процедурам Request и Release. Если процесс обращается к процедуре Request в тот момент, когда ресурс используется, значение переменной busy будет true и Request выполни
|
||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2020-03-02; просмотров: 693; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.145.41.108 (0.012 с.) |











 Key
Key





