
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Структура программы на языке СиСодержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте
Оператор перехода В языке С определены четыре оператора перехода: return, goto, break и continue. Операторы return и goto можно использовать в любом месте внутри функции. Операторы break и continue можно использовать в любом из операторов цикла. Как указывалось ранее в этой главе, break можно также использовать в операторе switch. Оператор return Оператор return используется для выхода из функции. Отнесение его к категории операторов перехода обусловлено тем, что он заставляет программу перейти в точку вызова функции. Оператор return может иметь ассоциированное с ним значение, тогда при выполнении данного оператора это значение возвращается в качестве значения функции. В функциях типа void используется оператор return без значения. Стандарт С89 допускает наличие оператора return без значения, даже если тип функции отличен от void. В этом случае функция возвращает неопределенное значение. Но что касается языков С99 и C++, если тип функции отличен от void, то ее оператор return обязательно должен иметь значение. Конечно, и в программе на С89 отсутствие возвращаемого значения в функции, тип которой отличен от void, является признаком плохого стиля! Общая форма оператора return следующая: return выражение;Выражение присутствует только в том случае, если функция возвращает значение. Это значение выражения становится возвращаемым значением функции. Внутри функции может присутствовать произвольное количество операторов return. Выход из функции происходит тогда, когда встречается один из них. Закрывающаяся фигурная скобка } также вызывает выход из функции. Выход программы на нее эквивалентен оператору return без значения. В этом случае функция, тип которой отличен от void, возвращает неопределенное значение. Функция, определенная со спецификатором void, не может содержать return со значением. Так как эта функция не возвращает значения, в ней не может быть оператора return, возвращающего значение. Более подробно returnрассматривается в главе 6. Оператор goto Кроме goto, в языке С есть другие операторы управления (например break, continue), поэтому необходимости в применении goto практически нет. В результате чрезмерного использования операторов goto программа плохо читается, она становится "похожей на спагетти". Чаще всего такими программами недовольна администрация фирм, производящих программный продукт. То есть оператор goto весьма непопулярен, более того, считается, что в программировании не существует ситуаций, в которых нельзя обойтись без оператора goto. Но в некоторых случаях его применение все же уместно. Иногда, при умелом использовании, этот оператор может оказаться весьма полезным, например, если нужно покинуть глубоко вложенные циклы[1]. В данной книге оператор goto рассматривается только в этом разделе. Для оператора goto всегда необходима метка. Метка — это идентификатор с последующим двоеточием. Метка должна находится в той же функции, что и goto, переход в другую функцию невозможен. Общая форма оператора goto следующая: goto метка;... метка:Метка может находиться как до, так и после оператора goto. Например, используя оператор goto, можно выполнить цикл от 1 до 100: x = 1;loop1: x++; if(x<=100) goto loop1;Оператор break Оператор break применяется в двух случаях. Во-первых, в операторе switch с его помощью прерывается выполнение последовательности case (см. раздел "Оператор выбора — switch" ранее в этой главе). В этом случае оператор break не передает управление за пределы блока. Во-вторых, оператор break используется для немедленного прекращения выполнения цикла без проверки его условия, в этом случае оператор break передает управление оператору, следующему после оператора цикла. Когда внутри цикла встречается оператор break, выполнение цикла безусловно (т.е. без проверки каких-либо условий.) прекращается и управление передается оператору, следующему за ним. Например, программа #include <stdio.h> int main(void){ int t; for(t=0; t<100; t++) { printf("%d ", t); if(t==10) break; } return 0;}выводит на экран числа от 0 до 10. После этого выполнение цикла прекращается оператором break, условие t < 100 при этом игнорируется. Оператор break часто используется в циклах, в которых некоторое событие должно вызвать немедленное прекращение выполнения цикла. В следующем примере нажатие клавиши прекращает выполнение функции look_up(): void look_up(char *name){ do { /* поиск имени 'name' */ if(kbhit()) break; } while(!found); /* process match */}Библиотечная функция kbhit() возвращает 0, если клавиша не нажата (то есть, буфер клавиатуры пуст), в противном случае она возвращает ненулевое значение. В стандарте С функция kbhit() не определена, однако практически она поставляется почти с каждым компилятором (возможно, под несколько другим именем). Оператор break вызывает выход только из внутреннего цикла. Например, программа for(t=0; t<100; ++t) { count = 1; for(;;) { printf("%d ", count); count++; if(count==10) break; }}100 раз выводит на экран числа от 1 до 9. Оператор break передает управление внешнему циклу for. Если оператор break присутствует внутри оператора switch, который вложен в какие-либо циклы, то break относится только к switch, выход из цикла не происходит. Функция exit() Функция exit() не является оператором языка, однако рассмотрим возможность ее применения. Аналогично прекращению выполнения цикла оператором break, можно прекратить работу программы и с помощью вызова стандартной библиотечной функции exit(). Эта функция вызывает немедленное прекращение работы всей программы и передает управление операционной системе. Общая форма функции exit() следующая: void exit (int код_возврата);Значение переменной код_возврата передается вызвавшему программу процессу, обычно в качестве этого процесса выступает операционная система. Нулевое значение кода возврата обычно используется для указания нормального завершения работы программы. Другие значения указывают на характер ошибки. В качестве кода возврата можно использовать макросыEXIT_SUCCESS и EXIT_FAILURE (выход успешный и выход с ошибкой). Функция exit() объявлена в заголовочном файле<stdlib.h>. Функция exit() часто используется, когда обязательное условие работы программы не выполняется. Рассмотрим, например, компьютерную игру в виртуальной реальности, использующую специальный графический адаптер. Главная функцияmain() этой игры выглядит так: #include <stdlib.h> int main(void){ if(!virtual_graphics()) exit(1); play(); /*... */}/*.... */Здесь virtual_graphics() возвращает значение ИСТИНА, если присутствует нужный графический адаптер. Если требуемого адаптера нет, вызов функции exit(1) прекращает работу программы. В следующем примере в новой версии ранее рассмотренной функции menu() вызов exit() используется для выхода из программы и возврата в операционную систему: void menu(void){ char ch; printf("1. Проверка правописания\n"); printf("2. Коррекция ошибок\n"); printf("3. Вывод ошибок\n"); printf("4. Выход\n"); printf(" Введите Ваш выбор: "); do { ch = getchar(); /* чтение клавиши */ switch(ch) { case '1': check_spelling(); break; case '2': correct_errors(); break; case '3': display_errors(); break; case '4': exit(0); /* Возврат в ОС */ } } while(ch!='1' && ch!='2' && ch!='3'); }Оператор continue Можно сказать, что оператор continue немного похож на break. Оператор break вызывает прерывание цикла, a continue — прерывание текущей итерации цикла и осуществляет переход к следующей итерации. При этом все операторы до конца тела цикла пропускаются. В цикле for оператор continue вызывает выполнение операторов приращения и проверки условия цикла. В циклах while и do-while оператор continue передает управление операторам проверки условий цикла. В следующем примере программа подсчитывает количество пробелов в строке, введенной пользователем: /* Подсчет количества пробелов */#include <stdio.h> int main(void){ char s[80], *str; int space; printf("Введите строку: "); gets(s); str = s; for(space=0; *str; str++) { if(*str!= ' ') continue; space++; } printf("%d пробелов\n", space); return 0;}Каждый символ строки сравнивается с пробелом. Если сравниваемый символ не является пробелом, оператор continueпередает управление в конец цикла for и выполняется следующая итерация. Если символ является пробелом, значение переменной space увеличивается на 1. В следующем примере оператор continue применяется для выхода из цикла while путем передачи управления на условие цикла: void code(void){ char done, ch; done = 0; while(!done) { ch = getchar(); if(ch=='$') { done = 1; continue; } putchar(ch+1); /* печать следующего в алфавитном порядке символа */ }}Функция code предназначена для кодирования сообщения путем замены каждого символа символом, код которого на 1 больше кода исходного символа в коде ASCII. Например, символ А заменяется символом В (если это латинские символы.). Функция прекращает работу при вводе символа $. При этом переменной done присваивается значение 1 и оператор continueпередает управление на условие цикла, что и прекращает выполнение цикла.
[1]Уже одно это (чрезмерная вложенность и неожиданный выход сразу из нескольких циклов) может свидетельствовать о плохой структуре программы. №10 Сортировка массива Сортировкой называется такой процесс перестановки элементов массива, когда все его элементы выстраиваются по возрастанию или по убыванию. Сортировать можно не только числовые массивы, но и, например, массивы строк (по тому же принципу, как расставляют книги на библиотечных полках). Вообще сортировать можно элементы любого множества, где задано отношение порядка. Существуют универсальные алгоритмы, которые выполняют сортировку вне зависимости от того, каким было исходное состояние массива. Но кроме них существуют специальные алгоритмы, которые, например, очень быстро могут отсортировать почти упорядоченный массив, но плохо справляются с сильно перемешанным массивом (или вообще не справляются). Специальные алгоритмы нужны там, где важна скорость и решается конкретная задача, их подробное изучение выходит за рамки нашего курса. Сортировка массива выбором Рассмотрим пример сортировки по возрастанию. То есть на начальной позиции в массиве должен стоять минимальный элемент, на следующей — больший или равный и т. д., на последнем месте должен стоять наибольший элемент. Суть алгоритма такова. Во всём отыскиваем минимальный элемент, меняем его местами с начальным. Затем в оставшейся части массива (т. е. среди всех элементов кроме начального) снова отыскиваем минимальный элемент, меняем его местами уже со вторым элементом в массиве. И так далее. #include <iostream>#include <cstdlib>#include <ctime>using namespace std;int main() { int n = 13; int a[n]; srand(time(NULL)); for (int i=0; i<n; i++) { a[i] = rand()%90+10; cout << a[i] << " "; } for (int i=0; i<n; i++) { int min=a[i], imin = i; for (int j=i+1; j<n; j++) { if(a[j]<min) { min = a[j]; imin = j; } } if (imin!= i) { int t = a[i]; a[i] = a[imin]; a[imin] = t; } } cout << endl; for (int i=0; i<n; i++) { cout << a[i] << " "; } }Сортировка методом пузырька Суть алгоритма такова. Если пройдёмся по любому массиву установив правильный порядок в каждой паре соседних элементов, то после того прохода на последнем месте массива гарантированно будет стоять нужный элемент (самый большой для сортировки по возрастанию или самый маленький для сортировки по убыванию). Если ещё раз пройтись по массиву с такими же преобразованиями, то и на предпоследнем месте гарантированно окажется нужный элемент. И так далее. Пример: 2 9 1 4 3 5 2 → порядок правильный, не будет перестановки 2 9 1 4 3 5 2 → 2 1 9 4 3 5 2 2 1 9 4 3 5 2 → 2 1 4 9 3 5 2 2 1 4 9 3 5 2 → 2 1 4 3 9 5 2 2 1 4 3 9 5 2 → 2 1 4 3 5 9 2 2 1 4 3 5 9 2 → 2 1 4 3 5 2 9 Код: #include <iostream>#include <cstdlib>#include <ctime>using namespace std;int main() { int n = 13; int a[n]; srand(time(NULL)); for (int i=0; i<n; i++) { a[i] = rand()%90+10; cout << a[i] << " "; } for (int i=n-1; i>=2; i--) { bool sorted = true; for (int j=0; j<i; j++) { if (a[j] > a[j+1]) { int temp = a[j]; a[j] = a[j+1]; a[j+1] = temp; sorted = false; } } if(sorted) { break; } } cout << endl; for (int i=0; i<n; i++) { cout << a[i] << " "; } }Не редко программисты сталкиваются с задачей поиска ключевого значения в массиве. Под ключевым значением подразумевается искомое значение в массиве. В программировании насчитывается огромное количество методов поиска значения в массиве. Но мы рассмотрим два основных метода поиска в массивах:
Линейный поиск в массивах Линейный поиск в массивах, или как его ещё называют, поиск в ЛОБ эффективен в масссивах, с небольшим количеством элементов, причём элементы в таких массивах никак не отсортированы и неупорядочены. Алгоритм линейного поиска в массивах последовательно проверяет все элементы массива и сравнивает их с ключевым значением. Таким образом, в среднем необходимо проверить половину значений в массиве, чтобы найти искомое значение. Чтобы убедиться, в отсутствии искомого значения необходимо проверить все элементы массива. Разработаем программу, которая ищет минимальное значение в массиве. Поиск в программе реализован согласно алгоритму линейного поиска в массиве. ?
В строке 12 объявлена переменная с квалификатором const. В цикле for строки 14 - 18 заполняется массив array1 и сразу же печатаются знячения элементов массива. Два действия объединены в один цикл, таким образом не надо объявлять отдельный цикл для вывода значений массива. В строке 19 объявлена переменная min для хранения минимального значения, которое будет найдено в ходе линейного поиска в массиве. Причём переменная min инициализирована первым значением массива, так как перед сравнением необходимо сначала инициализировать переменную. В строках 20 - 24 объявлен цикл for, в котором будет выполнятся алгоритм линейного поиска в массивах. Переменная-счётчик в цикле for инициализирована единицей, то есть обработка массива начнётся со второго элемента, ведь первый элемент массива уже содержится в переменной min В теле цикла объявлен оператор условного выбора if, который будет последовательно сравнивать значение в переменной min со значениями элементов массива array1. В каждой итерации цикла будет выполнятся проверка условия в строке 22, и если условие истинно, то в переменную min будет записываться всё меньшее и меньшее значение, если таковое окажется в массиве. В противном случае значение в переменной min меняться не будет. Результат работы алгоритма линейного поиска в массиве (см. Рисунок 1).
Рисунок 1 - Поиск в массивах С++ Как показала программа, значение 26 - это минимальное значение массива array1. Мы знаем как искать минимальное значение в массиве, используя алгоритм линейного поиска в массиве. Переделаем эту программу так, чтобы она искала максимальное значение в массиве. Всё, что нужно изменить, так это знак строгого отношения, в операторе условного выбора if, на противоположный, строка 22. ?
Теперь мы знаем, как быстро и легко переделать алгоритм линейного поиска в массивах минимального значения на алгоритм линейного поиска в массивах максимального значения. Мы организовали линейный поиск в одномерном массиве, в двумерных массивах алгоритм линейного поиска не изменится. Рассмотрим фрагмент кода - алгоритм линейного поиска в двумерном массиве. ?
В строке 1 мы инициализируем переменную min первым значением двумерного массива array1, для того, чтобы избежать логических ошибок. Фактически переменную min можно не инициализировать, и программа будет работать правильно. Но существует вероятностьвозникновения логической ошибки, то есть программа сработает, но сработает не правильно. Суть в том, что при объявлении переменной, в ней изначально будет содержаться какое-то значение(это значение называют мусор), и в зависимости от того, какое значение будет содержаться в переменной изначально, без принудительной инициализации этой переменной, программа будет работать не правильно. Так как будет сравнивать значения массива с мусором. Обычно мусор всегда положительный, а значит минимальное значение в массиве будет искаться безошибочно. В случае с алгоритмом линейного поиска в массиве максимального значения, программа всегда будет срабатывать не правильно. Именно по этому мы принудительно инициализируем переменную min или max начальным значением. тогда возникает вопрос: "Каким значением инициализировать эту переменную?". Да всё просто, инициализируем переменную min любым значением из массива. Да, не обязательно выполнять инициализацию первым значением из массива, можно взять любое. Но для простоты советую брать первое значение массива. Алгоритм линейного поиска в двумерном массиве не сильно изменился, а точнее, вообще не изменился. Добавился ещё один цикл for, ведь поиск выполняется в двумерном массиве. Бинарный поиск в массивах Двоичный(бинарный) поиск - алгоритм поиска элемента в отсортированном массиве. Бинарный поиск нашёл себе применение в математике и информатике. Возможно, Вы не будете пользоваться алгоритмом двоичного поиска, но знать его принцип работы должны. Двоичный поиск можно использовать только в том случае, если есть массив, все элементы которого упорядочены (отсортированы). Бинарный поиск не используется для поиска максимального или минимального элементов, так как в отсортированном массиве эти элементы содержатся в начале и в конце массива соответственно, в зависимости от тога как отсортирован массив, по возрастанию или по убыванию. Поэтому алгоритм бинарного поиска применителен, если необходимо найти некоторый ключевой элемент в массиве. То есть организовать поиск по ключу, где ключ - это определённое значение в массиве. Разработаем программу, в которой объявим одномерный массив, и организуем двоичный поиск.Объявленный массив нужно инициализировать некоторыми значениями, причём так, чтобы эти значения были упорядоченны. ?
Итак, в строке 9 объявлена целочисленная переменная константа, которой присвоено значение 10 - размер одномерного массива. Согласно тону хорошего программирования размер статического массива должен задаваться в отдельной переменной, с квалификатором const. В строке 10 объявлен одномерный массив соответствующего размера. Строки 11 - 16 выводят на экран элементы массива с некоторым оформлением. В строках 17 -19 объявляются переменные. которые будут использоваться в алгоритме двоичного поиска В строке 21 объявлена переменная, значение в которой будет искомым. В строка 23 - 33 находится алгоритм двоичного поискав массивах. Сначала нужно проверить размер массива, вкотором будет искаться ключевое значение ,строка 23. Массив может быть нулевого размера, если размер массива больше или равен 1, тогда начинаем искать ключевое значение. Объявление цикла while строки 25 - 29, в цикле организован поиск значения таким образом, что после выхода из цикла индекс найденного значения сохранится в переменной last_index. В телецикла, строка 28 объявлена условная операция ?:, хотя можно было воспользоваться оператором выбора if else. И наконец, в строках 30 - 33 объявлен оператор условного выбора if else, который определяет, говорит о том, было ли найдено искомое значение или нет. ?
Так как, алгоритмы сортировки, нам пока не известны, то массив инициализируем вручную, причём обязательно упорядоченно. В строке 21 указываем искомый элемент массива и запускаем программу (см. Рисунок2).
Механизм параметров является основным способом обмена информацией между вызываемой и вызывающей функциями. Параметры, перечисленные в заголовке описания функции, называются формальными, а записанные в операторе вызова функции — фактическими (или аргументами). При вызове функции в первую очередь вычисляются выражения, стоящие на месте фактических параметров; затем в стеке выделяется память под формальные параметры функции в соответствии с их типом, и каждому из них присваивается значение соответствующего фактического параметра. При этом проверяется соответствие типов и при необходимости выполняются их преобразования. При несоответствии типов выдается диагностическое сообщение. Существует два вида передачи величин в функцию: по значению и по адресу. При передаче по значению в стек заносятся копии значений фактических параметров, и операторы функции работают с этими копиями. Доступа к исходным значениям параметров у функции нет, а, следовательно, нет и возможности их изменить. При передаче по адресу в стек заносятся копии адресов параметров, а функция осуществляет доступ к ячейкам памяти по этим адресам и может изменить исходные значения параметров: #include <iostream.h> void f(int i, int* j, int& k); int main() {int i = 1, j = 2, k = 3; cout <<"i j k\n"; cout << i <<' '<< j <<' '<< k <<'\n'; f(i, &j, k); cout << i <<' '<< j <<' '<< k; } void f(int i, int* j, int& k) {i++; (*j)++; k++;} Результат работы программы: i j k 1 2 3 1 3 4 Первый параметр (i) передается по значению. Его изменение в функции не влияет на исходное значение. Второй параметр (j) передается по адресу с помощью указателя, при этом для передачи в функцию адреса фактического параметра используется операция взятия адреса, а для получения его значения в функции требуется операция разыменования. Третий параметр (k) передается по адресу с помощью ссылки. При передаче по ссылке в функцию передается адрес указанного при вызове параметра, а внутри функции все обращения к параметру неявно разыменовываются. Поэтому использование ссылок вместо указателей улучшает читаемость программы. Использование ссылок вместо передачи по значению более эффективно, поскольку не требует копирования параметров. Если требуется запретить изменение параметра, используется модификатор const: int f(const char*); char* t(char* a, const int* b); СОВЕТ Рекомендуется указывать const перед всеми параметрами, изменение которых в функции не предусмотрено. Это облегчает отладку. Кроме того, на место параметра типа const& может передаваться константа. Параметры, передаваемые в функцию, могут быть любого типа (например, вещественного, структурой, перечислением, объединением, указателем), кроме массива или функции, которые передаются с помощью указателей. УРОК 13. ПЕРЕГРУЗКА ФУНКЦИЙ При определении функций в своих программах вы должны указать тип возвращаемого функцией значения, а также количество параметров и тип каждого из них. В прошлом (если вы программировали на языке С), когда у вас была функция с именем add_values, которая работала с двумя целыми значениями, а вы хотели бы использовать подобную функцию для сложения трех целых значений, вам следовало создать функцию с другим именем. Например, вы могли бы использовать add_two_values и add_three_values. Аналогично если вы хотели использовать подобную функцию для сложения значений типа float, то вам была бы необходима еще одна функция с еще одним именем. Чтобы избежать дублирования функции, C++ позволяет вам определять несколько функций с одним и тем же именем. В процессе компиляции C++ принимает во внимание количество аргументов, используемых каждой функцией, и затем вызывает именно требуемую функцию. Предоставление компилятору выбора среди нескольких функций называется перегрузкой. В этом уроке вы научитесь использовать перегруженные функции. К концу данного урока вы освоите следующие основные концепции: • Перегрузка функций позволяет вам использовать одно и то же имя для нескольких функций с разными типами параметров. • Для перегрузки функций просто определите две функции с одним и тем же именем и типом возвращаемого значения, которые отличаются количеством параметров или их типом. Перегрузка функций является особенностью языка C++, которой нет в языке С. Как вы увидите, перегрузка функций достаточно удобна и может улучшить удобочитаемость ваших программ. КОГДА НЕОБХОДИМА ПЕРЕГРУЗКА Одним из наиболее общих случаев использования перегрузки является применение функции для получения определенного результата, исходя из различных параметров. Например, предположим, что в вашей программе есть функция с именем day_of_week, которая возвращает текущий день недели (0 для воскресенья, 1 для понедельника,..., 6 для субботы). Ваша программа могла бы перегрузить эту функцию таким образом, чтобы она верно возвращала день недели, если ей передан юлианский день в качестве параметра, или если ей переданы день, месяц и год: int day_of_week(int julian_day) { int day_of_week(int month, int day, int year) { По мере изучения объектно-ориентированного программирования в C++, представленного в следующих уроках, вы будете использовать перегрузку функций для расширения возможностей своих программ. ЧТО ВАМ НЕОБХОДИМО ЗНАТЬ Перегрузка функций позволяет вам указать несколько определений для одной и той же функции. В процессе компиляции C++ определит, какую функцию следует использовать, основываясь на количестве и типе передаваемых параметров. Из данного урока вы узнали, что перегружать функции достаточно просто. Из урока 14 вы узнаете, как ссылки C++ упрощают процесс изменения параметров внутри функций. Однако, прежде чем перейти к уроку 14, убедитесь, что вы изучили следующие основные концепции:
№25 Рекурсия Рекурсия — это такой способ организации вспомогательного алгоритма (подпрограммы), при котором эта подпрограмма (процедура или функция) в ходе выполнения ее операторов обращается сама к себе. Вообще, рекурсивным называется любой объект, который частично определяется через себя. Например, приведенное ниже определение двоичного кода является рекурсивным: <двоичный код>::= <двоичная цифра> | <двоичный код><двоичная цифра> <двоичная цифра>::= 0 | 1Здесь для описания понятия были использованы, так называемые, металингвистический формулы Бэкуса-Наура (язык БНФ); знак "::=" обозначает "по определению есть", знак "|" — "или". Вообще, в рекурсивном определении должно присутствовать ограничение, граничное условие, при выходе на которое дальнейшая инициация рекурсивных обращений прекращается. Приведём другие примеры рекурсивных определений. Пример 1. Классический пример, без которого не обходятся ни в одном рассказе о рекурсии, — определение факториала. С одной стороны, факториал определяется так: n!=1*2*3*...* n. С другой стороны,
Граничным условием в данном случае является n <=1. Пример 2. Определим функцию K(n), которая возвращает количество цифр в заданном натуральном числе n:
Задание. По аналогии определите функцию S(n), вычисляющую сумму цифр заданного натурального числа. Пример 3. Функция C(m, n), где 0 <= m <= n, для вычисления биномиального коэффициента Ниже будут приведены программные реализации всех этих (и не только) примеров. Обращение к рекурсивной подпрограмме ничем не отличается от вызова любой другой подпрограммы. При этом при каждом новом рекурсивном обращении в памяти создаётся новая копия подпрограммы со всеми локальными переменными. Такие копии будут порождаться до выхода на граничное условие. Очевидно, в случае отсутствия граничного условия, неограниченный рост числа таких копий приведёт к аварийному завершению программы за счёт переполнения стека. Порождение все новых копий рекурсивной подпрограммы до выхода на граничное условие называется рекурсивным спуском. Максимальное количество копий рекурсивной подпрограммы, которое одновременно может находиться в памяти компьютера, называется глубиной рекурсии. Завершение работы рекурсивных подпрограмм, вплоть до самой первой, инициировавшей рекурсивные вызовы, называется рекурсивным подъёмом. Выполнение действий в рекурсивной подпрограмме может быть организовано одним из вариантов: { { { P; операторы; операторы; операторы; P; P; } } операторы; } рекурсивный подъём рекурсивный спуск и рекурсивный спуск, и рекурсивный подъёмЗдесь P — рекурсивная подпрограмма. Как видно из рисунка, действия могут выполняться либо на одном из этапов рекурсивного обращения, либо на обоих сразу. Способ организации действий диктуется логикой разрабатываемого алгоритма. Реализуем приведённые выше рекурсивные определения в виде функций. Пример 1. double Factorial(int N) { double F; if (N<=1) F=1.; else F=Factorial(N-1)*N; return F; }Пример 2. int K(int N) { int Kol; if (N<10) Kol=1; else Kol=K(N/10)+1; return Kol; }Пример 3. int C(int m, int n) { int f; if (m==0||m==n) f=1; else f=C(m, n-1)+C(m-1, n-1); return f; }Пример 4. Вычислить сумму элементов линейного массива. При решении задачи используем следующее соображение: сумма равна нулю, если количество элементов равно нулю, и сумме всех предыдущих элементов плюс последний, если количество элементов не равно нулю. #include <stdio.h> #include <conio.h> #include <stdlib.h> #include <time.h> int summa(int N, int a[100]); int i,n, a[100]; void main() { clrscr(); printf("\nКоличество элементов массива? "); scanf("%d", &n); printf("\nВ сформированном массиве %d чисел:\n", n); randomize(); for (i=0; i<n; i++) {a[i]= -10+random(21); printf("%d ", a[i]);} printf("Сумма: %d", summa(n-1, a)); } int summa(int N, int a[100]) { if (N==0) return a[0]; else return a[N]+summa(N-1, a); }
Пример 5. Определить, является ли заданная строка палиндромом, т.е. читается одинаково слева направо и справа налево. Идея решения заключается в просмотре строки одновременно слева направо и справа налево и сравнении соответствующих символов. Если в какой-то момент символы не совпадают, делается вывод о том, что строка не является палиндромом, если же удается достичь середины строки и при этом все соответствующие символы совпали, то строка является палиндромом. Граничное условие — строка является палиндромом, если она пустая или состоит из одного символа. #include <stdio.h> #include <conio.h> #include <string.h> char s[100]; int pal(char s[100]); void main() { clrscr(); printf("\nВведите строку: "); gets(s); if (pal(s)) printf("Строка является палиндромом"); else printf("Строка не является палиндромом"); } int pal(char s[100]) { int l; char s1[100]; if (strlen(s)<=1) return 1; else {l=s[0]==s[strlen(s)-1]; strncpy(s1, s+1, strlen(s)-2); s1[strlen(s)-2]='\0'; return l&&pal(s1);} }
Подводя итог, заметим, что использование рекурсии является красивым приёмом программирования. В то же время в большинстве практических задач этот приём неэффективен с точки зрения расходования таких ресурсов ЭВМ, как память и время исполнения программы. Использование рекурсии увеличивает время исполнения программы и зачастую требует значительного объёма памяти для хранения копий подпрограммы на рекурсивном спуске. Поэтому на практике разумно заменять рекурсивные алгоритмы на итеративные. Структура программы на языке СИ
Программа на языке Си это текстовый файл с расширением. c Текст программы имеет определенную структуру: 1. заголовок 2. включение необходимых внешних файлов 3. ваши определения для удобства работы 4. объявление глобальных переменных Перед использованием переменной в Си её необходимо объявить! Т.е. указать компилятору какой тип данных она может хранить и как она называется. Глобальные переменные объявляются, вне какой либо функции. Т.е. не после фигурной скобки {. Они доступны в любом месте программы, значит можно читать их значения и присваивать им значения там, где требуется. 5. описание функций - обработчиков прерываний 6. описание других функций используемых в программе 7. функция main - это единственный обязательный пункт!
Это не жесткий порядок, а ориентировочный! Иногда п. 6 - это прототипы функций, а сами функции описываются полностью после п. 7. Прототип функции - показывает образец того, как применять функцию в программе, какие значения в нее передаются и, если она возвращает какое-то значение, то прототип указывает тип возвращаемых данных. Прототип не име
|
||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-04-07; просмотров: 892; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.15 (0.017 с.) |




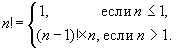

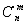 по следующей формуле
по следующей формуле  является рекурсивной.
является рекурсивной.


