Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Другие операции над спискамиСодержание книги
Поиск на нашем сайте
Что ещё можно делать со списками? Вот несколько основных функ- ций работы с ними.
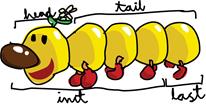
Функция head принимает список и возвращает его головной элемент. Головной элемент списка – это, собственно, его первый элемент. ghci> head [5,4,3,2,1]
5 Функция tail принимает список и возвращает его «хвост». Ины- ми словами, эта функция отрезает «голову» списка и возвращает остаток.
ghci> tail [5,4,3,2,1]
[4,3,2,1] Функция last принимает список и возвращает его последний элемент.
ghci> last [5,4,3,2,1]
1 Функция init принимает список и возвращает всё, кроме его последнего элемента.
ghci> init [5,4,3,2,1]
[5,4,3,2]
Если представить список в виде сороконожки, то с функциями получится примерно такая картина:
Но что будет, если мы попытаемся получить головной элемент пустого списка?
ghci> head []
*** Exception: Prelude.head: empty list Ну и ну! Всё сломалось!.. Если нет сороконожки, нет и «голо- вы». При использовании функций head, tail, last и init будьте осто- рожны – не применяйте их в отношении пустых списков. Эту ошиб- ку нельзя отловить на этапе компиляции, так что всегда полезно предотвратить случайные попытки попросить язык Haskell выдать несколько элементов из пустого списка.
Функция length, очевидно, принимает список и возвращает его длину: ghci> length [5,4,3,2,1]
5 Функция null проверяет, не пуст ли список. Если пуст, функция возвращает True, в противном случае – False. Используйте эту фун- кцию вместо xs == [] (если у вас есть список с именем xs).
ghci> null [1,2,3] False
ghci> null [] True Функция reverse обращает список (расставляет его элементы в обратном порядке).
ghci> reverse [5,4,3,2,1]
[1,2,3,4,5]
Функция take принимает число и список. Она извлекает соот- ветствующее числовому параметру количество элементов из нача- ла списка: ghci> take 3 [5,4,3,2,1] [5,4,3] ghci> take 1 [3,9,3] [3] ghci> take 5 [1,2] [1,2]
ghci> take 0 [6,6,6] [] Обратите внимание, что если попытаться получить больше эле- ментов, чем есть в списке, функция возвращает весь список. Если мы пытаемся получить 0 элементов, функция возвращает пустой список. Функция drop работает сходным образом, но отрезает указан-
ное количество элементов с начала списка: ghci> drop 3 [8,4,2,1,5,6] [1,5,6] ghci> drop 0 [1,2,3,4] [1,2,3,4]
ghci> drop 100 [1,2,3,4] [] Функция maximum принимает список, состоящий из элементов, которые можно упорядочить, и возвращает наибольший элемент.
Функция minimum возвращает наименьший элемент. ghci> minimum [8,4,2,1,5,6] ghci> maximum [1,9,2,3,4]
9 Функция sum принимает список чисел и возвращает их сумму. Функция product принимает список чисел и возвращает их про-
изведение. ghci> sum [5,2,1,6,3,2,5,7] ghci> product [6,2,1,2] ghci> product [1,2,5,6,7,9,2,0]
0 ИНТЕРВАЛЫ 35
Функция elem принимает элемент и список элементов и прове- ряет, входит ли элемент в список. Обычно эта функция вызывается как инфиксная, поскольку так её проще читать: ghci> 4 `elem` [3,4,5,6] True
ghci> 10 `elem` [3,4,5,6] False
А что если нам нужен список всех чисел от 1 до 20? Конечно, мы могли бы просто набрать их подряд, но, очевидно, это не решение для джентльмена, требующего совершенства от языка программирова- ния. Вместо этого мы будем использо- вать интервалы. Интервалы – это способ создания списков, являющихся арифме- тическими последовательностями эле- ментов, которые можно перечислить по порядку: один, два, три, четыре и т. п. Символы тоже могут быть перечислены: например, алфавит – это перечень символов от A до Z. А вот имена перечислить нельзя. (Какое, например, имя будет идти после «Иван»? Лично я понятия не имею!) Чтобы создать список, содержащий все натуральные числа от 1 до 20, достаточно написать [1..20]. Это эквивалентно пол- ной записи [1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20],
и единственная разница в том, что записывать каждый элемент списка, как показано во втором варианте, довольно глупо. ghci> [1..20] [1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20]
ghci> ['a'..'z'] "abcdefghijklmnopqrstuvwxyz" ghci> ['K'..'Z'] "KLMNOPQRSTUVWXYZ" Интервалы замечательны ещё и тем, что они позволяют указать шаг. Что если мы хотим внести в список все чётные числа от 1 до 20? Или каждое третье число от 1 до 20?
ghci> [2,4..20] [2,4,6,8,10,12,14,16,18,20] ghci> [3,6..20]
[3,6,9,12,15,18] Нужно всего лишь поставить запятую между первыми двумя элементами последовательности и указать верхний предел диа- пазона. Но, хотя интервалы достаточно «умны», на их сообрази- тельность не всегда следует полагаться. Вы не можете написать [1,2,4,8,16..100] и после этого ожидать, что получите все степени двойки. Во-первых, потому, что при определении интервала можно указать только один шаг. А во-вторых, потому что некоторые после- довательности, не являющиеся арифметическими, неоднозначны, если представлены только несколькими первыми элементами. ПРИМЕЧАНИЕ. Чтобы создать список со всеми числами от 20 до 1 по убыванию, вы не можете просто написать [20..1], а долж- ны написать [20,19..1]. При попытке записать такой интервал без шага (т. е. [20..1]) Haskell начнёт с пустого списка, а затем будет увеличивать начальный элемент на единицу, пока не достигнет или не превзойдет элемент в конце интервала. Поскольку 20 уже превосходит 1, результат окажется просто пустым списком.
Будьте осторожны при использовании чисел с плавающей точ- кой в интервалах! Из-за того что они не совсем точны (по опреде- лению), их использование в диапазонах может привести к весьма забавным результатам. ghci> [0.1, 0.3.. 1]
[0.1,0.3,0.5,0.7,0.8999999999999999,1.0999999999999999] Мой совет: не используйте такие числа в интервалах! Интервалы, кроме прочего, можно использовать для создания бесконечных списков, просто не указывая верхний предел. Позже мы рассмотрим этот вариант в подробностях. А сейчас давайте пос- мотрим, как можно получить список первых 24 чисел, кратных 13. Конечно, вы могли бы написать [13,26..24*13]. Но есть способ по- лучше: take 24 [13,26..]. Поскольку язык Haskell ленив, он не будет пытаться немедленно вычислить бесконечный список, потому что процесс никогда не завершится. Он подождет, пока вы не захотите получить что-либо из такого списка. Тут-то обнаружится, что вы хо- тите получить только первые 24 элемента, что и будет исполнено.
Немного функций, производящих бесконечные списки: ® Функция cycle принимает список и зацикливает его в беско- нечный. Если вы попробуете отобразить результат, на это уй- дёт целая вечность, поэтому вам придётся где-то его обрезать.
ghci> take 10 (cycle [1,2,3]) [1,2,3,1,2,3,1,2,3,1]
ghci> take 12 (cycle "LOL ") "LOL LOL LOL " ® Функция repeat принимает элемент и возвращает бесконеч- ный список, состоящий только из этого элемента. Это по- добно тому, как если бы вы зациклили список из одного эле- мента.
ghci> take 10 (repeat 5)
[5,5,5,5,5,5,5,5,5,5] Однако проще использовать функцию replicate, если вам ну- жен список из некоторого количества одинаковых элементов. replicate 3 10 вернёт [10,10,10].
Если вы изучали курс математики, то, возможно, сталкивались со способом задания множества путём описания ха- рактерных свойств, которыми долж- ны обладать его элементы. Обычно этот метод используется для построе- ния подмножеств из множеств. Вот пример простого описания множества. Множество, состо- ящее из первых десяти чётных чисел, это S = {2 · x | x Î N, x £ 10}, где выражение перед символом | называется производящей функцией (out put function), x – переменная, N – входной набор, а x £ 10 – ус- ловие выборки. Это означает, что множество содержит удвоенные натуральные числа, которые удовлетворяют условию выборки. Если бы нам потребовалось написать то же самое на языке Has- kell, можно было бы изобрести что-то вроде: take 10 [2,4..]. Но что если мы хотим не просто получить первые десять удвоенных нату-
ральных чисел, а применить к ним некую более сложную функцию? Для этого можно использовать генератор списков. Он очень похож на описание множеств: ghci> [x*2 | x <– [1..10]] [2,4,6,8,10,12,14,16,18,20]
В выражении [x*2 | x <– [1..10]] мы извлекаем элементы из списка [1..10], т. е. x последовательно принимает все значения эле- ментов списка. Иногда говорят, что x связывается с каждым элемен- том списка. Часть генератора, находящаяся левее вертикальной черты |, определяет значения элементов результирующего списка. В нашем примере значения x, извлеченные из списка [1..10], умно- жаются на два.
Теперь давайте добавим к этому генератору условие выборки (предикат). Условия идут после задания источника данных и отде- ляются от него запятой. Предположим, что нам нужны только те элементы, которые, будучи удвоенными, больше либо равны 12. ghci> [x*2 | x <– [1..10], x*2 >= 12] [12,14,16,18,20]
Это работает. Замечательно! А как насчёт ситуации, когда тре- буется получить все числа от 50 до 100, остаток от деления на 7 ко- торых равен 3? Легко! ghci> [ x | x <– [50..100], x `mod` 7 == 3] [52,59,66,73,80,87,94]
И снова получилось! ПРИМЕЧАНИЕ. Заметим, что прореживание списков с помощью условий выборки также называется фильтрацией.
Мы взяли список чисел и отфильтровали их условиями. Те- перь другой пример. Давайте предположим, что нам нужно вы- ражение, которое заменяет каждое нечётное число больше 10 на БАХ!", а каждое нечётное число меньше 10 – на БУМ!". Если число чётное, мы выбрасываем его из нашего списка. Для удобства по- местим выражение в функцию, чтобы потом легко использовать его повторно. boomBangs xs = [if x < 10 then "БУМ!" else "БАХ!" | x <– xs, odd x]
ПРИМЕЧАНИЕ. Помните, что если вы пытаетесь определить эту функцию в GHCi, то перед ее именем нужно написать let. Если же вы описываете ее в отдельном файле, а потом загружаете его в GHCi, то никакого let не требуется.
Последняя часть описания – условие выборки. Функция odd воз- вращает значение True для нечётных чисел и False – для чётных. Элемент включается в список, только если все условия выборки возвращают значение True. ghci> boomBangs [7..13] ["БУМ!","БУМ!","БАХ!","БАХ!"]
Мы можем использовать несколько условий выборки. Если бы потребовалось получить все числа от 10 до 20, кроме 13, 15 и 19, то мы бы написали: ghci> [x | x <– [10..20], x /= 13, x /= 15, x /= 19] [10,11,12,14,16,17,18,20]
Можно не только написать несколько условий выборки в гене- раторах списков (элемент должен удовлетворять всем условиям, чтобы быть включённым в результирующий список), но и выби- рать элементы из нескольких списков. В таком случае выражения перебирают все комбинации из данных списков и затем объединя- ют их по производящей функции, которую мы указали: ghci> [x+y | x <- [1,2,3], y <- [10,100,1000]] [11,101,1001,12,102,1002,13,103,1003]
Здесь x берётся из списка [1,2,3], а y – из списка [10,100,1000]. Эти два списка комбинируются следующим образом. Во-первых, x становится равным 1, а y последовательно принимает все значе- ния из списка [10,100,1000]. Поскольку значения x и y складыва- ются, в начало результирующего списка помещаются числа 11, 101 и 1001 (1 прибавляется к 10, 100, 1000). После этого x становится рав- ным 2 и всё повторяется, к списку добавляются числа 12, 102 и 1002. То же самое происходит для x равного 3. Таким образом, каждый элемент x из списка [1,2,3] всеми возможными способами комбинируется с каждым элементом y из списка [10,100,1000], а x+y используется для построения из этих комбинаций результирующего списка.
Вот другой пример: если у нас есть два списка [2,5,10] и [8,10,11], и мы хотим получить произведения всех возможных комбинаций из элементов этих списков, то можно использовать следующее вы- ражение: ghci> [x*y | x <– [2,5,10], y <– [8,10,11]]
[16,20,22,40,50,55,80,100,110] Как и ожидалось, длина нового списка равна 9.
Допустим, нам потребовались все возможные произведения, которые больше 50: ghci> [x*y | x <– [2,5,10], y <– [8,10,11], x*y > 50] [55,80,100,110]
А как насчёт списка, объединяющего элементы списка прилага- тельных с элементами списка существительных... с довольно забав- ным результатом? ghci> let nouns = ["бродяга","лягушатник","поп"] ghci> let adjs = ["ленивый","ворчливый","хитрый"]
ghci> [adj ++ " " ++ noun | adj <– adjs, noun <– nouns] ["ленивый бродяга","ленивый лягушатник","ленивый поп", "ворчливый бродяга","ворчливый лягушатник", "ворчливый поп", "хитрый бродяга","хитрый лягушатник","хитрый поп"] Генераторы списков можно применить даже для написания сво- ей собственной функции length! Назовем ее length': эта функция будет заменять каждый элемент списка на 1, а затем мы все эти еди- ницы просуммируем функцией sum, получив длину списка:
length' xs = sum [1 | _ <– xs] Символ _ означает, что нам неважно, что будет получено из списка, поэтому вместо того, чтобы писать имя образца, которое мы никогда не будем использовать, мы просто пишем _. Поскольку строки – это списки, генератор списков можно использовать для обработки и создания строк. Вот функция, которая принимает строку и удаляет из неё всё, кроме букв в верхнем регистре:
removeNonUppercase st = [c | c <– st, c `elem` ['А'..'Я']]
Всю работу здесь выполняет предикат: символ будет добав- ляться в новый список, только если он является элементом списка ['А'..'Я']. Загрузим функцию в GHCi и проверим: ghci> removeNonUppercase "Ха-ха-ха! А-ха-ха-ха!" "ХА"
ghci> removeNonUppercase "ЯнеЕМЛЯГУШЕК" "ЯЕМЛЯГУШЕК" Вложенные генераторы списков также возможны, если вы ра- ботаете со списками, содержащими вложенные списки. Допустим, список содержит несколько списков чисел. Попробуем удалить все нечётные числа, не разворачивая список:
ghci> let xxs = [[1,3,5,2,3,1,2],[1,2,3,4,5,6,7],[1,2,4,2,1,6,3,1,3,2]]
ghci> [[x | x <– xs, even x ] | xs <– xxs] [[2,2],[2,4,6],[2,4,2,6,2]] ПРИМЕЧАНИЕ. Вы можете писать генераторы списков в несколь- ко строк. Поэтому, если вы не в GHCi, лучше разбить длинные ге- нераторы списков, особенно вложенные, на несколько строк.
Кортежи позволяют хранить несколь- ко элементов разных типов как единое целое. В некотором смысле кортежи похо- жи на списки, однако есть и фундамен- тальные отличия. Во-первых, корте- жи гетерогенны, т. е. в одном кортеже можно хранить элементы нескольких различных типов. Во-вторых, кортежи имеют фиксированный размер: необходимо заранее знать, сколько именно элементов потребуется сохранить.
Кортежи обозначаются круглыми скобками, а их компоненты отделяются запятыми: ghci> (1, 3) (1,3) ghci> (3, 'a', "привет")
(3,'a',"привет") ghci> (50, 50.4, "привет", 'b')
(50,50.4,"привет",'b')
Использование кортежей Подумайте о том, как бы мы представили двумерный вектор в языке Haskell. Один вариант – использовать список. Это могло бы срабо- тать – ну а если нам нужно поместить несколько векторов в список для представления точек фигуры на двумерной плоскости?.. Мы могли бы, например, написать: [[1,2],[8,11],[4,5]].
Проблема подобного подхода в том, что язык Haskell не запре- тит задать таким образом нечто вроде [[1,2],[8,11,5],[4,5]] – ведь это по-прежнему будет список списков с числами. Но по сути данная запись не имеет смысла. В то же время кортеж с двумя элементами (также называемый «парой») имеет свой собственный тип; это зна- чит, что список не может содержать несколько пар, а потом «трой- ку» (кортеж размера 3). Давайте воспользуемся этим вариантом. Вместо того чтобы заключать векторы в квадратные скобки, при- меним круглые: [(1,2),(8,11),(4,5)]. А что произошло бы, если б мы попытались создать такую комбинацию: [(1,2),(8,11,5),(4,5)]? Получили бы ошибку: Couldn't match expected type `(t, t1)' against inferred type `(t2, t3, t4)' In the expression: (8, 11, 5) In the expression: [(1, 2), (8, 11, 5), (4, 5)]
In the definition of `it': it = [(1, 2), (8, 11, 5), (4, 5)] Мы попытались использовать пару и тройку в одном списке, и нас предупреждают: такого не должно быть. Нельзя создать и спи- сок вроде [(1,2),("Один",2)], потому что первый элемент списка – это пара чисел, а второй – пара, состоящая из строки и числа. Кортежи также можно использовать для представления широ- кого диапазона данных. Например, если бы мы хотели представить чьё-либо полное имя и возраст в языке Haskell, то могли бы вос- пользоваться тройкой: ("Кристофер", "Уокен", 69). Как видно из это- го примера, кортежи также могут содержать списки. Используйте кортежи, когда вы знаете заранее, из скольких элементов будет состоять некоторая часть данных. Кортежи гораз-
до менее гибки, поскольку количество и тип элементов образуют тип кортежа, так что вы не можете написать общую функцию, что- бы добавить элемент в кортеж – понадобится написать функцию, чтобы добавить его к паре, функцию, чтобы добавить его к тройке, функцию, чтобы добавить его к четвёрке, и т. д. Как и списки, кортежи можно сравнить друг с другом, если можно сравнивать их компоненты. Однако вам не удастся сравнить кортежи разных размеров (хотя списки разных размеров сравнива- ются, если можно сравнивать их элементы). Несмотря на то что есть списки с одним элементом, не бывает кортежей с одним компонентом. Если вдуматься, это неудивитель- но. Кортеж с единственным элементом был бы просто значением, которое он содержит, и, таким образом, не давал бы нам никаких дополнительных возможностей6.
Использование пар Вот две полезные функции для работы с парами: ®
fst – принимает пару и возвращает её первый компонент. ghci> fst (8,11)
ghci> fst ("Вау", False) "Вау" ® snd – принимает пару и возвращает её второй компонент. Не- ожиданно!
ghci> snd (8,11)
ghci> snd ("Вау", False) False
ПРИМЕЧАНИЕ. Эти функции работают только с парами. Они не будут работать с тройками, четвёрками, пятёрками и т. д. Выде- ление данных из кортежей мы рассмотрим чуть позже.
Замечательная функция, производящая список пар, – zip. Она принимает два списка и сводит их в один, группируя соответству- ющие элементы в пары. Это очень простая, но крайне полезная функция. Особенно она полезна, когда вы хотите объединить два 6 Однако есть нульместный кортеж, обозначаемый в языке Haskell как (). – Прим. ред.
списка или обойти два списка одновременно. Продемонстрируем работу zip: ghci> zip [1,2,3,4,5] [5,5,5,5,5] [(1,5),(2,5),(3,5),(4,5),(5,5)]
ghci> zip [1.. 5] ["один", "два", "три", "четыре", "пять"] [(1,"один"),(2,"два"),(3,"три"),(4,"четыре"),(5,"пять")] Функция «спаривает» элементы и производит новый список. Первый элемент идёт с первым, второй – со вторым и т. д. Обрати- те на это внимание: поскольку пары могут содержать разные типы, функция zip может принять два списка, содержащих разные типы, и объединить их. А что произойдёт, если длина списков не совпа- дает?
ghci> zip [5,3,2,6,2,7,2,5,4,6,6] ["я","не","черепаха"]
[(5,"я"),(3,"не"),(2,"черепаха")] Более длинный список просто обрезается до длины более ко- роткого! Поскольку язык Haskell ленив, мы можем объединить бес- конечный список с конечным:
ghci> zip [1..] ["яблоко", "апельсин", "вишня", "манго"] [(1,"яблоко"),(2,"апельсин"),(3,"вишня"),(4,"манго")]
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2017-02-17; просмотров: 180; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.142.195.79 (0.008 с.) |











 Интервалы
Интервалы




 Генераторы списков
Генераторы списков Кортежи
Кортежи