
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Тема 4: Понятия параллельного выполненияСодержание книги Похожие статьи вашей тематики
Поиск на нашем сайте
Лекция 6 ПАРАЛЛЕЛИЗМ В СИСТЕМАХ АППАРАТНОГО ОБОРУДОВАНИЯ Параллелизм заложен уже на уровне разрядов. Так, операция сложения чисел реализована путем параллельного сложения разрядов с учетом переноса. Команды процессора выполняются параллельно за счет использования конвейера и суперскалярности. Суперскалярнисть означает наличие нескольких блоков для параллельного выполнения операций. К сожалению, параллельное выполнение команд возможно не всегда по следующим причинам: · последовательные команды могут быть зависимыми по результатам. Это означает, что результат выполнения последующей команды зависит от результата выполнения предыдущей команды; · команды перехода нарушают порядок выполнения команд, оттого результат выполнения следующей команды аннулируется; · современные процессоры используют специализированные блоки для целочисловых расчетов, для вычислений с плавающей точкой, для операций умножения и др. В связи с последним недостатком в современных процессорах используется технология HYPER THREADING. Содержание этой технологии заключается в том, что параллельные устройства процессора используются не для выполнения дежурных команд одного потока, а для различных потоков одного процесса или даже различных процессов. В этом случае ОС рассматривает один физический процессор как несколько логических процессоров - ОС их использует для различных потоков. В этом случае говорят о многоядерном процессоре. Пример такого процессора - процессор ITANIUM. Процессоры внешних устройств работают параллельно с ЦП, если одно устройство выполняет операцию ввода / вывода, а другое - вычислительные операции. Это обеспечивает параллельное выполнение нескольких операций даже на однопроцессорной системе. В многопроцессорной системе параллельно работают все процессоры. Определим способы осуществления многозадачности: 1. Сама задача может время от времени передавать управление другой задаче. 2. Управление может в порядке очереди отбираться у одной задачи и передаваться другой задаче. Первый способ получил название кооперативной (не вытесненной) многозадачности, а второй, используемый в большинстве современных ОС - вытесненной многозадачности. ПАРАЛЛЕЛИЗМ В СИСТЕМАХ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ Программы, которые выполняются параллельно, или устройства, которые работают параллельно, как правило не должны знать друг о друге и не мешать одна одной. К тому же, различные устройства могут работать с различной скоростью. Исходя из этого единичный результат выполнения работы должен быть независимым и такой единицей результата является процесс. Таким образом, один с признаков процессов - независимые результаты работы, которые выполняються с различной скоростью. Не все процессы должны быть независимыми. Возможны определенные требования взаимодействия между параллельно работающими процессами. Эти взаимодействия осуществляется по предварительно определенным правилам. Заметим, что параллелизм может быть обеспеченный не только на уровне отдельных процессов, но и внутри процесса за счет использования языковых возможностей. Существует целая теория параллельных вычислений и их использования для решения конкретных задач. Некоторые языки программирования обеспечивают задания участков кода, которые могут выполняться параллельно. В наше время, когда многопроцессорные системы приобрели широкое применение, эта проблема становится все актуальнее. Лекция 7
План лекции: 5. Аппаратная поддержка многозадачного режима 6. Алгоритм аппаратного переключения между задачами 7. Параллелизм в системах программного обеспечения
Литература: М.Ф.Бондаренко, О.Г.Качко Операційні системи: навч.посібник. 2008. 432с. Стр.76 – 79
Переключение задач Задача - единица работы для процессора, то есть это единица, на которую процессор может переключиться, приостановить ее выполнение или удалить. Это может быть утилита ОС или управляющая программа. На аппаратном уровне решаются такие проблемы: · сохранение состояния текущей задачи; · запуск задачи, начиная с начала или из точки, где ее выполнение было приостановлено. Новая задача может быть запущенная как функция - этим обеспечивается возврат к предыдущей задаче после завершения запущенной (команда CALL). Можно запустить новую задачу без сохранения адреса возврата (команда JMP). Аппаратные средства перехода между задачами могут использоваться и часто используются ОС для поддержки механизма перехода между приложениями в случае многопрограммного режима. В дальнейшем будем называть старой задачу, которая инициирует переход, а новой будем называть задачу, на которую выполняется переход. Схема переключения между задачами посредством команд JMP и CALL представлена на рис. 4.1
Рис. 4.1- Переключение между задачами посредством команд JMP и CALL Для переключения задач используются такие структуры данных. • сегмент состояния задачи (Task Status Segment - TSS); • дескриптор сегмента состояния задачи (Task Status Segment Descriptor - TSSD); • регистр задачи (Task Register - 77?); • дескриптор шлюза задачи (Task Gate Descriptor); • NT-флаг в регистре EFLAGS. Сегмент состояния задачи (TSS) Используется для сохранения состояния задачи с целью обеспечения возможности продолжения ее выполнения. Все поля сегмента состояния задачи разделяются на статические и динамические. Статические поля формируются при создании задачи и остаются без изменения вплоть до ее завершения. Состояние динамических полей изменяется в процессе переключения. Минимальный размер TSS равняется 104 байтам, то есть при переходе между задачами необходимо сохранить и потом возобновить, по меньшей мере, 104 байтов. Учитывая это переход между задачами является сложной операцией. Переключение между задачами происходит, если: 1. В командах call, jmp задан селектор для TSS или селектор для шлюза TSS - явное переключение. 2. Выполняется переход на обработчик прерываний или исключений - неявное переключение. 3. Выполняется команда iret после завершения задачи, вызванной командой call (то есть установлен флажок вложенности задач NT в EFLAGS). Дескриптор TSS Сегмент состояния задачи, как и все другие сегменты, определяется дескриптором. Дескриптор TSS задается в GDT и представляет собой пример системного дескриптора. Минимальный размер TSS при условии отсутствия карты разрешения ввода/вывода и дополнительной информации равняется 104 байтам. Если граница сегмента меньше 103, то при переходе на такую задачу генерируется отказ на выполнение. Заметим, что сегмент TSS имеет особые права доступа. Право осуществлять чтение/запись в этот сегмент имеет только процессор. Пользователю с любым уровнем привилегий в этот сегмент не только нельзя записать какую-либо информацию, но даже прочитать ее. Регистр задачи Регистр задачи (Task Register - TR) содержит информацию о текущей задаче, которая состоит из двух частей: «видимой» и «невидимой». «Видимая» часть может считываться и изменяться программным обеспечением. «Невидима» часть используется процессором. В видимой части есть селектор для TSS, что содержит индекс TSS в GDT. Процессор использует невидимую часть для записи адреса начала и границы дескриптора TSS. Сохранение в регистре этих значений делает выполнение задачи более эффективным, поскольку для ссылки к TSS текущей задаче процессору не нужно добывать эти значения с памяти. Шлюз задачи Используется для защищенного переключения между задачами. В шлюзе задается информация о TSS и переключение между задачами происходит по команде перехода, где задается адрес TSS. NT-флаг в регистре EFLAGS Поскольку переключение между задачами происходит только в два способа: по команде JMP без возвращения в область старой задачи и по команде CALL с возможностью возвращения. Но есть способ возвращения с помощью установки в регистре флагов выполняемой задачи бита NT, что означает, что по завершении новой задачи необходимо вернуться к выполнению старой. Лекция 8 Лекция 9
План лекции: 3. Средства синхронизации и связи взаимодействующих вычислительных процессов. 3.1 Блокировка памяти 3.2 Синхронизация процессов с помощью операций проверки и установки 3.3 Семафорные примитивы Дейкстры 3.4 Мониторы Хоара
Литература: А.В.Гордеев Операционные системы: учебник. 2007. 416с. Стр.209 –246
5.2 Средства синхронизации и связи взаимодействующих вычислительных процессов Все известные средства решения проблемы взаимного исключения основаны на использовании специально введенных аппаратных возможностей. К этим аппаратным возможностям относятся: -блокировка памяти, -специальные команды типа «проверка и установка» -и механизмы управления системой прерываний, которые позволяют организовать такие средства, как семафорные операции, мониторы, почтовые ящики и др. С помощью перечисленных средств можно разрабатывать взаимодействующие процессы, при исполнении которых будут корректно решаться все задачи, связанные с проблемой критических секций. Рассмотрим эти средства в следующем порядке по мере их усложнения, перехода к функциям операционной системы и увеличения предоставляемых ими удобств, опираясь на уже древнюю, но все же еще достаточно актуальную работу Дейкстры [10]. Заметим, что этот материал позволяет в полной мере осознать проблемы, возникающие при организации параллельных взаимодействующих вычислений. Эта работа Дейкстры полезна, прежде всего, с методической точки зрения, поскольку она позволяет понять наиболее тонкие моменты в этой проблематике. 5.2.1 Использование блокировки памяти при синхронизации параллельных процессов Все вычислительные машины и системы (в том числе и с многопортовыми блоками оперативной памяти) имеют средство для организации взаимного исключения, называемое блокировкой памяти. Блокировка памяти запрещает одновременное исполнение двух (и более) команд, которые обращаются к одной и той же ячейке памяти. Блокировка памяти имеет место всегда, то есть это обязательное условие функционирования компьютера. Соответственно, поскольку в некоторой ячейке памяти хранится значение разделяемой переменной, то получить доступ к ней может только один процесс, несмотря на возможное совмещение выполнения команд во времени на различных процессорах (или на одном процессоре, но с конвейерной организацией параллельного выполнения команд). Механизм блокировки памяти предотвращает одновременный доступ к разделяемой переменной, но не предотвращает чередование доступа. Таким образом, если критические секции исчерпываются одной командой обращения к памяти, данное средство может быть достаточным для непосредственной реализации взаимного исключения. Если же критические секции требуют более одного обращения к памяти, то задача становится сложной, но алгоритмически разрешимой.
Лекция 10
План лекции: 4. Почтовые ящики 5. Конвейеры и очереди сообщений
Литература: А.В.Гордеев Операционные системы: учебник. 2007. 416с. Стр.209 –246 5.2 Почтовые ящики Тесное взаимодействие между процессами предполагает не только синхронизацию — обмен временными сигналами, но также передачу и получение произвольных данных, то есть обмен сообщениями. В системе с одним процессором посылающий и получающий процессы не могут работать одновременно. В мультипроцессорных системах также нет никакой гарантии их одновременного исполнения. Следовательно, для хранения посланного, но еще не полученного сообщения необходимо место. Оно называется буфером сообщений, или почтовым ящиком Если процесс Р1 хочет общаться с процессом Р2, то Р1 просит систему предоставить или образовать почтовый ящик, который свяжет эти два процесса так, чтобы они могли передавать друг другу сообщения. Для того чтобы послать процессу Р2 какое-то сообщение, процесс Р1 просто помещает это сообщение в почтовый ящик, откуда процесс Р2 может его в любое время получить. При применении почтового ящика процесс Р2 в конце концов обязательно получит сообщение, когда обратится за ним (если вообще обратится). Естественно, что процесс Р2 должен знать о существовании почтового ящика. Поскольку в системе может быть много почтовых ящиков, необходимо обеспечить доступ процессу к конкретному почтовому ящику. Почтовые ящики являются системными объектами, и для пользования таким объектом необходимо получить его у операционной системы, что осуществляется с помощью соответствующих запросов. Если объем передаваемых данных велик, то эффективнее не передавать их непосредственно, а отправлять в почтовый ящик сообщение, информирующее процесс- получатель о том, где можно их найти. Почтовый ящик может быть связан с парой процессов, только с отправителем, только с получателем, или его можно получить из множества почтовых ящиков, которые используют все или несколько процессов. Почтовый ящик, связанный с процессом-получателем, облегчает посылку сообщений от нескольких процессов в фиксированный пункт назначения. Если почтовый ящик не связан жестко с процессами, то сообщение должно содержать идентификаторы и процесса – отправителя и процесса – получателя. Итак, почтовый ящик — это информационная структура, поддерживаемая операционной системой. Она состоит из головного элемента, в котором находится информация о данном почтовом ящике, и нескольких буферов (гнезд), в которые помещают сообщения. Размер каждого буфера и их количество обычно задаются при образовании почтового ящика. Основные достоинства почтовых ящиков: · процессу не нужно знать о существовании других процессов до тех пор, пока он не получит сообщения от них; · два процесса могут обменяться более чем одним сообщением за один раз; · операционная система может гарантировать, что никакой иной процесс не вмешается во взаимодействие процессов, ведущих между собой «переписку»; · очереди буферов позволяют процессу-отправителю продолжать работу, не обращая внимания на получателя. Основным недостатком буферизации сообщений является появление еще одного ресурса, которым нужно управлять. Этим ресурсом являются сами почтовые ящики. К другому недостатку можно отнести статический характер этого ресурса: количество буферов для передачи сообщений через почтовый ящик фиксировано. Поэтому естественным стало появление механизмов, подобных почтовым ящикам, но реализованных на принципах динамического выделения памяти под передаваемые сообщения. В операционных системах компании Microsoft тоже имеются почтовые ящики (mailslots). В частности, они достаточно часто используются при создании распределенных приложений для сети. При работе с ними в приложении, которое должно отправить сообщение другому приложению, необходимо указывать класс доставки сообщений. Различают два класса доставки. Первый класс (first-class delivery) гарантирует доставку сообщений; он ориентирован на сеансовое взаимодействие между процессами и позволяет организовать посылки типа «один к одному» и «один ко многим». Второй класс (second-class delivery) основан на механизме датаграмм, и он уже не гарантирует доставку сообщений получателю.
5.3 Конвейеры и очереди сообщений Конвейеры Программный канал связи (pipe), или, как его иногда называют, конвейер, транспортер, является средством, с помощью которого можно обмениваться данными между процессами. Принцип работы конвейера основан на механизме ввода-вывода файлов, то есть задача, передающая информацию, действует так, как будто она записывает данные в файл, в то время как задача, для которой предназначается эта информация, читает ее из этого файла. Операции записи и чтения осуществляются не записями, как это делается в обычных файлах, а потоком байтов. Таким образом, функции, с помощью которых выполняется запись в канал и чтение из него, являются теми же самыми, что и при работе с файлами. По сути, канал представляет собой поток данных между двумя (или более) процессами. Это упрощает программирование и избавляет программистов от использования каких-то новых механизмов. На самом деле конвейеры не являются файлами на диске, а представляют собой буферную память, работающую по принципу FIFO, то есть по принципу обычной очереди. Однако не следует путать конвейеры с очередями сообщений; последние реализуются иначе и имеют другие возможности. Конвейер имеет определенный размер[4], который не может превышать 64 Кбайт и работает циклически. Вспомните реализацию очереди на массивах, когда имеются указатели начала и конца очереди, которые перемещаются циклически по массиву. То есть имеется некий массив и два указателя: один показывает на первый элемент (указатель на начало — head), а второй — на последний (указатель на конец — tail). В начальный момент оба указателя равны нулю. Добавление самого первого элемента в пустую очередь приводит к тому, что указатели на начало и на конец принимают значение, равное 1 (в массиве появляется первый элемент). В последующем добавление нового элемента вызывает изменение значения второго указателя, поскольку он отмечает расположение именно последнего элемента очереди. Чтение (и удаление) элемента (читается и удаляется всегда первый элемент из созданной очереди) приводит к необходимости модифицировать значение указателя на ее начало. В результате операций записи (добавления) и чтения (удаления) элементов в массиве, моделирующем очередь элементов, указатели будут перемещаться от начала массива к его концу. При достижении указателем значения индекса последнего элемента массива значение указателя вновь становится единичным (если при этом не произошло переполнение массива, то есть количество элементов в очереди не стало большим числа элементов в массиве). Можно сказать, что мы как бы замыкаем массив в кольцо, организуя круговое перемещение указателей на начало и на конец, которые отслеживают первый и последний элементы в очереди. Сказанное иллюстрирует рис. 5.4. Именно так функционирует конвейер. Как информационная структура конвейер описывается идентификатором, размером и двумя указателями. Конвейеры представляют собой системный ресурс. Чтобы начать работу с конвейером, процесс сначала должен заказать его у операционной системы и получить в свое распоряжение. Процессы, знающие идентификатор конвейера, могут через него обмениваться данными.
Указатель на конец Указатель на начало Рис.5.4-Организация очереди в массиве В качестве иллюстрации приведем основные системные запросы для работы с конвейерами, которые имеются в API OS/2. Функция создания конвейера: DosCreatePipe (SReadHandle, &WriteHandle, PipeSize): Здесь ReadHandle — дескриптор чтения из конвейера, WriteHandle — дескриптор записи в конвейер, PipeSize — размер конвейера. Функция чтения из конвейера: DosRead (SReadHandle, (PVOID)SInform. sizeof(Inform), SBytesRead): Здесь ReadHandle — дескриптор чтения из конвейера, Inform — переменная любого типа, sizeof(Inform) — размер переменной Inform, BytesRead — количество прочитанных байтов. Данная функция при обращении к пустому конвейеру будет ожидать, пока в нем не появится информация для чтения. Функция записи в конвейер: DosWrite (SWriteHandle, (PVOID)&Inform, sizeof(Inform), &BytesWrite); Здесь WriteHandle — дескриптор записи в конвейер, BytesWrite — количество записанных байтов. Читать из конвейера может только тот процесс, который знает идентификатор соответствующего конвейера. При работе с конвейером данные непосредственно помещаются в него. Еще раз отметим, что из-за ограничения на размер конвейера программисты сталкиваются и с ограничениями на размеры передаваемых через него сообщений. Очереди сообщений Очереди (queues) сообщений предлагают более удобный метод связи между взаимодействующими процессами по сравнению с каналами, но в своей реализации они сложнее. С помощью очередей также можно из одной или нескольких задач независимым образом посылать сообщения некоторой задаче-приемнику. При этом только процесс-приемник может читать и удалять сообщения из очереди, а процессы-клиенты имеют право лишь помещать в очередь свои сообщения. Таким образом, очередь работает только в одном направлении. Если же необходима двухсторонняя связь, то можно создать две очереди. Работа с очередями сообщений отличается от работы с конвейерами. Во-первых, очереди сообщений предоставляют возможность использовать несколько дисциплин обработки сообщений: · FIFO — сообщение, записанное первым, будет первым и прочитано; · LIFO — сообщение, записанное последним, будет прочитано первым; · приоритетный доступ — сообщения читаются с учетом их приоритетов; · произвольный доступ — сообщения читаются в произвольном порядке. Тогда как канал обеспечивает только дисциплину FIFO. Во-вторых, если при чтении сообщения оно удаляется из конвейера, то при чтении сообщения из очереди этого не происходит, и сообщение при желании может быть прочитано несколько раз. В-третьих, в очередях присутствуют не непосредственно сами сообщения, а только их адреса в памяти и размер. Эта информация размещается системой в сегменте памяти, доступном для всех задач, общающихся с помощью данной очереди. Каждый процесс, использующий очередь, должен предварительно получить разрешение на доступ в общий сегмент памяти с помощью системных запросов API, ибо очередь — это системный механизм, и для работы с ним требуются системные ресурсы и, соответственно, обращение к самой ОС. Во время чтения из очереди задача-приемник пользуется следующей информацией: · идентификатор процесса (Process Identifier, PID), который передал сообщение; · адрес и длина переданного сообщения; · признак необходимости ждать, если очередь пуста; · приоритет переданного сообщения; · номер освобождаемого семафора, когда сообщение передается в очередь. Наконец, приведем перечень основных функций, управляющих работой очереди (без подробного описания передаваемых параметров, поскольку в различных ОС обращения к этим функциям могут существенно различаться):
Контрольные вопросы и задачи 1. Какие последовательные вычислительные процессы мы называем параллельными и почему? Какие параллельные процессы называются независимыми, а какие — взаимодействующими? 2. Изложите алгоритм Деккера, позволяющий разрешить проблему взаимного исключения путем использования одной только блокировки памяти. 3. Объясните, как действует команда проверки и установки. Расскажите о работе команд BTS и BTR, которые имеются в процессорах с архитектурой ia32. 4. Расскажите о семафорах Дейкстры. Чем обеспечивается взаимное исключение при выполнении примитивов Р и V? 5. Изложите, как могут быть реализованы семафорные примитивы для мультипроцессорной системы? 6. Что такое мьютекс? 7. Изложите алгоритм решения задачи «поставщик-потребитель» при использовании семафоров Дейкстры. 8. Изложите алгоритм решения задачи «читатели-писатели» при использовании семафоров Дейкстры. 9. Что такое «монитор Хоара»? Приведите пример такого монитора. 10. Что представляют собой почтовые ящики? 11. Что представляют собой конвейеры (программные каналы)? 12. Что представляют собой очереди сообщений? Чем отличаются очереди сообщений от почтовых ящиков?
Лекция 11 Тема 6: Планирование и диспетчеризация процессов и задач
План лекции: 1. Операции планирования и диспетчеризации 2. Типы планирования процессора 3. Алгоритмы планирования
Литература: А.В.Гордеев Операционные системы: учебник. 2007. 416с. Стр.50 – 71 М.Ф.Бондаренко, О.Г.Качко Операційні системи: навч.посібник. 2008. Стр.126-159 6.1 ОПЕРАЦИИ ПЛАНИРОВАНИЯ И ДИСПЕТЧЕРИЗАЦИИ Самым критичным ресурсом в ЭВМ есть центральный процессор. Наличие нескольких процессоров в многопроцессорных системах только усложняет алгоритм управления временем процессоров. Для управления временем процессоров используются модули планирования и диспетчеризации. Планирование –это формирование очереди процессов, готовых к выполнению. Диспетчеризация –это выбор процессора для конкретного процесса, готового к выполнению. Обычно процедуры обслуживания очереди процессов и выбора процессора выполняются одним модулем, который носит название планировщик – диспетчер. В очереди готовых процессов могут стоять процессы разных типов:
В многозадачных системах в основной памяти одновременно содержится код нескольких процессов. В работе каждого процесса периоды использования процессора чередуются с ожиданием завершения выполнения операций ввода-вывода или некоторых внешних событий. Процессор (или процессоры ) занят выполнением одного процесса, в то время как остальные находятся в состоянии ожидания. Ключом к многозадачности является планирование. Обычно используются ч етыре типа планирования (табл. 6. 1). Одно из них — планирование ввода-вывода. Планирование остальных трех типов, является планированием процессора. Таблица 6.1- Типы планирования
Поскольку изучение планирования при использовании нескольких процессоров сопряжено с дополнительными сложностями, методологически правильнее сначала рассмотреть работу одного процессора, чтобы отчетливее увидеть отличия разных алгоритмов планирования.
6.2 ТИПЫ ПЛАНИРОВАНИЯ ПРОЦЕССОРА Цель планирования процессора состоит в распределении во времени процессов, выполняемых процессором (или процессорами) таким образом, чтобы удовлетворять требованиям системы, таким, как время отклика, пропускная способность и эффективность работы процессора. Во многих системах планирование разбивается на три отдельные функции — долгосрочного, среднесрочного и краткосрочного планирования. Их названия соответствуют временным масштабам выполнения этих функций. Долгосрочное планирование осуществляется при создании нового процесса и представляет собой решение о добавлении нового процесса к множеству активных в настоящий момент процессов. Среднесрочное планирование является частью свопинга и представляет собой решение о добавлении процесса к множеству по крайней мере частично расположенных в основной памяти (и, следовательно, доступных для выполнения) процессов. Краткосрочное планирование является решением о том, какой из готовых к выполнению процессов будет выполняться следующим. На рис. 6.1 диаграмма переходов реорганизована таким образом, чтобы показать вложенность функций планирования. Планирование оказывает большое влияние на производительность системы, поскольку именно оно определяет, какой процесс будет выполняться, а какой — ожидать выполнения. На рис. 6.2 показаны очереди, включенные в диаграмму переходов состояний процесса.[5] По сути,планирование представляет собой управление очередями с целью минимизации задержек и оптимизации производительности системы.
Долгосрочное планирование Долгосрочное планирование указывает, какие программы допускаются к выполнению системой, и тем самым определяет степень многозадачности. Будучи допущенным к выполнению, задание (или пользовательская программа) становится процессом, который добавляется в очередь для краткосрочного планирования. В некоторых системах вновь созданный процесс добавляется к очереди среднесрочного планировщика, будучи целиком сброшенным на диск. В пакетных системах (или в пакетной части операционной системы общего назначения) новое задание направляется на диск и хранится в очереди пакетных заданий, а долгосрочный планировщик по возможности создает процессы для заданий из очереди. В такой ситуации планировщик должен принять решение, во-первых, о том, способна ли операционная система работать с дополнительными процессами, а во-вторых, о том, какое именно задание (или задания) следует превратить в процесс (процессы). Рассмотрим вкратце эти решения.
Рис.6.1-Уровни планирования
Решение о том, когда следует создавать новый процесс, в общем определяется желаемым уровнем многозадачности. Чем больше процессов будет создано, тем меньший процент времени будет тратиться на выполнение каждого из них (поскольку в борьбе за одно и то же время конкурирует большее количество процессов). Таким образом, долгосрочный планировщик может ограничить степень многозадачности, с тем чтобы обеспечить удовлетворительный уровень обслуживания текущего множества процессов. Каждый раз при завершении задания планировщик решает, следует ли добавить в систему один или несколько новых процессов. Кроме того, долгосрочный планировщик может быть вызван в случае, когда относительное время простоя процессора превышает некоторый предопределенный порог. Решение о том, какое из заданий должно быть добавлено в систему, можетосновываться на простейшем принципе « первым поступил — первым обслужен »; кроме того, для управления производительностью системы может использоваться и специальный инструментарий. Используемые в последнем случае критерии могут включать приоритет заданий, ожидаемое время выполнения и требования для работы устройств ввода-вывода. Например, если заранее доступна детально информация о процессах, планировщик может пытаться поддерживать в системе смесь из процессов, ориентированных на вычисления и загружающих процессор, и процессов с высокой интерактивностью ввода-вывода и малой загрузкой прс- цессора. Принимаемое решение может также зависеть от того, какие именно ресурсы ввода-вывода будут запрашиваться процессом. В случае использования интерактивных программ в системах с разделением времени запрос на запуск процесса может генерироваться действиями пользователя по подключению к системе. Пользователи не просто вносятся в очередь в ожидании, когда система обработает их запрос на подключение. Вместо этого операционная система принимает всех зарегистрированных пользователей до насыщения системы (пороговое значение которого определяется заранее). После достижения состояния насыщения на все запросы на вход в систему будет получено сообщение о заполненности системы и временном прекращении доступа к ней с предложением повторить операцию входа попозже. Среднесрочное планирование Среднесрочное планирование является частью системы св опинга. Обычно решение о загрузке процесса в память принимается в зависимости от степени многозадачности; кроме того, в системе с отсутствием виртуальной памяти среднесрочное планирование также тесно связано с вопросами управления памятью. Таким образом, решение о загрузке процесса в память должно учитывать требования к памяти выгружаемого процесса.
Краткосрочное планирование Рассматривая частоту работы планировщика, можно сказать, что долгосрочное планирование выполняется сравнительно редко, среднесрочное — несколько чаще. Краткосрочный же планировщик, известный также как диспетчер (dispatcher), работает чаще всего, определяя, какой именно процесс будет выполняться следующим. Краткосрочный планировщик вызывается при наступлении события, которое может приостановить текущий процесс или предоставить возможность прекратить выполнение данного процесса в пользу другого. Вот некоторые примеры таких событий: · прерывание таймера; · прерывания ввода-вывода; · вызовы операционной системы; · сигналы. 6.3 АЛГОРИТМЫ ПЛАНИРОВАНИЯ Критерии краткосрочного планирования Основная цель краткосрочного планирования состоит в распределении процессорного времени таким образом, чтобы оптимизировать один или несколько аспектов поведения системы. Вообще говоря, имеется множество критериев оценки различных стратегий планирования. Наиболее распространенные критерии могут быть классифицированы в двух плоскостях. Во-первых, мы можем разделить их на пользовательские и системные. Пользовательские критерии связаны с поведением системы по отношению к отдельному пользователю или процессу. В качестве примера можно привести время отклика в интерактивной системе. Время отклика представляет собой интервал между передачей запроса и началом ответа на него. Его пользователь ощущает непосредственно, и, само собой, продолжительность интервала очень интересует его. Мы намерены создать стратегию планирования, обеспечивающую качественный сервис для пользователей? В таком случае для времени отклика следует установить порог, например в 2 секунды. Тогда цель механизма планирования должна заключаться в максимизации количества пользователей, среднее время отклика для которых не превышает 2 секунд. Системные критерии ориентированы на эффективность и полноту использования процессора. В качестве примера можно привести пропускную способность, которая представляет собой скорость завершения процессов. Это, безусловно, эффективная мера производительности системы, которая должна быть максимизирована. Однако она в большей степени ориентирована на производительность системы, а не на обслуживание пользователя, так что и удовлетворять она будет системного администратора, а не пользователей системы. В то время как пользовательские критерии важны почти для всех систем, системные критерии для однопользовательских сист
|
|||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2017-02-06; просмотров: 638; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.3 (0.02 с.) |



 Старая задача JMP Новая задача
Старая задача JMP Новая задача
 Старая задача CALL Новая задача
Старая задача CALL Новая задача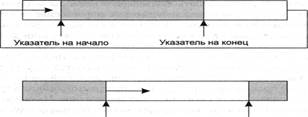
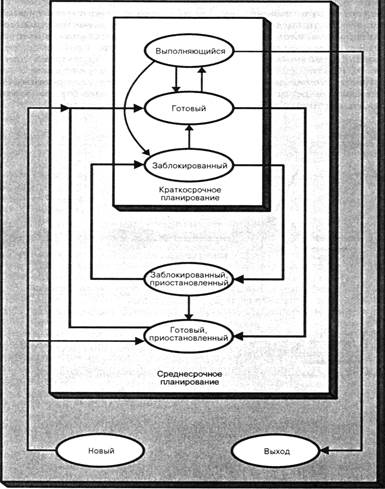
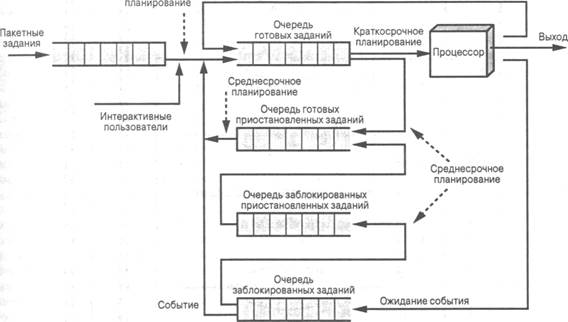 Рис. 6.2- Диаграмма планирования с участием очередей
Рис. 6.2- Диаграмма планирования с участием очередей



